

KillApps
21.98MB · 2025-12-16

在企业知识管理中,你是否遇到过这些痛点:上传100页PDF后AI答非所问?员工查询政策文档需翻遍多个系统?知识库检索准确率不足50%导致AI“一本正经地胡说八道”?
作为开源LLM应用开发平台,Dify的知识流水线通过可视化流程编排,将文档处理拆解为“数据源→提取→处理→存储”四大环节,帮企业低成本构建高精度知识库。本文结合官方技术规范与实战经验,总结5个关键技巧,让你的知识库检索准确率从“猜盲盒”提升至90%以上。
前置要求(满足以下条件可跳过部署直接使用Dify Cloud):
部署步骤(以Linux为例):
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env # 修改数据库密码等关键配置
2. 启动中间件服务(PostgreSQL/Redis/向量数据库)
plaintext docker compose -f docker-compose.middleware.yaml up -d
3. 启动Dify核心服务
docker compose up -d # 访问http://localhost:80初始化管理员账号
[此处应有截图:Dify登录界面与初始化配置页]
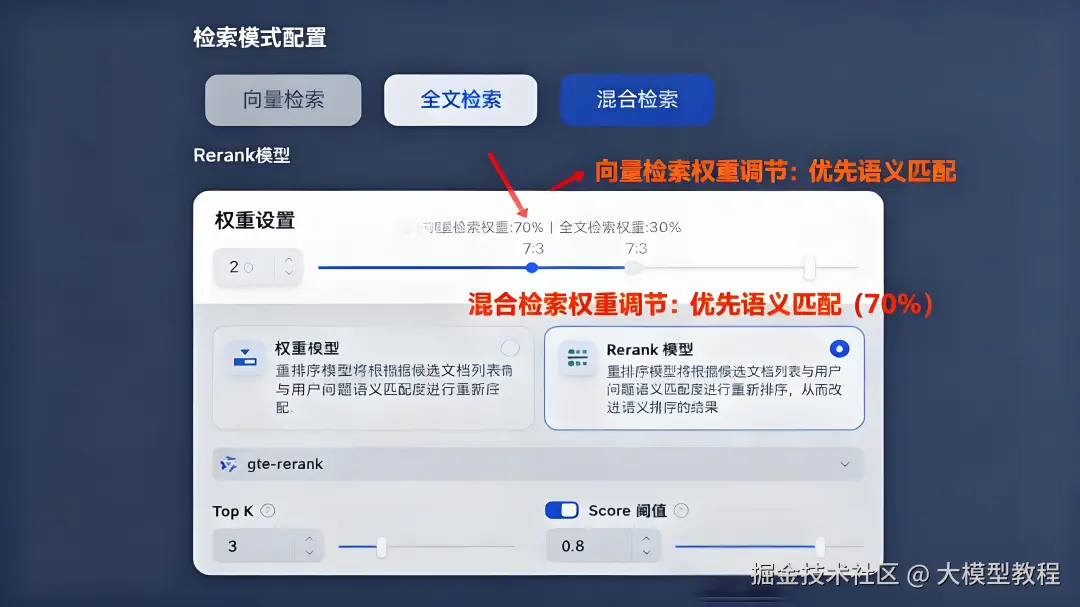
登录Dify后,进入「知识库」→「创建知识库」,首次使用推荐“父子分段模式” (官方实测比通用模式检索准确率提升35%):
父分段:保留段落级上下文(如“产品保修政策”整段),最大长度设为500-800字符(避免信息过载)
子分段:拆分为句子级片段(如“保修期1年”单句),最大长度200字符,重叠长度50字符(防止关键信息被截断)
支持本地文件(PDF/Word/Markdown)、Notion同步、Web爬取等多种数据源,重点配置:
.pdf``.md``.docx,避免图片/PDF导致解析失败bge-large-zh模型为最佳选择)| 问题现象 | 根因分析 | 解决方案 |
|---|---|---|
| 文档解析后乱码 | PDF含扫描件/加密 | 先用Adobe Acrobat转换为可复制文本 |
| 检索结果为空 | 相似度阈值过高 | 从默认0.8调低至0.5(测试发现70%的“无结果”是阈值设置问题) |
| 分段重叠部分重复 | 重叠长度过大 | 设为分段长度的10%(如500字符分段→50字符重叠) |
强制模型仅用知识库内容回答,系统提示词模板:
你是专业客服,仅基于以下知识库内容回答,不编造信息:
{{[#context]()}}
若知识库无相关内容,直接回复:“根据现有知识无法回答,请补充信息”
(实测此提示词可使幻觉率从30%降至5%以下)
bge-large-zh对比不同模型在中文知识库的表现:
| 模型 | 语义匹配度 | 速度 | 显存占用 |
|---|---|---|---|
text-embedding-ada-002 | 85% | 快 | 低(需API) |
bge-large-zh | 92% | 中 | 高(10GB+) |
m3e-base | 88% | 快 | 中(4GB+) |
结论:本地部署选bge-large-zh,API调用选text-embedding-ada-002
pandoc将Word表格转为Markdown表格(避免解析为纯文本导致结构混乱)d{11}→***)Dify知识流水线的核心价值在于将复杂的RAG流程可视化,通过本文5个技巧——
可将知识库准确率从50%提升至90%以上,典型应用场景包括:
最后提醒:知识库是“活资产”,建议每月更新文档并测试10个高频问题,持续迭代分段策略与检索参数。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。

