









缘之空安卓版汉化
1435MB · 2025-12-24

接下来,让我们来看看这场升级,是否能让大家更加认可的吧!
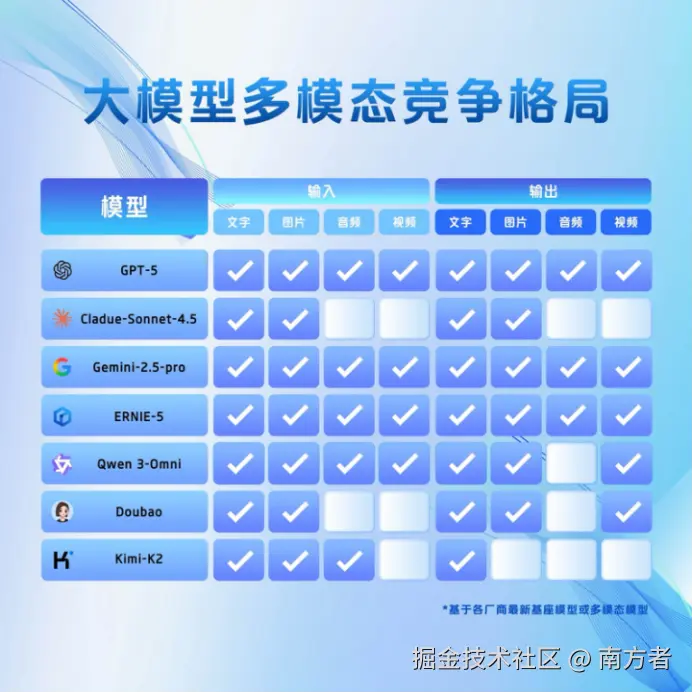
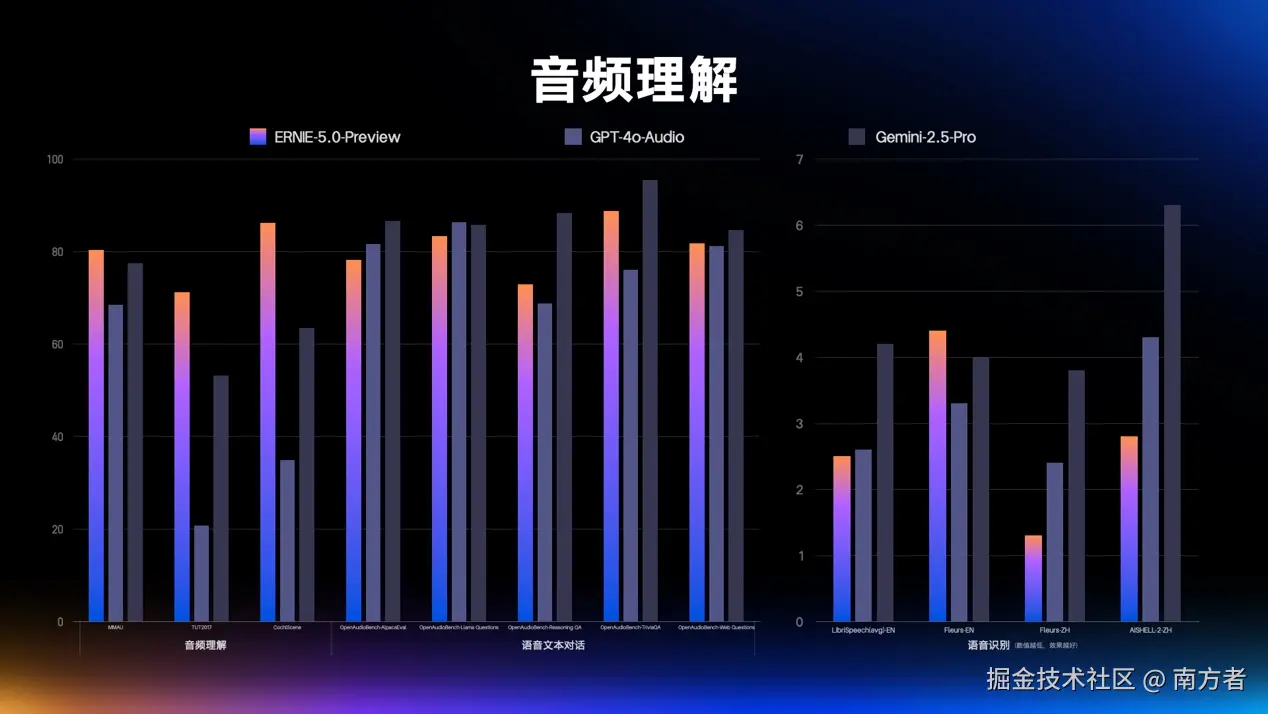
老规矩,先上效果对比图!看看所谓的「原生全模态」到底是怎么个事,目前主流大模型中,在「文本、图像、音频、视频」四个模态中,支持输入输出的情况是这样的:
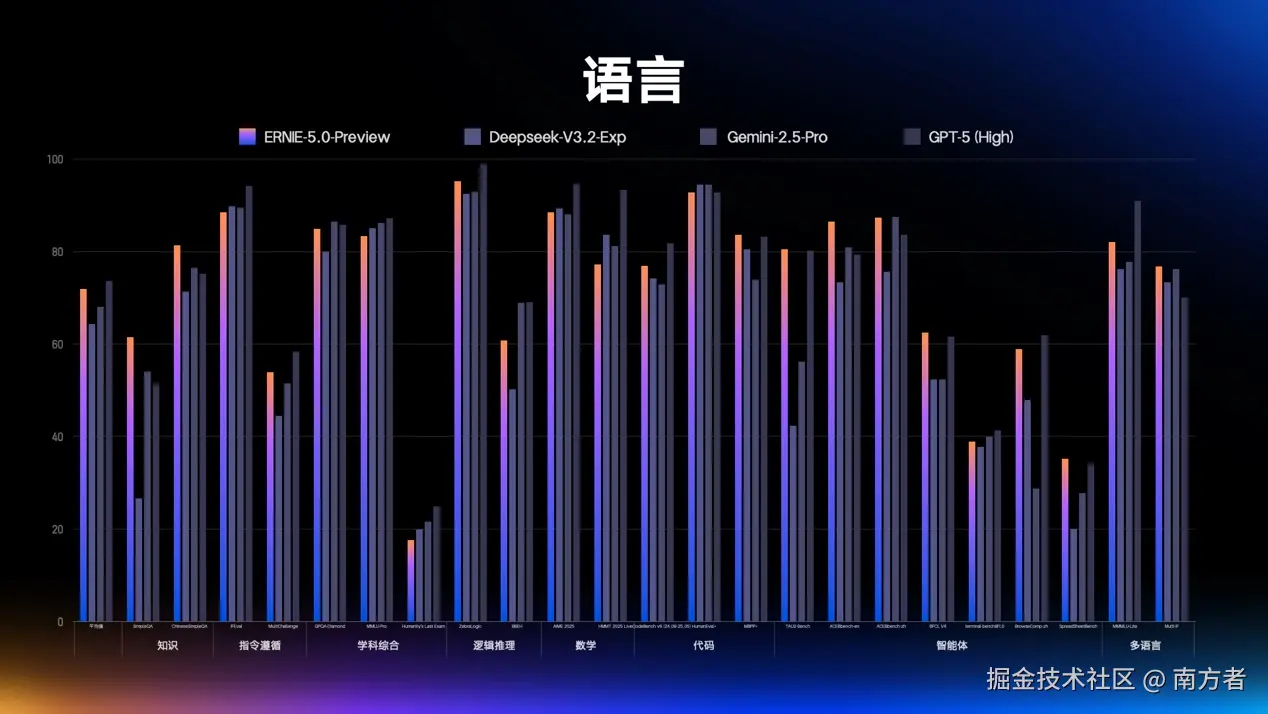
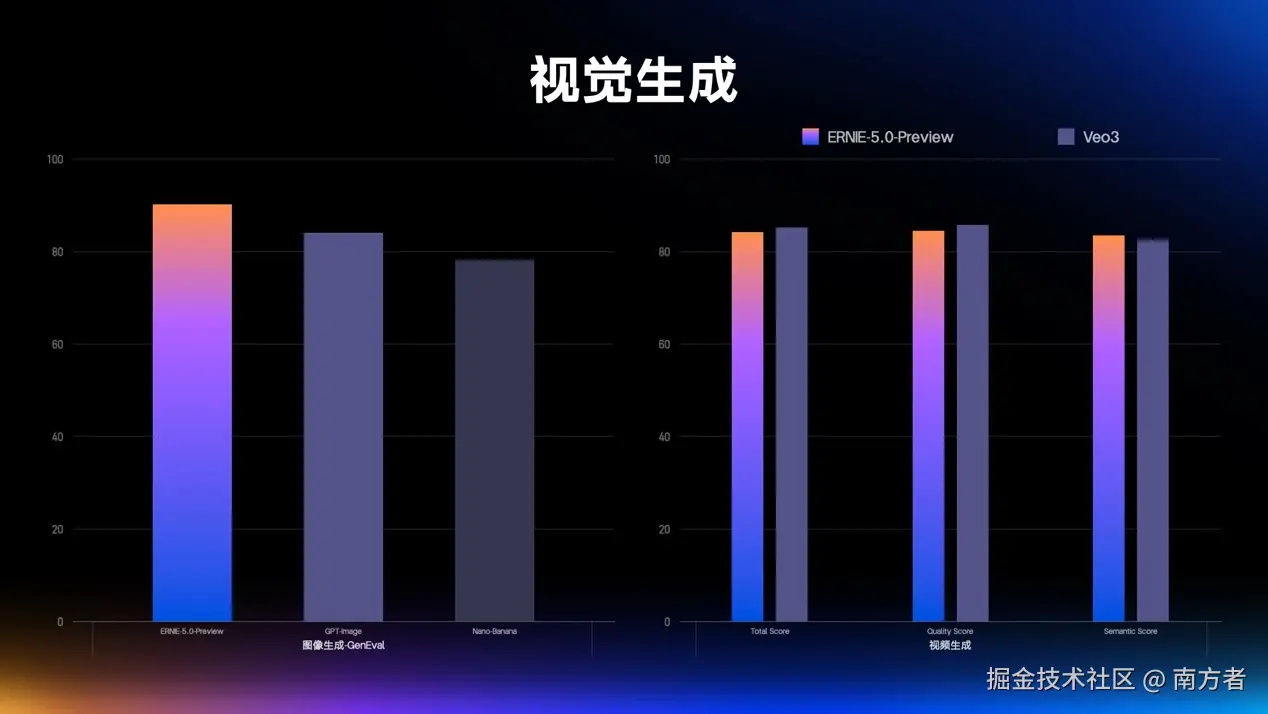
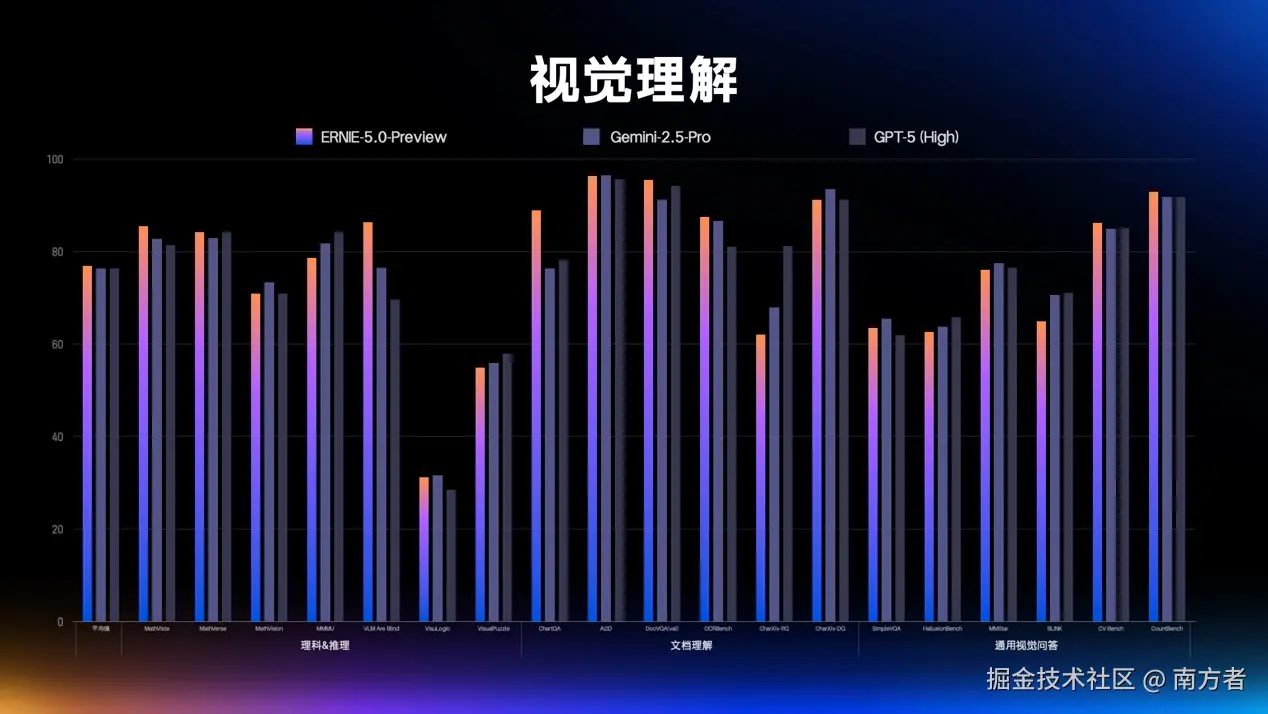
这时候可能在想,有没有这么厉害,真的是不是这样?还是那句话:
"Talk is cheap. Show me the code."
话不多说,我们接下来开始它都能干些啥!
这是一个 “3D 地球与卫星” 模拟交互界面,用于直观展示地球自转和卫星绕地球公转的运动状态,各部分功能与信息如下:
信息说明区:
3D 可视化场景:
交互控制区:
这个界面通过 3D 可视化和交互操作,帮助人们直观理解地球自转、卫星公转的周期与运动关系,是兼具科普性与互动性的工具。
这是一个太阳系 3D 模拟交互界面,用于直观展示太阳系的结构与行星运动,可分为左侧控制面板和右侧 3D 模拟场景两部分:
左侧控制面板
标题与功能说明:“太阳系 3D 模拟”,核心功能是探索太阳系,观察行星绕日轨迹,支持通过滑块调节模拟速度、缩放视角,点击行星查看详细信息。
交互滑块:
行星信息区:当前展示太阳的关键参数:
操作指南:明确了鼠标交互方式 —— 左键拖动旋转视角、右键拖动平移视角、滚轮缩放视角,点击行星可查看其详细信息。
右侧 3D 模拟场景
️视频传送门
和很多模型 “先处理单模态、再拼接融合” 不同,文心 5.0 从训练一开始就把文字、图片、视频、音频等数据 “揉在一起学”。不管是同时输入文档 + 产品图 + 讲解音频,还是要输出图文结合的报告 + 配套短视频,它都能直接打通不同信息形式,不用再靠后期技术 “补漏洞”,真正实现了多模态信息的统一理解与生成。
以往多模态模型常出现 “能看懂图却写不出准描述,或能生成内容却理解错需求” 的问题,文心 5.0 通过精细化打磨多模态语义特征,把 “理解信息” 和 “生成内容” 的能力绑在一起升级。比如分析一段产品测评视频时,既能精准提取核心卖点(理解),又能据此生成带货文案 + 演示动画(生成),两者互相助力,大幅提升了全场景下的多模态处理效果。
为了让文字、图像等不同模态的特征能深度融合,文心 5.0 把各模态的训练目标转化为统一的离散格式,再用一套自回归架构完成训练。就像用同一种 “语言” 教 AI 识别图片、解读文字、分析音频,让不同类型的信息在同一个框架里充分磨合、优化,从根本上增强了多模态统一建模的能力。
参数规模与激活效率双突破、训练效率飙升、推理成本大降
通过大量真实或模拟场景的长任务数据(比如复杂项目规划、多步工具调用流程),文心 5.0 在训练中强化了 “按步骤解决问题” 的能力。它会像人一样 “先思考、再行动”,还能通过多轮强化学习优化流程,比如用它做市场调研,能自动调用数据分析工具、整理报告、生成可视化图表,一步接一步完成复杂任务,工具调用和智能决策能力明显提升。
从文心 5.0 的交互体验到数字人落地,能清晰看到一个趋势:全球 AI 竞争已从 “参数规模” 转向 “理解力深度”。无论是与 GPT-5.1 对标的 “情商”(情绪解读、需求预判),还是原生全模态建模带来的 “沉浸式理解”,本质都是让 AI 从 “能计算” 走向 “会感知”!这场升级,我认可了!你认可吗?

