


弹弹岛2vivo客户端
607.37MB · 2025-12-11

上期分享LangGraph实战项目:从零手搓DeepResearch(一)——DeepResearch应用体系详细介绍中,笔者对DeepResearch的应用体系进行了系统梳理,掌握了理论知识后,下一步的关键就是动手实践——只有通过项目实操才能真正巩固所学,深入理解DeepResearch智能体系统的运行机制。
本期内容笔者将基于上期介绍的 Pipeline-Agent(顺序管线)模式,使用 LangGraph 与 LangChain 框架,逐步构建一个功能完整的 DeepResearch 多智能体应用。在正式编写代码之前,合理的架构规划是项目成功的重要前提。因此,本文将聚焦于 DeepResearch 系统的整体架构设计思路,并具体探讨搜索工具如何有效接入智能体流程,为后续的代码实现打下坚实基础。
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前基础部分已更新 20 讲,接下来将重点推出实战项目篇,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
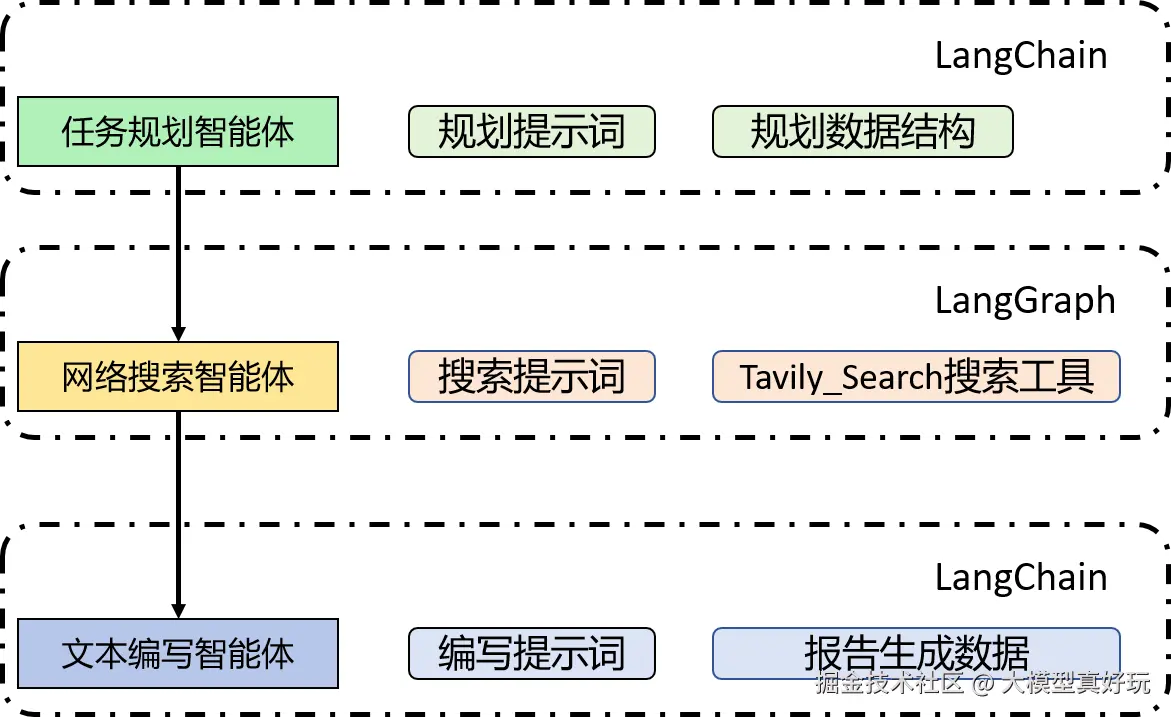
在本实战项目中,笔者采用 Pipeline-Agent(顺序管线)架构来构建 DeepResearch 应用。该架构的核心思想是将整个研究流程划分为多个独立环节,并按预定顺序依次执行,从而形成清晰、可控的处理链路。一个基础的 DeepResearch Pipeline 架构如下图所示:
create_react_agent快速搭建。具备基础的思路之后接下来就探究不同智能体的具体实现,新建项目文件,开发环境依然利用anaconda下的虚拟环境langgraphenv,具体环境搭建可见 深入浅出LangGraph AI Agent智能体开发教程(二)—LangGraph预构建图API快速创建Agent
首先,我们来构建任务规划智能体。开发智能体在 LangChain 与 LangGraph 之间做技术选型时,需要明确两者并非对立关系,而是互补的工具。根据笔者的实践经验,若仅需通过意图引导和输出约束来规范模型行为,推荐使用 LangChain 构建工作流;而涉及工具调用或复杂智能体逻辑时,则更适合采用 LangGraph。任务规划智能体的核心功能是对用户提问进行多角度扩展,仅依赖大模型能力即可完成,因此使用 LangChain 就足够满足需求。
.env文件,填入你在Deepseek官网注册的api_key:DEEPSEEK_API_KEY=
2. 引入项目依赖并初始化大模型组件,需要导入的模块包括约束LangGraph数据的pydantic依赖、DeepSeek大模型依赖、提示词模板依赖、运行工具依赖、图节点数据依赖、高阶预构建图api依赖和搜索工具依赖等,具体的依赖项及使用方法在《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏均有详细讲解。
import os
from dotenv import load_dotenv # 加载环境变量的依赖
from pydantic import BaseModel
from langchain_deepseek import ChatDeepSeek
from langchain.prompts import ChatPromptTemplate
from langchain_core.runnables import Runnable
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.prebuilt import create_react_agent
from langchain_tavily import TavilySearch
load_dotenv(override=True)
Deepseek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
model = ChatDeepSeek(
model_name='deepseek-chat',
api_key=Deepseek_API_KEY
)
PLANNER_INSTRUCTIONS = (
"You are a helpful research assistant, Given a query, come up with a set of web searches "
"to perform to best answer the query, Output between 5 and 7 terms to query for."
)
planner_prompt = ChatPromptTemplate.from_messages([
("system", PLANNER_INSTRUCTIONS),
("human", "{query}")
])
WebSearchItem:定义单个搜索条目,包含搜索词及其重要性理由WebSearchPlan:封装完整的搜索计划,包含多个搜索条目。class WebSearchItem(BaseModel):
query: str
"The search term to use for the web search."
"用于网络搜索的关键词"
reason: str
"You reasoning for why this search is important to the query."
"为什么这个搜索对于解答该问题很重要的理由"
class WebSearchPlan(BaseModel):
searches: list[WebSearchItem]
"A list of web searches to perform to best answer the query"
"为了尽可能全面回答该问题而需要执行的网页搜索列表"
.with_structured_output() 方法确保输出符合预定义结构(这里考察大家是否熟练掌握 Chain 的详细用法,可参考《深入浅出LangChain AI Agent智能体开发教程(三)》):planner_chain = planner_prompt | model.with_structured_output(WebSearchPlan)
planner_result = planner_chain.invoke({'query': '请问你对AI+教育有何看法'})
网络搜索智能体需要多次调用 Tavily 工具获取信息,若继续使用 LangChain 会显得过于死板。为快速实现这一功能,我们采用 LangGraph 提供的高级预构建图 API create_react_agent 来构建搜索智能体,步骤如下:
.env文件中加入TAVILY_API_KEYTAVILY_API_KEY=
2. 创建专门的搜索提示词模板,引导模型根据任务规划阶段生成的搜索词进行网络搜索,并对结果进行核心内容提炼。中文释义为:"你是一名研究助理。根据提供的搜索词,你需要在网络上进行搜索,并生成一份简明扼要的结果摘要。摘要应包含2到3个段落,总字数不超过300词。务必抓住主要观点,表述简洁,无需使用完整句子或优美语法。这份摘要将供他人用于整合研究报告,因此至关重要的是,你要准确提炼核心内容,忽略任何无关信息。除摘要本身外,不要添加任何额外评论。"
SEARCH_INSTRUCTIONS = (
"You are a research assistant. Given a search term, you search the web for that term and "
"produce a concise summary of the results. The summary must 2-3 paragraphs and less than 300"
"words. Capture the main points. Write succinctly, no need to have complete sentences or good"
"grammar. This will be consumed by someone synthesizing a report, so its vital you capture the "
"essence and ignore any fluff. Do not include any additional commentary other than the summary itself."
)
search_tool = TavilySearch(max_results=5, topic="general")
create_react_agent快速构建智能体,不熟悉的大家可参考笔者文章:深入浅出LangGraph AI Agent智能体开发教程(二)—LangGraph预构建图API快速创建Agentsearch_agent = create_react_agent(
model,
prompt=SEARCH_INSTRUCTIONS,
tools=[search_tool]
)
search_agent_res = search_agent.invoke({'messages': [{'role': 'user', "content": planner_result.searches[0].query}]})
print(search_agent_res)
最后需要构建文本编写智能体,负责整合前期搜集的信息并生成结构完整的长篇研究报告。由于此环节不涉及外部工具调用,同样使用 LangChain 进行开发。基本开发步骤如下:
WRITER_PROMPT = (
"You are a senior researcher tasked with writing a cohesive report for a research query."
"You will be provided with the original query, and some initial research done by a research assistant. n"
"You should first come up with an outline for the report that describes the structure and flow of the report. Then, "
"generate the report and return that as your final output. n The final output should be in markdown format, and it should"
"be lengthy and detailed. Aim for 10-20 pages of content, at least 1500 words. 最终生成的报告采用中文输出."
)
ReportData类,包含三个核心字段:short_summary:报告简短摘要markdown_report:最终生成的Markdown格式报告follow_up_questions:建议进一步研究的主题同时将提示词模板与大模型封装为编写链,通过结构化输出确保返回内容符合预定格式:
writer_prompt = ChatPromptTemplate.from_messages([
('system', WRITER_PROMPT),
('human', '{query}')
])
writer_chain = writer_prompt | model.with_structured_output(ReportData)
完成三个独立智能体的开发后,下一步关键工作是将它们串联成一个完整的 DeepResearch 应用。整体流程如下:
我们使用pyhton编写函数逻辑串联以上流程,
# 生成关键词规划
def plan_searches(query: str) -> WebSearchPlan:
result = planner_chain.invoke({'query': query})
return result
# 根据关键词进行搜索
def search(item:WebSearchItem) -> str | None:
try:
final_query = f"Search Item: {item.query}nReason for searching: {item.reason}"
result = search_agent.invoke({"messages":[
{
"role": "user",
"content": final_query
}
]})
return str(result['messages'][-1].content)
except Exception:
return None
# 根据关键词列表逐个搜索得到搜索结果列表
def perform_searches(search_plan: WebSearchPlan):
results = []
for item in search_plan.searches:
result = search(item)
if result is not None:
results.append(result)
return results
# 根据搜索的结果列表和用户提问生成报告
def write_report(query: str, search_results) -> ReportData:
summary=''
for search_result in search_results:
summary += search_result
final_query = f'Original query: {query}n Summarized search results: {summary}'
result = writer_chain.invoke({
'query': final_query
})
return result
# 串联以上流程函数
def deepresearch(query: str) -> ReportData:
'''
输入一个研究主题,自动完成搜索规划、搜索和写报告
返回最终的ReportData对象,就是一个markdown的格式完整的研究报告文档
'''
search_plan = plan_searches(query)
search_results = perform_searches(search_plan)
report = write_report(query, search_results)
print(report.markdown_report)
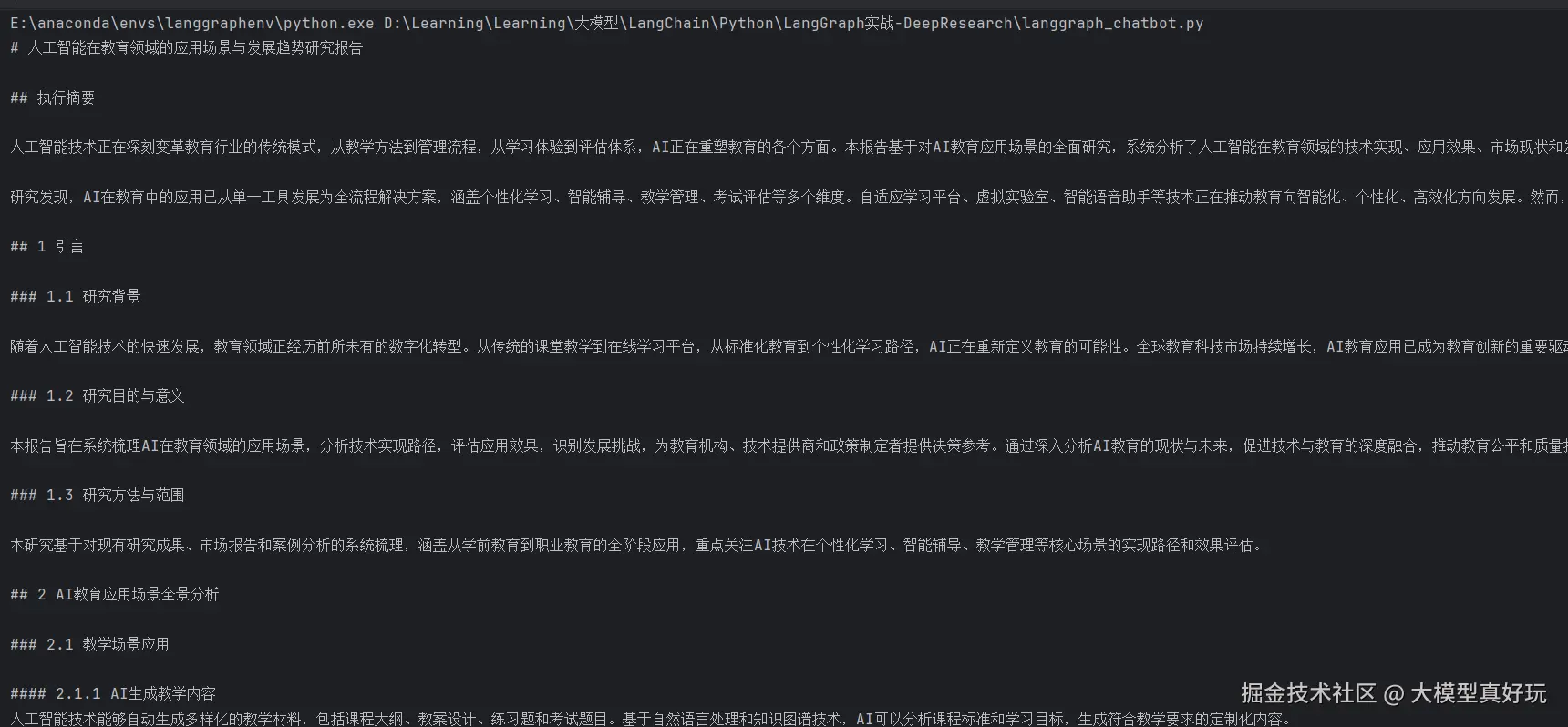
通过实际测试验证整个系统的运行效果,输入"AI在教育方面的应用场景"后,系统成功生成了结构完整、内容详实的长篇研究报告:
deepresearch('AI在教育方面的应用场景')
测试结果显示,系统能够按照预期流程自动完成搜索规划、多角度信息搜集和报告生成,输出的Markdown格式报告内容充实、结构清晰,验证了多智能体协作的有效性。以上就是我们本期分享的全部内容啦~
本期内容完整分享了如何基于 Pipeline-Agent 架构编写多智能体实现DeepResearch应用,整个系统通过任务规划、网络搜索和报告生成三个核心智能体的协同工作,实现了从问题分析到研究报告生成的完整流程。
不过大家别忘了我们是在LangChain/LangGraph开发场景下,LangGraph是天然的多智能体框架,那我们可不可以使用LangGraph 汇总三个智能体并构造多智能体应用呢?答案当然是可以的,大家可以先想一下实现方法,下一期分享我们就来详细讲解如何利用LangGraph构建多智能体并部署成网站的形式~
当然本期内容实现的只是一个简单的顺序管线的DeepResearch应用,实际的DeepResearch功能要复杂的多,比如Tavily搜索除了搜索网络数据,还能搜索本地的文档和知识库。还可以扩充第三步写文档的各种格式,可以支持格式选择等等,大家开动开动聪明的小脑瓜利用我们的所学技术构建出更强大的DeepResearch应用吧~
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前基础部分已更新 20 讲,接下来将重点推出实战项目篇,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。

