
学园偶像大师中文
458.61MB · 2025-11-24

本文将分享一个用于音频源分离(特别是人声与伴奏分离)的自动化脚本和工作流。该方案利用了 audio-separator 库、FFmpeg 进行媒体预处理,并通过 uv 实现了一个免手动配置、依赖自包含的执行环境。
最终效果是:一个Python脚本,一条命令,即可处理任意音频或视频文件,非常适合集成到自动化流程或作为独立的开发者工具使用。
audio-separator: 一个封装了 MDX-Net、Demucs 等多种先进Spleeter模型的Python库,源于 Ultimate Vocal Remover (UVR) 的核心技术。uv: 一个极速 Python 打包和解析器,可作为 pip 和 venv 的替代品。在此方案中,我们利用其 uv run 功能,创建了一个“脚本即环境”的体验。FFmpeg: 音视频处理的瑞士军刀,用于将不同格式的输入文件标准化,作为模型处理的前置步骤。在运行脚本前,确保 uv 和 FFmpeg 在你的环境中可用。
创建一个项目文件夹,例如 audio_sep_tool。后续所有文件都将存放于此。
mkdir audio_sep_tool
cd audio_sep_tool
① FFmpeg
44.1kHz、16-bit PCM WAV 格式。bin/ffmpeg.exe 放置到工作目录。# macOS with Homebrew
brew install ffmpeg
# Debian/Ubuntu
sudo apt update && sudo apt install ffmpeg
② uv
uv.exe 放置到工作目录。curl -LsSf https://astral.sh/uv/install.sh | sh
f.py) 与模型文件f.py在工作目录中创建 f.py 文件。此脚本通过文件顶部的注释块(遵从 PEP 723)定义了其自身的 Python 版本、依赖项和 PyPI 镜像源,uv 会自动识别并应用这些配置。
# /// script
# requires-python = ">=3.10,<=3.12"
# dependencies = [
# "audio-separator>=0.39.1",
# "onnxruntime>=1.18.0"
# ]
#
# [[tool.uv.index]]
# url = "https://pypi.tuna.tsinghua.edu.cn/simple"
# ///
from pathlib import Path
from audio_separator.separator import Separator
import os
import subprocess
import sys
ROOT = Path.cwd()
MODEL_DIR = ROOT / "models"
TMP_DIR = ROOT / "tmp"
def main():
print("="*50)
print(" Audio Separator Initialized...")
print("="*50)
if len(sys.argv) < 2:
print("n Error: Input file path is required.")
print(" Usage: uv run f.py "/path/to/your/audio_or_video.mp4"")
sys.exit(1)
MODEL_DIR.mkdir(exist_ok=True)
TMP_DIR.mkdir(exist_ok=True)
filepath = Path(sys.argv[1])
print(f"n Input file: {filepath.name}")
print(" Step 1/3: Standardizing audio format with FFmpeg...")
file_wav = TMP_DIR / f"{filepath.stem}.wav"
try:
result = subprocess.run(
["ffmpeg", "-y", "-i", str(filepath), "-c:a", "pcm_s16le", "-ac", "2", "-ar", "44100", str(file_wav)],
check=True, capture_output=True, text=True, encoding='utf-8', errors='ignore'
)
print(" Format conversion successful.")
except subprocess.CalledProcessError as e:
print(f"n FFmpeg Error: Pre-processing failed. Check file path and integrity.")
print(f" FFmpeg stderr: {e.stderr}")
sys.exit(1)
separator = Separator(output_dir=ROOT, model_file_dir=MODEL_DIR, output_format="wav", use_soundfile=True)
print("n Step 2/3: Loading separation model...")
model_name = 'vocals_mel_band_roformer.ckpt' # A high-quality vocal separation model (MDX-Net Arch)
try:
separator.load_model(model_filename=model_name)
print(f" Model '{model_name}' loaded successfully.")
except Exception as e:
print(f"n Model loading/download failed. This is often a network issue.")
print(" Please manually download the required model files and place them in the 'models' directory.")
print("n--- Manual Download Links ---")
print(f"1. Create a directory: '{MODEL_DIR}'")
print("2. Download and place the following 3 files inside:")
print(" - Model: https://github.com/nomadkaraoke/python-audio-separator/releases/download/model-configs/vocals_mel_band_roformer.ckpt")
print(" - Checksum: https://raw.githubusercontent.com/TRvlvr/application_data/main/filelists/download_checks.json")
print(" - Config: https://github.com/nomadkaraoke/python-audio-separator/releases/download/model-configs/vocals_mel_band_roformer.yaml")
print("---------------------------n")
sys.exit(1)
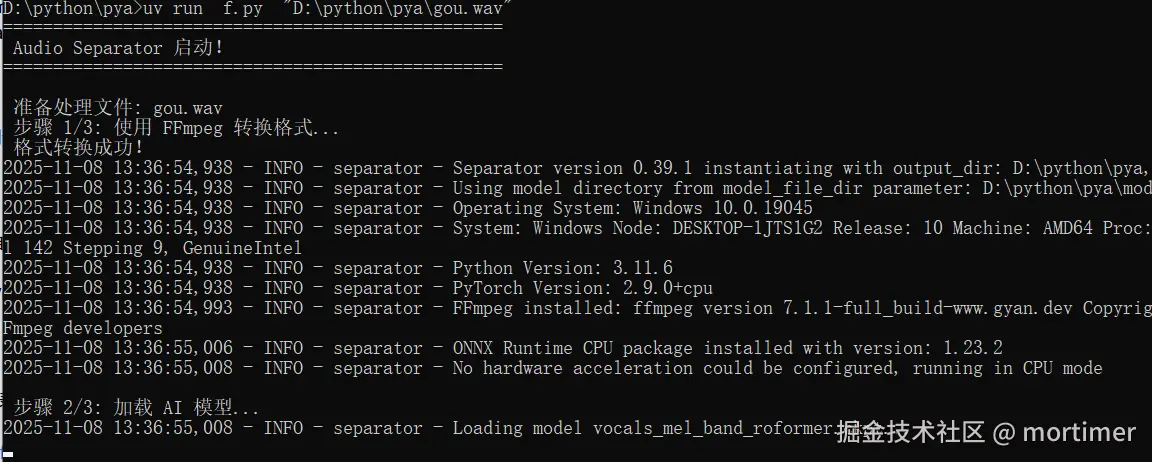
print("n Step 3/3: Processing... This may take a while depending on file length and CPU.")
separator.separate(str(file_wav))
file_wav.unlink(missing_ok=True)
print("n Separation complete!")
print(f" Output files are located in: '{ROOT}'")
print("="*50)
if __name__ == "__main__":
main()
audio-separator 会在首次运行时尝试自动下载模型,但这极易因网络问题失败。推荐先行手动下载。
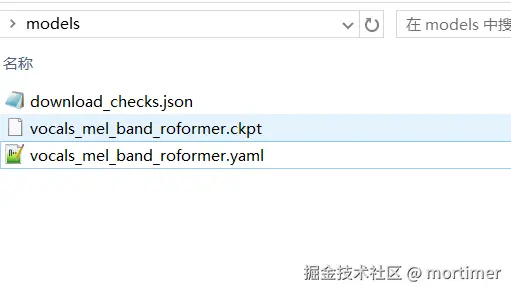
models 文件夹。models 文件夹:
你的项目目录结构应如下:
打开终端(或 Windows 上的 cmd/PowerShell),导航到你的工作目录,然后执行以下命令:
uv run f.py "your/song.mp4"
发生了什么?
uv run 指令会:
f.py 顶部的元数据。audio-separator 和 onnxruntime。f.py,并将文件路径作为参数传递给脚本。拖拽文件到终端是传递路径的便捷方式,可以有效避免空格或特殊字符导致的问题。
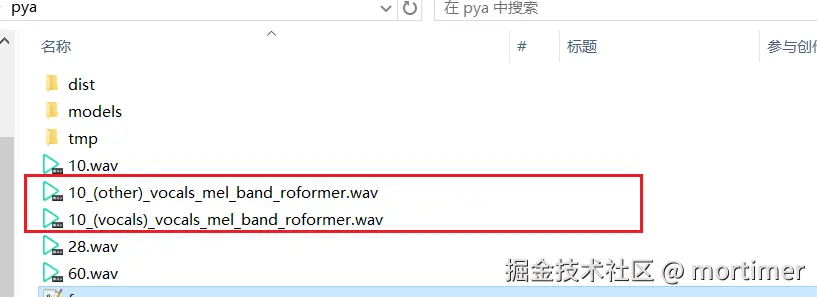
处理完成后,在你的工作目录中会生成两个 WAV 文件:
[原始文件名]_(Vocals)_... .wav: 分离出的人声。[原始文件名]_(Other)_... .wav: 分离出的伴奏/背景声。此脚本是一个简单的起点,以下是一些可供探索的扩展方向:
更换模型:
本脚本硬编码了 vocals_mel_band_roformer.ckpt 模型。你可以访问 audio-separator models list 查找其他模型,例如用于分离鼓 (UVR-MDX-NET-Inst_full_2.onnx) 或贝斯 (UVR-MDX-NET_Inst_1.onnx) 的模型。只需修改 f.py 中的 model_name 变量即可。
GPU 加速: 如果你的机器配备了兼容的 NVIDIA 或 AMD 显卡,可以显著提升处理速度。
f.py 顶部的依赖为 onnxruntime-gpu。更改输出格式:
默认输出为 WAV 以保证无损质量。你可以在 Separator 初始化时修改 output_format="mp3" 来获得体积更小的文件。
这个方案的优雅之处在于,它将环境配置、依赖管理和业务逻辑高度统一。通过 uv 的特性,整个复杂的音频处理流程被简化为一条命令,使得工具的分发和使用变得极其便捷,同时也为开发者提供了清晰的定制和扩展路径。
参考audio-separator仓库:github.com/nomadkaraok…

