


跑腿快车新商家版app
142.01MB · 2025-11-27

一直以来,我都希望能拍一组日照金山的照片,向往那种巍峨雪山的寂寥与金光漫射的神圣,因缘际会一直未能如愿。看着朋友圈的AI整的手办图,咱也试试生成一个。
你别说,你还真别说,有那么点意思。
我们考虑一个问题,如何让计算机学会画画?我们可能第一时间想到人类画画的过程:
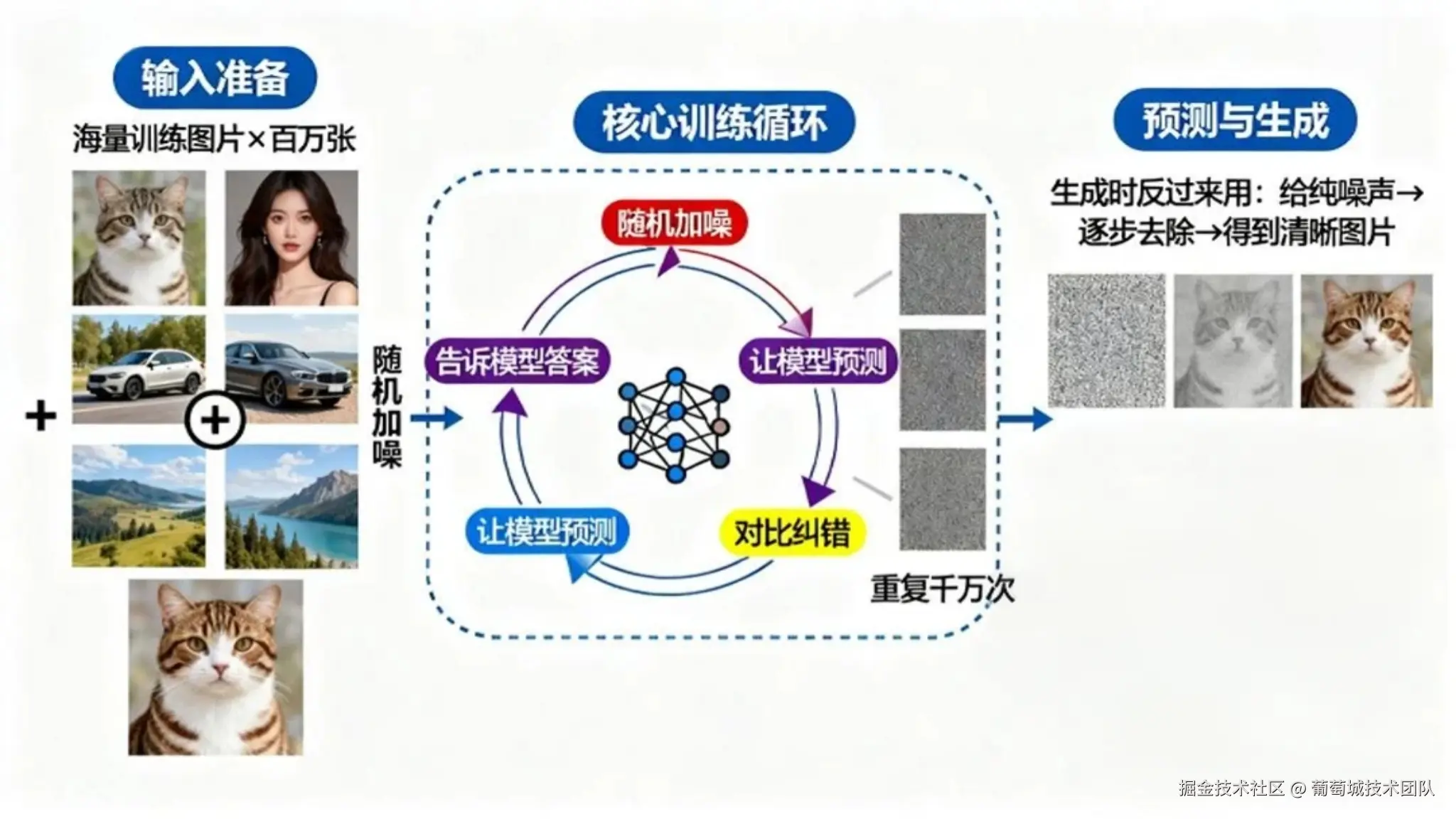
现实世界中有大量不同主体的摄影作品和美术作品,但美术作品大多不会有中间过程的披露,而摄影作品则完全没有(和我的快门说去吧)。所以,学习的出发点一定是现有的优秀作品。**人类学习通过反复练习内化技巧,计算机则是从数据中提取规律。**如果我们有一种可逆的操作,输入图片=>输出特征(学习过程),输入特征=>输出图片(工作过程),那么计算机画画的问题就解决了。
对于学习过程,需要一个提取图像特征的步骤(需要可逆),换个说法就是遮蔽掉非特征的部分,这个遮蔽过程应该具备什么样的特征呢?
看到随机我们可能很自然的想到正态分布(高斯分布),自然界中的随机分布大多都是正态分布,这是中心极限定理的效用(大量独立随机因素的叠加效应,其最终结果的分布会趋于正态分布)。如果按照直觉选择标准正态分布,具体会有什么特性呢?
这种服从正态分布(高斯分布)的噪声我们称之为高斯噪声,下面展示一下高斯噪声的效果。
我们将步数记为 t ( 1 到 T ,T 通常为 1000 ),不同 t 对应不同的噪声水平,t = 0 时, 对应清晰图像。
记为该步数的噪声图像。
还记得我们我们的出发点吗? 我们需要这个过程是可逆的,现在的高斯噪声可以保留图像特征,但是我们怎么记忆这种噪声规律,如何从噪声中恢复图像呢(即对带噪声的图像去掉噪声)?
我们需要"神经网络"这个工具。
如果我们将不同噪声水平的图片 、步数 t、以及图片对应的文本描述 作为训练数据,目标是预测从原始干净图片 x₀ 生成 xₜ 时添加的噪声 ε。最终就可以 预测ε 去噪还原图像。
上面的神经网络模型主要结构是 UNet 模型。在预测是生成过程中,第一步的输入 是纯噪声 图片,此时信息已经完全损失,所以我们无法一步准确推导出 ε(准确的噪声),估算出一个噪声后,应该推导出 ,迭代这个过程,不断更新 ε,我们的信息原来越多,得到的 ε 也会越来约准确。
对于上面的多步骤的过程。每次进行一步,都只仅依赖上一步的结果,这样每次计算的成本都相同,这种过程称为马尔可夫过程。
如果你不熟悉神经网络,还需要额外注意下上面的随机加噪,这一点也很重要, 第一直觉可能是直接从小到大遍历所有噪声水平,这是不合适的:
这里我们已经接近 Diffusion 的核心原理了:**我们不是要直接画图,而是去掉噪声。**像是一个雕刻家一样:雕刻家仅仅是去掉石头多余的部分,把真正的形象"引出"。------米开朗基罗
Diffusion 有两个扩散过程(扩散:一点一点的变模糊或者清晰):
到这里我们已经掌握了 Diffusion 模型的生图核心原理,下面对一些其他重要概念做简要说明。
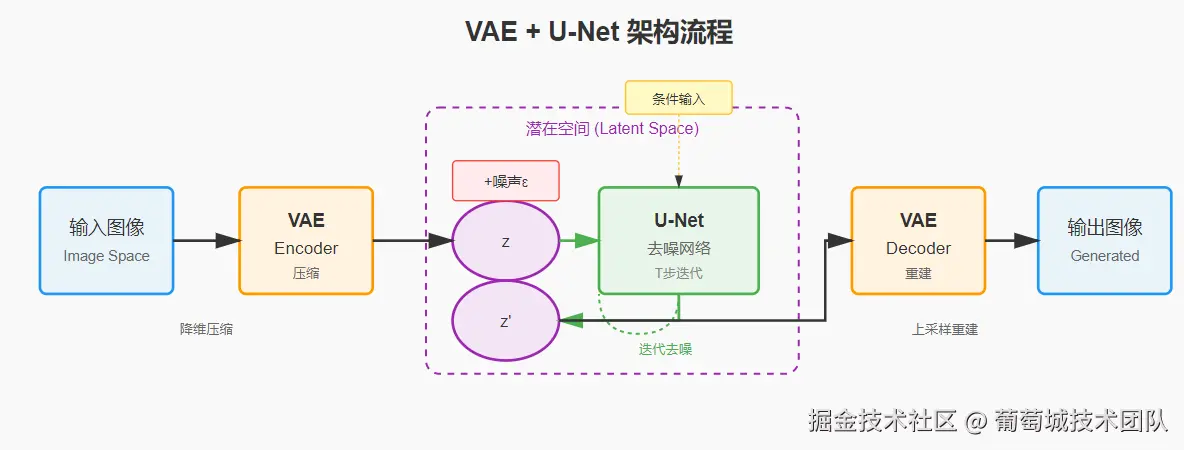
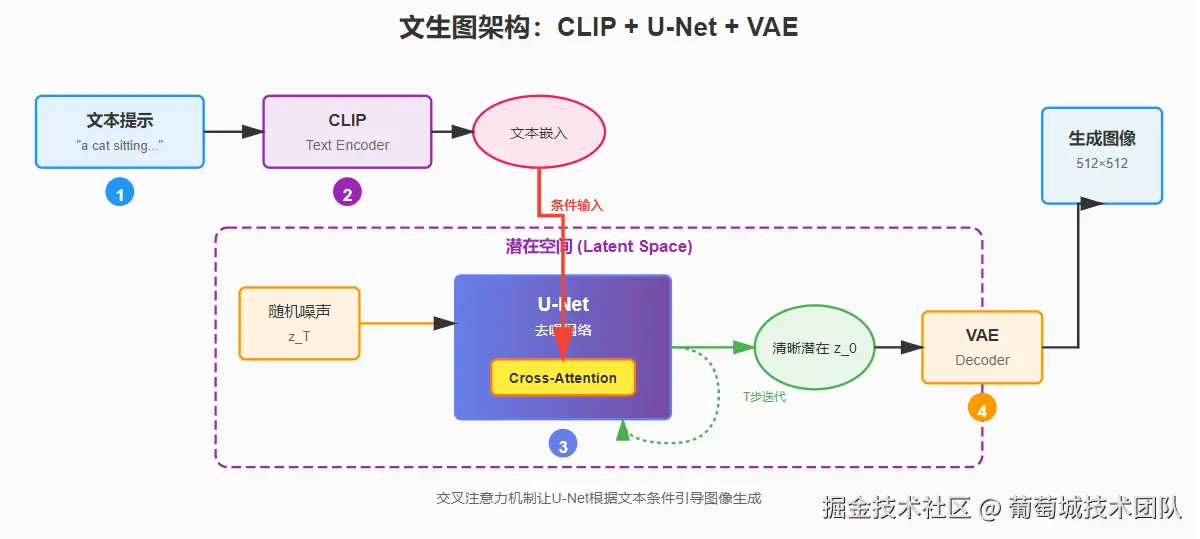
图片实际上非常复杂,常见的手机照片大约是:4032×3024 像素,每个像素会有3个维度 (3个0-255的数字表示颜色RGB)。对这样大的图像直接处理成本过高,我们需要对图片进行压缩(降维),这个压缩后的空间称为潜空间。处理压缩(编码)和解压(解码) 的常见模型为VAE。
压缩比通常为 8倍(每个维度),这么高比例的压缩是一种有损压缩,损失了两部分。
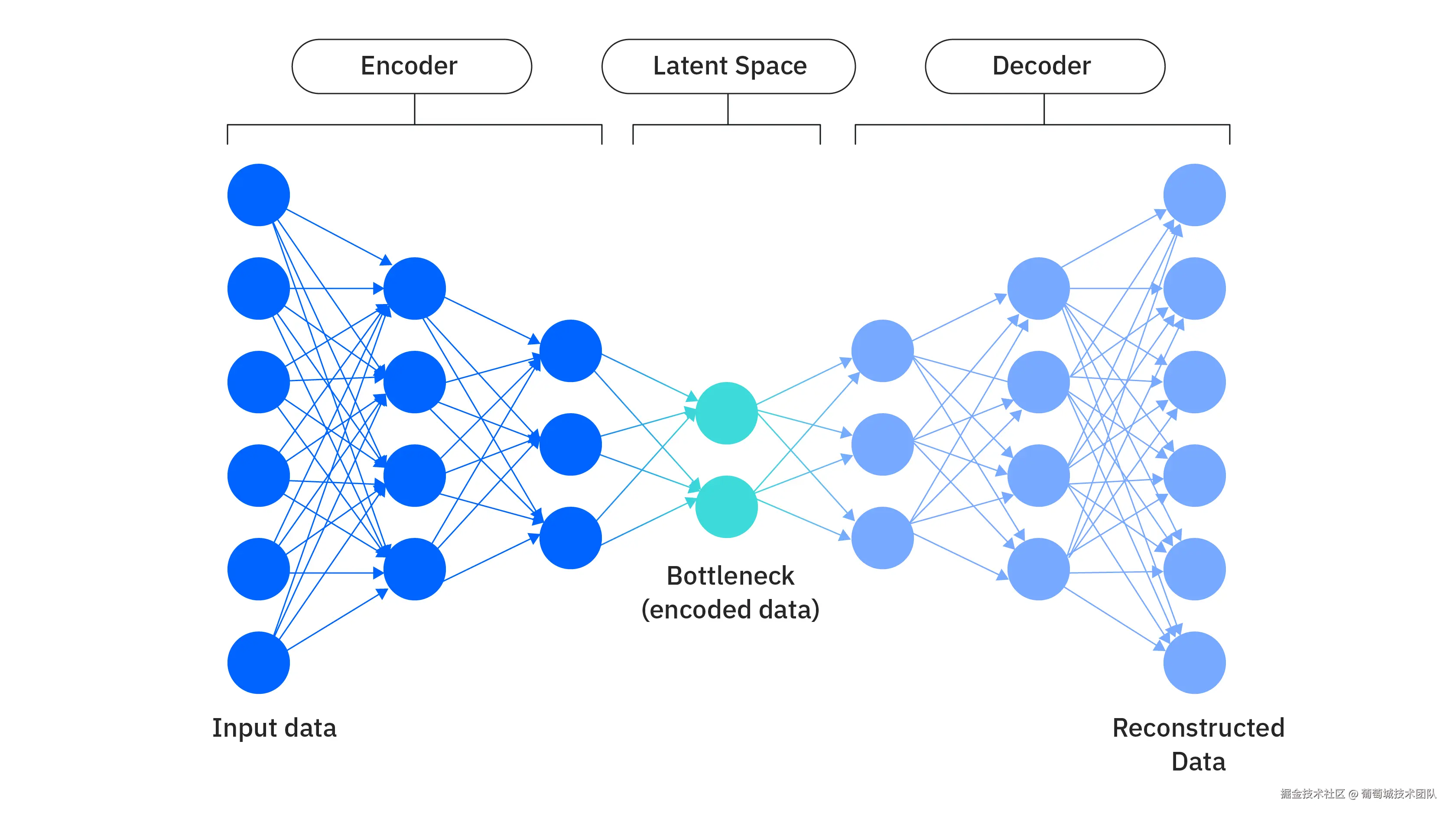
VAE 的全程是 变分自编码器,自编码器是深度学习中的一种神经网络架构,其训练目标是通过降维来压缩(或"编码")输入数据,然后使用该压缩表示准确重建(或"解码")其原始输入。
VAE 和 标准自编码器的区别:
标准自编码器:将训练数据的潜在变量编码为固定的离散值。两个相似的图片在如果用固定离散的点表示,可能会相距很远,而两个固定的点之间值可能是毫无意义的,
VAE: 将训练数据的潜在变量编码为以概率分布表示的连续可能性范围。平滑的概率分布会让相似的图片离得很近,附近区域内的点都是有意义的。
Diffusion 选择 VAE 是由于意义的潜空间表示和高质量的图像重构能力。
上面提到的所有内容和文生图还有一定距离,生成图像是怎么和我们输入的文本关联的呢?
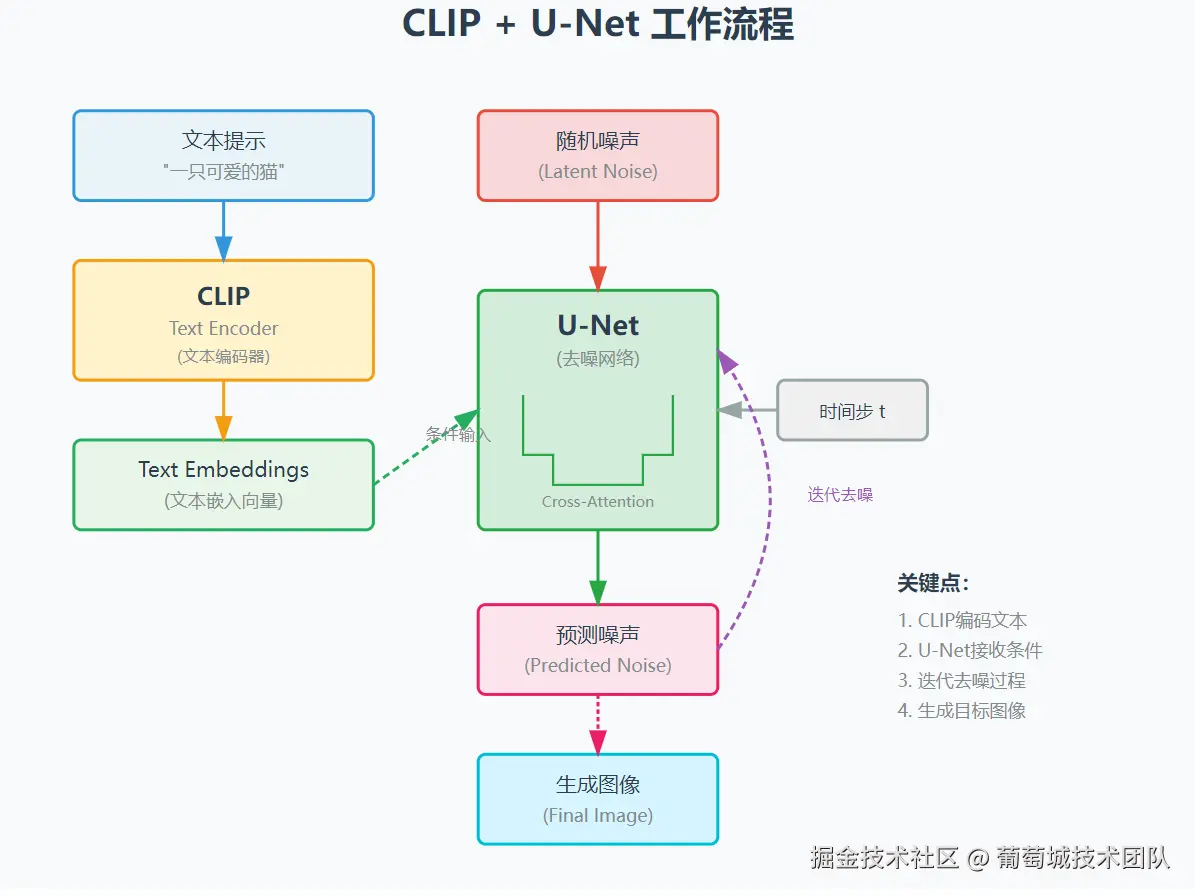
UNet 的去噪过程的起点是一张充满噪声的无意义照片,我们需要指导 UNet 每一步降噪都向我们的提示词靠近。这种机制称为交叉注意力,区别于自主意力(关注自己的内部元素),交叉注意力是两个不同的序列建立关联关系。 交叉注意力机制就是 CLIP 和 UNet 的工作桥梁。
CLIP 从海量的图像文本对中学习图像和文本的匹配关系,这不是在教一个模型"这张图是猫,那张图是狗",而是让匹配的图片文字对的向量在数学空间中尽可能地靠近;让不匹配的尽可能地远离。这个过程叫做对比学习。经过数亿次这样的"拉近"和"推远"的训练后,模型就建立起了一个巨大的、共享的多模态嵌入空间。
这种方式带来了CLIP 的两个核心特性:组合泛化 和零样本学习。
举个例子:假设我们的训练数据中没有斑马,CLIP 还能有效的表示斑马吗? 一定程度上是可以的,CLIP 学会了"马":"四条腿"、"长长的脸"、"鬃毛"等特征;同样,它也从老虎、斑马鱼、条纹衬衫等图片中学到了什么是"条纹"这个视觉模式。当你给出一个从未见过的描述,比如 一匹有黑白条纹的马,文本编码器能够将这些已知词语的语义向量组合起来,在嵌入空间中创造出一个全新的、指向这个复合概念的向量。
我们这里来整理下完整的流程:
回到我们最初的标题------"从混沌中见你所见"。这不仅仅是技术描述,更是一种哲学思考:
我们不是在创造图像,而是在引导混沌显现出它本就蕴含的可能性。
就像摄影师等待光线,雕刻家发现石中的形态,我们通过文本提示,在无数可能性中引导出符合愿景的那一个。每一次生成都是与概率的共舞,在随机性与确定性之间寻找平衡。
142.01MB · 2025-11-27
59.95M · 2025-11-27
131.15MB · 2025-11-27

