
缘之空安卓版汉化
1435MB · 2025-12-24

大型语言模型 (LLM) 无疑是当今科技领域最耀眼的明星。它们强大的自然语言处理和内容生成能力,正在重塑从搜索到创意工作的几乎所有行业。然而,如同希腊神话中的阿喀琉斯,这些强大的模型也有其“阿喀琉斯之踵”——它们固有的两大缺陷:
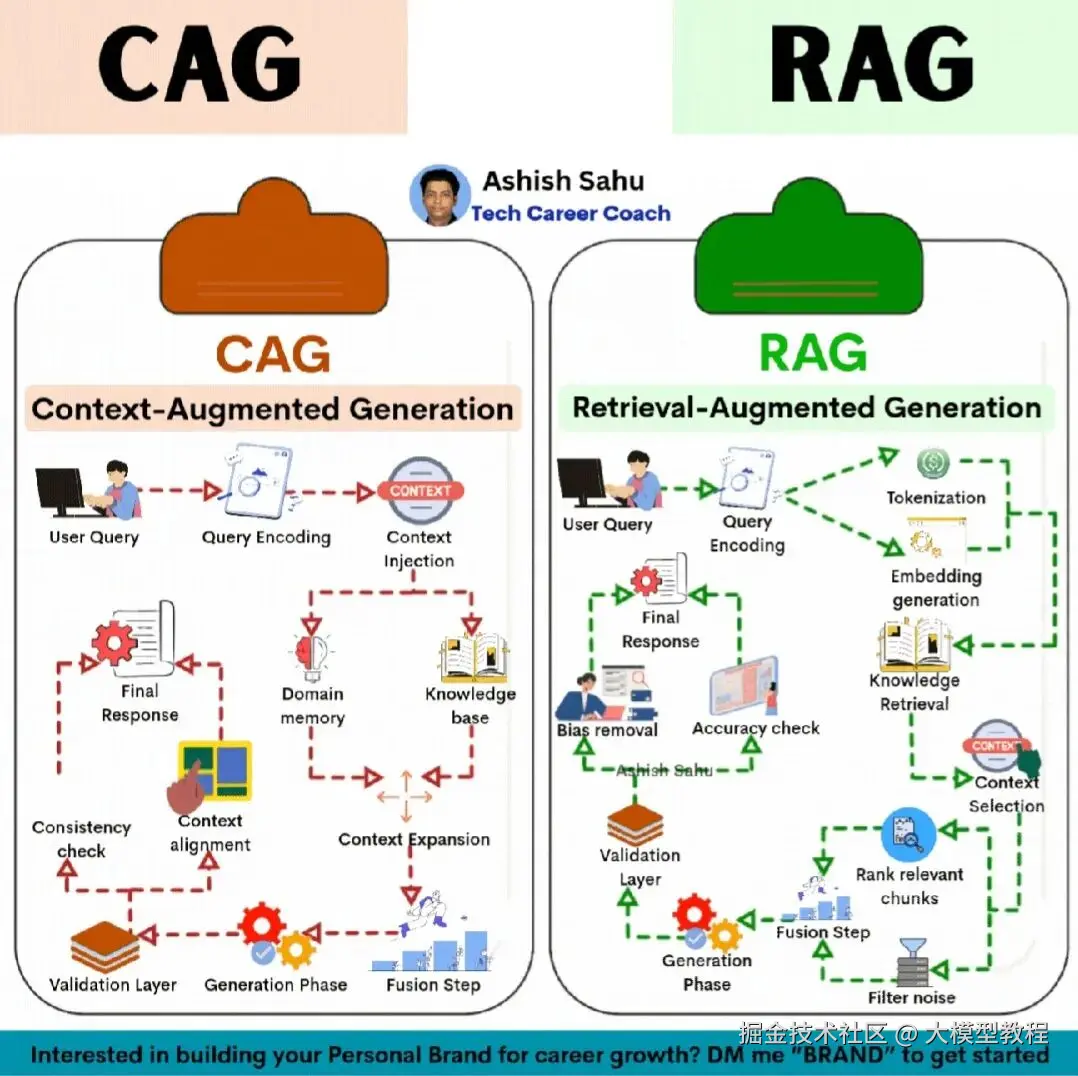
为了解决这些问题, “增强生成” (Augmented Generation) 技术应运而生。在这一领域中,RAG (Retrieval-Augmented Generation) 已成为行业标配,而 CAG (Context-Augmented Generation) 则代表了一个更深入、更智能的演进方向。
RAG(检索增强生成)是目前解决 LLM 缺陷最有效和最主流的架构。其核心思想非常直观:与其强迫模型“背诵”全世界的知识,不如让它学会“查资料” 。
RAG 就像是给了 AI 一套最新的参考书(知识库),并允许它在回答问题前进行“开卷考试”。
RAG 的标准工作流程:
RAG 的核心价值在于:
RAG 极其强大,但它在本质上仍是一种“即时反应式”的检索。它擅长回答“是什么”类型的事实问题,但在处理需要深度理解、长期记忆或专业领域一致性的复杂对话时,就显得力不从心。
这就是 CAG(上下文增强生成) 登场的契机。CAG 不仅仅是“检索”,它追求的是“上下文的深度管理与维护”。如果说 RAG 是“事实检索器”,那么 CAG 的目标是成为“领域专家”。
CAG 的核心区别在于:
我们可以将这两种架构视为AI智能的两个不同进化阶段:
| 特性 | RAG (检索增强生成) | CAG (上下文增强生成) |
|---|---|---|
| 核心焦点 | 事实检索 (Fact Retrieval) | 情境管理 (Context Management) |
| 工作模式 | 偏向无状态 (Stateless) (每次查询都像一次新的检索) | 强调有状态 (Stateful) (维护和调用持久的记忆) |
| 知识源 | 外部知识库(文档、网页等) | 外部知识库 + 领域记忆 (规则、历史、偏好) |
| 关键动作 | 检索 (Retrieve)、排序 (Rank)、融合 (Fuse) | 注入 (Inject)、对齐 (Align)、一致性检查 (Consistency) |
| 目标角色 | “开卷考试”的考生 (能快速查到正确答案) | “融会贯通”的专家 (能结合记忆和知识给出一贯的见解) |
RAG 解决了 LLM“不知道”和“说错话”的问题,这是 AI 从“玩具”走向“工具”的关键一步。
而 CAG 则代表了 AI 从“工具”走向“伙伴”和“专家”的雄心。它追求的不再是“单点正确”,而是“全局一致”和“深度个性化”。
我们必须明白,CAG 并非要替代 RAG,而是 RAG 的必然演进和扩展。在先进的 CAG 框架中,RAG 往往会作为其“上下文注入”的一个关键组件,负责从外部世界获取实时事实。
未来的高级 AI 助手,必然是一个 RAG 和 CAG 的混合体:它既能像 RAG 一样博览群书、快速检索,也能像 CAG 一样拥有深刻的记忆和一致的“人格”,真正做到从“知道”走向“理解”。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。

