
末世生存法则手游最新版
132.93MB · 2025-11-28

在互联网架构演进的历程中,性能优化的思路经历了从 “单机垂直增强” 到 “分布式水平扩展” 的跃迁 —— 早期通过升级 CPU 主频、扩容内存、优化 SQL 索引和缓存策略缓解瓶颈,而当业务规模突破单机极限(如秒杀场景每秒数十万请求、金融交易毫秒级响应要求),“如何高效调度任务、最大化利用硬件资源” 成为架构设计的核心命题,线程与并发模型由此成为现代后端架构的 “基础设施”。
然而,Java 开发者对线程的认知普遍存在三层误区:
要打破这些误区,需先建立一条清晰的认知主线:线程是操作系统级的资源单位,线程池是资源治理的架构范式,虚拟线程是调度效率的技术革命。三者并非替代关系,而是从 “资源管理” 到 “调度优化” 的递进演进。
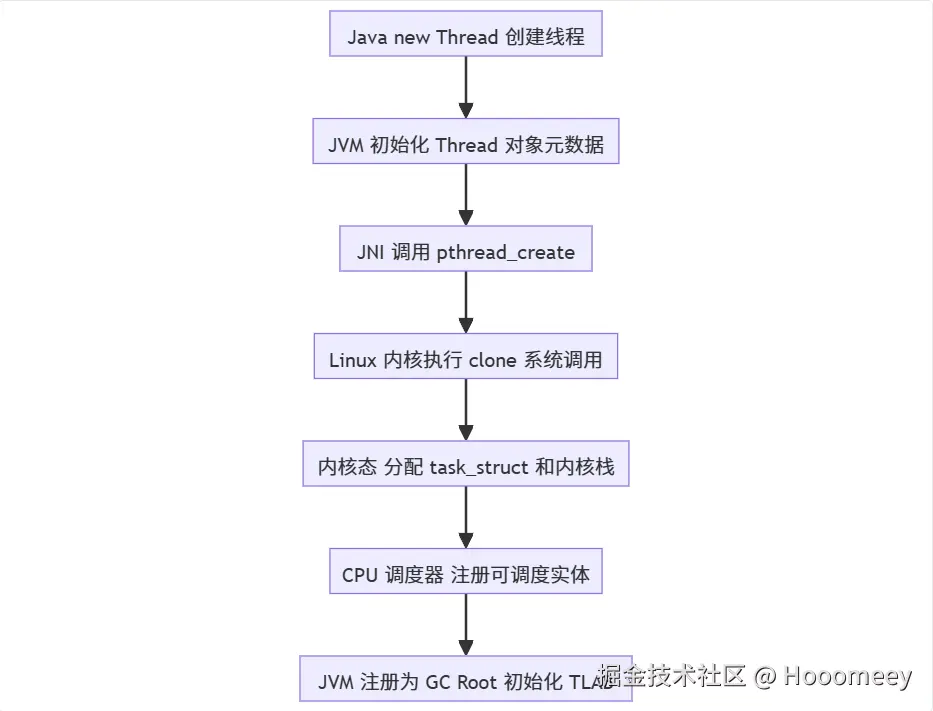
很多初学者误以为 “线程创建成本等同于 new Object ()”,根源在于 Java 的抽象封装掩盖了线程从 “语言对象” 到 “OS 调度实体” 的转化过程。实际上,一个 Java 线程的生命周期需跨越 JVM 抽象层、JNI 调用层、OS 内核层 三层链路,其成本体现在内存、CPU、JVM 协同三个维度的 “重量级开销”。
一个 Java 线程的创建链路并非 “new Thread ()” 这么简单,其完整流程如下:
每个线程需要占用多块独立内存区域,且部分区域的大小是 “固定开销”,无法通过 JVM 参数无限压缩。具体内存分布如下表所示:
| 内存区域 | 作用 | 典型大小 | 归属层级 |
|---|---|---|---|
| Java Thread 对象 | 存储线程元数据(ID、状态、优先级) | ~512 字节 | 用户态(JVM) |
| Java 虚拟机栈(JVM Stack) | 存储方法调用栈帧、局部变量、操作数栈 | 1MB(默认) | 用户态(JVM) |
| TLAB(线程私有分配缓冲) | 减少线程间对象分配竞争,加速内存分配 | 128KB~4MB | 用户态(JVM) |
| Linux 内核栈 | 处理系统调用(如 IO、内存申请)的栈空间 | 8KB~32KB | 内核态(OS) |
| task_struct(进程描述符) | 存储 OS 调度所需信息(状态、优先级、PID) | ~16KB(64 位系统) | 内核态(OS) |
计算得出:一个线程的最小内存开销约 1.1MB。若系统盲目创建 5000 个线程,仅 Java 虚拟机栈就需占用 5GB 内存(5000 * 1MB),直接触发 OOM 异常 —— 这也是 “Thread per request” 模型在高并发场景下必然崩溃的核心原因。
线程创建的核心开销来自 clone () 系统调用,该过程会触发 CPU 从 “用户态” 切换到 “内核态”,并伴随一系列耗时操作:
这些损耗看似微小,但 “频繁创建线程” 会放大问题 —— 例如,每秒创建 1000 个线程,仅上下文切换的耗时就可能占 CPU 总时间的 30% 以上,导致 “计算资源被调度本身消耗”,业务逻辑反而得不到执行。
JVM 为保证线程的安全性、可见性和可管理性,需为每个线程维护 “专属档案”,即使线程空闲也不会释放这些成本:
线程的成本并非来自 “创建对象”,而是来自 “成为 OS 调度实体” 所需的全链路资源投入。下表汇总了线程成本的核心来源:
| 成本维度 | 具体来源 | 影响程度 |
|---|---|---|
| 内存成本 | 多区域内存分配(虚拟机栈、内核栈、task_struct) | 高 |
| CPU 成本 | 系统调用、上下文切换、TLB 刷新、Pipeline Stall | 中高 |
| JVM 成本 | GC Root 维护、Safepoint 检查、TLB 管理 | 中 |
| 应用成本 | 线程间同步(锁竞争)、栈深拷贝(线程销毁时) | 中 |
理解这一点,就能明白:线程池的核心价值不是 “优化性能”,而是 “治理资源”—— 通过复用线程,摊销创建 / 销毁的重量级成本,同时通过 “资源上限控制” 避免系统被无限线程拖垮。
线程池的本质是 “线程生命周期管理 + 任务调度抽象 + 系统背压机制” 的三位一体架构。它不仅解决了 “线程昂贵” 的技术问题,更构建了一套 “应对高并发的稳定性范式”,这也是为什么线程池成为所有后端架构的 “标配组件”。
线程池的设计并非凭空出现,而是 “池化思想” 在并发领域的延伸(类似数据库连接池、对象池)。其核心设计意图与架构效果的对应关系如下:
| 设计意图 | 底层技术手段 | 架构效果 |
|---|---|---|
| 资源复用 | 线程创建后不销毁,放回池中等待复用 | 摊销线程创建 / 销毁成本,降低 CPU / 内存损耗 |
| 调度抽象 | 解耦 “任务提交”(Client)与 “任务执行”(Worker) | 支持灵活切换执行模型(如 OS 线程→虚拟线程) |
| 任务缓冲 | 引入工作队列(Work Queue) | 削峰填谷,避免瞬间流量冲垮执行线程 |
| 背压机制 | 拒绝策略(Reject Policy)+ 资源上限控制 | 防止系统过载,保障核心业务可用性 |
| 弹性伸缩 | 核心线程(core)+ 非核心线程(max) | 高峰期扩容提升吞吐量,低峰期缩容节约资源 |
以电商秒杀场景为例:秒杀开始时请求量骤增,线程池通过 “队列缓冲” 暂存超出核心线程处理能力的任务,同时启动非核心线程加速执行;若请求量超过队列 + 最大线程的承载能力,拒绝策略会丢弃非核心请求(如 “已售罄” 提示),确保核心下单流程不崩溃 —— 这就是线程池作为 “架构韧性屏障” 的价值。
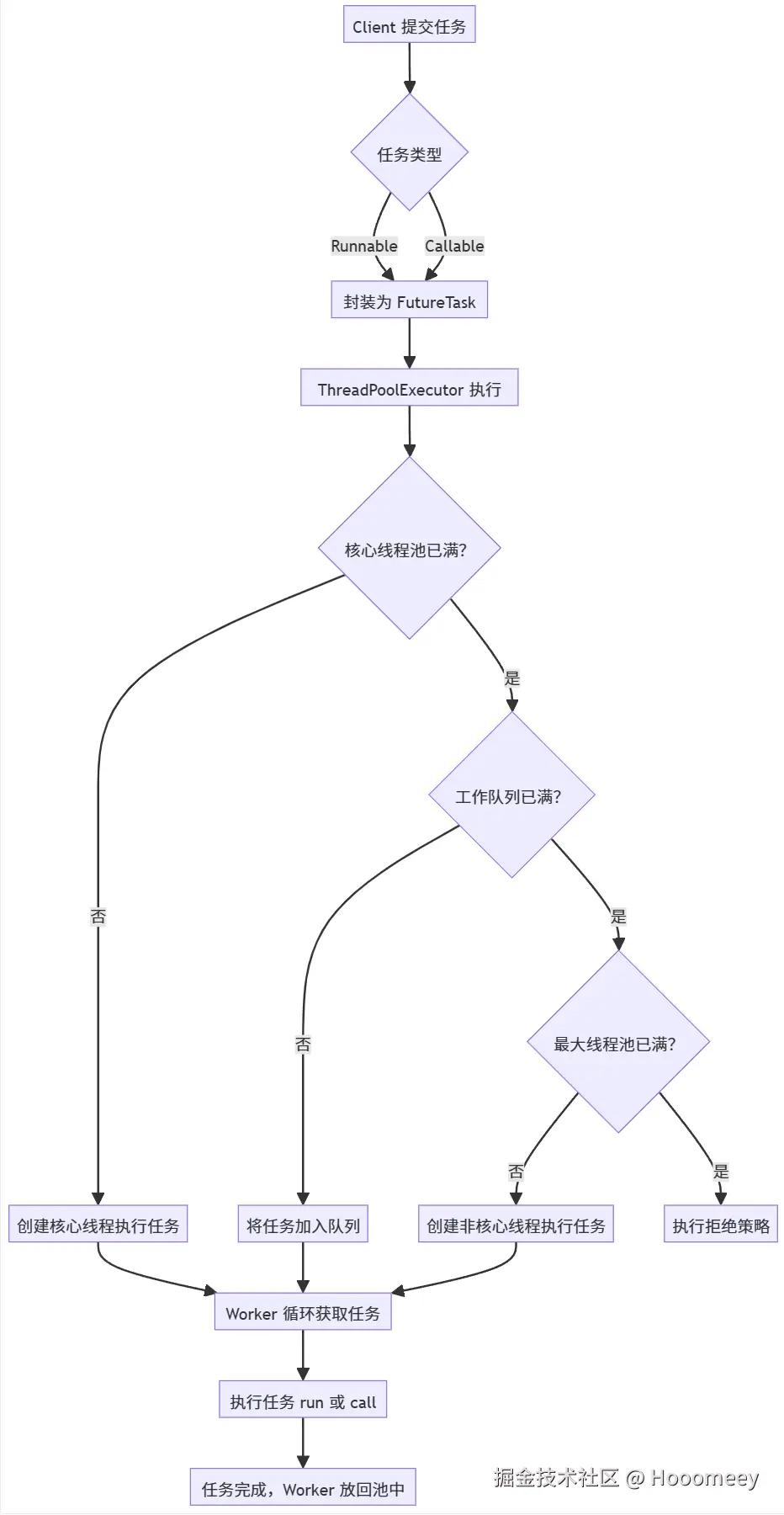
Java 中的 ThreadPoolExecutor 是线程池设计的经典实现,其核心组件与执行链路可通过以下流程图理解:
private Runnable getTask() {
boolean timedOut = false; // 标记是否超时
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 若线程池已关闭,或队列空且线程池处于关闭中,返回null(销毁线程)
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// 判断是否需要超时回收(非核心线程,或允许核心线程超时)
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 若线程数超过最大线程数,或超时且队列空,销毁当前线程
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 超时获取任务:非核心线程会阻塞 keepAliveTime 后返回 null
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take(); // 核心线程无限阻塞等待任务
if (r != null)
return r;
timedOut = true; // 标记超时
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
这段代码揭示了线程池的 “弹性回收逻辑”:非核心线程会通过 poll(keepAliveTime) 超时等待任务,超时后返回 null,触发 Worker 线程销毁;而核心线程默认通过 take() 无限阻塞,除非开启 allowCoreThreadTimeOut=true。
| 拒绝策略 | 核心逻辑 | 适用场景 |
|---|---|---|
| AbortPolicy(默认) | 抛出 RejectedExecutionException | 核心业务,需快速失败并报警 |
| CallerRunsPolicy | 由提交任务的线程(如 Tomcat 线程)执行 | 非核心业务,需背压上游避免系统崩溃 |
| DiscardOldestPolicy | 丢弃队列中最旧的任务,执行新任务 | 实时性任务(如日志收集),旧任务无价值 |
| DiscardPolicy | 直接丢弃新任务,不抛异常 | 非关键任务(如监控上报),允许少量丢失 |
当线程池中的 Worker 线程执行 task.run() 时,其成本仅是 “方法调用开销”,而非 “线程创建开销”—— 原因在于:
本质上,线程池将 “线程创建的一次性高成本”,转化为 “任务执行的多次低成本”,这是其提升并发效率的核心逻辑。
线程池参数配置是 “写代码” 与 “做架构” 的分水岭 —— 理论公式仅能提供基线,实际配置需结合业务场景、硬件资源、监控数据进行 “闭环调优”。
线程池的核心参数(corePoolSize、maxPoolSize)需根据任务的 “计算 / IO 占比” 确定,因为这直接影响线程的 “空闲率”:
| 任务类型 | 核心特征 | 理论线程数公式 | 示例(8 核 CPU) |
|---|---|---|---|
| CPU 密集型 | 线程几乎不阻塞(如数学计算、序列化) | CPU 核心数 + 1(避免 CPU 空闲) | 8 + 1 = 9 |
| IO 密集型 | 线程频繁阻塞(如 DB 读写、HTTP 调用) | CPU 核心数 × (1 + 等待时间 / 计算时间) | 8 × 2 |
| 混合型 | 计算与 IO 占比相当 | 拆分两个线程池:CPU 密集池 + IO 密集池 | 9(计算)+ 16(IO) |
注意:理论公式仅为起点,实际调优需通过压测验证 —— 例如,某 IO 密集型任务的 “等待时间 / 计算时间” 为 3,理论线程数为 8×4=32,但压测发现 24 线程时 CPU 利用率已达 90%(上下文切换增加),最终确定 20 为最优值。
线程池调优不是 “拍脑袋定参数”,而是 “监控→分析→调整→验证” 的循环过程。以下是一套生产环境落地的调优流程:
| 指标名称 | 核心含义 | 预警阈值参考 |
|---|---|---|
| executor_active_threads | 当前活跃线程数 | 超过 maxPoolSize 的 80% 需关注 |
| executor_queue_size | 队列中等待的任务数 | 超过队列容量的 50% 需扩容 |
| executor_reject_count | 任务被拒绝的次数 | 大于 0 需告警,分析是否参数不足 |
| executor_task_duration | 任务平均执行时间 | 超过预期值(如 100ms)需优化任务逻辑 |
| executor_thread_idle_ratio | 线程空闲比例 | 低于 20% 需扩容,高于 80% 需缩容 |
单一线程池处理所有任务是典型的 “反模式”—— 若某类任务阻塞(如 DB 慢查询),会导致线程池耗尽,进而影响所有业务。解决思路是 “线程池隔离”,即按业务类型拆分线程池,实现 “舱壁模式(Bulkhead Pattern)”。
以下是电商系统的线程池隔离方案示例:
| 线程池类型 | 核心参数(8 核 CPU) | 队列类型 | 拒绝策略 | 业务场景 |
|---|---|---|---|---|
| 订单核心线程池 | core=16,max=32 | ArrayBlockingQueue(200) | AbortPolicy | 下单、支付、库存扣减 |
| 商品查询线程池 | core=8,max=16 | ArrayBlockingQueue(100) | CallerRunsPolicy | 商品列表、详情查询 |
| 日志上报线程池 | core=4,max=8 | ArrayBlockingQueue(50) | DiscardPolicy | 操作日志、错误日志上报 |
| 定时任务线程池 | core=2,max=4 | PriorityBlockingQueue(20) | AbortPolicy | 订单超时关闭、库存同步 |
通过隔离,即使 “商品查询线程池” 因 DB 慢查询阻塞,也不会影响 “订单核心线程池” 的正常执行,避免了全系统雪崩(注:关键的线程池参数的设定需要根据性能目标做压测,此处仅为示例设置)。
线程池的 “纸上谈兵” 容易,生产环境落地需关注 “监控可视化”“风险规避”“优雅运维” 三个维度。
以下是一套生产可用的线程池监控方案,支持实时查看线程池状态、告警异常指标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.binder.jvm.ExecutorServiceMetrics;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.Executors;
@Configuration
public class ThreadPoolConfig {
// 核心业务线程池
@Bean(name = "orderExecutor")
public ThreadPoolExecutor orderExecutor(MeterRegistry meterRegistry) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
16, // corePoolSize
32, // maxPoolSize
60, // keepAliveTime
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(200), // 有界队列
Executors.defaultThreadFactory(), // 线程工厂(建议自定义命名)
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略
);
// 绑定 Micrometer 监控,添加业务标签便于区分
ExecutorServiceMetrics.monitor(
meterRegistry,
executor,
"threadPool.orderExecutor", // 指标前缀
"module", "order", // 业务模块标签
"env", "prod" // 环境标签
);
return executor;
}
// 自定义线程工厂(推荐):线程名包含业务信息,便于日志排查
@Bean
public ThreadFactory orderThreadFactory() {
return new ThreadFactory() {
private final AtomicInteger sequence = new AtomicInteger(0);
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setName("order-executor-" + sequence.getAndIncrement());
thread.setDaemon(false); // 非守护线程,避免 JVM 退出时任务中断
return thread;
}
};
}
}
在 application.yml 中配置 Actuator 暴露 Prometheus 指标:
management:
endpoints:
web:
exposure:
include: prometheus,health,info
metrics:
tags:
application: order-service # 应用标签,便于多服务监控
在 Grafana 中导入 “线程池监控仪表盘”(可使用社区模板 ID:1872),配置 Prometheus 数据源后,即可查看以下核心指标:
@PreDestroy // Spring 容器销毁时执行
public void shutdownExecutor() {
ThreadPoolExecutor executor = (ThreadPoolExecutor) applicationContext.getBean("orderExecutor");
executor.shutdown();
try {
// 等待 60 秒,若任务仍未完成则强制关闭
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
List<Runnable> unfinishedTasks = executor.shutdownNow();
log.warn("线程池关闭超时,未完成任务数:{}", unfinishedTasks.size());
}
} catch (InterruptedException e) {
executor.shutdownNow();
}
}
JDK 21 正式 GA 的虚拟线程(Virtual Thread),是 Java 并发模型的重大升级 —— 但它并非 “线程池的替代品”,而是 “调度效率的优化者”,二者需结合使用才能发挥最大价值。
传统 OS 线程(称为 “平台线程”)是 1:1 映射到内核线程的,而虚拟线程是 M:N 映射 —— 多个虚拟线程(M)共享一个平台线程(N,称为 Carrier Thread),调度由 JVM 完成,而非 OS。其核心机制如下:
虚拟线程的优势是 “轻量级、高并发”,但无法替代线程池的 “资源治理” 功能。二者的适用场景对比如下:
| 功能维度 | 虚拟线程(Virtual Thread) | 线程池(ThreadPool) |
|---|---|---|
| 资源开销 | 轻量(每个约 100 字节),支持百万级并发 | 重量级(每个约 1.1MB),支持数千级并发 |
| 调度方式 | JVM 用户态调度,IO 等待时释放载体线程 | OS 内核态调度,线程阻塞时占用内核资源 |
| 资源隔离 | 无隔离能力,需依赖外部机制 | 支持按业务隔离,避免雪崩 |
| 限流与背压 | 无内置策略,需结合线程池或信号量 | 内置拒绝策略,支持背压 |
| 适用场景 | IO 密集型任务(如 HTTP 调用、DB 读写) | 资源隔离、限流、CPU 密集型任务 |
最佳实践:将虚拟线程作为线程池的 “执行单元”,例如:
// 创建一个线程池,使用虚拟线程作为 Worker 线程
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
// 提交 IO 密集型任务
executor.submit(() -> {
// HTTP 调用(IO 阻塞时,虚拟线程会释放 Carrier Thread)
try (var httpClient = HttpClient.newHttpClient()) {
var request = HttpRequest.newBuilder()
.uri(URI.create("https://example.com"))
.build();
var response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
} catch (IOException | InterruptedException e) {
throw new RuntimeException(e);
}
});
此时,虚拟线程解决了 “IO 密集型任务并发量低” 的问题,而线程池(若使用自定义 ThreadPoolExecutor 包装)仍可提供资源隔离和限流能力。
从 Thread per request 到线程池,再到虚拟线程,Java 并发模型的演进始终围绕一个核心目标:在 “资源限制” 与 “并发需求” 之间寻找最优解。
未来,Java 并发架构的演进可能会向以下方向发展:
对于开发者而言,理解 “线程的资源属性”“线程池的架构价值”“虚拟线程的调度逻辑”,远比死记参数配置更重要 —— 只有掌握底层逻辑,才能在复杂业务场景中设计出稳定、高效的并发架构。

