

缘之空安卓版汉化
1435MB · 2025-12-24

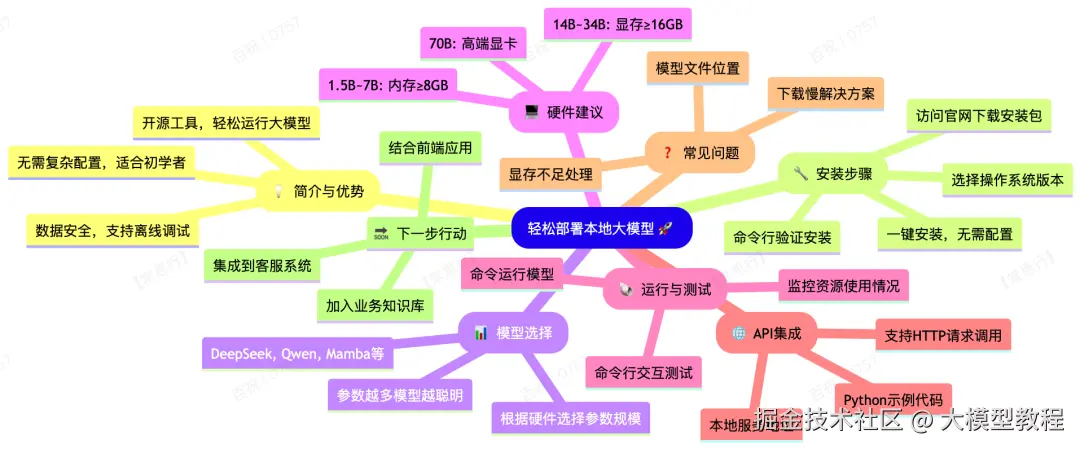
你是不是也遇到过这样的情况:想用大模型搭建个智能客服系统,但又担心数据泄露、网络延迟,或者只是想在本机先调试测试?别担心,今天我就来带你一步步在本地电脑上部署属于你自己的大模型!无需深厚的技术背景,只要跟着做,30分钟内就能搞定!
Ollama 是一个开源工具,专门用来在本地运行各种大型语言模型(比如 DeepSeek、千问、Mamba 等等)。你不用纠结环境配置、依赖安装,它都帮你封装好了,特别适合初学者或者快速原型开发。
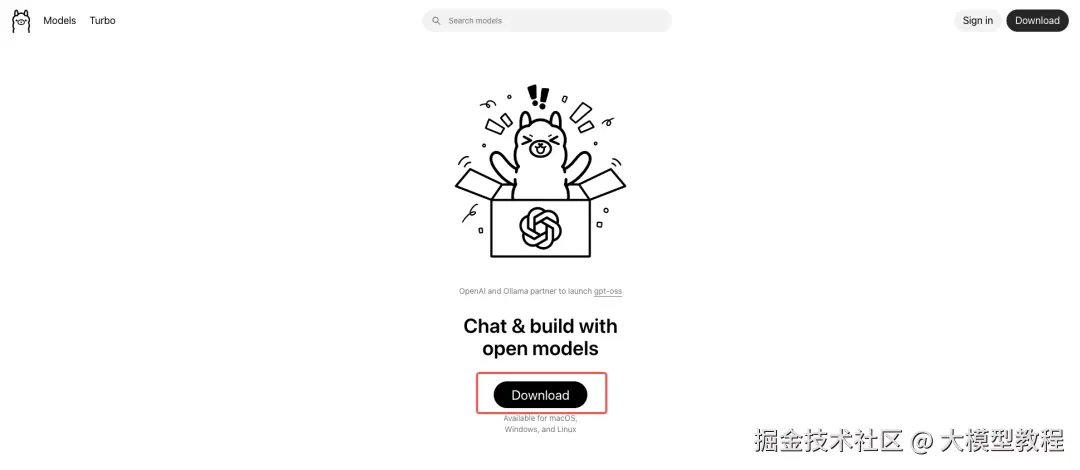
官网在这里:Ollama官方网站(打开直接点击下载就行~)
打开 Ollama官网,点击页面上的 Download 按钮;
选择你的操作系统版本(这里以 Windows 为例),下载安装包;
双击安装,一路“下一步”就行——它自动装好,不用你选安装路径啥的;
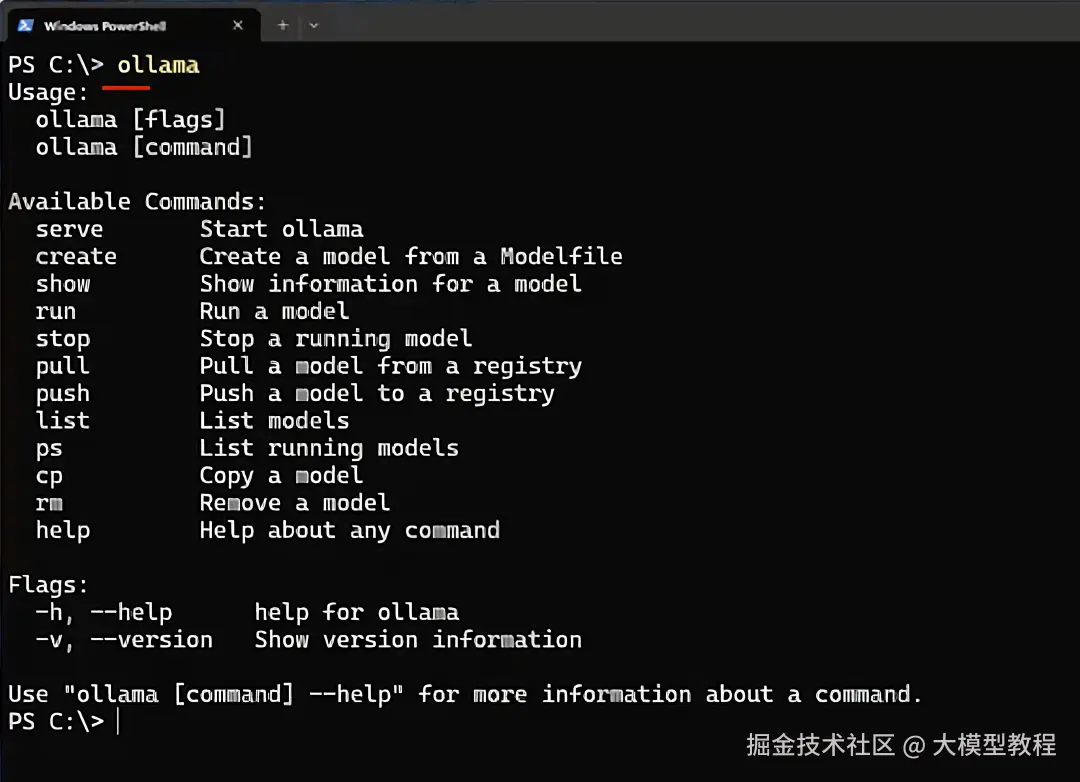
安装完成后,打开命令行(Win+R 输入 cmd 回车),输入:
ollama
如果出现一屏说明文字,恭喜你,安装成功!
回到 Ollama官网,点击 Models 标签,你会看到很多模型可选:
每个模型还有不同参数规模,比如:1.5B、7B、14B、70B等。 这个“B”是“Billion”的意思,也就是10亿参数。参数越多,模型越聪明,但对电脑要求也越高。
如果你不清楚该选哪个模型参数,可以参考这个建议:
| 模型规模 | CPU | 内存 | 硬盘空间 | 显卡 (GPU) | 典型应用场景 |
| 1.5B | 4 核 | 8 GB+ | 3 GB+ | 非必需。若加速,可选 4GB+ 显存 | 低资源设备部署、入门级试用、简单任务 |
| 7B | 8 核以上 | 16 GB+ | 8 GB+ | 推荐 8GB+ 显存 | 本地开发与测试、个人爱好者、中等复杂度任务 |
| 8B | 略高于 8 核 | 略高于 16 GB | 略高于 8 GB | 推荐 8GB+ (需求略高于7B) | 需要比7B更高精度的轻量级生产任务 |
| 14B | 12 核以上 | 32 GB+ | 15 GB+ | 推荐 16GB+ 显存 | 企业级应用、复杂问答、代码生成、高质量文本创作 |
| 32B | 16 核以上 | 64 GB+ | 30 GB+ | 要求 24GB+ 显存 | 高精度专业任务、高级推理、复杂分析、专业领域应用 |
| 70B | 32 核以上 | 128 GB+ | 70 GB+ | 需多卡并行 (如 2x 24GB 或更高) | 科研机构、超高复杂度生成、尖端技术探索 |
补充说明与注意事项:
选好模型后,比如你想用 :
deepseek-r1:7b
就直接在命令行中输入:
第一次运行会自动下载模型文件(可能需要几分钟到几十分钟,取决于你的网速和模型大小)。 完成后,你会看到命令行中出现三个箭头 >>>,意味着模型已经加载好,你可以直接在这里打字跟它对话了!
试着输入一句你好,比如:
你好,你是谁?
模型就会回答你啦~如果响应速度还行,说明你的硬件扛得住!
️ 注意:运行过程中可以打开任务管理器看看 GPU/CPU 和内存使用情况,如果卡顿可以考虑换更小模型。
虽然命令行能聊天,但我们最终是要把模型接入到客服系统中去的。Ollama 支持 API 方式调用。
启动模型后,它默认会在本地开启一个服务(通常是 http://localhost:11434),你可以用代码(比如 Python、Node.js)发送请求到这个地址,就能获得模型回复。
例如使用 curl 测试一下:
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:7b",
"prompt": "你好,请介绍你自己"
}'
或者用 Python 写个简单的调用示例:
import requests
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": "deepseek-r1:7b",
"prompt": "请问你们客服工作时间是?"
}
)
print(response.json()["response"])
这样你就可以把大模型集成到你自己的客服系统或者应用中啦!
C:Users<你的用户名>.ollamamodels(Windows)或 ~/.ollama/models(Mac/Linux)如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。

