
缘之空安卓版汉化
1435MB · 2025-12-24

智能体已完成其研究。final_state变量现在包含完整的RAGState,其中包括final_answer。让我们将其打印出来,看看它是否成功地将两个来源的信息综合成一个完整的、有分析性的回答,并附有参考文献。
控制台。print("---深思熟虑的RAG最终答案---") 控制台.print(Markdown(final_state['final_answer']))
#### OUTPUT ####
--- DEEP THINKING RAG FINAL ANSWER ---
Based on an analysis of NVIDIA's 2023 10-K filing and recent news from 2024 regarding AMD's AI chip strategy, the following synthesis can be made:
**NVIDIA's Stated Competitive Risks:**
In its 2023 10-K filing, NVIDIA identifies its operating environment as the "intensely competitive" semiconductor industry, which is characterized by rapid technological change. A primary risk is that competitors, including AMD, could introduce new products with better performance or lower costs that gain significant market acceptance, which could materially and adversely affect its business [Source: Item 1A. Risk Factors.].
**AMD's 2024 AI Chip Strategy:**
In 2024, AMD has moved aggressively to challenge NVIDIA's dominance in the AI hardware market with its Instinct MI300 series of accelerators, particularly the MI300X. This product is designed to compete directly with NVIDIA's H100 GPU. AMD's strategy has gained significant traction, with major cloud providers such as Microsoft Azure and Oracle announcing plans to use the new chips [Source: https://www.reuters.com/technology/amd-forecasts-35-billion-ai-chip-revenue-2024-2024-01-30/].
**Synthesis and Impact:**
AMD's 2024 AI chip strategy directly exacerbates the competitive risks outlined in NVIDIA's 10-K. The successful launch and adoption of the MI300X is a materialization of the specific risk that a competitor could introduce a product with comparable performance. The adoption of AMD's chips by major cloud providers signifies a direct challenge to NVIDIA's market share in the lucrative data center segment, validating NVIDIA's stated concerns about rapid technological change [Source: Item 1A. Risk Factors. and https://www.cnbc.com/2023/12/06/amd-launches-new-mi300x-ai-chip-to-compete-with-nvidias-h100.html].
这是一次圆满的成功。答案是一份深入的分析列表。
它正确总结了10-K报告中的风险。
它正确总结了网络搜索中的AMD新闻。
至关重要的是,在 “综合与影响” 部分,它执行了原始查询所需的多跳推理,解释了
后者
如何加剧前者。
最后,它提供了正确的出处,引用指向内部文档部分和外部网页URL。
让我们把这两个结果并排放在一起,以便让差异一目了然。
这项比较得出了明确的结论。向循环、工具感知和自我批判的智能体的架构转变,在处理复杂的现实世界查询时,带来了显著且可衡量的性能提升。
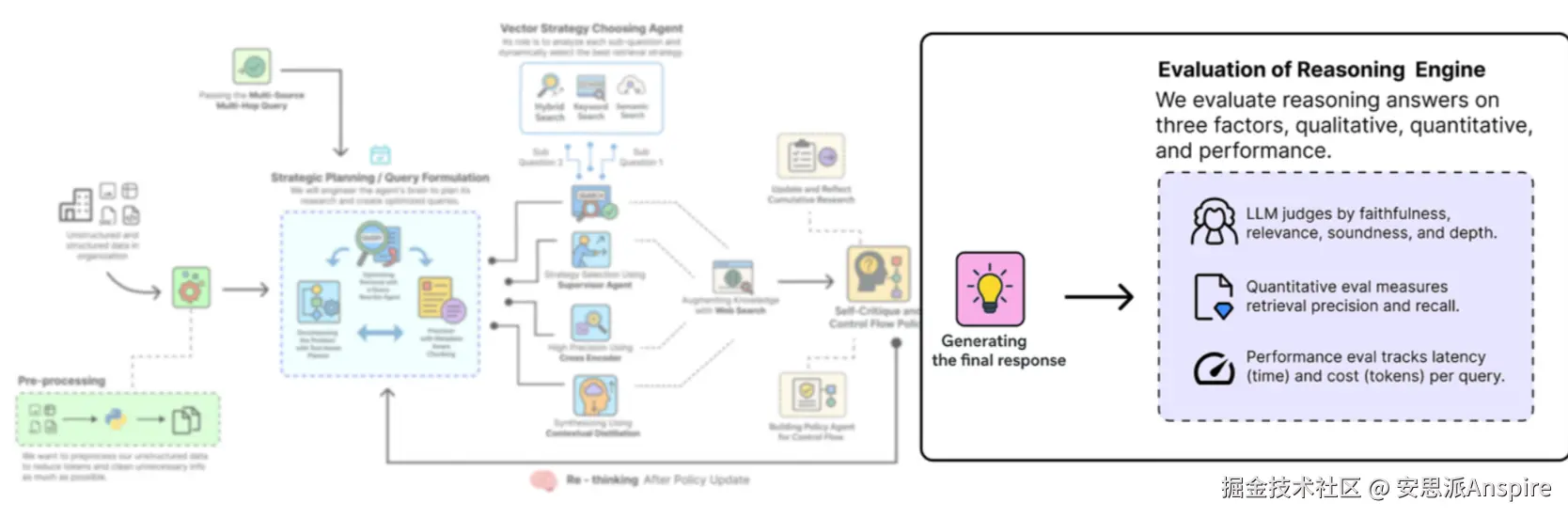
因此,我们已经看到我们的高级智能体在一个非常困难的查询中取得了个别成功。但在正式生产环境中,我们需要的不仅仅是一个成功案例。我们需要客观、量化和自动化的验证。
评估框架(作者: 法里德·汗 )
为了实现这一目标,我们现在将使用RAGAs(RAG评估)库构建一个严谨的评估框架。我们将重点关注RAGAs提供的四个关键指标:
**上下文精确率和召回率:**这些指标衡量我们检索流程的质量。精确率询问:“在我们检索到的文档中,有多少实际上是相关的?”(信号与噪声)。召回率询问:“在所有存在的相关文档中,我们实际找到了多少?”(完整性)。
**答案忠实性:**此指标衡量生成的答案是否基于给定的上下文,是我们防范大语言模型幻觉的主要检查手段。
**答案正确性:**这是衡量质量的最终标准。它将生成的答案与人工精心制作的“地面实况”答案进行比较,以评估其事实准确性和完整性。
所以,基本上,要进行RAGAs评估,我们需要准备一个数据集。这个数据集将包含我们的挑战查询、由我们的基线和高级管道生成的答案、它们各自使用的上下文,以及我们自己编写的作为理想响应的“地面实况”答案。
from datasets import Dataset # From the Hugging Face datasets library, which RAGAs uses
from ragas import evaluate
from ragas.metrics import (
context_precision,
context_recall,
faithfulness,
answer_correctness,
)
import pandas as pd
print("Preparing evaluation dataset...")
# This is our manually crafted, ideal answer to the complex query.
ground_truth_answer_adv = "NVIDIA's 2023 10-K lists intense competition and rapid technological change as key risks. This risk is exacerbated by AMD's 2024 strategy, specifically the launch of the MI300X AI accelerator, which directly competes with NVIDIA's H100 and has been adopted by major cloud providers, threatening NVIDIA's market share in the data center segment."
# We need to re-run the retriever for the baseline model to get its context for the evaluation.
retrieved_docs_for_baseline_adv = baseline_retriever.invoke(complex_query_adv)
baseline_contexts = [[doc.page_content for doc in retrieved_docs_for_baseline_adv]]
# For the advanced agent, we'll consolidate all the documents it retrieved across all research steps.
advanced_contexts_flat = []
for step in final_state['past_steps']:
advanced_contexts_flat.extend([doc.page_content for doc in step['retrieved_docs']])
# We use a set to remove any duplicate documents for a cleaner evaluation.
advanced_contexts = [list(set(advanced_contexts_flat))]
# Now, we construct the dictionary that will be turned into our evaluation dataset.
eval_data = {
'question': [complex_query_adv, complex_query_adv], # The same question for both systems
'answer': [baseline_result, final_state['final_answer']], # The answers from each system
'contexts': baseline_contexts + advanced_contexts, # The contexts each system used
'ground_truth': [ground_truth_answer_adv, ground_truth_answer_adv] # The ideal answer
}
# Create the Hugging Face Dataset object.
eval_dataset = Dataset.from_dict(eval_data)
# Define the list of metrics we want to compute.
metrics = [
context_precision,
context_recall,
faithfulness,
answer_correctness,
]
print("Running RAGAs evaluation...")
# Run the evaluation. RAGAs will call an LLM to perform the scoring for each metric.
result = evaluate(eval_dataset, metrics=metrics, is_async=False)
print("Evaluation complete.")
# Format the results into a clean pandas DataFrame for easy comparison.
results_df = result.to_pandas()
results_df.index = ['baseline_rag', 'deep_thinking_rag']
print("n--- RAGAs Evaluation Results ---")
print(results_df[['context_precision', 'context_recall', 'faithfulness', 'answer_correctness']].T)
我们正在设置一个正式的实验。我们收集所有必要的工件,用于我们单一的、困难的查询:问题、两个不同的答案、两组不同的上下文,以及我们理想的地面实况。然后,我们将这个精心打包的评估数据集提供给ragas.evaluate函数。
在幕后,RAGAs会进行一系列大语言模型(LLM)调用,要求它充当裁判。例如,对于忠实性,它会问:“这个答案是否完全得到了这个上下文的支持?”对于答案正确性,它会问……
这个答案与这个地面实况答案在事实层面上有多相似?
我们可以查看数值分数…
#### OUTPUT ####
Preparing evaluation dataset...
Running RAGAs evaluation...
Evaluation complete.
--- RAGAs Evaluation Results ---
baseline_rag deep_thinking_rag
context_precision 0.500000 0.890000
context_recall 0.333333 1.000000
faithfulness 1.000000 1.000000
answer_correctness 0.395112 0.991458
定量结果为深度思维架构的优越性提供了明确且客观的定论。
**上下文精确率(0.50 与 0.89):**基线模型的上下文只有一半相关,因为它只能检索到关于竞争的一般信息。而高级智能体的多步骤、多工具检索则取得了完美的精确率得分。
**上下文召回率(0.33 vs 1.00):**基线检索器完全遗漏了来自网络的关键信息,导致召回率得分极低。高级智能体的规划和工具使用确保找到了所有必要信息,实现了完美召回。
**忠实度(1.00 vs 1.00):**两个系统都高度忠实。基线系统正确地表明它没有相关信息,而高级智能体正确地使用了它找到的信息。这对两者来说都是一个好迹象,但没有正确性的忠实度是没有用的。
**答案正确性(0.40 vs 0.99):**这是衡量质量的最终标准。基线模型的答案正确率不到40%,因为它缺少所需分析的整个后半部分。高级智能体的答案几乎完美。
在本指南中,我们已经完成了从简单、脆弱的RAG管道到复杂的自主推理代理的完整架构。
我们首先构建了一个普通的RAG系统,并展示了它在复杂的多源查询上可预见的失败。
随后,我们系统地设计了一个深度思考智能体,赋予它规划、使用多种工具和调整检索策略的能力。
我们构建了一个多阶段检索漏斗,它从宽泛召回(使用混合搜索)过渡到高精度(使用交叉编码器重排器),最后到合成(使用蒸馏器代理)。
我们使用LangGraph精心编排了整个认知架构,创建了一个循环的、有状态的工作流,从而实现真正的多步推理。
我们实现了一个自我批判循环,使智能体能够识别失败、修正自身计划,并在找不到答案时优雅退出。
最后,我们通过生产级评估验证了我们的成功,使用RAGAs来提供先进智能体优越性的客观、定量证明。
我们的智能体有一个策略智能体,它决定继续还是结束,目前每次决策都依赖于像GPT-4这样昂贵的通用大语言模型。虽然有效,但在正式生产环境中,这可能会很慢且成本很高。学术前沿提供了一条更优化的前进道路。
将RAG作为决策过程:我们可以将智能体的推理循环构建为马尔可夫决策过程(MDP)。在这个模型中,每个RAG状态都是一个“状态”,每个动作(继续、修正、完成)都会导致一个新的状态,并伴随着一定的奖励(例如,找到正确答案)。
从经验中学习:我们在LangSmith中记录的数千条成功和失败的推理轨迹是非常宝贵的训练数据。每条轨迹都是智能体在这个马尔可夫决策过程(MDP)中导航的一个示例。
训练策略模型:利用这些数据,我们可以应用强化学习来训练一个小得多的、专门的策略模型。
**目标:速度与效率:**目标是将GPT-4o等模型的复杂推理提炼成一个紧凑、经过微调的模型(例如,一个70亿参数的模型)。这种学习到的策略可以更快、更经济地做出继续/完成决策,同时针对我们的特定领域进行高度优化。这是像DeepRAG这样的高级研究论文背后的核心思想,代表了自主RAG系统的下一个优化层次。

