
造价师万题库
163.84MB · 2025-12-16

现代 AI 聊天机器人常常依赖 Retrieval-Augmented Generation (RAG) ,也就是检索增强生成技术。这种技术让机器人能从外部数据中提取真实信息来支撑回答。如果你用过“与你的文档聊天”之类的工具,你就见过 RAG 的实际应用:系统会从文档中找到相关片段,喂给大语言模型(LLM),让它能用准确的信息回答你的问题。
RAG 大大提升了 LLM 回答的事实准确性。不过,传统 RAG 系统大多把知识看成一堆互不关联的文本片段。LLM 拿到几段相关内容后,得自己把它们拼凑起来回答。这种方式对简单问题还行,但遇到需要跨多个来源串联信息的复杂查询,效果就不理想了。
这篇文章会深入浅出地解释两个能让聊天机器人更上一层楼的概念:ontologies(本体论) 和 knowledge graphs(知识图谱) ,以及它们如何与 RAG 结合,形成 GraphRAG(基于图的检索增强生成) 。我们会用简单的语言说明它们是什么,为什么重要。
为什么这很重要?你可能会问。因为 GraphRAG 能让聊天机器人的回答更准确、更贴合上下文、更有洞察力,比传统 RAG 强多了。企业在探索 AI 解决方案时很看重这些特质——一个真正理解上下文、避免错误、能处理复杂问题的 AI 可以彻底改变游戏规则。(不过,这需要完美的实现,实际中往往没那么理想。)
通过把非结构化文本和结构化的知识图谱结合起来,GraphRAG 系统能提供感觉上更“有学问”的回答。把知识图谱和 LLM 结合起来,是让 AI 不仅能检索信息,还能真正理解信息的关键一步。
Retrieval-Augmented Generation,简称 RAG,是一种通过外部知识来增强语言模型回答的技术。RAG 系统不是仅靠模型记忆里的东西(可能过时或不完整)来回答,而是会从外部来源(比如文档、数据库或网络)抓取相关信息,喂给模型来帮助生成答案。
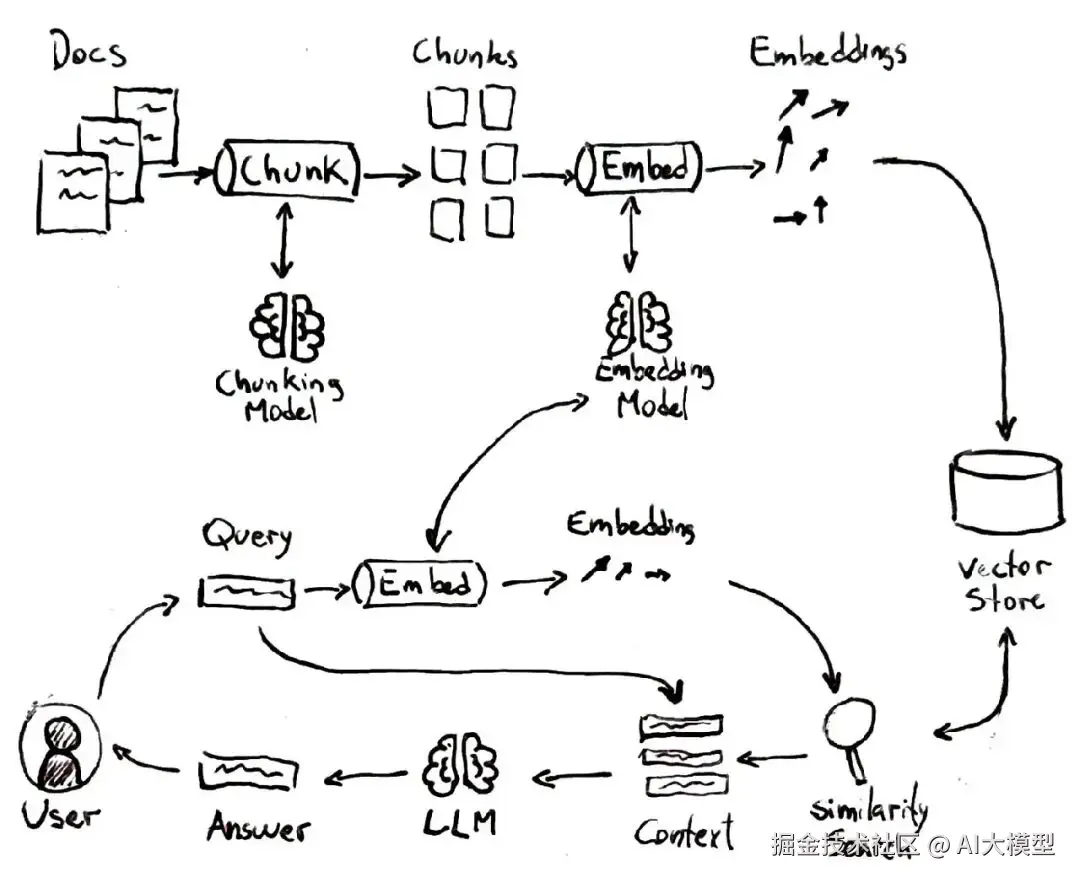
简单来说,RAG = LLM + 搜索引擎:模型先检索支持数据,增强对主题的理解,然后结合内置知识和检索到的信息生成回答。
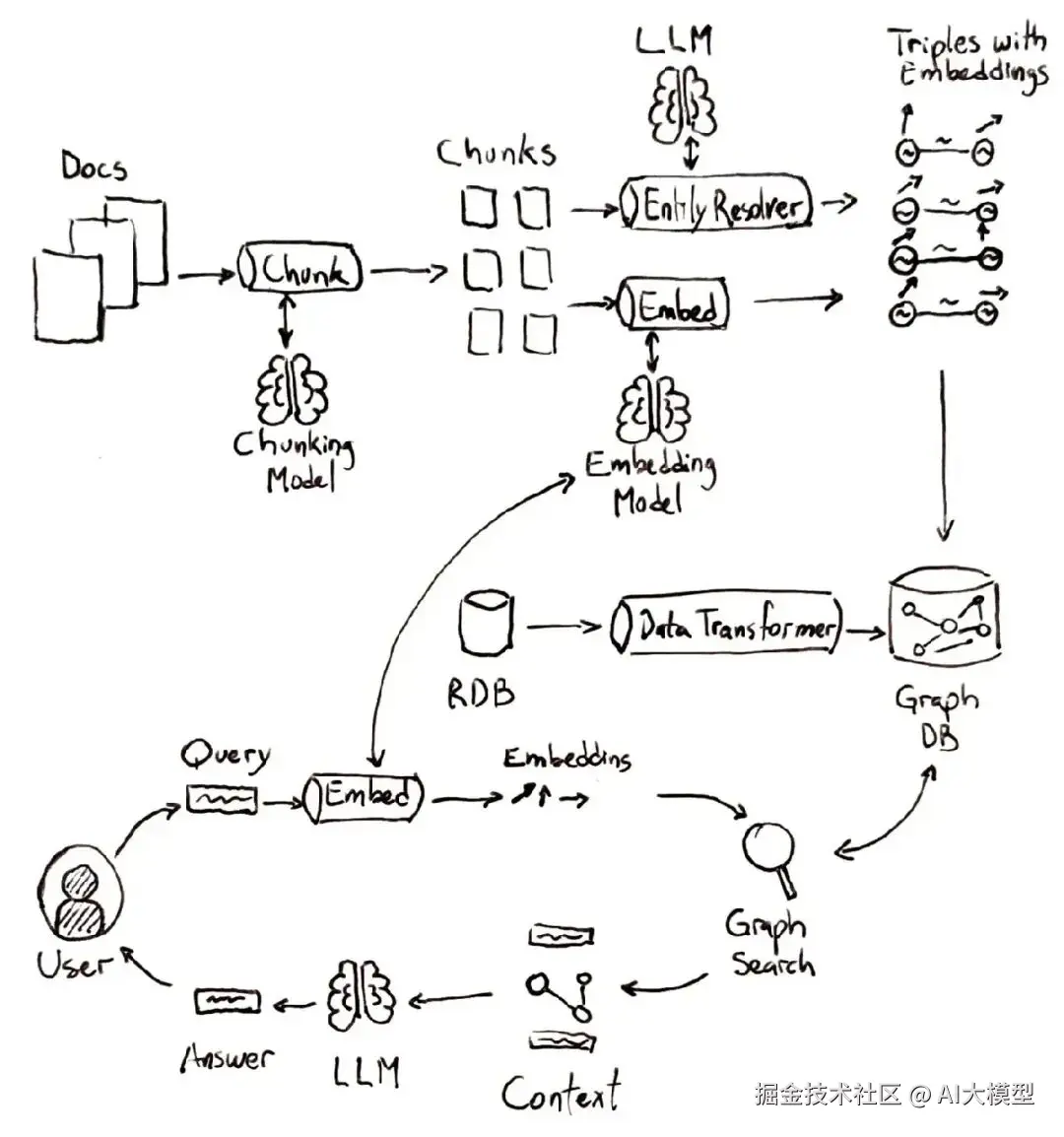
如上图所示,典型的 RAG 流程包含几个步骤,就像一个智能查找过程:
RAG 让 LLM 在现实场景中变得更实用。像 Bing Chat 或各种文档问答机器人就是靠 RAG 提供最新、具体的答案,还能附上参考资料。通过用检索到的文本来“锚定”回答,RAG 减少了 hallucinations(模型瞎编) ,还能访问超出 AI 训练截止日期的信息。不过,传统 RAG 也有一些明显的局限:
在实际中,对于简单的事实查询,比如“这家公司什么时候成立的?”,传统 RAG 表现很好。但对于复杂问题,比如“比较第一季度销售和营销支出的趋势,并找出相关性”,传统 RAG 就可能掉链子。它可能返回一段关于销售的文本,另一段关于营销的,但逻辑整合得靠 LLM 自己来,可能不一定能连贯成功。
这些局限性指向一个机会。如果我们不只是给 AI 一堆文档,而是再给它一个 knowledge graph(知识图谱) ,也就是实体和它们关系的网络,作为推理的框架呢?如果 RAG 检索不只是基于相似性返回文本,而是返回一组相互关联的事实,AI 就能顺着这些联系生成更有洞察力的回答。
GraphRAG 就是把基于图的知识整合进 RAG 流程。通过这样做,我们希望解决上面提到的多来源、歧义和推理问题。
在深入 GraphRAG 的工作原理之前,我们先搞清楚 knowledge graphs(知识图谱) 和 ontologies(本体论) 是什么——它们是这种方法的基础。
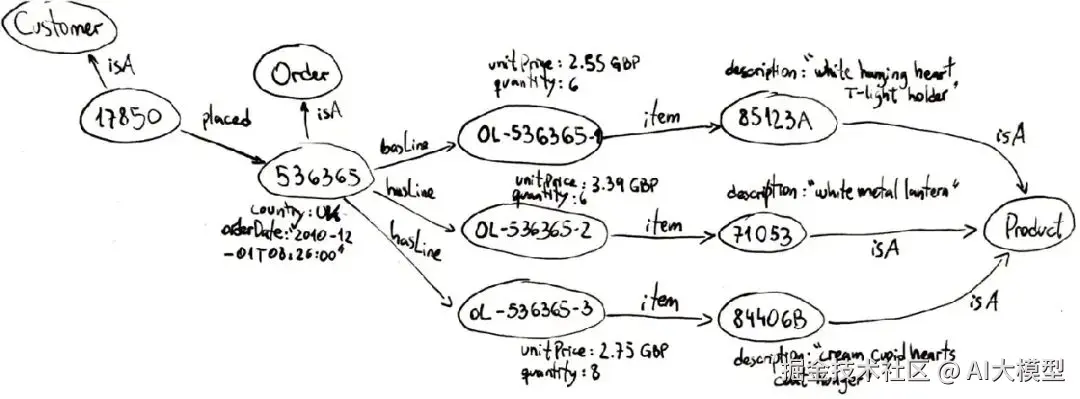
知识图谱 是一种对现实世界知识的网络化表示,图中的每个 node(节点) 代表一个实体,每条 edge(边) 代表实体间的关系。
如上图所示,知识图谱以图的形式组织数据,而不是表格或孤立的文档。这意味着信息天然就捕捉了联系。一些关键特点:
知识图谱通常存储在专门的 graph databases(图数据库) 或 triplestores(三元存储) 中。这些系统专为存储节点和边、运行图查询而优化。
知识图谱的结构对 AI 系统(尤其在 RAG 场景中)是个大加分项。因为事实是相互关联的,LLM 能拿到一整个相关信息的网络,而不是孤立的片段。这意味着:
总结来说,知识图谱为 AI 的上下文注入了意义。它不是把数据当一堆词袋处理,而是当作一个知识网络。这正是我们希望 AI 在回答复杂问题时拥有的:一个可以导航的、丰富的关联上下文,而不是每次都要硬解析一堆文档。
现在我们了解了知识图谱是什么,以及它如何助力 AI 系统,接下来看看 ontologies(本体论) 是什么,以及它们如何帮助构建更好的知识图谱。
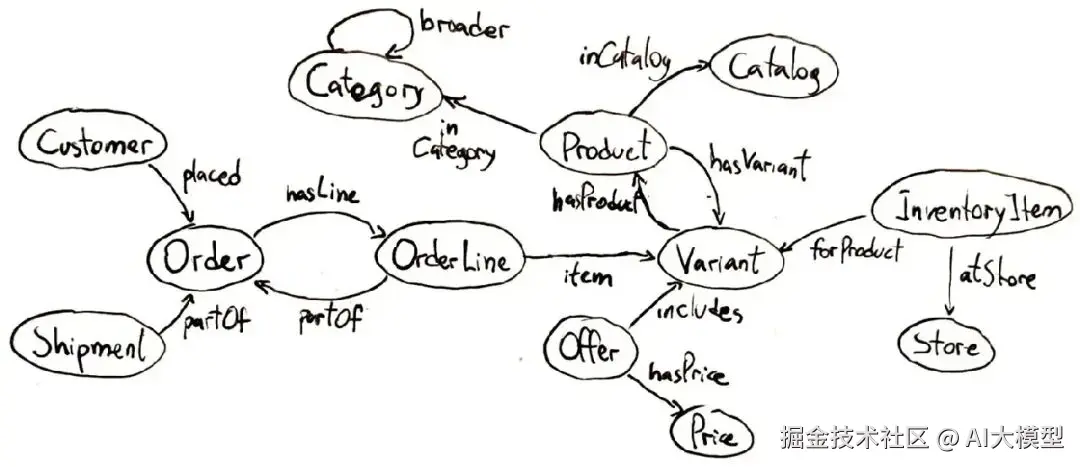
在知识系统的语境中,ontology(本体论) 是一个特定领域的知识的正式规范。它定义了该领域中存在的实体(或概念)以及这些实体之间的关系。
本体论通常将概念组织成层级或分类体系,但也可能包含逻辑约束或规则。比如,可以声明“每个订单必须至少包含一个产品项目”。
为什么本体论重要?你可能会问。本体论为一个领域提供了共享的理解,这在整合多个来源的数据或构建需要推理该领域的 AI 系统时特别有用。通过定义一组通用的实体类型和关系,本体论确保不同团队或系统用一致的方式指代事物。比如,如果一个数据集把人叫“Client”,另一个叫“Customer”,通过映射到同一个本体论类(比如 Customer 作为 Person 的子类),就能无缝合并这些数据。
在 AI 和 GraphRAG 的语境中,本体论是知识图谱的蓝图——它决定了图中会有哪些节点和链接。这对复杂推理至关重要。如果你的聊天机器人知道在你的应用中“Amazon”是一个 Company(公司) (而不是河流),而 Company 在本体论中有定义(包含 headquarters、CEO 等属性,以及 hasSubsidiary 等关系),它就能更精确地锚定答案。
现在我们了解了知识图谱和本体论,来看看如何把它们整合进类似 RAG 的流程中。
GraphRAG 是传统 RAG 的进化版,它明确将知识图谱纳入检索过程。在 GraphRAG 中,用户提问时,系统不只是对文本做向量相似性搜索,还会查询知识图谱中相关的实体和关系。
我们来高层次地走一遍典型的 GraphRAG 流程:
在底层,GraphRAG 可以用多种策略整合图查询。系统可能先做常规的语义搜索,找 top-K 文本块,然后遍历这些块的图邻居以收集额外上下文,再生成答案。这确保了即使相关信息分散在不同文档中,图也能把它们拉到一起。在实际中,GraphRAG 可能涉及额外步骤,比如 entity disambiguation(实体消歧) (确保问题中的“Apple”链接到正确的节点,可能是公司或水果)和图遍历算法来扩展上下文。但总体思路如上:搜索 + 图查询,而不只是搜索。
对非技术读者来说,你可以把 GraphRAG 想象成给 AI 增加了一个“类脑”知识网络,除了文档库之外。AI 不再孤立地读每本书(文档),而是有一本事实及其关联的百科全书。对技术读者来说,你可以想象一个架构,里面既有向量索引又有图数据库,两者协同工作——一个检索原始段落,另一个检索结构化事实,都喂进 LLM 的上下文窗口。
构建支持 GraphRAG 系统的知识图谱有两种主要方法:Top-Down(自上而下) 和 Bottom-Up(自下而上) 。它们不完全互斥(通常会混用),但区分它们有助于理解。
自上而下的方法从定义领域的本体论开始,由领域专家或行业标准建立类、关系和规则。这个模式加载到图数据库中作为空的框架,指导数据提取和组织,相当于一个蓝图。
一旦本体论(模式)就位,接下来是用真实数据填充它。有几种子方法:
关键在于,自上而下的方法中,本体论在每一步都起到指导作用。它告诉提取算法要找什么,确保输入的数据符合一个连贯的模型。
使用正式本体论的一大优势是你可以利用 reasoners(推理器) 和 validators(验证器) 保持知识图谱一致性。本体论推理器可以自动推断新事实或检查逻辑矛盾,而像 SHACL 这样的工具可以强制执行数据形状规则(类似更丰富的数据库模式)。这些检查能防止矛盾事实,并通过自动推导关系丰富图。在 GraphRAG 中,这意味着即使多跳连接不明确,本体论也能帮助推导出来。
自下而上的方法直接从数据生成知识图谱,不依赖预定义的模式。NLP 和 LLM 的进步让从非结构化文本中提取结构化三元组成为可能,这些三元组随后被输入图数据库,实体成为节点,关系成为边。
在底层,自下而上的提取可以结合传统 NLP 和现代 LLM:
有像 spaCy 或 Flair 这样的传统方法库,也有整合 LLM 调用的新库用于 IE(信息提取) 。另外,像 ChatGPT 插件 或 LangChain 代理 这样的技术可以设置来填充图:代理可以逐个读取文档,找到事实时调用“图插入”工具。另一个有趣的策略是用 LLM 通过读取文档样本建议模式(这有点像本体论生成,但自下而上)。
自下而上提取的一个大问题是,LLM 可能不完美,甚至会“创造性”输出。它们可能瞎编一个不存在的关系,或错误标记一个实体。因此,验证很重要:
这个过程通常是迭代的。你运行提取,找到错误或缺失,调整提示或过滤器,再运行一次。久而久之,这能大幅提高知识图谱的质量。好消息是,即使有些错误,知识图谱对很多查询仍然有用——你可以优先清理对用例最重要的部分。
最后,记住,发送文本进行提取会将你的数据暴露给 LLM/服务,所以要确保符合隐私和保留要求。
构建 GraphRAG 系统听起来可能有点复杂,你得管理向量数据库、图数据库、运行 LLM 提取流程等。好消息是,社区正在开发工具让这事变得更简单。我们来简单提一些工具和框架,以及它们的作用。
首先,你需要一个地方存储和查询知识图谱。传统的图数据库如 Neo4j、Amazon Neptune、TigerGraph 或 RDF triplestores(如 GraphDB 或 Stardog)是常见选择。
这些数据库专为我们讨论的操作优化:
在 GraphRAG 设置中,检索流程可以用这些查询来获取相关的子图。一些向量数据库(像 Milvus 或带 Graph 插件的 Elasticsearch)也开始整合类图查询,但通常专用图数据库提供最丰富的功能。重要的是,你的图存储要能高效检索直接邻居和多跳邻居,因为复杂问题可能需要抓取整个事实网络。
一些新工具正在将图与 LLM 结合:
重点是,如果你想尝试 GraphRAG,不用从零开始。你可以:
总之,虽然 GraphRAG 处于前沿,但周边生态正在快速成长。你可以利用这些库和服务快速搭建原型,然后迭代优化知识图谱和提示。
传统 RAG 适合简单的事实查询,但在需要深入推理、准确性或多步回答的查询上会吃力。这时 GraphRAG 就大显身手了。通过结合文档和知识图谱,它用结构化事实锚定回答,减少 hallucinations(瞎编) ,支持多跳推理,让 AI 能以标准 RAG 无法做到的方式连接和综合信息。
当然,这种能力也有代价。构建和维护知识图谱需要模式设计、提取、更新和基础设施开销。对于简单用例,传统 RAG 仍是更简单高效的选择。但当需要更丰富的回答、一致性或 explainability(可解释性) 时,GraphRAG 的优势显而易见。
展望未来,知识增强的 AI 正在快速发展。未来平台可能直接从文档自动生成图,LLM 直接在图上推理。对于像 GoodData 这样的公司,GraphRAG 将 AI 与分析结合,带来超越“发生了什么”到“为什么发生”的洞察。
最终,GraphRAG 让我们更接近于不仅能检索事实,还能真正理解和推理事实的 AI,就像人类分析师,但规模和速度更大。虽然这条路有复杂性,但目标(更准确、可解释、更有洞察力的 AI)绝对值得投资。关键不仅在于收集事实,而在于连接它们。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。

