

弹弹岛2vivo客户端
607.37MB · 2025-12-11

在上一篇文章里,我们聊到一个现实问题:
解决思路之一就是构建“拥挤度指标”来监控市场过热信号。 今天我们不讲空话,带大家实战地计算一个最具代表性的技术指标——RSI的拥挤度。
RSI(Relative Strength Index,相对强弱指标)本质上衡量的是市场短期超买/超卖程度。 计算公式如下:
通常:
很多量化策略会在RSI < 30 时买入,RSI > 70 时卖出,这类信号在A股非常常见。
但问题是: 当越来越多的量化策略、CTA、量化私募都在用RSI逻辑, 这类“超买超卖信号”会失效,甚至反噬。
于是我们需要一个 “RSI 拥挤度指标” 来告诉我们——
我们可以从信号一致性的角度来刻画拥挤度。 简单说:
于是我们可以定义一个指标:
我们把每只股票的 RSI 和 50 这个中性点作比较。
于是我们计算:每只股票离 50 的距离有多远,再取平均。
简单来说:
或者更直观地用统计分布刻画:
更简单理解:
我们看一眼市场里所有股票的 RSI 值,是不是都差不多?
“标准差”就是用来衡量这种“分散程度”的数学指标。标准差越小,越集中;越大,越分散。
当然,还可以进一步扩展: 加入成交量加权或行业分布,比如:
这样可以衡量主力资金在哪些区域过度集中。 想象两只股票:
显然,热门大票的 RSI 变化更能代表主力资金的态度。 所以我们可以给成交量大的股票更高权重,让拥挤度更“贴近真金白银”的流向。
这样:
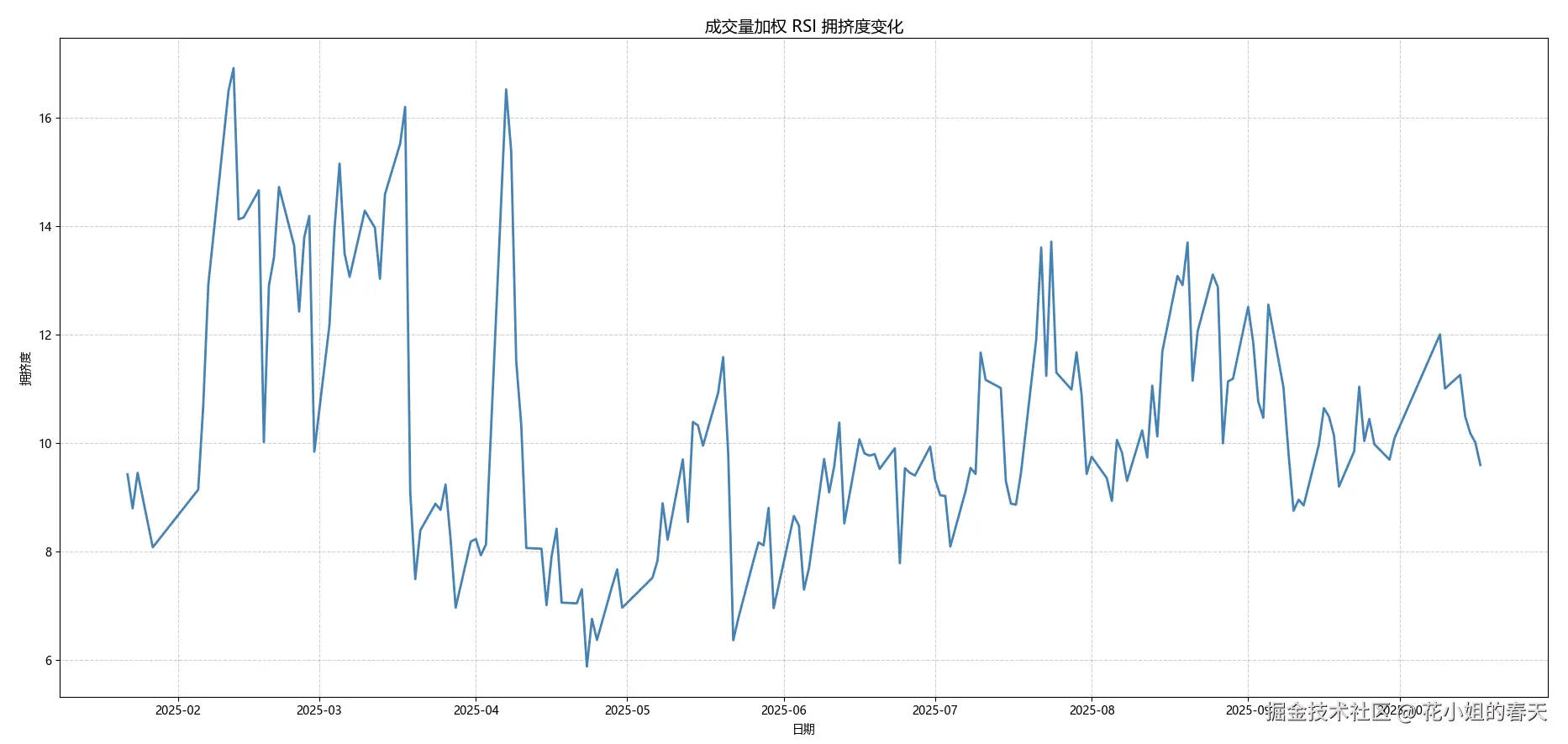
我用方法3绘制出了“拥挤度指标”,数据是从25年1月到10月17号的。
基于全市场股票,计算出每日的成交量加权 RSI 拥挤度,并将结果画成时间序列。 (如下图所示)
从图中可以看到几个关键结论:
拥挤度曲线并不是平稳的,而是不断在高低区间之间震荡。 这说明市场情绪在持续经历一个循环过程:
也就是说,市场并不是长期拥挤,而是阶段性地出现一致交易行为。 这恰好印证了:“因子有效性是周期性的”。
从图中来看,2025年2月–3月、7月–8月期间,RSI 拥挤度飙升到 15~17 区间。 这代表:
在这些阶段,市场行为极度一致,典型特征就是:
结合行情来看,这类阶段往往对应市场的局部顶部或短线过热区。 也就是说: RSI 拥挤度的高点,是一种市场“情绪过热预警信号”。
例如在 2025 年 4–5 月、9 月之后,拥挤度下降至 6~8 左右,说明:
这种状态通常意味着:
从交易角度看,这正是许多反转策略、左侧布局策略开始具备性价比的阶段。
下面是基于成交量加权的拥挤度算法
import pandas as pd
import numpy as np
import talib
import matplotlib.pyplot as plt
def calc_rsi_talib(df, period=14):
"""用 TA-Lib 计算 RSI"""
df['rsi'] = talib.RSI(df['close'].values, timeperiod=period)
return df
def calc_crowd_rsi_vol_daily(quotes_dict, period=14):
"""
计算每天的成交量加权 RSI 拥挤度
quotes_dict: dict {symbol: df},每个 df 至少包含 ['date','close','volume']
返回: DataFrame(date, crowd_rsi_vol)
"""
# 1 对每只股票计算 RSI
all_df = []
for symbol, df in quotes_dict.items():
df = df.sort_values('date')
df = calc_rsi_talib(df, period)
df['symbol'] = symbol
all_df.append(df[['date', 'symbol', 'rsi', 'volume']])
df_all = pd.concat(all_df)
# 2 计算每天的成交量加权拥挤度
def weighted_rsi(group):
valid = group.dropna(subset=['rsi', 'volume'])
if len(valid) == 0:
return np.nan
return np.sum(valid['volume'] * abs(valid['rsi'] - 50)) / np.sum(valid['volume'])
crowd_df = df_all.groupby('date').apply(weighted_rsi).reset_index(name='crowd_rsi_vol')
return crowd_df
def plot_crowd_rsi_vol(crowd_df):
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 中文
plt.rcParams['axes.unicode_minus'] = False
"""画出 RSI 拥挤度的时间序列折线图"""
plt.figure(figsize=(10, 5))
plt.plot(crowd_df['date'], crowd_df['crowd_rsi_vol'], color='steelblue', linewidth=2)
plt.title('成交量加权 RSI 拥挤度变化', fontsize=14)
plt.xlabel('日期')
plt.ylabel('拥挤度')
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()
# ======== 示例用法 ========
# quotes_dict = {
# '000001.SZ': df1, # 每个 df 必须含有 ['date','close','volume']
# '600000.SH': df2,
# ...
# }
# crowd_df = calc_crowd_rsi_vol_daily(quotes_dict, period=14)
# plot_crowd_rsi_vol(crowd_df)
上面的代码行情数据替换成你自己的就可以直接跑通了。基于miniQMT行情数据的完整代码已经放到知识星球了,需要的自取。
你可以用这个指标做出很多有意思的分析:
1️⃣ 风格热度监控 当 RSI 拥挤度过低,说明市场在同一方向过度一致, 可以作为反向信号使用(例如避开短期过热区域)。
2️⃣ 多因子模型风险修正项 在多因子Alpha模型中,将拥挤度作为“风险惩罚项”, 在拥挤度高时自动降低该因子的权重。
3️⃣ 策略回测中的状态切换 当 RSI 拥挤度进入历史极端低位时(例如过去1年分位数 < 5%), 可认为RSI逻辑暂时失效,应切换至动量或波动率因子。
量化的本质是数据、模型、资金、情绪的互动。 而“拥挤度指标”其实是一面镜子—— 它反映的不是指标本身,而是整个市场的共识密度。
RSI 拥挤度只是一个切入点。 你也可以延伸到:
真正成熟的量化系统,不仅预测市场,还预测别人也在预测什么。 当别人都盯着同一个信号时,你就该往别的方向看了。

