
百变躲猫猫中文版
94.77MB · 2025-12-01

这篇文章来源于我最近在接触响应式编程,了解到reactive streams的规范。发现里面的好多术语,或者概念我完全无法理解。但是总是在不经意间的灵光乍现,想到一些比较奇怪的想法,我怕这种感觉会消失,所以记录下来那一瞬间我的真实想法。也就是此时此刻,我对响应式的一些认知。或许随着时间的推移,这种感觉会被推翻,但是我想记录下我的成长历程。
在接触了project Reactor之后呢 我总是听到类似这样的内容:开发者不需要自己管理线程,reactor会有调度器帮我们自动管理。但是我是理解不上去的,任务在哪个线程执行,什么时候执行,啥叫调度啊。一时间很多概念闯进来。
在异步编程中,调度 指的是:
比如我们在webflux中总是写下面的这段代码:
Mono.just("Hello") .map(s -> s + " World") .subscribe(System.out::println);
.map()中的代码 和 System.out::println 是你要执行的逻辑。Scheduler 是 Reactor 提供的一个 抽象接口,用来:
你可以把它理解为 Java 中 ExecutorService 的响应式版本。
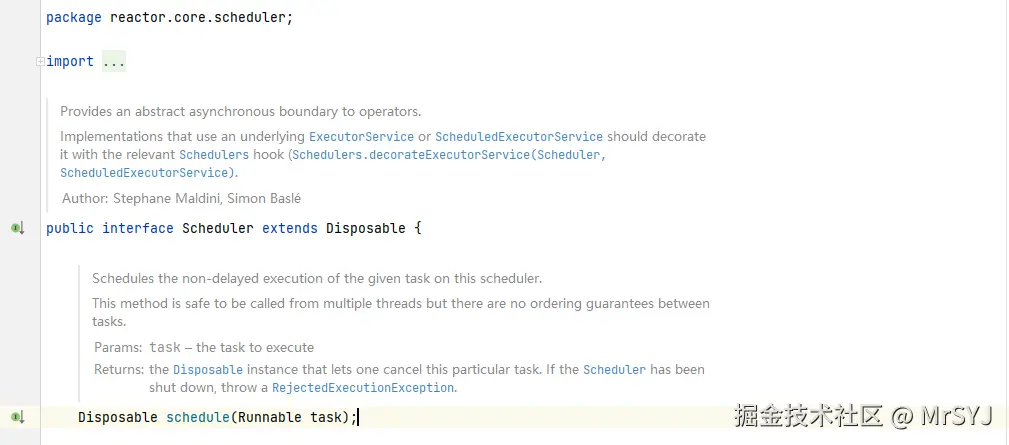
我去源码中截了个图片:看到了Scheduler中的schedule方法签名,就是接收个Runable的任务,将来我去调度到某个线程中去执行,但是具体实现交给实现类了。这是顶级抽象。
所以我们去把任务去调度的时候,总是调用类似下面的代码。
Mono.just("data")
.map(a -> processInThread1(a)) // 阶段1
.publishOn(Schedulers.parallel()) // 切换点
.map(b -> processInThread2(b)) // 阶段2
.subscribe(System.out::println); // 阶段3
publishOn(Schedulers.parallel()): 通过名称我们来分析这个方法的意思就好像是说 把数据发布到Scheduler指定的线程。
我们来说说publishOn。首先我应该能清楚的是,每一个算子都是一个publisher,因为它是链式调用的嘛,所以数据经过一个算子之后,一定要往下流。并且作为中间的算子,它本身是没有数据的,数据来源于上游。所以每个算子的内部要封装了一个Subscriber.因为在reactive streams规范中,数据是publisher通过onNext向下传递的。
Reactor 内部会构建一个 订阅链(Subscriber Chain),“订阅链”本质上是一个由 Subscriber 构成的“回调链表” ,数据要想从头向下流动,肯定是要进行订阅的,订阅就需要订阅者。所以我们平常用的操作符(如 map、filter)都包装一个 Subscriber,当你调用 .subscribe() 时,它从链的末端开始,逐级向上游触发 .subscribe() ,形成“向上订阅”。
Mono.just("hello")
.map(s -> s + "-1")
.map(s -> s + "-2")
.subscribe(System.out::println);
每个操作符都返回一个新的 Mono,当你调用map的时候。
Reactor 内部做了什么?
// 伪代码:map 操作符的实现
public final <R> Mono<R> map(Function<? super T, ? extends R> mapper) {
return new MonoMap<>(this, mapper); // 返回一个新的 Mono
}
this 是上游的 Mono(比如 Mono.just),就是调用.map的那个对象,那肯定就是上游的mono实例
MonoMap 是一个包装类,它持有:
sourcemapper所以整个链就变成了如下的感觉:
Mono<String> source = new MonoJust<>("hello");
Mono<String> mapped1 = new MonoMap<>(source, s -> s + "-1");
Mono<String> mapped2 = new MonoMap<>(mapped1, s -> s + "-2");
所以最底层的mapped2,持有了上层的mapped1,而mapped1持有了上层的source
结构如下:从底层逐渐走向上层。这就是向上订阅
mapped2 → mapped1 → source
当你调用:
mapped2.subscribe(System.out::println);
mapped2(即 MonoMap)创建一个自己的 Subscriber,因为它作为一个中间算子,虽然是一个publisher(因为Mono和Flux都是数据的发布者),那么它就要发布数据,数据从哪里来呢,肯定是从上游过来。这就决定了每个算子的内部都要包装一个subcriber.
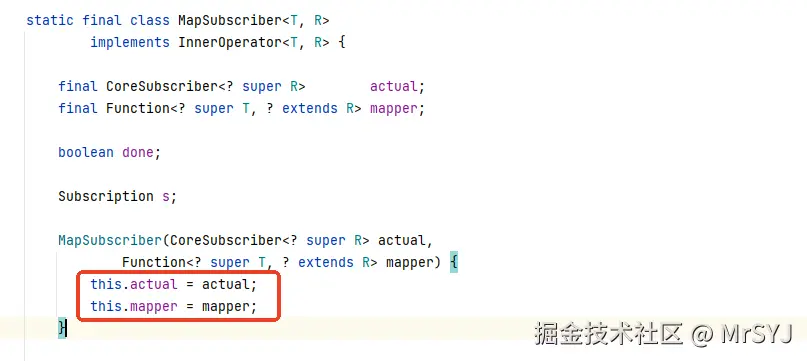
MonoMap 长什么样?class MonoMap<T, R> extends Mono<R> {
final Publisher<T> source; // 上游的 Publisher
final Function<T, R> mapper; // 当前 map 函数
public void subscribe(Subscriber<? super R> actual) {
// actual 是下游的 Subscriber
MapSubscriber<T, R> parent = new MapSubscriber<>(actual, mapper);
source.subscribe(parent); // 向上游发起订阅
}
}
所以 MonoMap 的作用是:
Subscriber----actualMapSubscriberMapSubscribermapped2(即 MonoMap)创建一个自己的 Subscriber// 在 MonoMap(mapper2) 中
Subscriber<? super R> actual = System.out::println;
// 创建一个 MapSubscriber,它会执行 mapper2,并把结果传给 actual
MapSubscriber<T, R> parent = new MapSubscriber<>(actual, mapper2);
// parent 的作用:拿到数据 → 执行 s -> s + "-2" → 传给 System.out::println
// 向上游订阅:让 mapped1 去订阅 parent
source.subscribe(parent); // source = mapped1
这里有几点说明
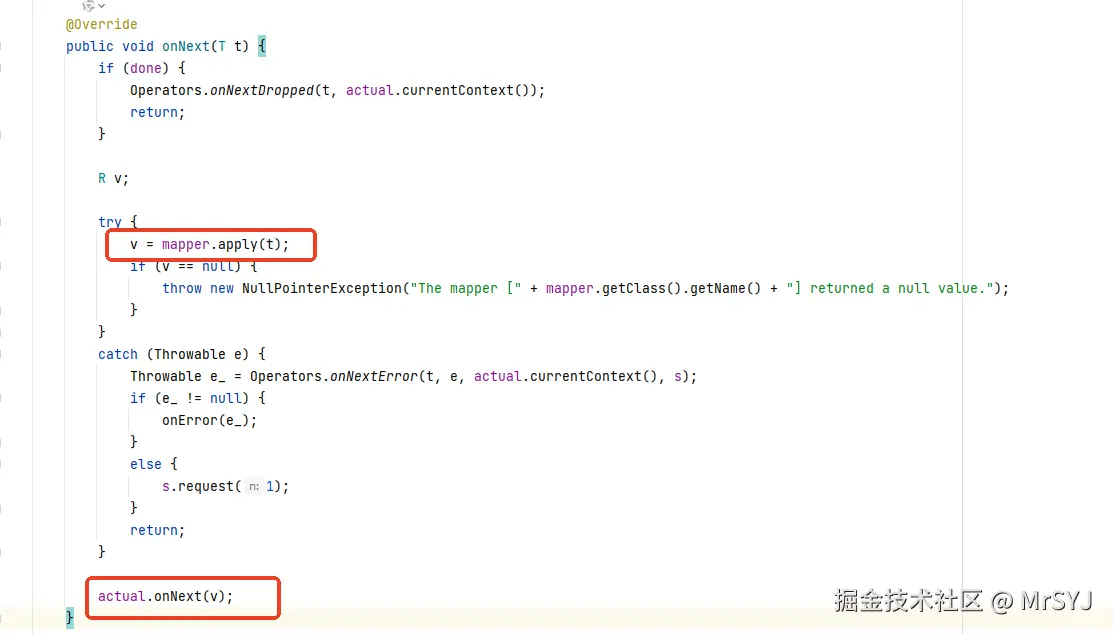
下面的代码就截取自FluxMap中的MapSubscriber,它的作用就是上游数据来的时候,先mapper,再把mapper的结果传递给下游
mapped1 接到订阅,继续向上// mapped1 的 subscribe()
public void subscribe(Subscriber<? super T> actual) {
// actual = MapSubscriber(println, mapper2)
MapSubscriber<T, R> parent = new MapSubscriber<>(actual, mapper1);
source.subscribe(parent); // source = MonoJust("hello")
}
MonoJust 最终被订阅// MonoJust的subscribe()
public void subscribe(Subscriber<? super T> actual) {
// actual = MapSubscriber(MapSubscriber(println, mapper2), mapper1)
// 直接触发数据流
actual.onSubscribe(Operators.emptySubscription());
actual.onNext(value); // "hello"
actual.onComplete();
}
源头触发:
actual.onNext("hello");
此时的 actual 是最上游的 MapSubscriber,它的 onNext 实现是:
// MapSubscriber.onNext()
public void onNext(T t) {
R mapped = mapper.apply(t); // 执行 map 函数
actual.onNext(mapped); // 向下游传递
}
所以流程是:
MonoJust: onNext("hello")
↓
MapSubscriber1: mapper1("hello") → "hello-1"
↓
MapSubscriber2: mapper2("hello-1") → "hello-1-2"
↓
System.out::println("hello-1-2")
说了这么多 我们发现
Subscriber 的实现类(如 MapSubscriber)。用来去订阅上游发布者的数据Subscriber内部还要包含一个下游的Subscriber,将处理好的数据(mapper)发送给下游的订阅者
