
后宫大酒店0.8汉化安卓版
15.23MB · 2025-12-25


近些年来,医院向数字化转型的速度极快,数据库这块“地基”非常关键,选型是否稳定,使用起来是否顺手,后期能否控制得住,这些都会影响到整个医院信息系统的根基。本文不过多阐述抽象概念,而是站在医院立场,用简单易懂的语言探讨电科金仓数据库如何切实落地,包含从国产化迁移以确保系统稳定运行的具体办法与步骤,并附上一些现成的SQL语句,这样一线工作人员在模仿操作时会更为便捷。
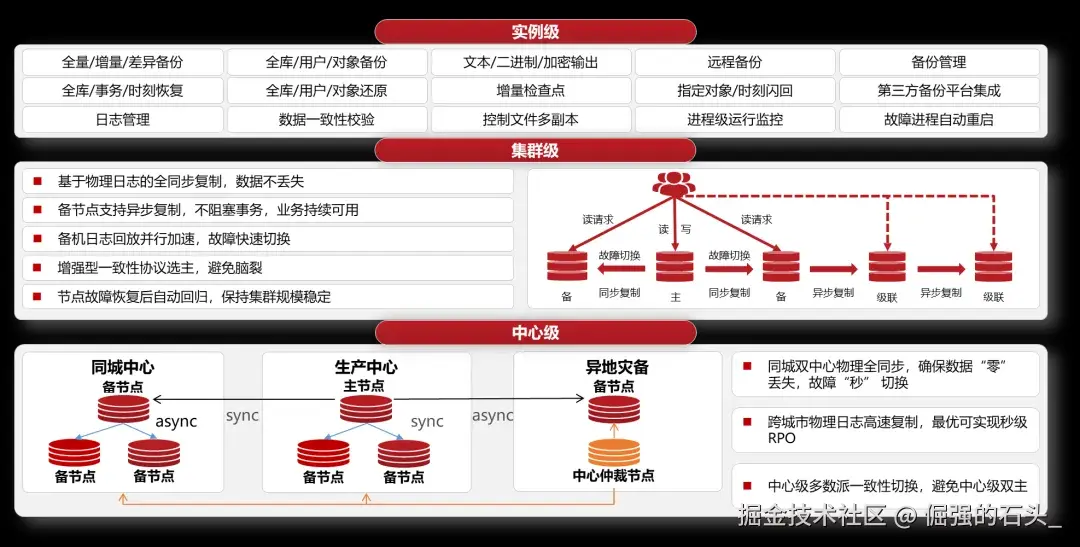
据公开资料,金仓数据库,已被许多三甲医院核心系统采用,云HIS,LIS,PACS,EMR等重要业务均有其应用实例,该产品已通过EAL4 + 这种高级别安全认证,具备主备,高可用,多活等架构能力,还附带一套包含迁移和同步功能的工具,在医疗这个关键领域,其基本形成了一套较为完善的国产化替代方案。

第一步为适配阶段,此时期老系统居于核心地位,金仓则作为辅助存在,利用即时同步工具将老系统中的数据复制到金仓端,使得两者的数据内容相一致,之后可以将部分查询请求转向金仓处理,也可以借助其执行压力检测,考察其适配情况及性能表现是否良好。
第二步是试运行阶段,在此将金仓设为关键角色,老系统沦为备选方案,而且,要反向调整数据同步方向,即由金仓向老系统执行同步操作,如此一来,若金仓端出现意外状况时,便能够及时切换至老系统以维持业务正常运作。
第三步是正式上线,试运行没有问题的话就可以正式“转正”,也就是下线老系统,并完善好相关的监测,审查以及应急演习等工作,之后就进入到长期稳定的运行及改进阶段。
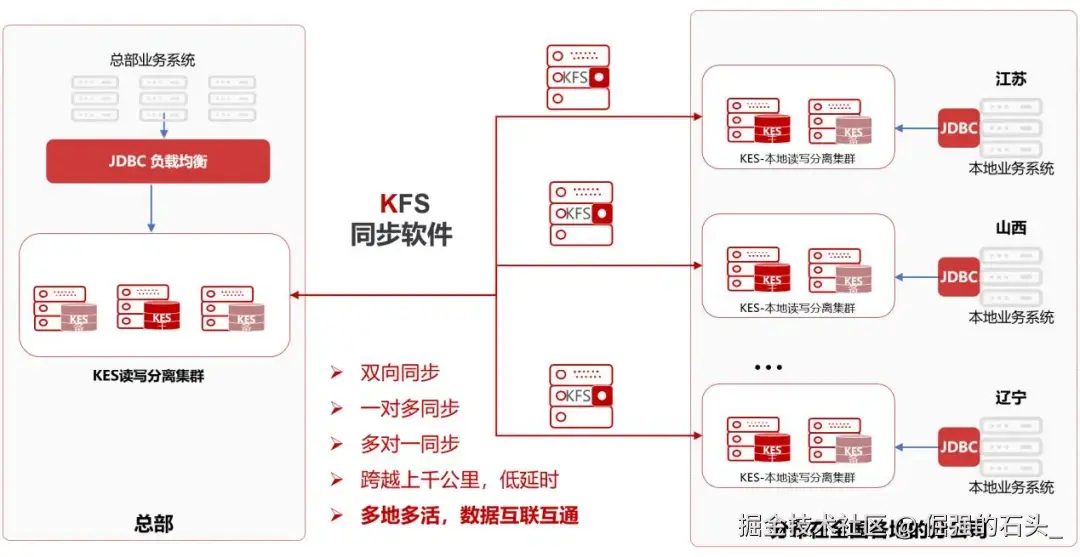
KFS同步工具的“杀手锏”在于此,这个被称作KFS的同步软件到底有何特别之处?其可自动判别源数据库为单机亦或是集群,并且具备自主应对主备切换的能力,无需人工干预,面对网络抖动情形时,具备断点续传功能,而且能够随时核查数据准确性,不论是执行一对多,多对一或者更为繁杂的同步任务,它均能从容应对,在我们推行“双轨并行”策略期间,该软件充当着正向与反向同步的主要力量,是所谓“后悔药”的核心所在。
KRplay回归验证的“实战演习”这种说法,其中的KRplay这个工具就是前面提到的“模拟考”神器,它会把老数据库里真实业务请求录制下来,并在金仓上直接运行一遍,从而帮你预先找到那些潜藏的适配性问题以及性能不足之处,再加上数据一致性对比和SQL压力加载之后,所得到的测试结果就十分接近实际上线时的情形。
KDTS迁移比对的“一条龙”服务,这个叫KDTS的工具有助于“搬家”与“对账”,其会遵照你原先数据库的类型,自动将表结构及数据迁移过来,迁移完毕之后,还能帮你执行全面或者增加的数据比对,并出具详尽的报告,这样便无需凭借人力逐行对比,既节省时间又省却力气而且准确。
柔性迁移可概括为“准在线,全数据,低侵扰”,其含义在于尽可能不干扰当前业务,将全部数据稳定转移,并达到那些仅给你一至二小时停机时间的严格标准。
光说不练假把式。下面这段SQL代码,模拟了医院里最常见的“患者-医生-预约”场景,语法在金仓数据库上跑没问题,可以直接用,或者照着改改。重点是看看怎么建表,以及怎么处理好几个人同时抢一个号的并发问题。
CREATE TABLE kb_patient (
patient_id BIGSERIAL PRIMARY KEY,
id_card VARCHAR(32) UNIQUE NOT NULL,
name VARCHAR(100) NOT NULL,
gender VARCHAR(16),
birth_date DATE,
phone VARCHAR(32),
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE kb_doctor (
doctor_id BIGSERIAL PRIMARY KEY,
dept_code VARCHAR(64) NOT NULL,
name VARCHAR(100) NOT NULL,
title VARCHAR(64),
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE kb_doctor_schedule (
schedule_id BIGSERIAL PRIMARY KEY,
doctor_id BIGINT NOT NULL REFERENCES kb_doctor(doctor_id),
start_time TIMESTAMP NOT NULL,
end_time TIMESTAMP NOT NULL,
capacity INTEGER NOT NULL,
booked INTEGER NOT NULL DEFAULT 0,
UNIQUE (doctor_id, start_time, end_time)
);
CREATE INDEX idx_schedule_doctor_time ON kb_doctor_schedule (doctor_id, start_time);
CREATE TABLE kb_appointment (
appt_id BIGSERIAL PRIMARY KEY,
patient_id BIGINT NOT NULL REFERENCES kb_patient(patient_id),
doctor_id BIGINT NOT NULL REFERENCES kb_doctor(doctor_id),
schedule_id BIGINT NOT NULL REFERENCES kb_doctor_schedule(schedule_id),
appt_time TIMESTAMP NOT NULL,
status VARCHAR(32) NOT NULL DEFAULT 'scheduled',
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
BEGIN;
SELECT capacity, booked
FROM kb_doctor_schedule
WHERE schedule_id = 123
FOR UPDATE;
UPDATE kb_doctor_schedule
SET booked = booked + 1
WHERE schedule_id = 123
AND booked < capacity;
INSERT INTO kb_appointment (patient_id, doctor_id, schedule_id, appt_time)
VALUES (1001, 77, 123, '2025-11-20 09:00:00');
COMMIT;
这里头的门道是:
SELECT ... FOR UPDATE 把这个号源记为“锁定”状态。这样,就算一百个人同时来抢这个号,也得一个个排队来,不会出现一个号卖给两个人的“超卖”情况。INSERT、UPDATE)立刻提交(COMMIT)。最怕的就是一个连接长时间占着茅坑不拉屎(处于 idle in transaction 状态),这样很容易把整个数据库连接池给拖垮。数据量大了,查询就会变慢。一个常见的优化办法就是“分区”,比如,可以把门诊病历按季度或者按年份存到不同的“抽屉”里。同时,为了安全,我们还得给核心操作加上审计,谁动了数据都得记下来。
CREATE TABLE kb_medical_record (
record_id BIGSERIAL PRIMARY KEY,
patient_id BIGINT NOT NULL REFERENCES kb_patient(patient_id),
visit_date DATE NOT NULL,
dept_code VARCHAR(64) NOT NULL,
doctor_id BIGINT NOT NULL REFERENCES kb_doctor(doctor_id),
diagnosis TEXT,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
) PARTITION BY RANGE (visit_date);
CREATE TABLE kb_medical_record_2025q4
PARTITION OF kb_medical_record
FOR VALUES FROM ('2025-10-01') TO ('2025-12-31');
CREATE TABLE kb_audit_log (
audit_id BIGSERIAL PRIMARY KEY,
table_name VARCHAR(64) NOT NULL,
op VARCHAR(16) NOT NULL,
row_id BIGINT NOT NULL,
ts TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE OR REPLACE FUNCTION kb_appointment_audit()
RETURNS TRIGGER AS $$
BEGIN
IF TG_OP = 'INSERT' THEN
INSERT INTO kb_audit_log(table_name, op, row_id) VALUES('kb_appointment', 'INSERT', NEW.appt_id);
ELSIF TG_OP = 'UPDATE' THEN
INSERT INTO kb_audit_log(table_name, op, row_id) VALUES('kb_appointment', 'UPDATE', NEW.appt_id);
ELSIF TG_OP = 'DELETE' THEN
INSERT INTO kb_audit_log(table_name, op, row_id) VALUES('kb_appointment', 'DELETE', OLD.appt_id);
END IF;
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg_kb_appointment_audit
AFTER INSERT OR UPDATE OR DELETE ON kb_appointment
FOR EACH ROW EXECUTE PROCEDURE kb_appointment_audit();
连接池需开启,并要调整好相关参数,数据库连接池化很有必要,最大连接数,空闲连接回收时限等参数得依照实际状况来调整,不能让系统在业务高峰期慌乱地生成新的物理连接,这样做速度太慢。
事务需干脆利落,在业务代码当中,每个逻辑单元结束时,要么执行提交(Commit),要么执行回滚(Rollback),不能含糊其辞。格外要防止出现历时过长的“长事务”,也要避开那些占着锁却不做任何事情的“懒汉”行为。
读操作要找“偏殿”,比如跑报表,做数据分析之类的只读任务,就安排到只读节点或者备库执行,不要影响主库处理关键的读写事务。
多留意“仪表盘”,要经常留意一些关键指标,比如连接池已使用的数量,是否存在锁等待情况,慢 SQL 语句有多频繁,哪个分区最为繁忙,以及是否启用了索引等,这些均可作为评判数据库健康状况的“体检报告”。
框架中的“坑”需谨慎对待,这里特意提及一个实际操作时会碰上的问题,假定你采用像 SqlSugar 这样的 ORM 框架,并且搭配金仓的 Kdbndp 驱动,就要格外留意事务的闭合情况。代码若调用了 BeginTran() 来开启事务,之后却忘记了执行 CommitTran() 或实施回滚,那么这个数据库连接就会一直陷于 idle in transaction 的状态,要么就是无法被释放,连接池很快就会被这些“僵尸”连接填满,从而致使整个应用程序因得不到新的连接而陷入瘫痪,所以,切记要有头有尾!
一个连接字符串的例子(参数根据你的环境改):
Host=10.10.10.10;Port=54321;Database=hospital;
User ID=app_user;Password=******;
Pooling=true;Maximum Pool Size=100;
Connection Idle Lifetime=300;Connection Pruning Interval=10
ANALYZE,更新数据库的统计信息,不然数据库“脑子”里的成本估算可能是错的,好好的索引它不用,非要去全表扫,慢SQL就是这么来的。再举两个索引优化的例子:
CREATE INDEX idx_appt_doctor_time_status ON kb_appointment (doctor_id, appt_time, status);
CREATE INDEX idx_patient_name_lower ON kb_patient (lower(name));
SELECT patient_id, name
FROM kb_patient
WHERE lower(name) LIKE lower('%张三%');
分区滚动是这么个意思:
CREATE TABLE kb_medical_record_2026q1
PARTITION OF kb_medical_record
FOR VALUES FROM ('2026-01-01') TO ('2026-03-31');
演练!再演练!多次开展演练,高可用切换,数据回退,容灾演练这些关键措施,不能仅仅停留在口头上,而是应该定时将其拿出来实际操作一番,从而形成一种类似于肌肉记忆的效果,如此一来,一旦发生意外状况时就不会手足无措。
索引与统计信息需不断更新,业务情况及查询模式均会发生改变,所以要定时查看统计信息是否过时,并遵照新的查询特征来改良索引,去除多余部分并增添必要的内容。
要掌握好数据的“生老病死”,即分区和归档策略一旦制定,就要按时执行,不能让主库的数据无限制增长,否则早晚会出现IO压力过大这种情况。
要定时回溯审查,查看审计,权限以及脱敏策略是否仍有效执行,从而保证可以随时应对诸如等保之类的检测。
对于性能趋势要心中有数,留意事务延误和并发量的变向趋势,一旦察觉其不断上升,便要考虑是否需增加机器执行扩容,或者要在架构层面做一些小调整。
医院数据库实行国产化,并非仅点击“替换”按钮这么简单,这属于系统工程范畴,依照电科金仓以往的操作经验,其成败与否主要取决于几个要点,“替换进程需处于控制之下”,“高可用要可靠”,“迁移及数据一致性可予以验证”,“运维应当做到自动化”。
打法上采用“双轨并行”这种形式作为支撑,配合“柔性迁移”工具来缩减停机时间,并且利用“一致性校验”和“负载回放”多次核对,如此一来才能以风险尽可能小的方式,平稳地切换核心业务。
换过来仅仅是一步,后续需不断加以改善,要合理执行分区,妥善完成读写分离,持之以恒地开展演习,并切实做好审查工作,如此才能渐渐使系统变得更为流畅,进而提升患者的就医感受以及自身的运维水准。
15.23MB · 2025-12-25
248.99MB · 2025-12-25
1.25 GB · 2025-12-25

