








缘之空安卓版汉化
1435MB · 2025-12-24

大模型学习文档+路线大纲已经导出整理打包了,在 >gitcode ←←←←←←
随着大语言模型(LLM)的不断发展,如何系统化、客观化地对其进行评测与性能对比,已经成为研究与工业落地中不可或缺的一环。传统的模型评测往往聚焦在单一的任务或指标,而在实际应用中,LLM 的表现不仅取决于模型本身,还与推理框架、硬件环境以及参数调优方式密切相关。
本文将结合 EvalScope 开源的大模型评测基座,探索如何完成 LLM Benchmark 流程,并通过实际的性能压测,进一步探索推理框架对模型推理表现的影响。
EvalScope 由阿里巴巴魔搭社区(ModelScope)开源,定位为「大模型全生命周期评估基座」,覆盖通用 LLM、多模态、Embedding、Reranker、CLIP、AIGC(图生文/视频)等全类型模型能力验证与性能压测。
总的来说,EvalScope支持以下特性:
评价基准丰富:内置了多个主流评价基准,包括且不限于:
丰富的场景:单模型评测、竞技场模式、Baseline对比、端到端RAG评测、长推理、吞吐/延迟压测等
多后端支持:Native(自研)、OpenCompass、VLMEvalKit、第三方插件如ToolBench等切换
训练与评测无缝衔接:与ms-swift训练框架无缝衔接,训练完直接evalscope eval出报告
可视化平台:evalscope app一键拉起Gradio WebUI,可视化图的方式实时浏览并交互
在系统架构上,Evalscope使用了模块化设计,组件包括:
Model Adapter -> Data Adapter -> Evaluation Backend -> Performance Evaluator -> Report & Visualization
以上这些组件均借口,可以通过python/cli/web三种入口调用,方便二次开发与私有云集成,进一步丰富了Evalscope的可扩展性。
下面我们通过一个示例快速上手EvalScope如何使用:
conda create -n evalscope python=3.10
# 激活conda环境
conda activate evalscope
# 安装evalscope依赖
pip install evalscope # 安装 Native backend (默认)
# 额外选项
pip install 'evalscope[opencompass]' # 安装 OpenCompass backend
pip install 'evalscope[vlmeval]' # 安装 VLMEvalKit backend
pip install 'evalscope[rag]' # 安装 RAGEval backend
pip install 'evalscope[perf]' # 安装 模型压测模块 依赖
pip install 'evalscope[app]' # 安装 可视化 相关依赖
pip install 'evalscope[all]' # 安装所有 backends (Native, OpenCompass, VLMEvalKit, RAGEval)
# 使用命令行方式开始示例测试:
evalscope eval
--model Qwen/Qwen2.5-0.5B-Instruct
--datasets gsm8k arc
--limit 5
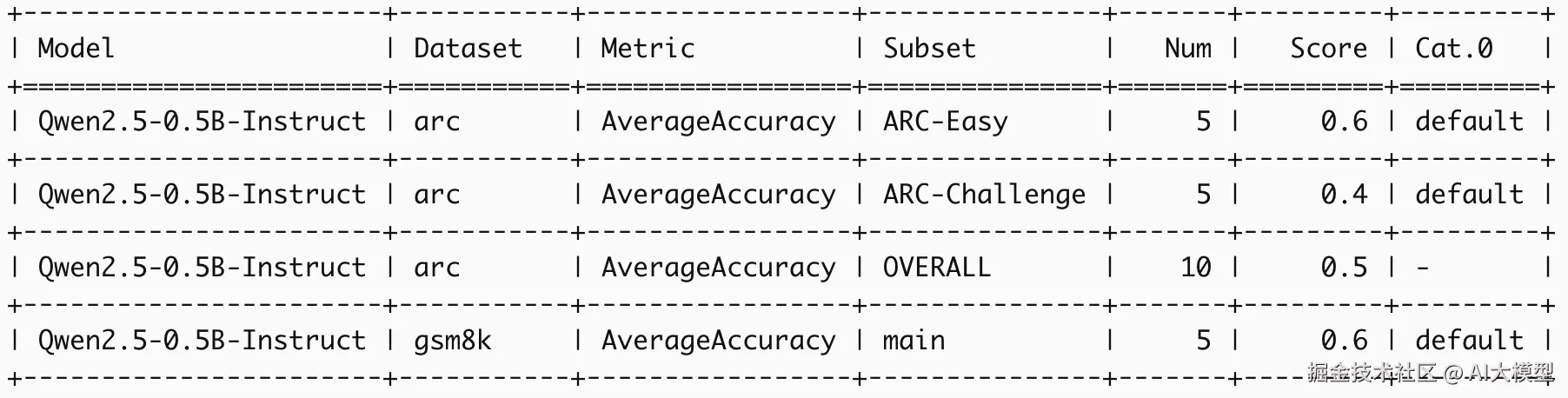
在运行示例测试命令后,便会自动下载模型与数据集,进行测试,并最终以表格的形式展示测试结果,例如:
evalscope也提供了可视化的界面,对测试结果进行可视化展示:
pip install 'evalscope[app]'
# 启动可视化服务
evalscope app
对于已经用了推理框架(例如vLLM、SGLang)部署的模型,EvalScope也支持指定模型推理的API进行测试,例如:
export VLLM_USE_MODELSCOPE=True && python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-0.5B-Instruct --served-model-name qwen2.5 --trust_remote_code --port 8801
# 使用evalscope对模型推理API进行测试
evalscope eval
--model qwen2.5
--api-url http://127.*0**.0.1:8801/v1
--api-key EMPTY
--eval-type service
--datasets gsm8k
--limit 10
接下来我们的目标是测试模型在不同场景下(例如GPU、推理引擎、推理参数等)的性能表现。对于性能测试部门,EvalScope也提供了对应的功能来完成,下面展示基本用法:
对应参数解释:
parallel: 请求的并发数,可以传入多个值,用空格隔开
number: 每个并发请求的数量,可以传入多个值,用空格隔开(与parallel一一对应)
url: 请求的URL地址
model: 使用的模型名称
api: 使用的API服务,默认为openai
dataset: 数据集名称,此处为random,表示随机生成数据集
tokenizer-path: 模型的tokenizer路径,用于计算token数量(在random数据集中是必须的)
extra-args: 请求中的额外的参数,传入json格式的字符串,例如{"ignore_eos": true}表示忽略结束token
在性能评测结束后,会打印每轮测试的结果,以及测试总结,具体指标解释可以参考官方文档具体说明。
模型性能测试的结果可以通过wandb和swanlab进行可视化展示。这里以swanlab为例:
在测试结束后,运行:
swanlab watch -h 0.0.0.0 /home/ubuntu/outputs
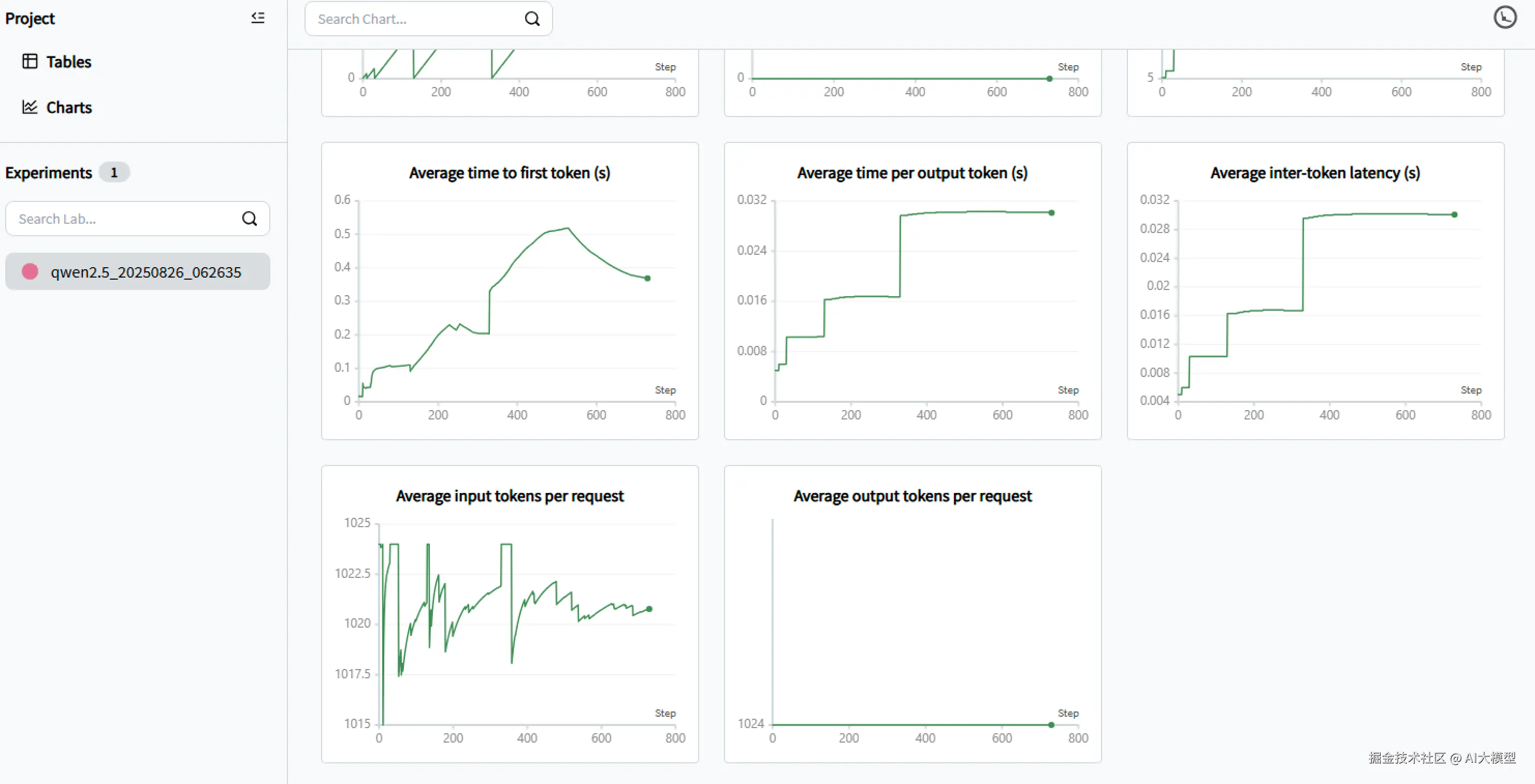
即可提供web访问页面,查看包括可视化结果、统计表格、以及系统、硬件等信息。例如:
在具备了LLM Benchmark的能力后,也就提供对推理框架例如vLLM调优的基础(baseline+benchmark对比)。下面我们开始尝试对vLLM的不同参数进行调优,观察对推理性能的影响。
在这次测试会使用以下环境与参数:
硬件选择:AWS p5.4xlarge实例
模型选择:由于现在主流LLM均在往MoE方向发展,所以测试近期比较热门的gpt-oss-120b(117B参数量,激活参数5.1B),它也能够在单卡H100上运行
常规来说,会从三个大的类别来评测LLM推理表现,包括:
在这个测试场景下,我们仅关注推理的性能效率,具体地说,主要关注以下指标:
TTFT(Time to First Token):处理prompt并生成第一个 token 所需的时间 。也就是用户在看到模型输出之前必须等待的时间。
端到端请求延迟(e2e_latency):在一个请求提交后,到获取到完整返回所用的时间
ITL(Intertoken latency):在一个sequence中,连续token生成的平均间隔时间,也称TPOT(time per output token)
TPS(Tokens per second):推理系统每秒输出token的吞吐,计入了所有并发请求。随着请求数的增加,一般会伴随着系统的总TPS增加,直到达到所有可用GPU计算资源的饱和点,超过该点后,总TPS可能会下降
RPS(Requests per second):在一秒内系统能够处理的平均请求数
对于不同的应用场景,所需要关注的指标也是不一样的。一个应用的具体场景首先决定了其序列的长度,包括输入序列长度ISL(Input Sequence Length)和输出序列长度OSL(Output Sequence Length)。进而影响系统处理输入prompt,生成KV Cache以及生成输出token的速度。
较长的ISL会增加prefill阶段的GPU内存需求,从而增加TTFT延迟。而较长的OSL会增加decode(generation)阶段的GPU内存需求(包括带宽和容量),从而增加ITL延迟。所以在优化推理系统时,仍然要考虑到应用的场景是什么,才能决定关注并优化的指标是什么。
下面是几个常见的应用场景以及ISL/OSL的典型组合:
在指定测试参数时,常规来说,我们会指定并发数、请求数、prompt token数、生成token数等参数。除了这些参数之外,还有些相关的LLM serving参数,它们不仅会影响推理性能,也会影响benchmark的准确性。
大部分LLM都有一个EOS标记,表示生成过程的结束。ignore_eos 参数通常用于指示LLM推理框架是否应该忽略EOS标记,并持续生成标记直到达到 max_tokens 的上限。出于benchmark测试的目的,此参数应设置为 True,以确保达到预期的输出长度,从而获得一致的测量结果。
不同的采样参数(如greedy、top_p、top_k 和 temperature)可能会对LLM的生成速度产生影响。例如,greedy采样直接选择具有最高logit值的token,无需对整个token的概率分布进行归一化和排序,从而节省了计算开销。无论选择哪种采样方法,在同一benchmark测试中保持一致性都是一个良好的实践。
下面我们参考vLLM官方文档[3]部署gpt-oss-120b模型。vLLM官方文档提到针对 gpt-oss 系列模型进行了以下优化:
通过以下命令即可直接通过vLLM部署gpt-oss-120b:
在部署时会遇到下面的报错:
(EngineCore_0 pid=5768) ValueError: To serve at least one request with the models's max seq len (131072), (4.79 GiB KV cache is needed, which is larger than the available KV cache memory (2.47 GiB). Based on the available memory, the estimated maximum model length is 63488. Try increasing gpu_memory_utilization or decreasing max_model_len when initializing the engine. |
|---|
可以尝试增加gpu_memory_utilization(默认为0.9)或减少max_model_len参数值来解决。这里我们通过增加gpu_memory_utilization解决:
| vllm serve openai/gpt-oss-120b --served-model-name gpt-oss-120b --trust_remote_code --gpu_memory_utilization 0.95 --port 8801 --async-scheduling |
|---|
部署后GPU内存使用情况为:79449MiB / 81559MiB
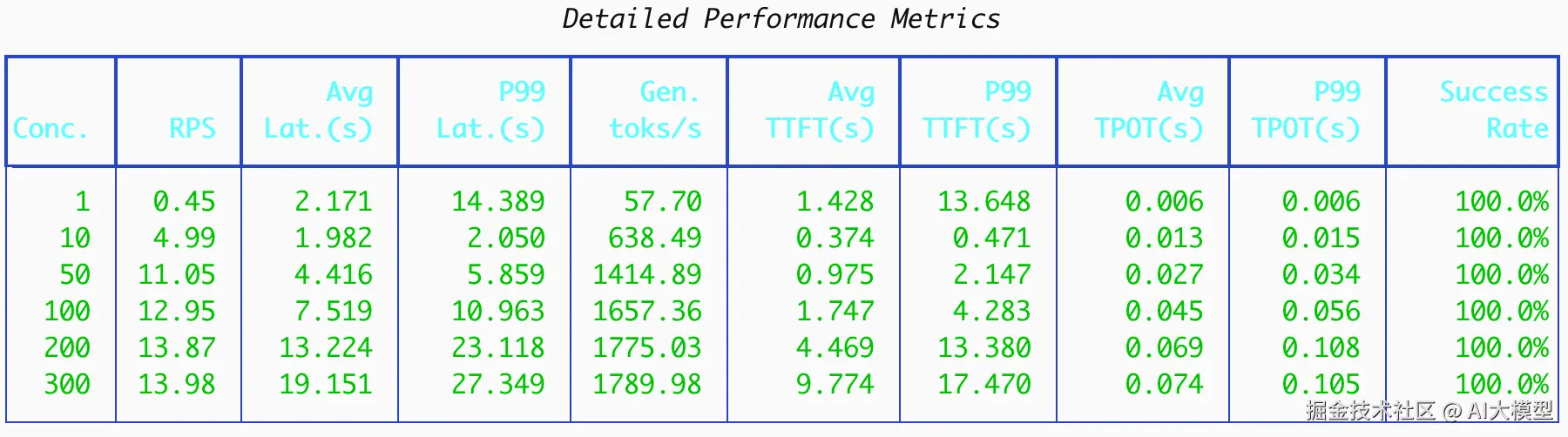
在部署完gpt-oss-120b后,我们选择Summarization作为应用场景,也就是ISL远长于OSL的场景(假设ISL : OSL = 1024 : 128)。首先做一个基准测试作为baseline:
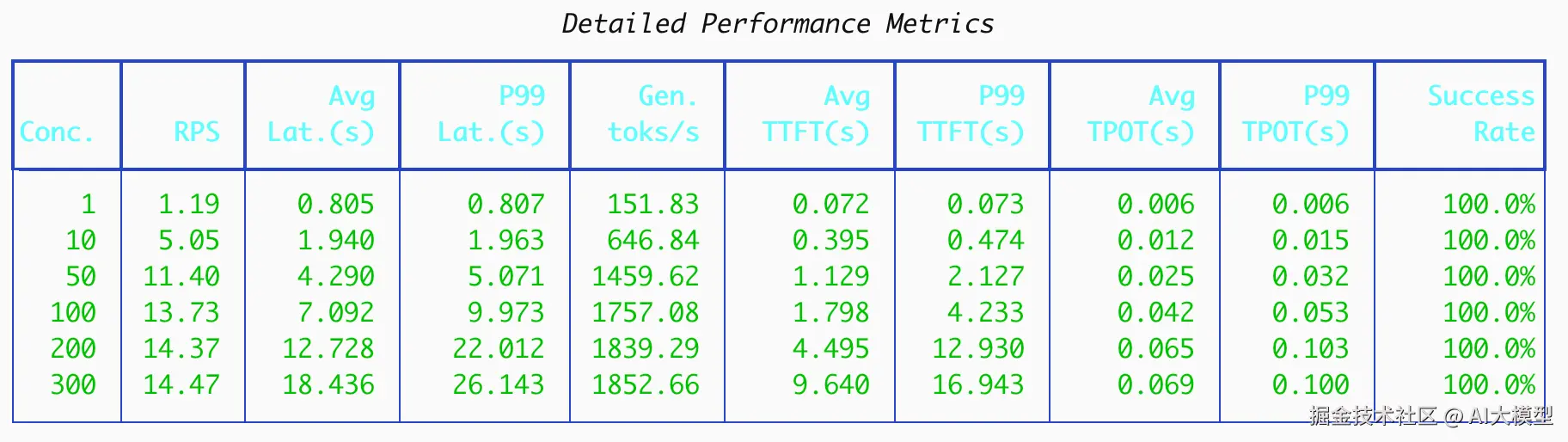
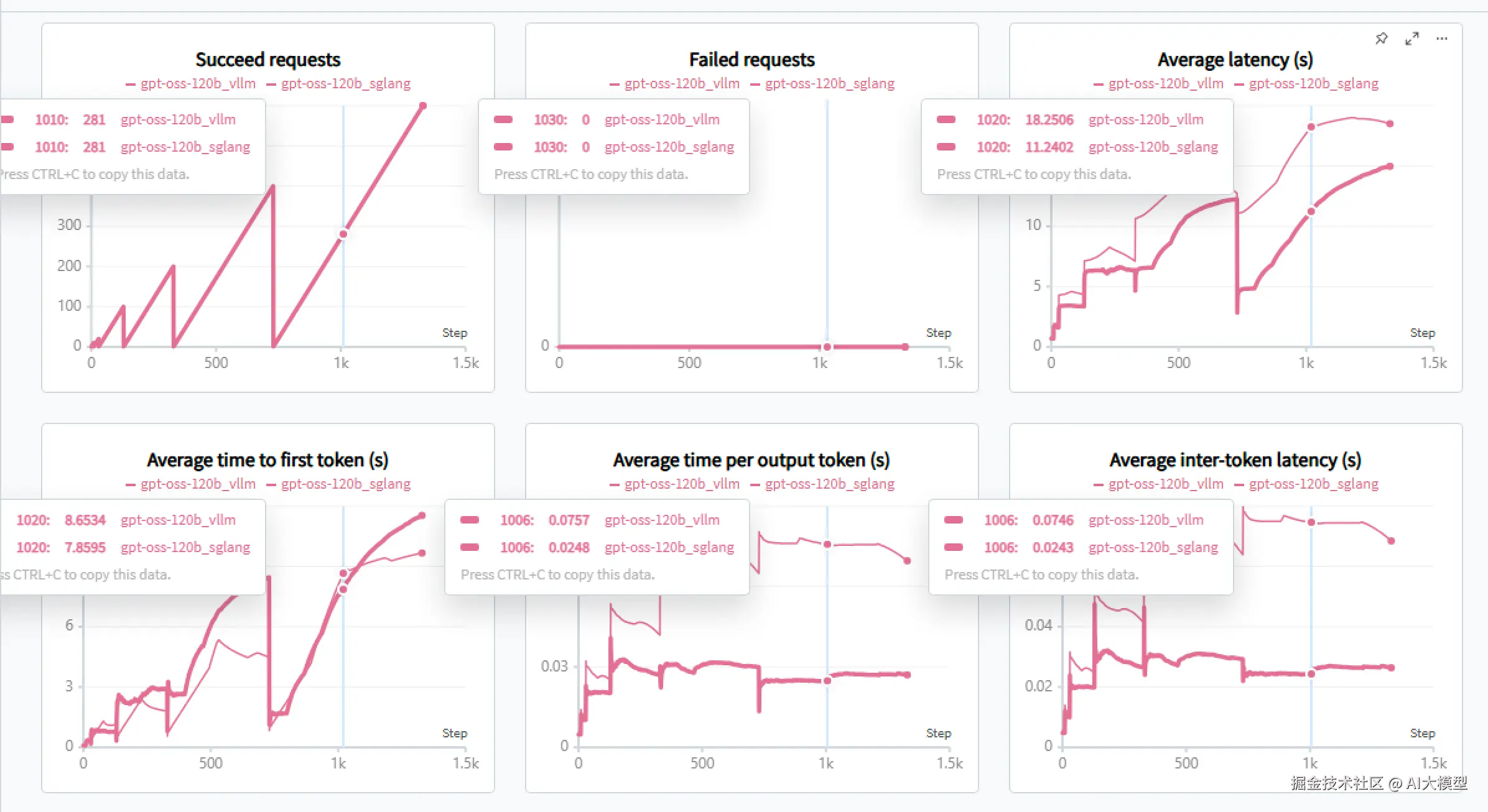
在这个配置下,prompt length=1024,output length=128。下面是整体的结果:
从这个图里我们可以得到几个结论:
随着并发不断升高,RPS先快速提升,最终在200-300并发之间达到吞吐饱和。在300并发下,RPS和token生成速度基本不变的情况下,平均延迟与p99延迟仍然在上升,请求排队时间变长
随着并发不断升高,TTFT成为主要瓶颈
TPOT相对稳定,随着并发的上升,恶化程度远小于TTFT和延迟。
生成的吞吐表现不错,在单卡H100上,基于达到最高1852 token/s。其趋势与RPS基本保持一致,也说明了在200-300并发时,系统处理生成任务能力也接近了上限
在baseline测试中,可以看到在Summarization的场景下,相比TPOT来说,TTFT是一个非常明显的瓶颈。接下来我们尝试是否可以优化TTFT。
在vLLM V1版本中,chunked prefill是默认启动的。这个功能的意思是将长prefill请求切分为更小的chunk,然后与其他的decode请求一起进行调度。这个功能可以更好地平衡prefill(计算需求高)与decode(内存需求高)的操作,继而提升吞吐与延迟表现,特别是在混合负载。
下面我们关闭chunked prefill,使其对一个请求先做prefill完成后,再进行decode:
然后继续进行一轮perf测试后,统计的各项指标基本没有任何改进,甚至稍微有一点点下降:
通过对比swanlab的可视化结果细节,也同样基本没有区别。
async-scheduling是一个实验性质的功能,这有助于降低 CPU 开销,从而改善延迟和吞吐量。然而,异步调度目前不支持某些功能,例如结构化输出、推测解码和流水线并行。
测试后的结果如下:
可以看到,关闭async-scheduling后,无论是RPS、Latency还是TTFT,这些指标都出现不同程度的下降,说明异步调度无论是在低并发还是高并发的情况下,都是有必要启用的。
在继续尝试了多种vLLM提供的各类参数后(例如--max-num-batched-tokens、--max-num-seqs等),我们仍然无法达到比第一次表现更好的测试。而在vLLM官方文档中提到的优化部分(例如并行策略、输入处理以及多模态Caching),均不适用于这次测试。从目前的情况来看,说明vLLM默认对单卡gpt-oss-120b已经做了相对不错的优化。
下面我们再基于监控继续探索在测试过程中的各项指标,首先部署grafana与prometheus:
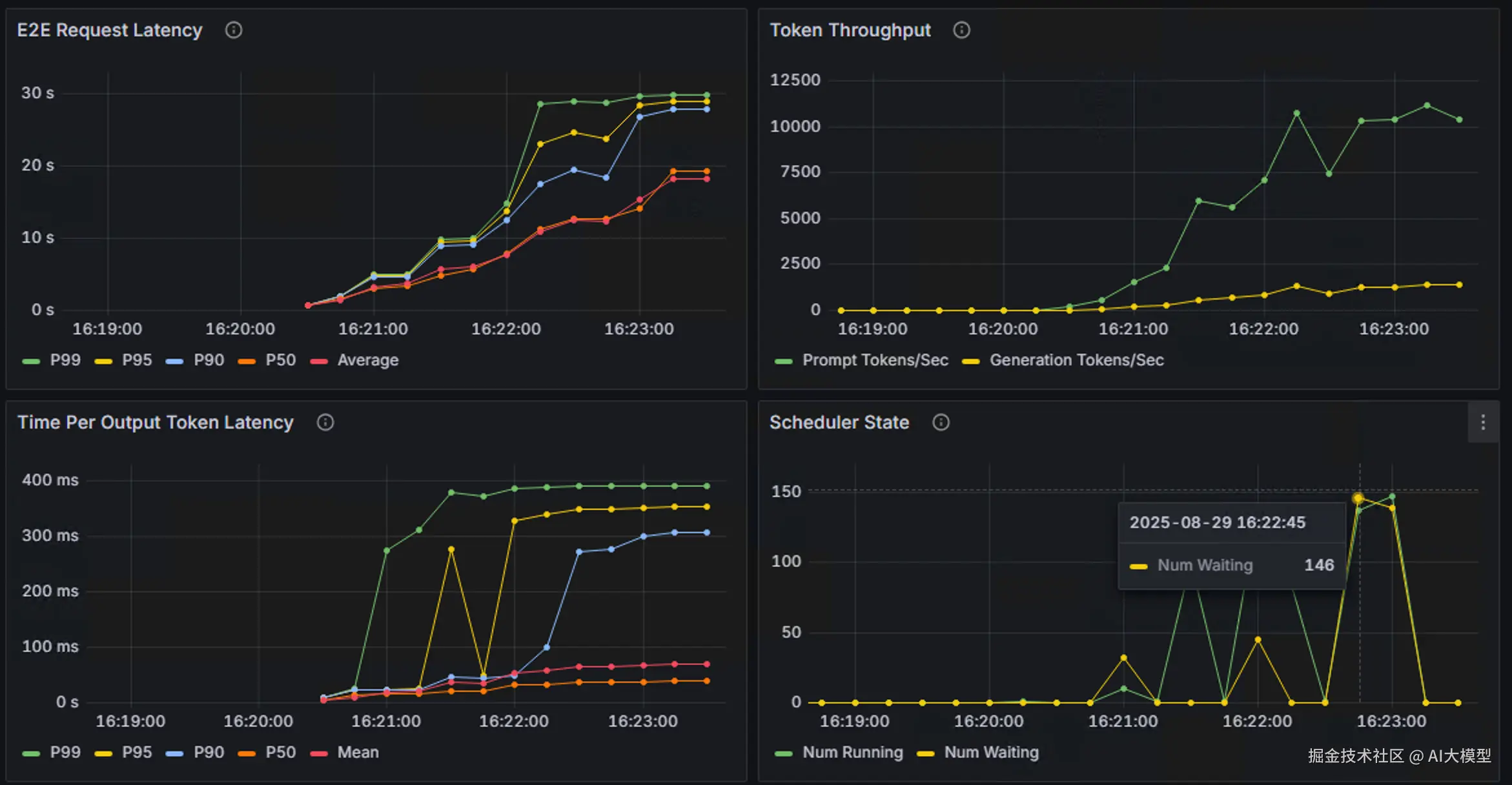
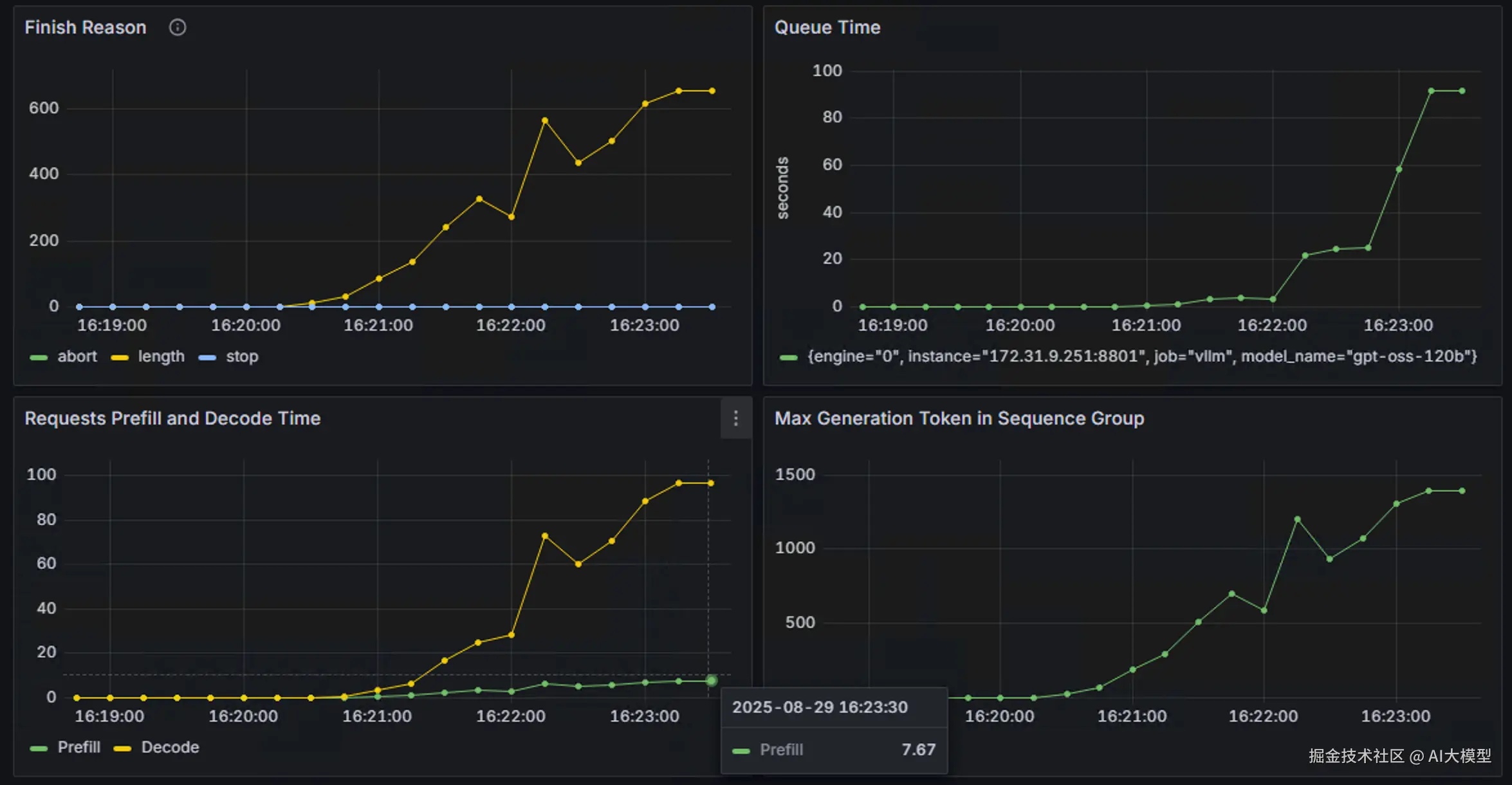
然后参考官方文档[6]配置grafana dashboard,并再次运行测试。得到如下部分监控结果:
从监控中可以看到,从端到端的延迟以及token输出延迟指标来看,p50和平均值基本一致,而p90,p95和p99超出了许多,原因主要是由于在高并发后大量请求排队导致。这也符合高并发下的预期表现。
回到顶部
在了解了gpt-oss-120b在单卡H100和vLLM推理框架下的summarization场景表现后,我们继续看看sglang上的表现。
在OpenAI gpt-oss开源模型后,sglang也在第一时间进行了集成,可以参考官方github进行部署[7]。使用默认参数部署时,同样会遇到与vLLM部署时同样的OOM问题。解决方法也一样,增加分配的GPU mem比例即可,如下命令所示:
| python3 -m sglang.launch_server --mem-fraction-static 0.95 --model openai/gpt-oss-120b |
|---|
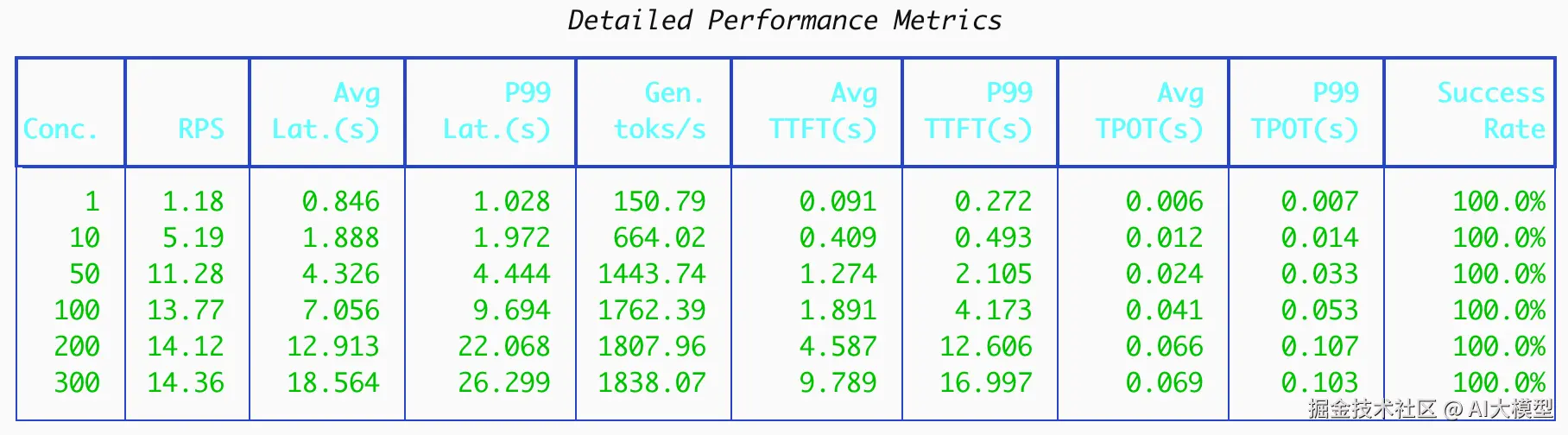
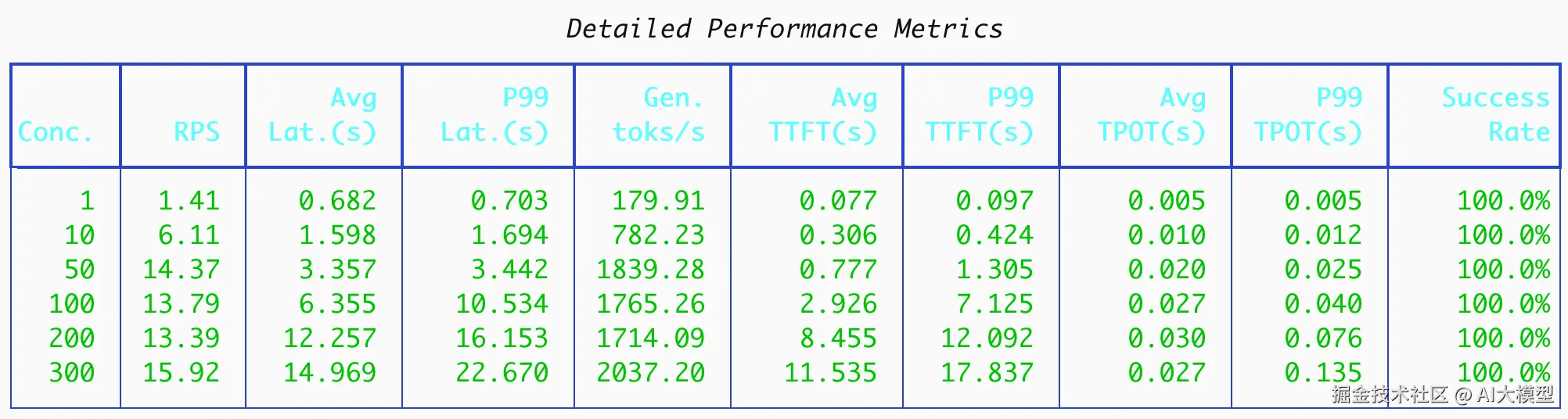
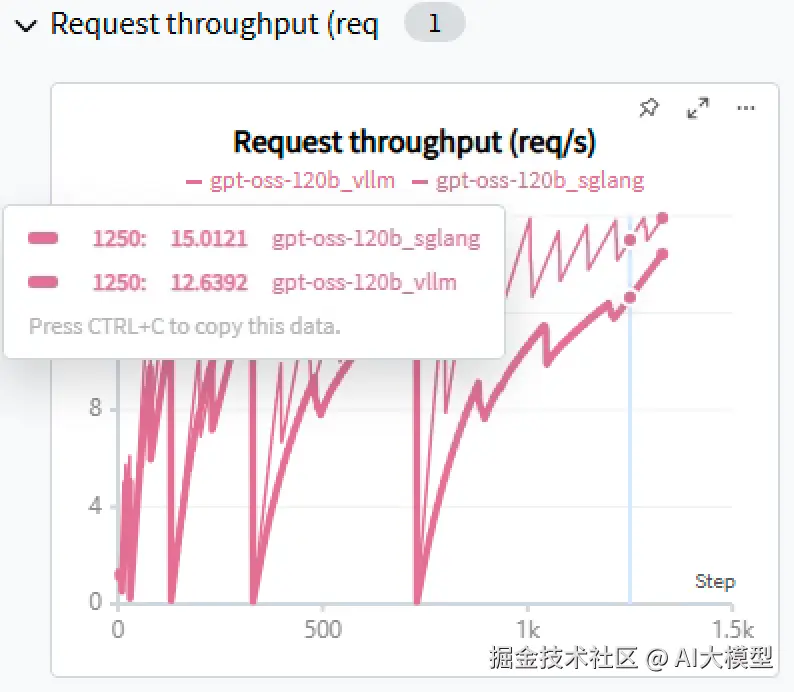
部署后运行与vLLM同样的测试,得到如下结果:
再次运行vLLM测试后,对比两者结果:
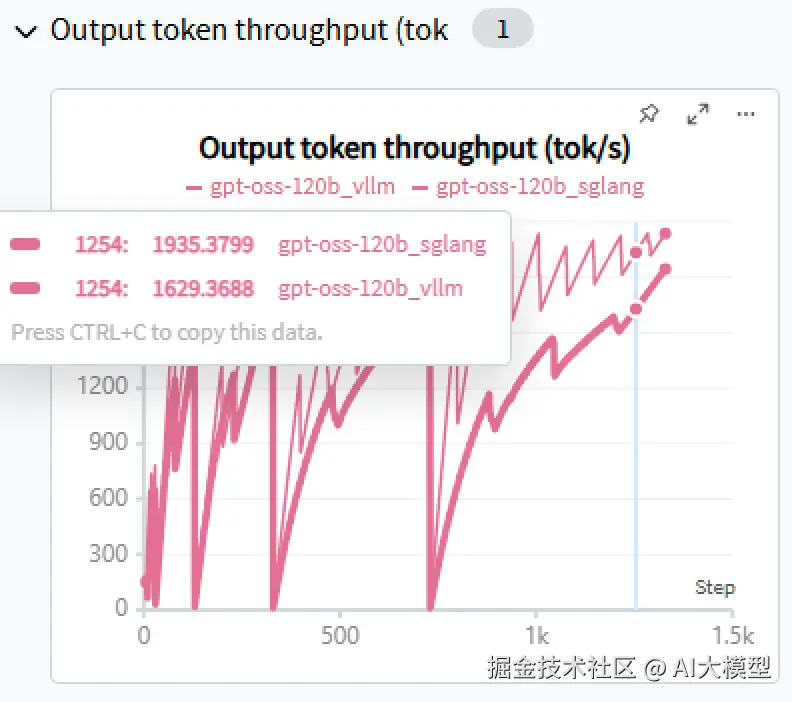
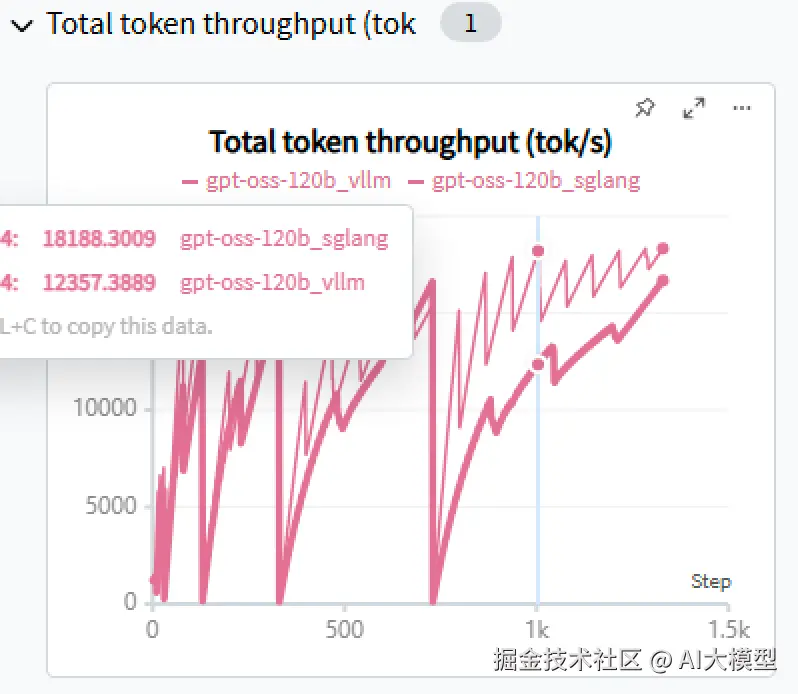
可以看到,在当前场景下:SGLang整体表现优于vLLM。且随着并发升高,SGLang的吞吐也相较vLLM有更大的提升。
本文介绍了EvalScope 在大模型评测中的优势与应用场景,也通过示例展示了其在多维度 Benchmark、性能压测与可视化分析中的能力。在此基础上,我们还对 vLLM 的推理性能表现进行了实验,验证了不同参数配置对延迟、吞吐与并发表现的影响。
总体来看,EvalScope 为研究者和工程师提供了一套 开箱即用、可扩展、可对接推理框架 的完整评测工具链,降低了构建 Benchmark 与性能分析的门槛。而结合 vLLM 等推理框架的实验结果,也为 LLM 的实际落地提供了有价值的调优参考。
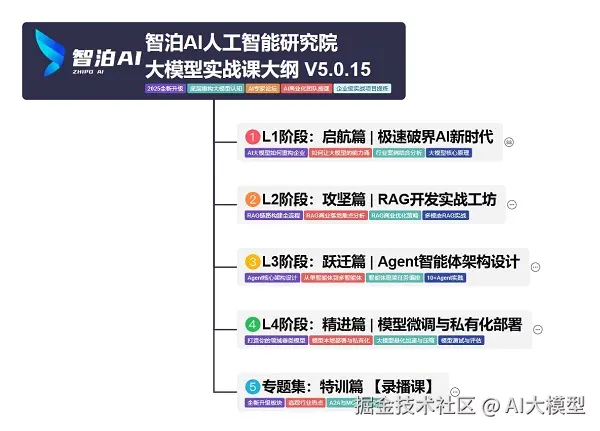
我使用PlantUML绘制了一份技能树脑图,把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。
这份学习路线大纲已经导出整理打包了,在 >gitcode ←←←←←←
总结:学习路径建议从 理论 -> 编程 -> 算法 -> 工程 逐步深入。在实践中,这些板块的能力是相辅相成、缺一不可的。对于大模型时代,Transformer的理解和模型部署优化的工程能力尤为关键。
这份学习路线大纲已经导出整理打包了,在 >gitcode ←←←←←←

