


缘之空安卓版汉化
1435MB · 2025-12-24

最近收到一个面试作业(不允许使用AI编程), 我哼哧哼哧尝试1个小时,略略写了一个能跑起来的框架代码和API函数,结果不尽如意。
今天驱动TRAE, 看下主流的AI开发编辑器的能力上下限在哪里, 也看下AI编辑器和人类的编程思维的差异。
原题如下:
TRAE思考了一阵子:
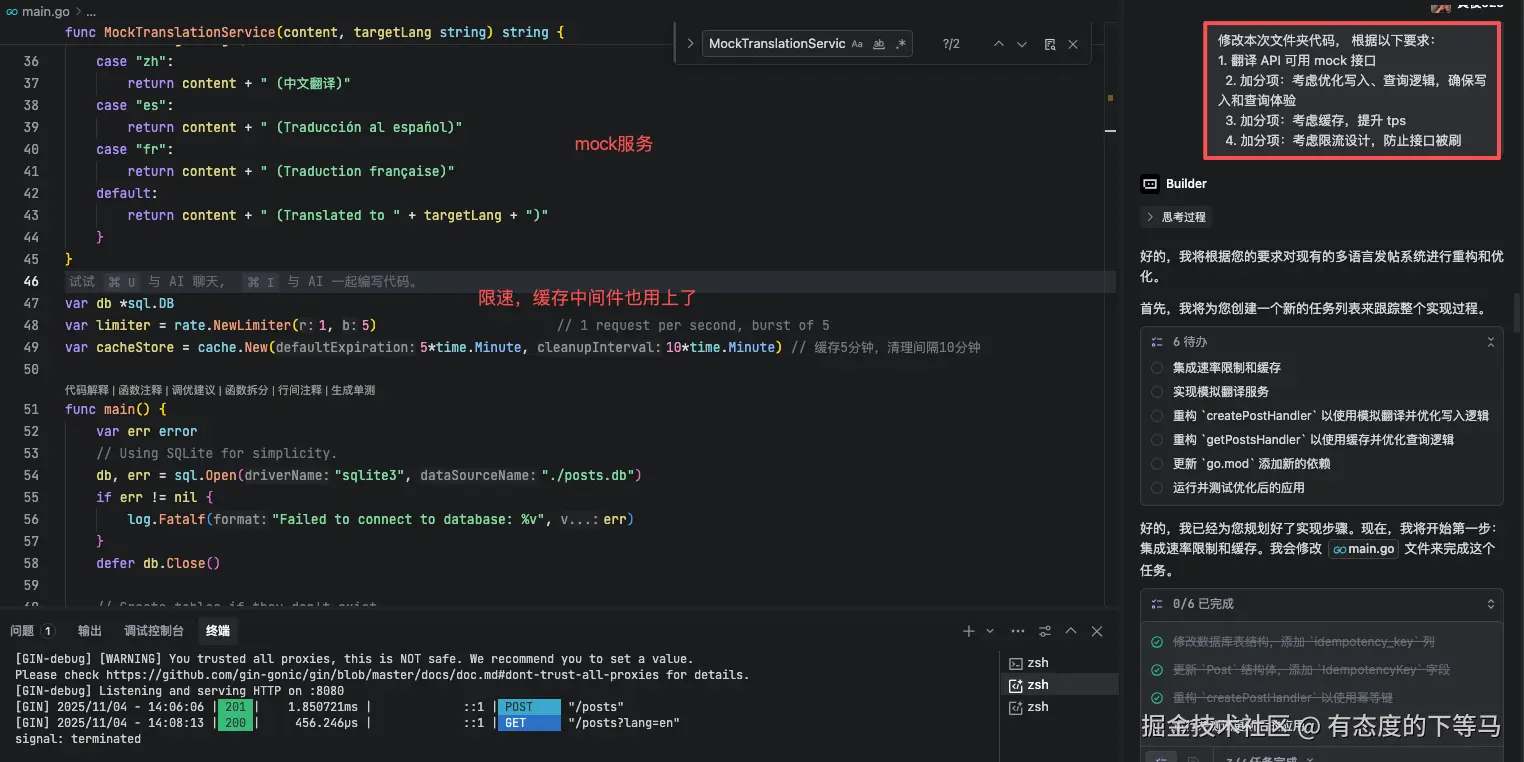
思考过程包括 分析需求目标,分析当前应用程序逻辑结构;在驱动代码过程中,会自动检查编辑器飘红的地方,并给出修复提示;
项目可运行,执行时可以默认端口上运行,并自动产生curl脚本验证API。
整个过程不是那么丝滑,但时间还是可以接受,目测比我一行行手搓代码要快不少。
TRAE生成的代码,使用的sqlite做为数据库,基于gin框架实现了
核心结构体: 使用切片定义语言系统的翻译帖子, 这一点应该与需求不符, 这也与我没有给完整的面试提示相关。
// Post represents the main post content.
type Post struct {
ID string `json:"id"`
Translation []Translation `json:"translation"`
}
// Translation represents the content of a post in a specific language.
type Translation struct {
Language string `json:"language"`
Title string `json:"title"`
Content string `json:"content"`
}
TRAE产生的POST新增帖子请求:
curl -X POST http://localhost:8080/posts -H 'Content-Type: application/json' -d '{
"translations": [
{
"language": "en",
"title": "Hello World",
"content": "This is a post in English."
},
{
"language": "zh",
"title": "你好世界",
"content": "这是一个中文帖子。"
}
]
}'
”现在请将原帖子架构 Post 的Translations 优化为单结构体, 不采用数组, 因为会通过内部mock api 得到翻译的帖子。”
TRAE 也能正确理解,并完成这以代码细节变化。
至此,TRAE 完成了作业Demo,两个API均是简单的独立CR查询 (新增帖子、返回特定语言的所有帖子列表)
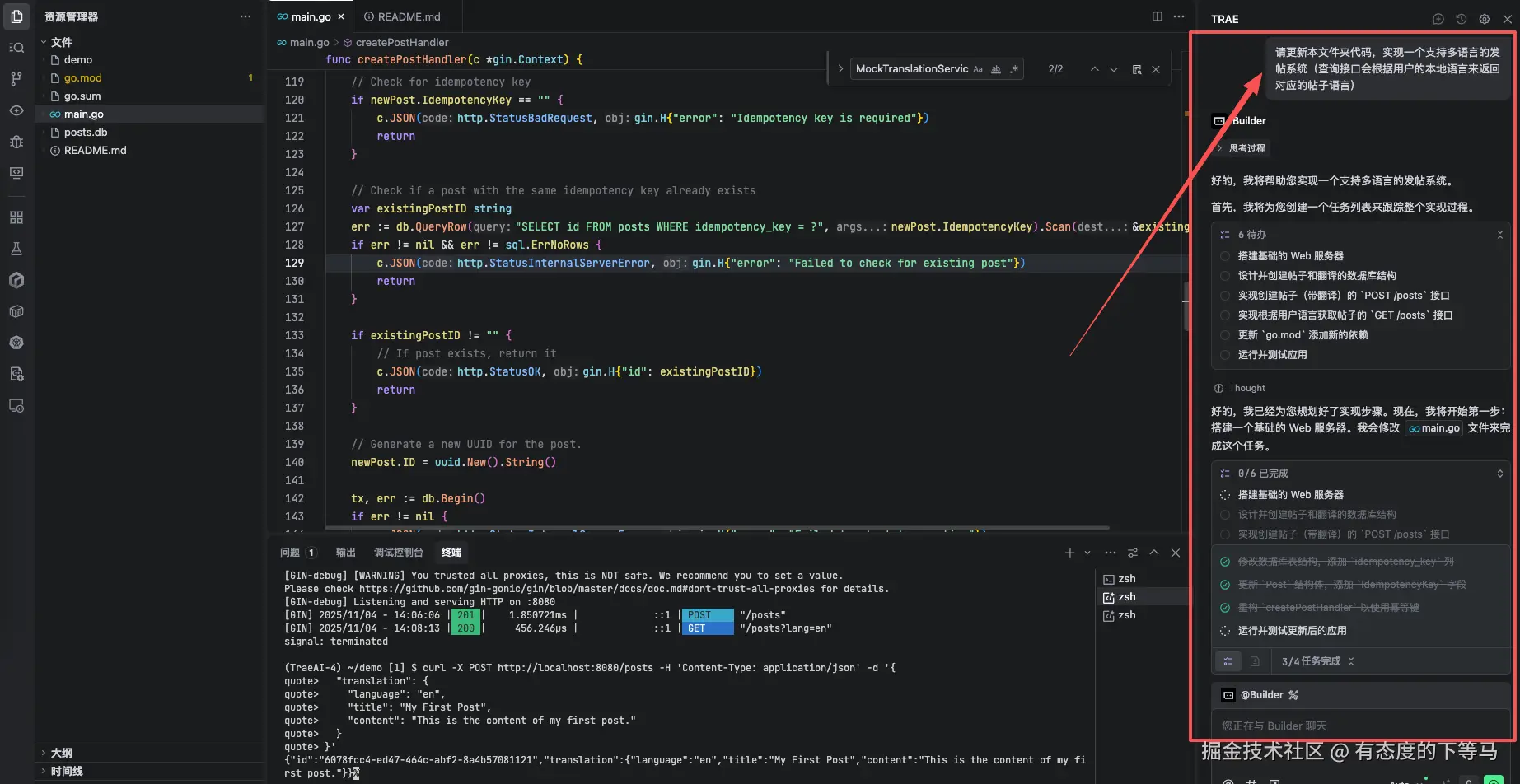
联想到最近我在写 ”幂等操作的实现“,
我琢磨着看AI能否理解 “幂等键”这一不怎么常见的编程术语,还是小看它了。
一顿操作猛于虎,它还是能理解,产生的代码也能匹配自己的认知。
func createPostHandler(c *gin.Context) {
var newPost Post
if err := c.ShouldBindJSON(&newPost); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
// Check for idempotency key
if newPost.IdempotencyKey == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "Idempotency key is required"})
return
}
// Check if a post with the same idempotency key already exists
var existingPostID string
err := db.QueryRow("SELECT id FROM posts WHERE idempotency_key = ?", newPost.IdempotencyKey).Scan(&existingPostID)
if err != nil && err != sql.ErrNoRows {
c.JSON(http.StatusInternalServerError, gin.H{"error": "Failed to check for existing post"})
return
}
if existingPostID != "" {
// If post exists, return it
c.JSON(http.StatusOK, gin.H{"id": existingPostID})
return
}
// Generate a new UUID for the post.
newPost.ID = uuid.New().String()
tx, err := db.Begin()
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": "Failed to start transaction"})
return
}
// Insert into posts table.
_, err = tx.Exec("INSERT INTO posts (id, idempotency_key) VALUES (?, ?)", newPost.ID, newPost.IdempotencyKey)
if err != nil {
tx.Rollback()
c.JSON(http.StatusInternalServerError, gin.H{"error": "Failed to create post"})
return
}
// Insert into translations table.
_, err = tx.Exec("INSERT OR REPLACE INTO translations (post_id, language, title, content) VALUES (?, ?, ?, ?)",
newPost.ID, newPost.Translation.Language, newPost.Translation.Title, newPost.Translation.Content)
if err != nil {
tx.Rollback()
c.JSON(http.StatusInternalServerError, gin.H{"error": "Failed to create translation"})
return
}
if err := tx.Commit(); err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": "Failed to commit transaction"})
return
}
// Clear cache for all languages after creating a new post
cacheStore.Flush()
c.JSON(http.StatusCreated, newPost)
}
if err != nil && err != sql.ErrNoRows { }错误的判断也很精准,这个我写代码都需要去查一下db apiTRAE给的结果:
代码审查完毕。
整体逻辑:
我没有发现任何重大的逻辑漏洞。代码结构清晰,并且我们已经逐步重构和测试了每个部分。
结论:
代码看起来已经准备好运行了。我现在将启动应用程序并进行最后的测试。
这一次启动并curl测试报错了,TRAE试图加日志并怀疑是:“查询幂等键”的逻辑不在事务中,它给移入事务了。
后面陆续出现我们日常开发都会遇到的 uuid 前后版本变更不兼容报错问题,TRAE也自圆其说了。
最后一次运行并验证:
测试再次失败,出现了同样的错误:“Failed to check for existing post”。
是时候检查我之前添加的日志了,看看究竟是什么原因导致了这个问题。
啊!日志清楚地显示了问题:“no such column: idempotency_key”。
这意味着 createTables 函数中的 ALTER TABLE 语句没有正确执行,或者数据库文件 posts.db 是从之前的运行中遗留下来的,当时还没有 idempotency_key 列。
我将停止当前的服务器,删除旧的数据库文件,然后重新运行服务器,以便重新创建带有正确表结构的数据库。
敏感操作(包括删除文件)TRAE都会提示用户,最后一颠一颠还是跑起来,基本满足我提示的需求。
单文件,237行,断断续续耗时40min吧。
初中级程序员危矣,
首先它强大的会话保持能力,能不知疲倦的连续工作; 我们日常开发,如果短时间诱惑去摸鱼或者被动打断编码,后面思路不一定能续上。
其次强大的推理决策能力让它一旦确定了它认为的需求目标,它产出的代码比一般的开发者更加健壮, 之前有戏言:开发者20%时间写代码, 80%时间在调试; 我认为TRAE能做到60%+在产出代码,调试的时间肯定比人类开发者要少。
再次强大的AI知识库, 可以让它指哪打哪,上面我提到Post幂等请求的“幂等键”方案,这个初中级dev不一定有这个术语概念。
最后它完善的端到端AI编程能力, 可以一个人完成需求分析、编码、单测、运行验证、部署全流程看,模糊了目前前后端dev、运维人员的能力边界。
当然现阶段还不能完全取代程序员, 目前的AI驱动编程,还不是你肚子里的蛔虫, 它只能理解通俗语义并基于基本的知识库搭建积木, 有时候代码的健壮性甚至有些啰嗦;业务逻辑的实现有时候并不很优雅,甚至很愕然;能跑但是跑不远,而且给人一种负重很多的感觉,这可能也与提示词的丰富度密切相关,作为快速原型验证,低代码开发是可行的。
我认为后续“编码”要变成“驱动码”了,就像大家都9年义务教育学了语文,都认识老祖宗的3000多汉字,但是有人就是会遣词造句,赋诗弄词, 有人遇到美景就只会“牛逼”,写的800字小作文也是漏洞百出、索然无味。
AI编程作为效率工具,和人类开发者一样,最终还是产品能力提供服务, 我们要把自己绑在这台洪流战车上,不轻易下车,也不排斥换车。
丰富自己的语文字典,也就是编程技能点,心中有墨水,才能指挥的动AI。
看到沙漠:能想到“大漠孤烟直长河落日圆”,看到湖泊能飚出“落霞与孤鹜齐飞,秋水共长天一色的”;
摘抄经典诗词、名言警句, 也就是驱动AI使用约定俗成的编码规范和最佳实践; 当前AI启动代码只管实现功能,比较直接,成熟的企业级项目还是需要让AI多历练最佳实践。
做到以上两点,我相信会最大程度延缓AI替代程序员的时间。

