
纸嫁衣2奘铃村苹果版
168.5M · 2025-11-04

| python | torch | torchaudio | torchvision | cuda | mmcv |
|---|---|---|---|---|---|
| 3.8.10 | 2.0.0 | 2.0.1 | 0.15.1 | 12.1.1 | 2.1.0 |
pip install -U openmim
mim install mmengine
# linux版本
pip install mmcv==2.1.0 -f https://download.openmmlab.com/mmcv/dist/cu118/torch2.0/index.html
# win版本
pip install mmcv==2.1.0 -f https://download.openmmlab.com/mmcv/dist/cpu/torch2.0/index.html
git clone https://github.com/open-mmlab/mmaction2.git
cd mmaction2
pip install -v -e .
# "-v" 表示输出更多安装相关的信息
# "-e" 表示以可编辑形式安装,这样可以在不重新安装的情况下,让本地修改直接生效。
点击跳转MMCV官方安装教程
python demo/demo_inferencer.py demo/demo.mp4
--rec tsn --print-result
--label-file tools/data/kinetics/label_map_k400.txt
# 推理结果
# {'predictions': [{'rec_labels': [[6]], 'rec_scores': [[...]]}]}
# 下载官方预先准备好的 kinetics400_tiny.zip ,并将其解压到 MMAction2 根目录下的 data/ 目录
wget https://download.openmmlab.com/mmaction/kinetics400_tiny.zip
mkdir -p data/
unzip kinetics400_tiny.zip -d data/
使用 resnet50 作为主干网络来训练 TSN。由于 MMAction2 已经有了完整的 Kinetics400 数据集的配置文件 (configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py),只需要在其基础上进行一些修改。
# 修改数据集
# 打开 configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py ,按如下替换关键字:
data_root = 'data/kinetics400_tiny/train'
data_root_val = 'data/kinetics400_tiny/val'
ann_file_train = 'data/kinetics400_tiny/kinetics_tiny_train_video.txt'
ann_file_val = 'data/kinetics400_tiny/kinetics_tiny_val_video.txt'
# 修改运行配置
# 由于数据集的大小减少,我们建议将训练批大小减少到4个,训练epoch的数量相应减少到10个。此外,我们建议将验证和权值存储间隔缩短为1轮,并修改学习率衰减策略。修改 configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py 中对应的关键字,如下所示生效。
# 设置训练批大小为 4
train_dataloader['batch_size'] = 4
# 每轮都保存权重,并且只保留最新的权重
default_hooks = dict(
checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=1))
# 将最大 epoch 数设置为 10,并每 1 个 epoch验证模型
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=10, val_interval=1)
#根据 10 个 epoch调整学习率调度
param_scheduler = [
dict(
type='MultiStepLR',
begin=0,
end=10,
by_epoch=True,
milestones=[4, 8],
gamma=0.1)
# 修改模型配置
# 由于精简版 Kinetics 数据集规模较小,建议加载原始 Kinetics 数据集上的预训练模型。此外,模型需要根据实际类别数进行修改。请直接将以下代码添加到 configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py 中。
model = dict(
cls_head=dict(num_classes=2))
load_from = 'https://download.openmmlab.com/mmaction/v1.0/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb_20220906-cd10898e.pth'
# 在这里,我们直接通过继承 ({external+mmengine:doc} MMEngine: Config <advanced_tutorials/ Config>) 机制重写了基本配置中的相应参数。原始字段分布在 configs/_base_/models/tsn_r50.py、configs/_base_/schedules/sgd_100e.py 和 configs/_base_/default_runtime.py中。
python tools/train.py configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py
# 在没有额外配置的情况下,模型权重将被保存到 work_dirs/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb/,而日志将被存储到 work_dirs/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb/。
# 修改此处 predictions[0].pred_score -> predictions[0].pred_scores.item
print('Scores of Sample[0]', predictions[0].pred_scores.item)
# 修改此处 data_sample['pred_score'].cpu().numpy() -> data_sample['pred_scores']['item']
scores = data_sample['pred_scores']['item']
# 并在下方额外添加 scores = np.array(scores)
scores = np.array(scores)
'''
修改此处 for data_batch in track_iter_progress(val_data_loader): ->
task_num = len(val_data_loader)
for data_batch in track_iter_progress((val_data_loader,task_num)):
'''
task_num = len(val_data_loader)
for data_batch in track_iter_progress((val_data_loader,task_num)):
import mmaction
from mmaction.utils import register_all_modules
register_all_modules(init_default_scope=True)
print('**************************步骤0:准备数据*****************************')
print('**************************步骤1:构建一个数据流水线*****************************')
import mmcv
import decord
import numpy as np
from mmcv.transforms import TRANSFORMS, BaseTransform, to_tensor
from mmaction.structures import ActionDataSample
@TRANSFORMS.register_module()
class VideoInit(BaseTransform):
def transform(self, results):
container = decord.VideoReader(results['filename'])
results['total_frames'] = len(container)
results['video_reader'] = container
return results
@TRANSFORMS.register_module()
class VideoSample(BaseTransform):
def __init__(self, clip_len, num_clips, test_mode=False):
self.clip_len = clip_len
self.num_clips = num_clips
self.test_mode = test_mode
def transform(self, results):
total_frames = results['total_frames']
interval = total_frames // self.clip_len
if self.test_mode:
# 使测试期间的采样具有确定性
np.random.seed(42)
inds_of_all_clips = []
for i in range(self.num_clips):
bids = np.arange(self.clip_len) * interval
offset = np.random.randint(interval, size=bids.shape)
inds = bids + offset
inds_of_all_clips.append(inds)
results['frame_inds'] = np.concatenate(inds_of_all_clips)
results['clip_len'] = self.clip_len
results['num_clips'] = self.num_clips
return results
@TRANSFORMS.register_module()
class VideoDecode(BaseTransform):
def transform(self, results):
frame_inds = results['frame_inds']
container = results['video_reader']
imgs = container.get_batch(frame_inds).asnumpy()
imgs = list(imgs)
results['video_reader'] = None
del container
results['imgs'] = imgs
results['img_shape'] = imgs[0].shape[:2]
return results
@TRANSFORMS.register_module()
class VideoResize(BaseTransform):
def __init__(self, r_size):
self.r_size = (np.inf, r_size)
def transform(self, results):
img_h, img_w = results['img_shape']
new_w, new_h = mmcv.rescale_size((img_w, img_h), self.r_size)
imgs = [mmcv.imresize(img, (new_w, new_h))
for img in results['imgs']]
results['imgs'] = imgs
results['img_shape'] = imgs[0].shape[:2]
return results
@TRANSFORMS.register_module()
class VideoCrop(BaseTransform):
def __init__(self, c_size):
self.c_size = c_size
def transform(self, results):
img_h, img_w = results['img_shape']
center_x, center_y = img_w // 2, img_h // 2
x1, x2 = center_x - self.c_size // 2, center_x + self.c_size // 2
y1, y2 = center_y - self.c_size // 2, center_y + self.c_size // 2
imgs = [img[y1:y2, x1:x2] for img in results['imgs']]
results['imgs'] = imgs
results['img_shape'] = imgs[0].shape[:2]
return results
@TRANSFORMS.register_module()
class VideoFormat(BaseTransform):
def transform(self, results):
num_clips = results['num_clips']
clip_len = results['clip_len']
imgs = results['imgs']
# [num_clips*clip_len, H, W, C]
imgs = np.array(imgs)
# [num_clips, clip_len, H, W, C]
imgs = imgs.reshape((num_clips, clip_len) + imgs.shape[1:])
# [num_clips, C, clip_len, H, W]
imgs = imgs.transpose(0, 4, 1, 2, 3)
results['imgs'] = imgs
return results
@TRANSFORMS.register_module()
class VideoPack(BaseTransform):
def __init__(self, meta_keys=('img_shape', 'num_clips', 'clip_len')):
self.meta_keys = meta_keys
def transform(self, results):
packed_results = dict()
inputs = to_tensor(results['imgs'])
data_sample = ActionDataSample().set_gt_label(results['label'])
metainfo = {k: results[k] for k in self.meta_keys if k in results}
data_sample.set_metainfo(metainfo)
packed_results['inputs'] = inputs
packed_results['data_samples'] = data_sample
return packed_results
import os.path as osp
from mmengine.dataset import Compose
pipeline_cfg = [
dict(type='VideoInit'),
dict(type='VideoSample', clip_len=16, num_clips=1, test_mode=False),
dict(type='VideoDecode'),
dict(type='VideoResize', r_size=256),
dict(type='VideoCrop', c_size=224),
dict(type='VideoFormat'),
dict(type='VideoPack')
]
pipeline = Compose(pipeline_cfg)
data_prefix = 'data/kinetics400_tiny/train'
results = dict(filename=osp.join(data_prefix, 'D32_1gwq35E.mp4'), label=0)
packed_results = pipeline(results)
inputs = packed_results['inputs']
data_sample = packed_results['data_samples']
print('shape of the inputs: ', inputs.shape)
# 获取输入的信息
print('image_shape: ', data_sample.img_shape)
print('num_clips: ', data_sample.num_clips)
print('clip_len: ', data_sample.clip_len)
# 获取输入的标签
print('label: ', data_sample.gt_label)
print('**************************步骤2:构建一个数据集和数据加载器*****************************')
import os.path as osp
from mmengine.fileio import list_from_file
from mmengine.dataset import BaseDataset
from mmaction.registry import DATASETS
@DATASETS.register_module()
class DatasetZelda(BaseDataset):
def __init__(self, ann_file, pipeline, data_root, data_prefix=dict(video=''),
test_mode=False, modality='RGB', **kwargs):
self.modality = modality
super(DatasetZelda, self).__init__(ann_file=ann_file, pipeline=pipeline, data_root=data_root,
data_prefix=data_prefix, test_mode=test_mode,
**kwargs)
def load_data_list(self):
data_list = []
fin = list_from_file(self.ann_file)
for line in fin:
line_split = line.strip().split()
filename, label = line_split
label = int(label)
filename = osp.join(self.data_prefix['video'], filename)
data_list.append(dict(filename=filename, label=label))
return data_list
def get_data_info(self, idx: int) -> dict:
data_info = super().get_data_info(idx)
data_info['modality'] = self.modality
return data_info
from mmaction.registry import DATASETS
train_pipeline_cfg = [
dict(type='VideoInit'),
dict(type='VideoSample', clip_len=16, num_clips=1, test_mode=False),
dict(type='VideoDecode'),
dict(type='VideoResize', r_size=256),
dict(type='VideoCrop', c_size=224),
dict(type='VideoFormat'),
dict(type='VideoPack')
]
val_pipeline_cfg = [
dict(type='VideoInit'),
dict(type='VideoSample', clip_len=16, num_clips=5, test_mode=True),
dict(type='VideoDecode'),
dict(type='VideoResize', r_size=256),
dict(type='VideoCrop', c_size=224),
dict(type='VideoFormat'),
dict(type='VideoPack')
]
train_dataset_cfg = dict(
type='DatasetZelda',
ann_file='kinetics_tiny_train_video.txt',
pipeline=train_pipeline_cfg,
data_root='data/kinetics400_tiny/',
data_prefix=dict(video='train'))
val_dataset_cfg = dict(
type='DatasetZelda',
ann_file='kinetics_tiny_val_video.txt',
pipeline=val_pipeline_cfg,
data_root='data/kinetics400_tiny/',
data_prefix=dict(video='val'))
train_dataset = DATASETS.build(train_dataset_cfg)
packed_results = train_dataset[0]
inputs = packed_results['inputs']
data_sample = packed_results['data_samples']
print('shape of the inputs: ', inputs.shape)
# 获取输入的信息
print('image_shape: ', data_sample.img_shape)
print('num_clips: ', data_sample.num_clips)
print('clip_len: ', data_sample.clip_len)
# 获取输入的标签
print('label: ', data_sample.gt_label)
from mmengine.runner import Runner
BATCH_SIZE = 2
train_dataloader_cfg = dict(
batch_size=BATCH_SIZE,
num_workers=0,
persistent_workers=False,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_dataset_cfg)
val_dataloader_cfg = dict(
batch_size=BATCH_SIZE,
num_workers=0,
persistent_workers=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=val_dataset_cfg)
train_data_loader = Runner.build_dataloader(dataloader=train_dataloader_cfg)
val_data_loader = Runner.build_dataloader(dataloader=val_dataloader_cfg)
batched_packed_results = next(iter(train_data_loader))
batched_inputs = batched_packed_results['inputs']
batched_data_sample = batched_packed_results['data_samples']
assert len(batched_inputs) == BATCH_SIZE
assert len(batched_data_sample) == BATCH_SIZE
print('**************************步骤3:构建一个识别器*****************************')
import torch
from mmengine.model import BaseDataPreprocessor, stack_batch
from mmaction.registry import MODELS
@MODELS.register_module()
class DataPreprocessorZelda(BaseDataPreprocessor):
def __init__(self, mean, std):
super().__init__()
self.register_buffer(
'mean',
torch.tensor(mean, dtype=torch.float32).view(-1, 1, 1, 1),
False)
self.register_buffer(
'std',
torch.tensor(std, dtype=torch.float32).view(-1, 1, 1, 1),
False)
def forward(self, data, training=False):
data = self.cast_data(data)
inputs = data['inputs']
batch_inputs = stack_batch(inputs) # 批处理
batch_inputs = (batch_inputs - self.mean) / self.std # 归一化
data['inputs'] = batch_inputs
return data
from mmaction.registry import MODELS
data_preprocessor_cfg = dict(
type='DataPreprocessorZelda',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375])
data_preprocessor = MODELS.build(data_preprocessor_cfg)
preprocessed_inputs = data_preprocessor(batched_packed_results)
print(preprocessed_inputs['inputs'].shape)
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmengine.model import BaseModel, BaseModule, Sequential
from mmengine.structures import LabelData
from mmaction.registry import MODELS
@MODELS.register_module()
class BackBoneZelda(BaseModule):
def __init__(self, init_cfg=None):
if init_cfg is None:
init_cfg = [dict(type='Kaiming', layer='Conv3d', mode='fan_out', nonlinearity="relu"),
dict(type='Constant', layer='BatchNorm3d', val=1, bias=0)]
super(BackBoneZelda, self).__init__(init_cfg=init_cfg)
self.conv1 = Sequential(nn.Conv3d(3, 64, kernel_size=(3, 7, 7),
stride=(1, 2, 2), padding=(1, 3, 3)),
nn.BatchNorm3d(64), nn.ReLU())
self.maxpool = nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 2, 2),
padding=(0, 1, 1))
self.conv = Sequential(nn.Conv3d(64, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm3d(128), nn.ReLU())
def forward(self, imgs):
# imgs: [batch_size*num_views, 3, T, H, W]
# features: [batch_size*num_views, 128, T/2, H//8, W//8]
features = self.conv(self.maxpool(self.conv1(imgs)))
return features
@MODELS.register_module()
class ClsHeadZelda(BaseModule):
def __init__(self, num_classes, in_channels, dropout=0.5, average_clips='prob', init_cfg=None):
if init_cfg is None:
init_cfg = dict(type='Normal', layer='Linear', std=0.01)
super(ClsHeadZelda, self).__init__(init_cfg=init_cfg)
self.num_classes = num_classes
self.in_channels = in_channels
self.average_clips = average_clips
if dropout != 0:
self.dropout = nn.Dropout(dropout)
else:
self.dropout = None
self.fc = nn.Linear(self.in_channels, self.num_classes)
self.pool = nn.AdaptiveAvgPool3d(1)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, x):
N, C, T, H, W = x.shape
x = self.pool(x)
x = x.view(N, C)
assert x.shape[1] == self.in_channels
if self.dropout is not None:
x = self.dropout(x)
cls_scores = self.fc(x)
return cls_scores
def loss(self, feats, data_samples):
cls_scores = self(feats)
labels = torch.stack([x.gt_label for x in data_samples])
labels = labels.squeeze()
if labels.shape == torch.Size([]):
labels = labels.unsqueeze(0)
loss_cls = self.loss_fn(cls_scores, labels)
return dict(loss_cls=loss_cls)
def predict(self, feats, data_samples):
cls_scores = self(feats)
num_views = cls_scores.shape[0] // len(data_samples)
# assert num_views == data_samples[0].num_clips
cls_scores = self.average_clip(cls_scores, num_views)
for ds, sc in zip(data_samples, cls_scores):
pred = LabelData(item=sc)
ds.pred_scores = pred
return data_samples
def average_clip(self, cls_scores, num_views):
if self.average_clips not in ['score', 'prob', None]:
raise ValueError(f'{self.average_clips} is not supported. '
f'Currently supported ones are '
f'["score", "prob", None]')
total_views = cls_scores.shape[0]
cls_scores = cls_scores.view(total_views // num_views, num_views, -1)
if self.average_clips is None:
return cls_scores
elif self.average_clips == 'prob':
cls_scores = F.softmax(cls_scores, dim=2).mean(dim=1)
elif self.average_clips == 'score':
cls_scores = cls_scores.mean(dim=1)
return cls_scores
@MODELS.register_module()
class RecognizerZelda(BaseModel):
def __init__(self, backbone, cls_head, data_preprocessor):
super().__init__(data_preprocessor=data_preprocessor)
self.backbone = MODELS.build(backbone)
self.cls_head = MODELS.build(cls_head)
def extract_feat(self, inputs):
inputs = inputs.view((-1, ) + inputs.shape[2:])
return self.backbone(inputs)
def loss(self, inputs, data_samples):
feats = self.extract_feat(inputs)
loss = self.cls_head.loss(feats, data_samples)
return loss
def predict(self, inputs, data_samples):
feats = self.extract_feat(inputs)
predictions = self.cls_head.predict(feats, data_samples)
return predictions
def forward(self, inputs, data_samples=None, mode='tensor'):
if mode == 'tensor':
return self.extract_feat(inputs)
elif mode == 'loss':
return self.loss(inputs, data_samples)
elif mode == 'predict':
return self.predict(inputs, data_samples)
else:
raise RuntimeError(f'Invalid mode: {mode}')
import torch
import copy
from mmaction.registry import MODELS
model_cfg = dict(
type='RecognizerZelda',
backbone=dict(type='BackBoneZelda'),
cls_head=dict(
type='ClsHeadZelda',
num_classes=2,
in_channels=128,
average_clips='prob'),
data_preprocessor = dict(
type='DataPreprocessorZelda',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375]))
model = MODELS.build(model_cfg)
# 训练
model.train()
model.init_weights()
data_batch_train = copy.deepcopy(batched_packed_results)
data = model.data_preprocessor(data_batch_train, training=True)
loss = model(**data, mode='loss')
print('loss dict: ', loss)
# 验证
with torch.no_grad():
model.eval()
data_batch_test = copy.deepcopy(batched_packed_results)
data = model.data_preprocessor(data_batch_test, training=False)
predictions = model(**data, mode='predict')
here = (predictions)
print('Label of Sample[0]', predictions[0].gt_label)
print('----------------------------------------------------')
print('Label of Sample[0]', predictions[0].gt_label)
print('Scores of Sample[0]', predictions[0].pred_scores.item)
print('**************************步骤4:构建一个评估指标*****************************')
import copy
from collections import OrderedDict
from mmengine.evaluator import BaseMetric
from mmaction.evaluation import top_k_accuracy
from mmaction.registry import METRICS
@METRICS.register_module()
class AccuracyMetric(BaseMetric):
def __init__(self, topk=(1, 5), collect_device='cpu', prefix='acc'):
super().__init__(collect_device=collect_device, prefix=prefix)
self.topk = topk
def process(self, data_batch, data_samples):
data_samples = copy.deepcopy(data_samples)
for data_sample in data_samples:
result = dict()
scores = data_sample['pred_scores']['item']
scores = np.array(scores)
label = data_sample['gt_label'].item()
result['scores'] = scores
result['label'] = label
self.results.append(result)
def compute_metrics(self, results: list) -> dict:
eval_results = OrderedDict()
labels = [res['label'] for res in results]
scores = [res['scores'] for res in results]
topk_acc = top_k_accuracy(scores, labels, self.topk)
for k, acc in zip(self.topk, topk_acc):
eval_results[f'topk{k}'] = acc
return eval_results
from mmaction.registry import METRICS
metric_cfg = dict(type='AccuracyMetric', topk=(1, 5))
metric = METRICS.build(metric_cfg)
data_samples = [d.to_dict() for d in predictions]
metric.process(batched_packed_results, data_samples)
acc = metric.compute_metrics(metric.results)
print(acc)
print('**************************步骤5:使用本地 PyTorch 训练和测试*****************************')
import torch.optim as optim
from mmengine import track_iter_progress
from tqdm import tqdm
device = 'cuda' # or 'cpu'
max_epochs = 10
optimizer = optim.Adam(model.parameters(), lr=0.01)
for epoch in range(max_epochs):
model.train()
losses = []
task_num = len(train_data_loader)
for data_batch in track_iter_progress((train_data_loader, task_num)):
data = model.data_preprocessor(data_batch, training=True)
loss_dict = model(**data, mode='loss')
loss = loss_dict['loss_cls']
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
print(f'Epoch[{epoch}]: loss ', sum(losses) / len(train_data_loader))
with torch.no_grad():
model.eval()
task_num = len(val_data_loader)
for data_batch in track_iter_progress((val_data_loader,task_num)):
data = model.data_preprocessor(data_batch, training=False)
predictions = model(**data, mode='predict')
data_samples = [d.to_dict() for d in predictions]
metric.process(data_batch, data_samples)
acc = metric.acc = metric.compute_metrics(metric.results)
for name, topk in acc.items():
print(f'{name}: ', topk)
print('**************************步骤6:使用 MMEngine 训练和测试(推荐)*****************************')
# from mmengine.runner import Runner
#
# train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=10, val_interval=1)
# val_cfg = dict(type='ValLoop')
#
# optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.01))
#
# runner = Runner(model=model_cfg, work_dir='./work_dirs/guide',
# train_dataloader=train_dataloader_cfg,
# train_cfg=train_cfg,
# val_dataloader=val_dataloader_cfg,
# val_cfg=val_cfg,
# optim_wrapper=optim_wrapper,
# val_evaluator=[metric_cfg],
# default_scope='mmaction')
# runner.train()
MMAction2 提供了用于对给定视频进行推理的高级 Python API:
init_recognizer: 使用配置文件和权重文件初始化一个识别器
inference_recognizer: 对给定视频进行推理
下面是一个使用 Kinitics-400 预训练权重构建模型并对给定视频进行推理的示例
from mmaction.apis import inference_recognizer, init_recognizer
config_path = 'configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb.py'
checkpoint_path = 'https://download.openmmlab.com/mmaction/v1.0/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb/tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb_20220906-2692d16c.pth' # 可以是本地路径
img_path = 'demo/demo.mp4' # 您可以指定自己的图片路径
# 从配置文件和权重文件中构建模型
model = init_recognizer(config_path, checkpoint_path, device="cpu") # device 可以是 'cuda:0'
# 对单个视频进行测试
result = inference_recognizer(model, img_path)
# result 是一个包含 pred_scores 的字典,概率最高的在pred_scores中索引为6
print(result)
使用 Python 文件作为配置文件,可以在 $MMAction2/configs 目录下找到所有提供的配置文件,可以运行 python tools/analysis_tools/print_config.py /PATH/TO/CONFIG 来查看完整的配置文件。
在使用 tools/train.py 或 tools/test.py 提交作业时,您可以通过指定 --cfg-options 来原地修改配置。
可以按照原始配置中字典键的顺序来指定配置选项。 例如,--cfg-options model.backbone.norm_eval=False 将模型骨干中的所有 BN 模块更改为 train 模式。
一些配置字典在配置文件中以列表形式组成。例如,训练流程 train_pipeline 通常是一个列表, 例如 [dict(type='SampleFrames'), ...]。如果您想要在流程中将 'SampleFrames' 更改为 'DenseSampleFrames', 您可以指定 --cfg-options train_pipeline.0.type=DenseSampleFrames。
如果要更新的值是列表或元组。例如,配置文件通常设置 model.data_preprocessor.mean=[123.675, 116.28, 103.53]。如果您想要 更改此键,您可以指定 --cfg-options model.data_preprocessor.mean="[128,128,128]"。请注意,引号 ” 是支持列表/元组数据类型的必需内容。
configs/base 下有 3 种基本组件类型,即 models、schedules 和 default_runtime。 许多方法只需要一个模型、一个训练计划和一个默认运行时组件就可以轻松构建,如 TSN、I3D、SlowOnly 等。 由 base 组件组成的配置文件被称为 primitive。
对于同一文件夹下的所有配置文件,建议只有一个 primitive 配置文件。其他所有配置文件都应该继承自 primitive 配置文件。这样,继承级别的最大值为 3。
为了方便理解,我们建议贡献者继承现有方法。 例如,如果基于 TSN 进行了一些修改,用户可以首先通过指定 base = ../tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py 来继承基本的 TSN 结构,然后在配置文件中修改必要的字段。
如果您正在构建一个与任何现有方法的结构不共享的全新方法,可以在 configs/TASK 下创建一个文件夹
配置文件名分为几个部分,不同部分逻辑上用下划线 '' 连接,同一部分的设置用破折号 '-' 连接 {算法信息}{模块信息}{训练信息}{数据信息}.py {xxx} 是必填字段,[yyy] 是可选字段
{算法信息}: {模型}: 模型类型,例如 tsn、i3d、swin、vit 等。 [模型设置]: 某些模型的特定设置,例如 base、p16、w877 等。
{模块信息}: [预训练信息]: 预训练信息,例如 kinetics400-pretrained、in1k-pre 等。 {骨干网络}: 骨干网络类型,例如 r50(ResNet-50)等。 [骨干网络设置]: 某些骨干网络的特定设置,例如 nl-dot-product、bnfrozen、nopool 等。
{训练信息}: {gpu x batch_per_gpu]}: GPU 和每个 GPU 上的样本数。 {pipeline设置}: 帧采样设置,例如 dense、{clip_len}x{frame_interval}x{num_clips}、u48 等。 {schedule}: 训练计划,例如 coslr-20e。
{数据信息}: {数据集}: 数据集名称,例如 kinetics400、mmit 等。 {模态}: 数据模态,例如 rgb、flow、keypoint-2d 等。
点击跳转官方文档
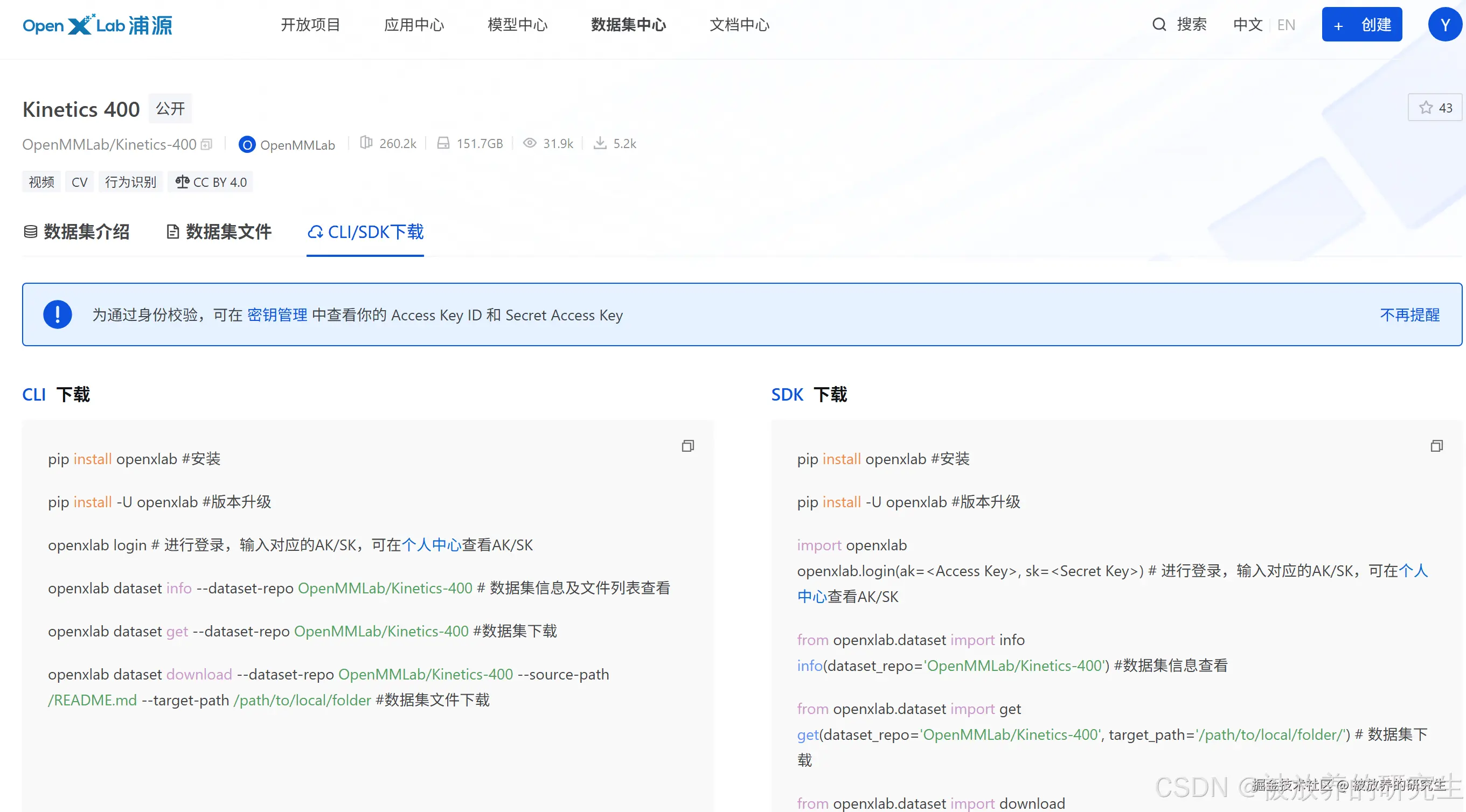
openxlab dataset get --dataset-repo username/repo-name
--target-path /path/to/local/folder
openxlab dataset get -r username/repo-name
-t /path/to/local/folder
openxlab dataset download --dataset-repo username/repo-name
--source-path /train/file
--target-path /path/to/local/folder
openxlab dataset download -r username/repo-name
-s /train/file
-t /path/to/local/folder
其中:
| 参数 | 缩写 | 是否必填 | 参数类型 | 参数说明 | 示例 |
|---|---|---|---|---|---|
| dataset-repo | -r | 是 | String | 数据集仓库的地址,由 username/repo_name 组成 | zhangsan/repo-name |
| source-path | -s | 是 | String | 对应数据集仓库下文件的相对路径 | -s /train/file |
| target-path | -t | 否 | String | 下载仓库指定的本地路径 | --target-path /path/to/local/folder |
from openxlab.dataset import get
get(dataset_repo='username/repo_name', target_path='/path/to/local/folder')
from openxlab.dataset import download
download(dataset_repo='username/repo_name', source_path='/train/file', target_path='/path/to/local/folder')
其中:
| 参数 | 缩写 | 是否必填 | 参数类型 | 参数说明 | 示例 |
|---|---|---|---|---|---|
| dataset | _repo -r | 是 | String | 数据集仓库的地址,由 username/repo_name 组成 | zhangsan/repo-name |
| source_path | -s | 是 | String | 对应数据集仓库下文件的相对路径 | -s /path/to/local/folder |
| target_path | -t | 否 | String | 下载仓库指定的本地路径 | --target-path /path/to/local/folder |

