
找房a+软件
95.75MB · 2025-12-16

本文系统梳理了检索增强生成(RAG)架构的演进历程,从基础架构到智能化解决方案的迭代路径。文章通过对比Naive RAG、Advanced RAG、Modular RAG和Agentic RAG四代架构的核心特点与技术突破,揭示了RAG技术如何通过模块化设计、智能体协同等创新解决知识更新、语义对齐和复杂任务处理等关键问题,为LLM应用落地提供重要参考。由于作者水平有限,若相关理解有误请以实际为准。
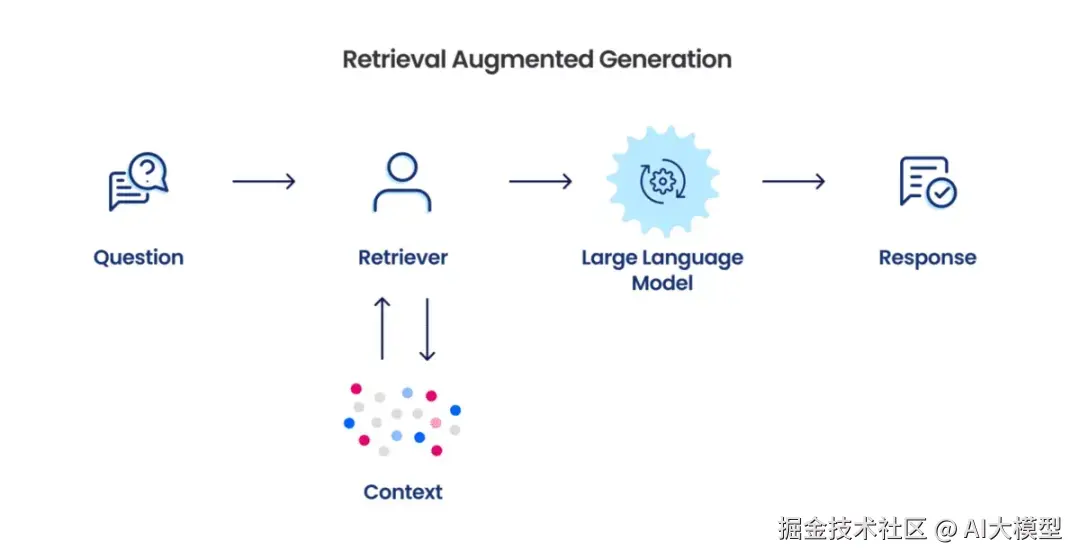
1.1 什么是RAG(维基)
简易RAG流程
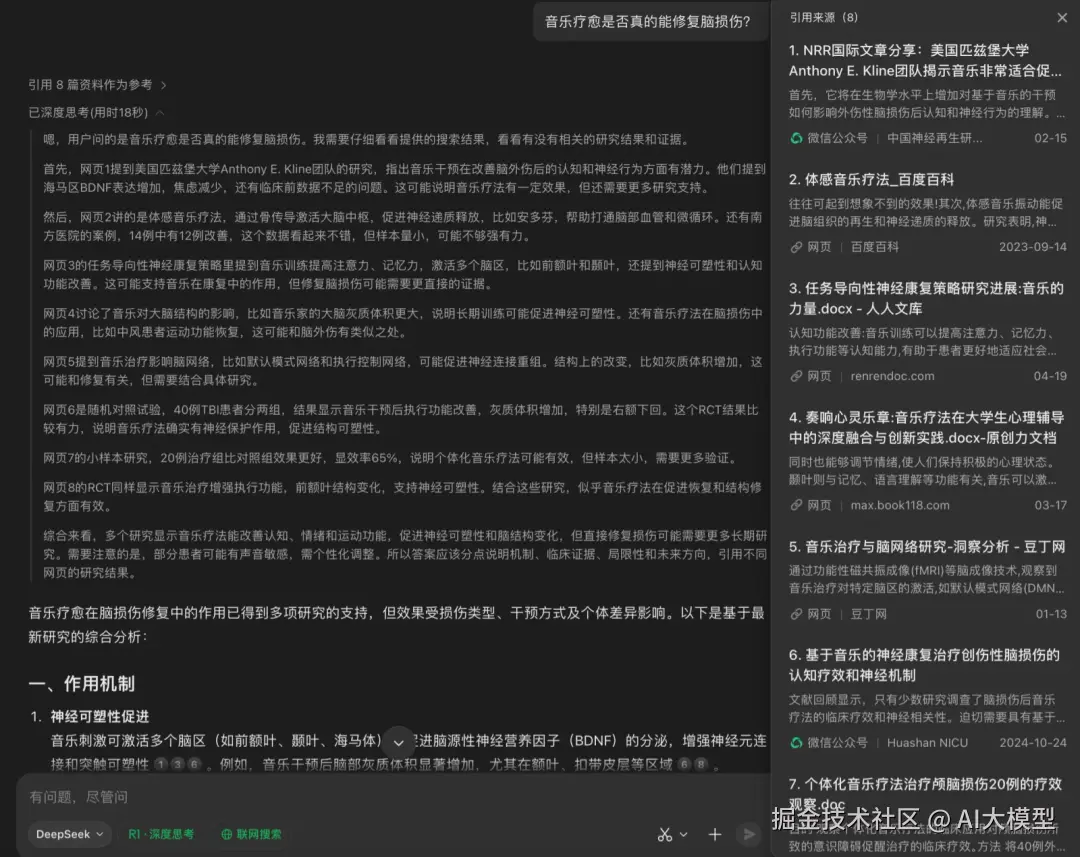
元宝 RAG示例
1.2 为什么需要RAG
1、LLM的已知问题
RAG是解决上述问题的一种比较轻量的解决方案。
2、RAG优点
3、RAG缺点
Navie RAG -> Advanced RAG -> Modular RAG -> Agentic RAG
2.1 Navie RAG
2.1.1 来源
最早由meta在论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中提出,提出的原因为: 大规模预训练语言模型(LLM)虽在下游任务上表现优异,但由于知识存储在参数中,无法及时更新且易出现“幻觉”(hallucination);为此,引入外部可检索的非参数化记忆(如 Wikipedia 向量索引),并将检索结果与生成模型结合,从而提升知识密集型任务的准确性与可追溯性。
2.1.2 介绍
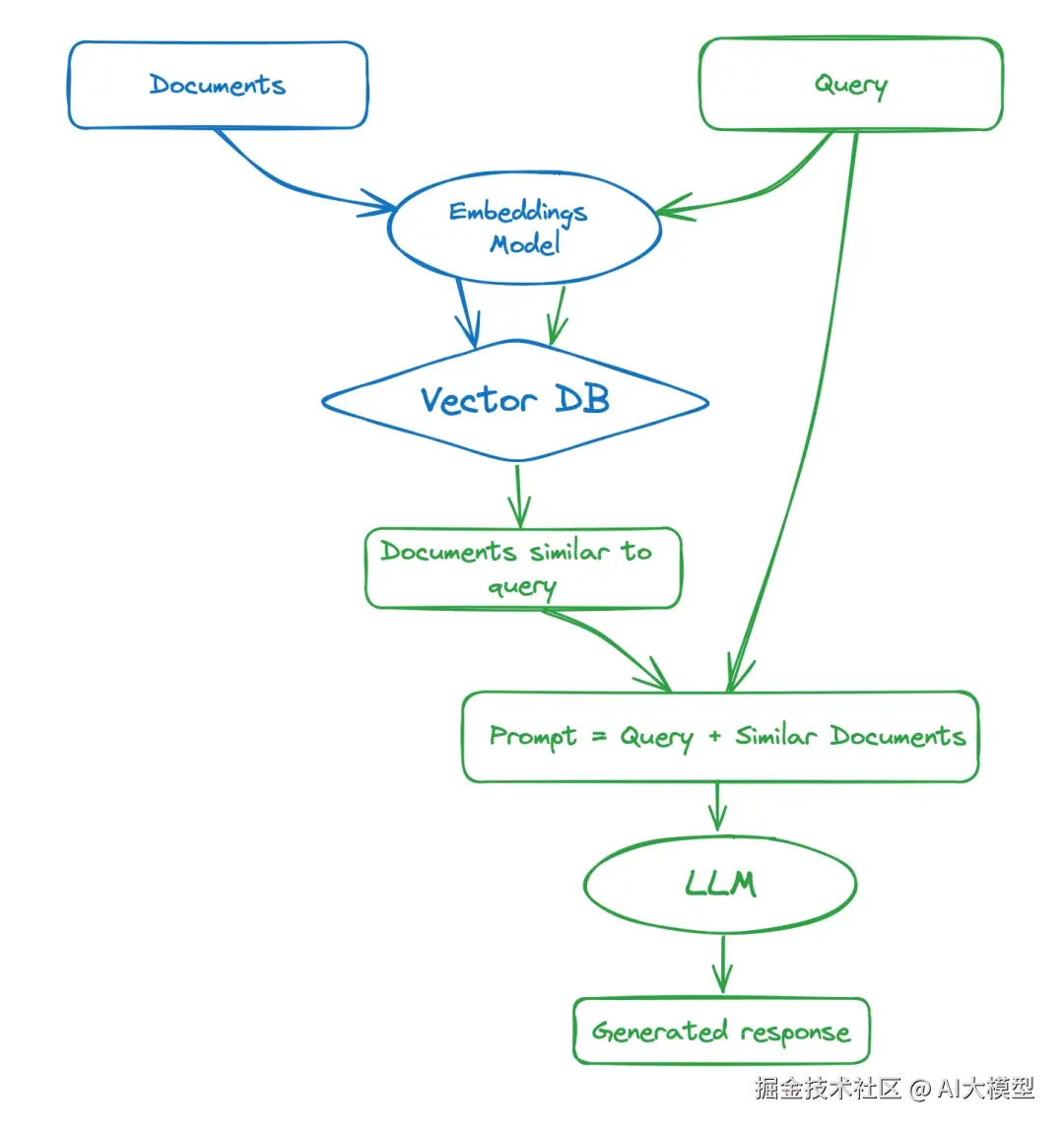
最简单的架构,只包含3个阶段:Indexing -> Retrieval -> Generation.
流程
1、索引构建(离线)
2、在线检索(在线)
缺点
2.2 Advanced RAG
2.2.1 来源
没有明确的提出者,在Navie RAG架构之后由多方逐步演进得到,如微软研究院提出HyDE,谷歌引入Rerank,以及如Elastic和Cohere公司提出的各种优化技术等,由多方共同构成Advanced RAG技术体系. 这些优化技术提出的动因,主要是由于Navie RAG仍存在一系列问题,如
2.2.2 介绍
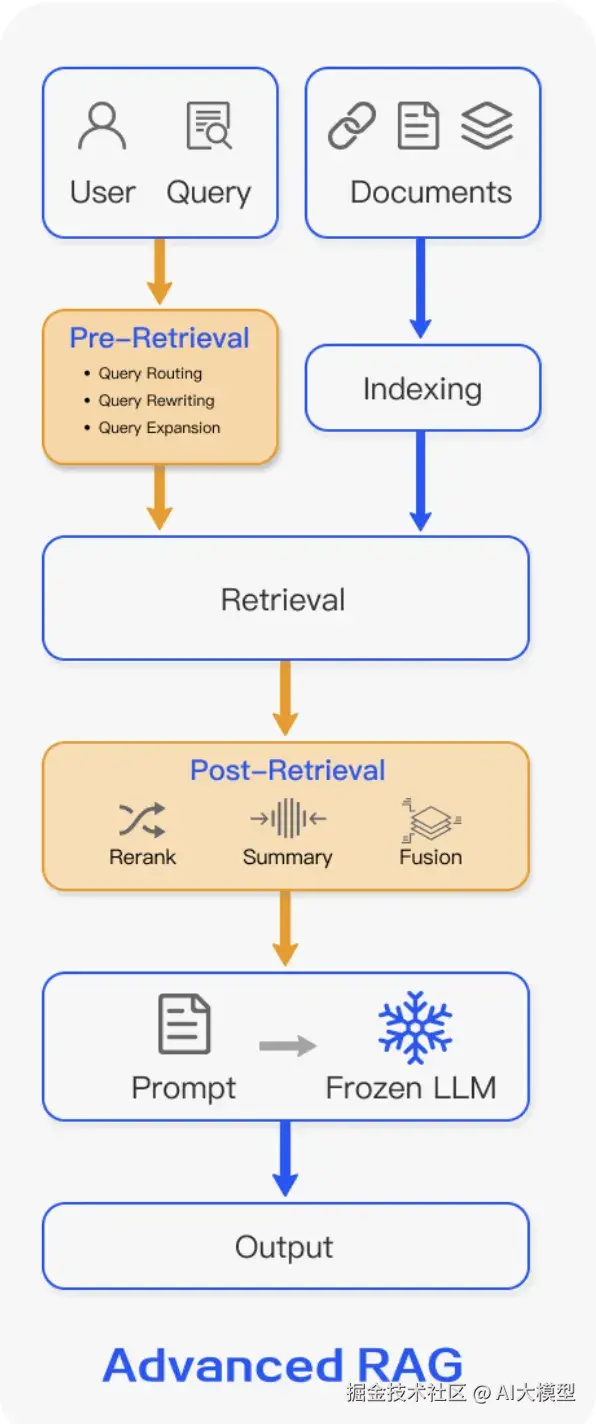
基于Navie Rag增加两个步骤,包含5个阶段:Indexing -> Pre Retrieval -> Retrievel -> Post Retrievel -> Generation,旨在解决文档召回的质量和准确率。Navie RAG属于Advanced Rag的一个特化,即Pre Retrievel和Post Retrievel为空。
1、Pre-Retrieval
预检索处理: 侧重数据索引优化。
2、Post-Retrievel
后检索处理: 侧重数据结果的二次加工&过滤
重排序Rerank
对检索出的文档做更精细的评估,将真正最匹配意图的文档排列到前面,尽可能减少噪声
上下文压缩Prompt Compression
若检索出大量文档,在输送给LLM之前可能还需要对文档做裁切,仅保留最关键核心的内容
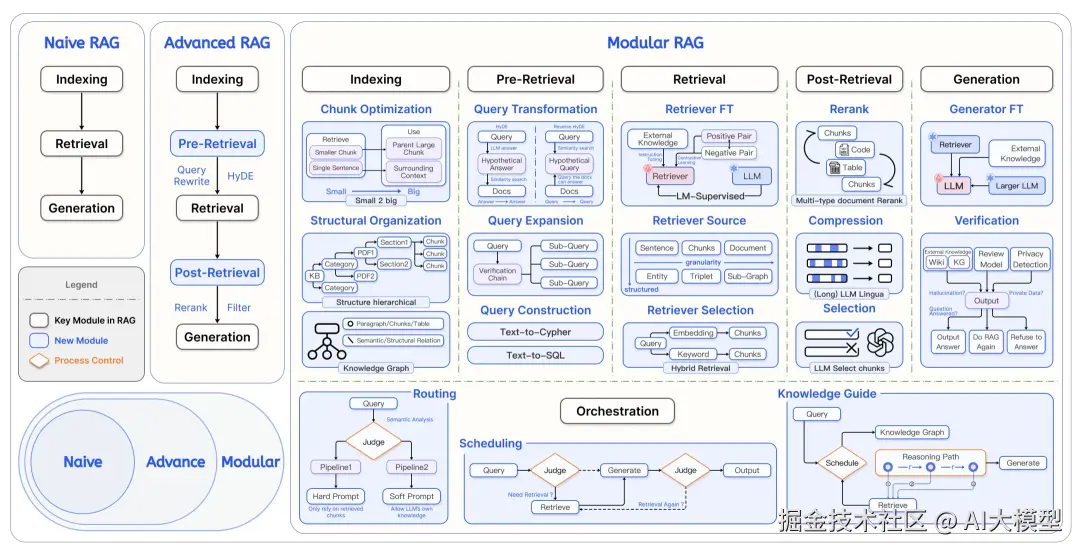
2.3 Modular RAG
2.3.1 来源
Modular RAG 最早由 Yunfan Gao 等人在 2024 年 7 月的论文《Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks》中首次系统化提出。提出的动因有:
对比Advanced RAG架构,该框架将系统各个部分抽象单独的模块与算子,实现模块可复用,易扩展及维护的RAG架构。
2.3.2 介绍
模块化RAG,将 RAG 系统分为 Module Type、Module 和 Operators 三层结构。每个 Module Type 代表 RAG 系统中的一个核心流程,包含多个功能模块。每个功能模块反过来都包含多个特定的运算符。整个 RAG 系统变成了多个模块和相应运算符的排列组合,形成了我们所说的 RAG Flow。整体有7个部分:Indexing, Pre Retrieval, Retrievel, Post Retrievel, Memory, Generation, Orchestration.这种范式在基于Advanced RAG的横向架构上引入了纵向的结构,即Module和Operators。
Orchestration是Modular RAG区分Advanced RAG的一个重要部分,而Memory模块虽然在原论文没有提及,但笔者认为也是Modular RAG的一个重要组成部分,用于赋予RAG系统的长期记忆能力
def _cosine_similarity(query_vec, doc_vec): # 操作符
return np.dot(query_vec, doc_vec) / (np.linalg.norm(query_vec)*np.linalg.norm(doc_vec))
关键区别
Modular Rag 举个例子
1、代码示例,使用haystack官方示例。
##################
### 0. 组件定义 ###
##################
from haystack import Document, Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
document_store = InMemoryDocumentStore(embedding_similarity_function="cosine")
text_embedder = SentenceTransformersTextEmbedder()
retriever = InMemoryEmbeddingRetriever(document_store=document_store)
##################
### 1. 添加组件 ###
##################
query_pipeline = Pipeline()
query_pipeline.add_component("component_name", component_type)
# Here is an example of how you'd add the components initialized in step 2 above:
query_pipeline.add_component("text_embedder", text_embedder)
query_pipeline.add_component("retriever", retriever)
# You could also add components without initializing them before:
query_pipeline.add_component("text_embedder", SentenceTransformersTextEmbedder())
query_pipeline.add_component("retriever", InMemoryEmbeddingRetriever(document_store=document_store))
##################
### 2. 连接组件 ###
##################
# This is the syntax to connect components. Here you're connecting output1 of component1 to input1 of component2:
pipeline.connect("component1.output1", "component2.input1")
# If both components have only one output and input, you can just pass their names:
pipeline.connect("component1", "component2")
# If one of the components has only one output but the other has multiple inputs,
# you can pass just the name of the component with a single output, but for the component with
# multiple inputs, you must specify which input you want to connect
# Here, component1 has only one output, but component2 has mulitiple inputs:
pipeline.connect("component1", "component2.input1")
# And here's how it should look like for the semantic document search pipeline we're using as an example:
pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
# Because the InMemoryEmbeddingRetriever only has one input, this is also correct:
pipeline.connect("text_embedder.embedding", "retriever")
2、可视化示例,使用LangFlow。
Modular RAG下的RAG流
各个模块之间的协作,可以有类似以下的工作流模式串联
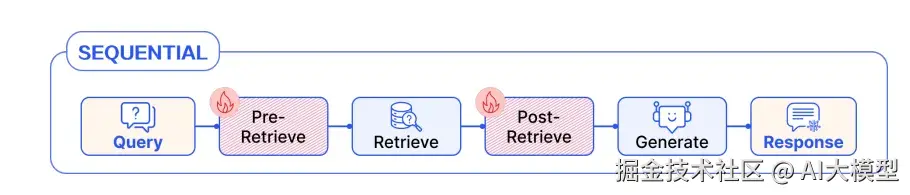
1、线性编排(Linear Pattern)
整个RAG流由各个Module线性串联起来,为最简单的模式。
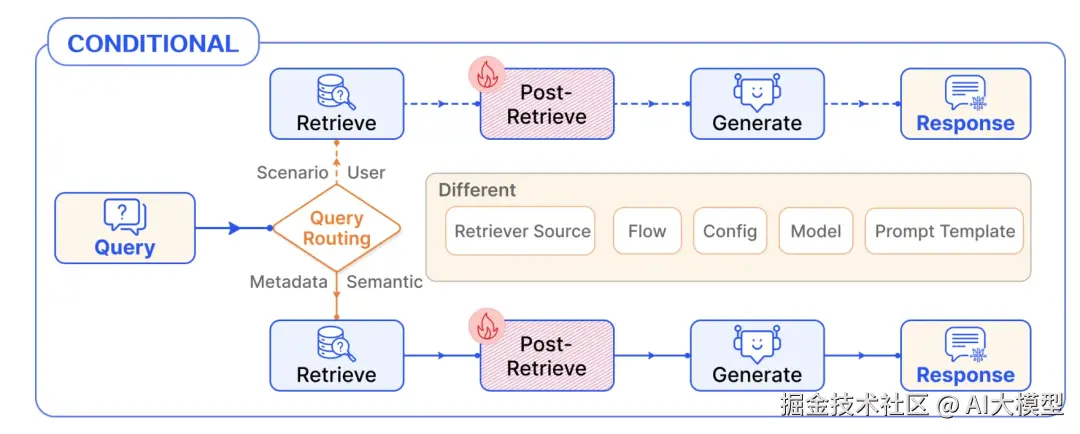
2、条件编排(Conditional Pattern)
RAG流中会添加一些Route条件判断,增强系统的灵活性。
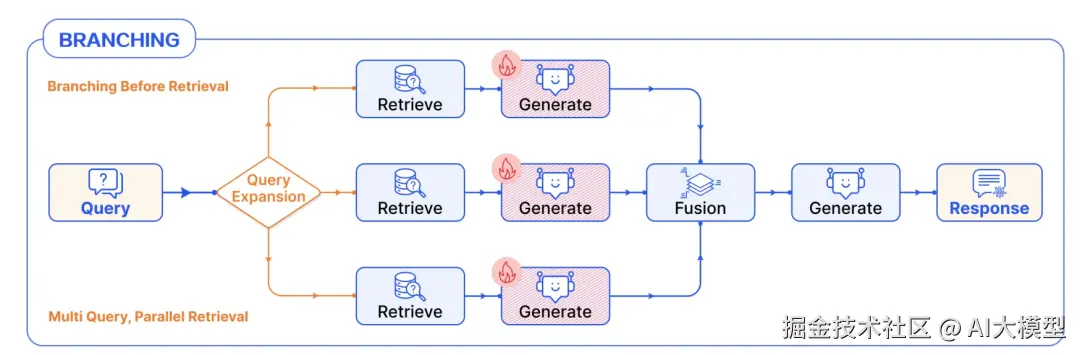
3、分支(并行)编排(Branching)
RAG流中存在多个并行的分支,各自处理后随之合并到一起,这种情况多用于要增加生成结果的多样性而引入
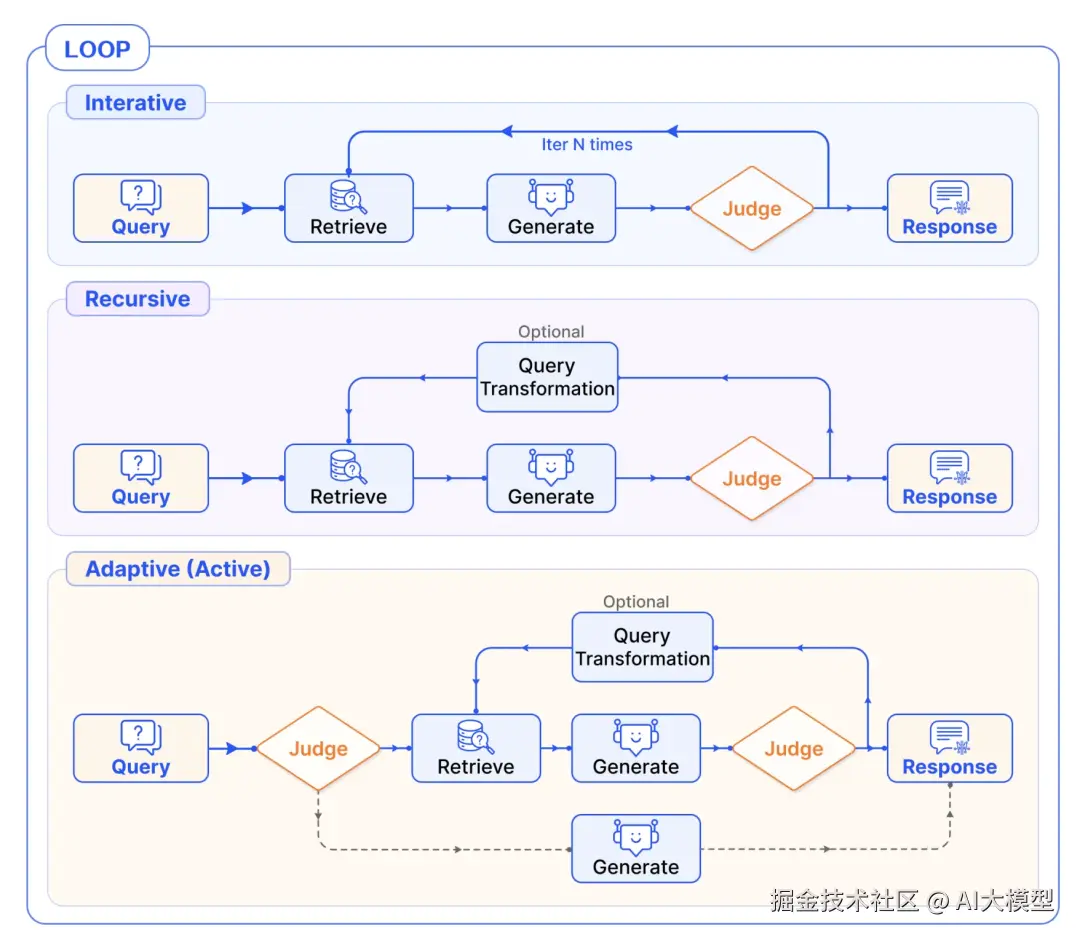
4、循环编排(Loop Pattern)
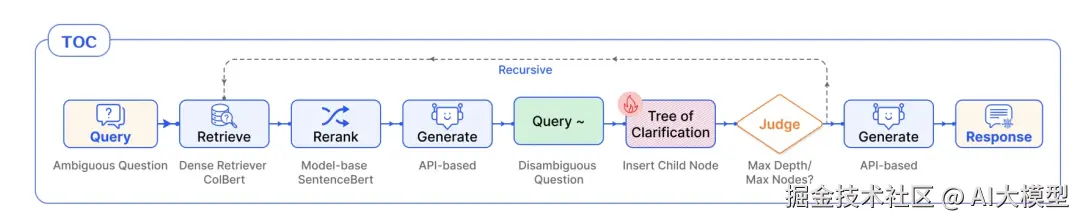
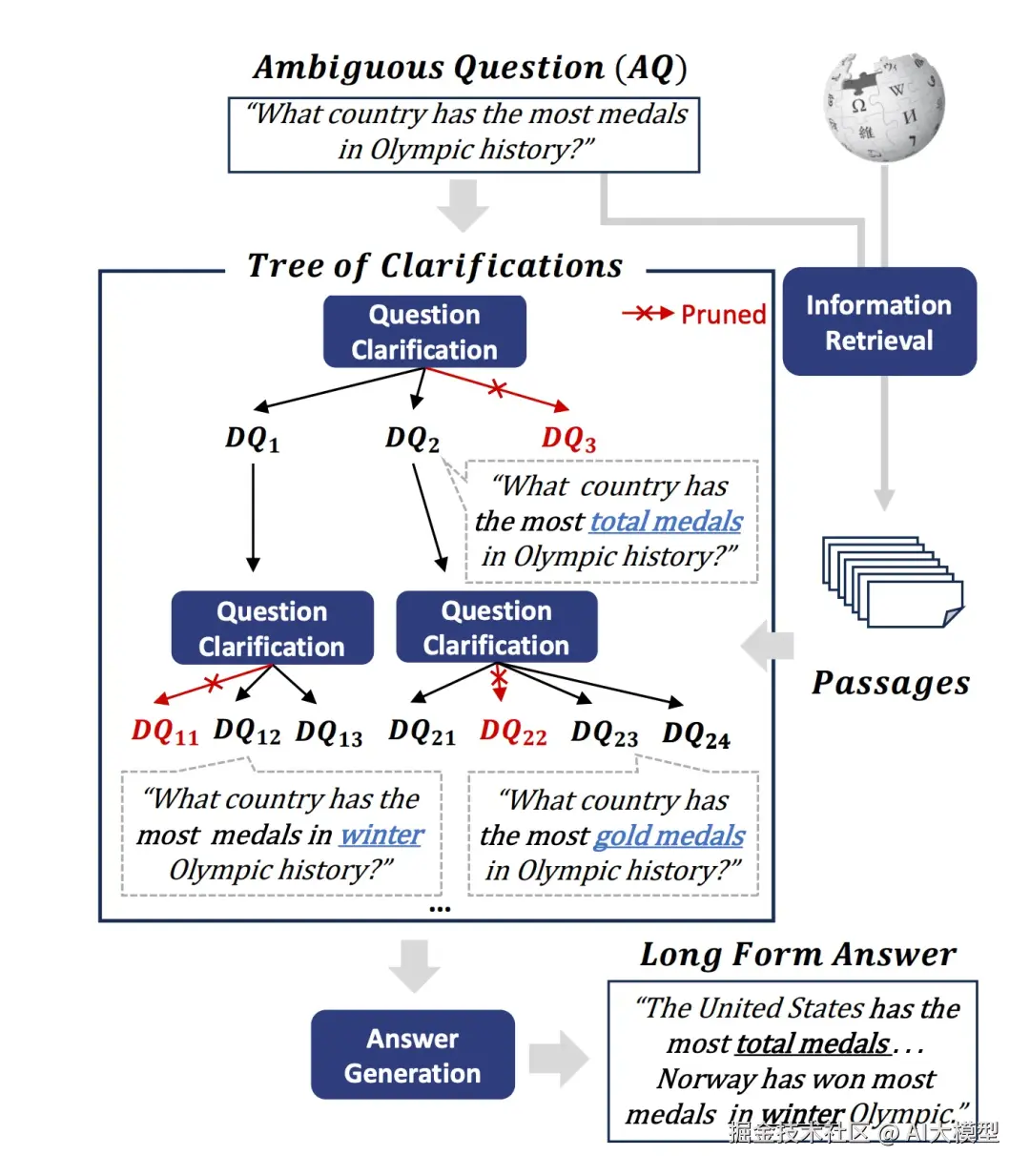
TOC RAG流,一种rescursive retrieval的实现
Tree of Clarification
Interative和rescursive的比较:
| 维度 | Interative | rescursive |
| 核心 | 在检索和生成之间交替执行,多次循环逐步迭代出更优结果 | 不断将复杂问题拆解成简单子问题,并逐层整合子答案生成最终结果 |
| 场景 | 需要逐步细化答案的开放性问题(如模糊查询、多意图混合问题) | 需多跳推理的复杂问题(如技术文档分析、法律条款追溯) |
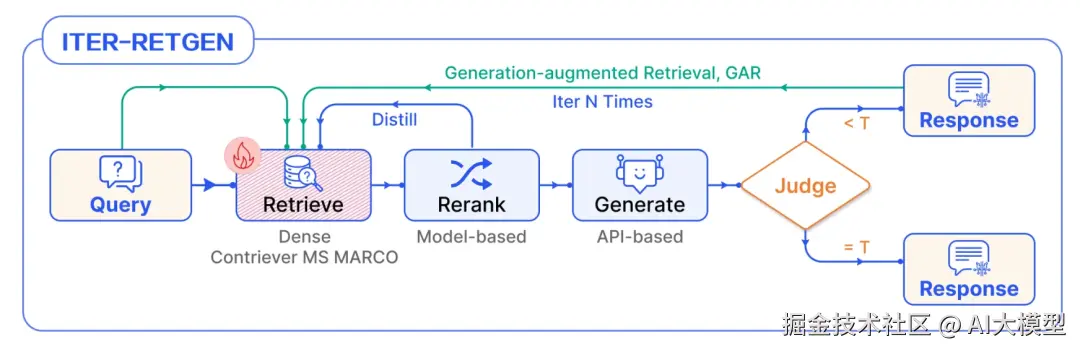
tuning模式
RAG系统在各个Module都可能使用了LLM技术,使用数据微调以优化各个LLM组件的表现,包括:
2.4 Agentic RAG
2.4.1 来源
最早Chidaksh Ravuru 等人于 2024 年 8 月 18 日在 arXiv 上发表的论文《Agentic Retrieval-Augmented Generation for Time Series Analysis》中正式提出。 提出动因:
对比传统RAG, Agentic RAG将能力依托于智能体,提升了RAG系统的灵活性及扩展其应用边界。
2.4.2 介绍
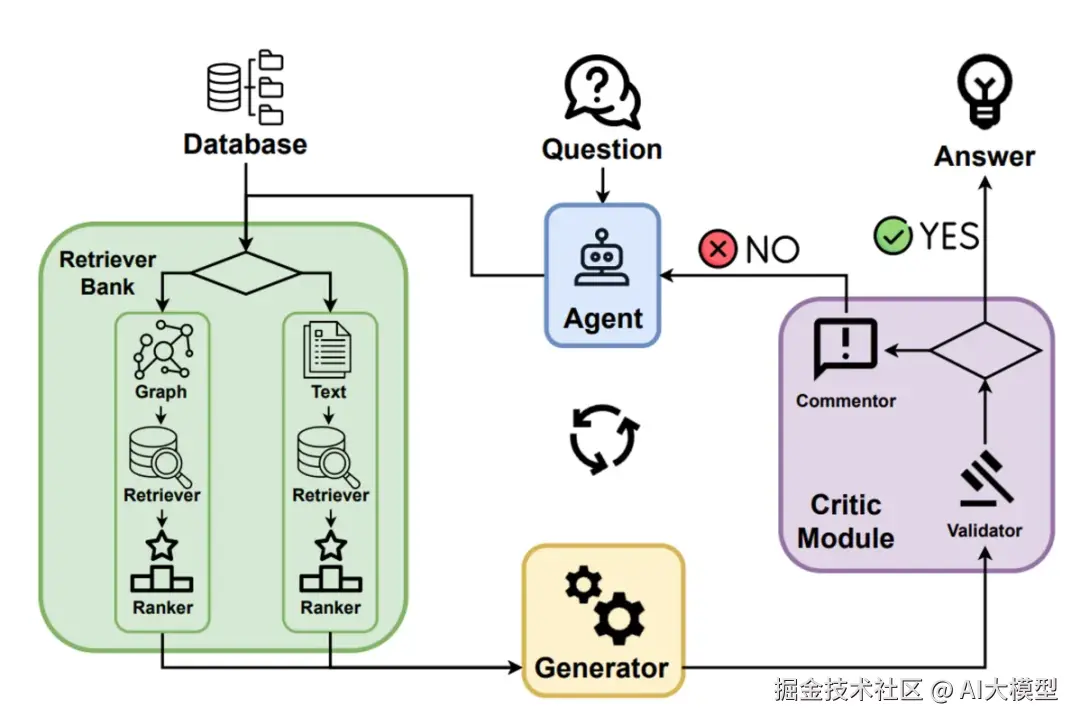
Agentic RAG:架构上引入Agent的思路,实现动态决策(如是否检索、工具调用)和多轮迭代优化。相比上述提到的几种RAG,Agentic RAG将实际输入处理的多样性交给LLM处理,可以解决更复杂的问题。
Agent的核心部件:LLM + Memory + Planning + Tools
如何运作?
从Modular RAG的架构来看,只要是涉及LLM的模块理论上都可以使用Agent来增强,但在该Agentic RAG架构中更多强调的是在retrievel模块中使用。 在检索阶段,不同数据源可以视作不同的tool,然后由检索Agent集成这些tool动态检索内容
一些Agent Agentic RAG架构
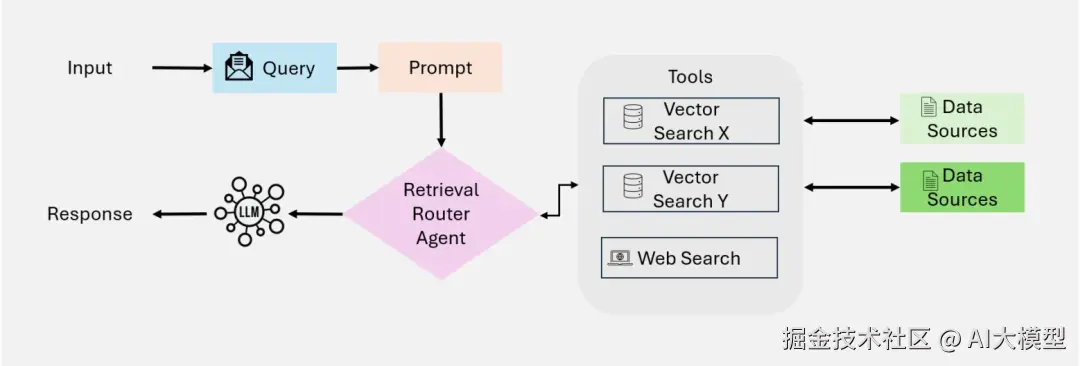
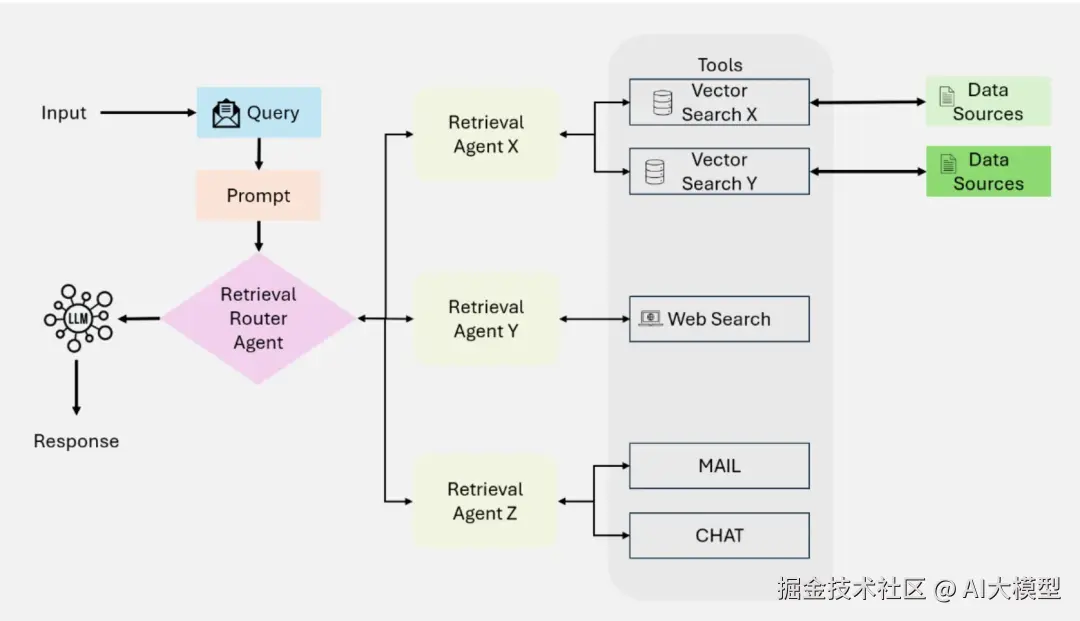
Single-Agent Agentic RAG
该框架核心是一个系统决策中心的Router Agent,该Agent动态处理信息检索,集成操作,类似上述Modular RAG中提到的条件编排的Agent代理版本,比较适用于多检索源的简单问答场景。
Multi-Agent Agentic RAG
为Single-Agent Agentic RAG架构的演进版本,用多个专用代理来细化更复杂的工作流和不同的查询类型。核心Router Agent下又挂接了多个检索Agent, 如Agent1用于查询结构化数据(Mysql),Agent2用于查询非结构化数据,Agent3用于Web查询或专用API查询等。
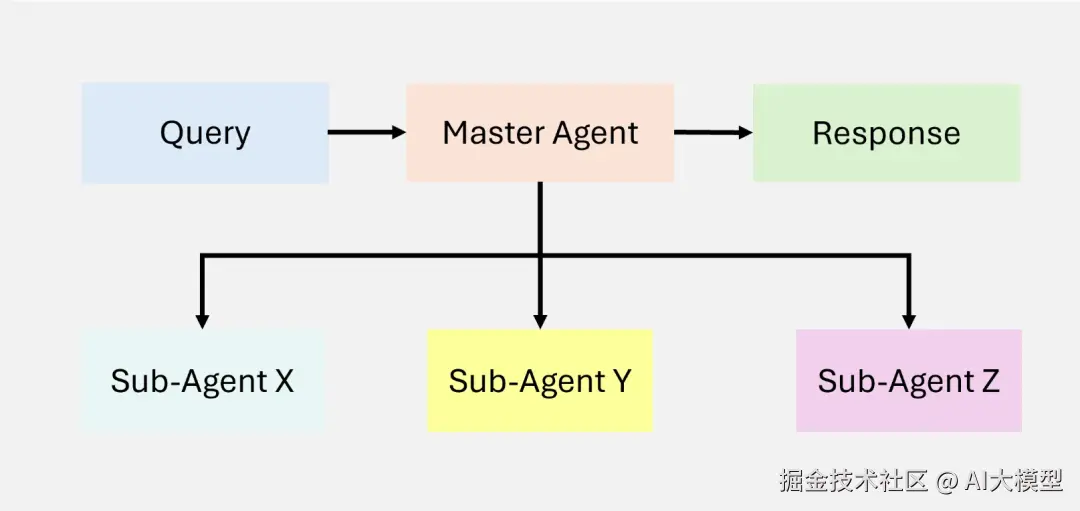
分层代理RAG,为Multi-Agent Agentic RAG架构的拓展,将整个系统分为多个层级的Agent,由顶级Agent驱动子Agent,并聚合子Agent的结果。
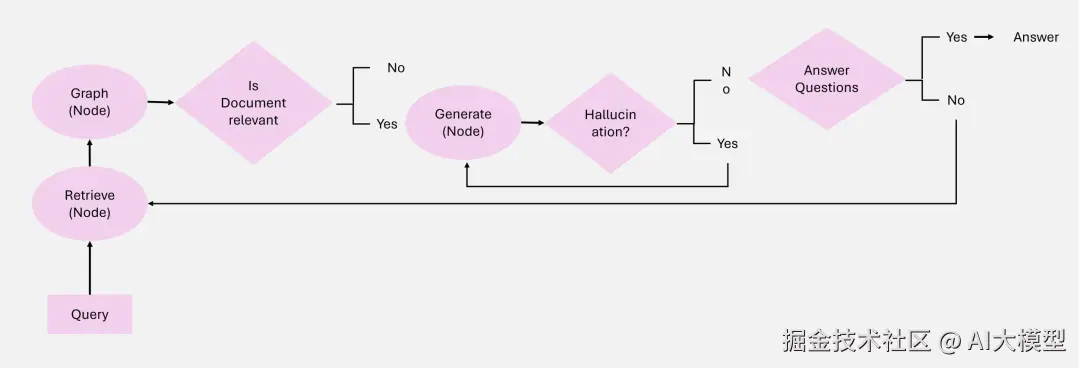
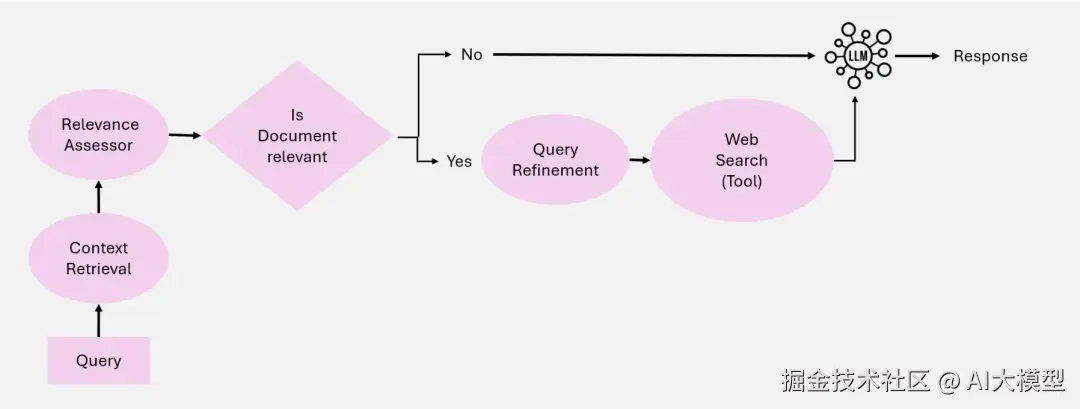
Corrective RAG的核心是他可以动态评估检索到的文档并纠正查询,提升检索文档的质量。
Agentic Corrective RAG系统建立在5个关键Agent上。
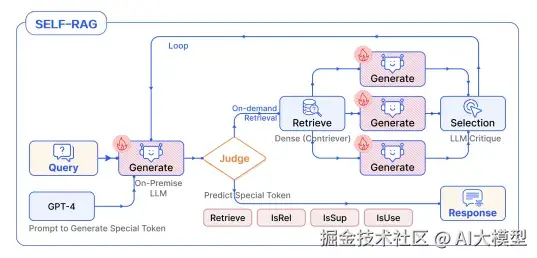
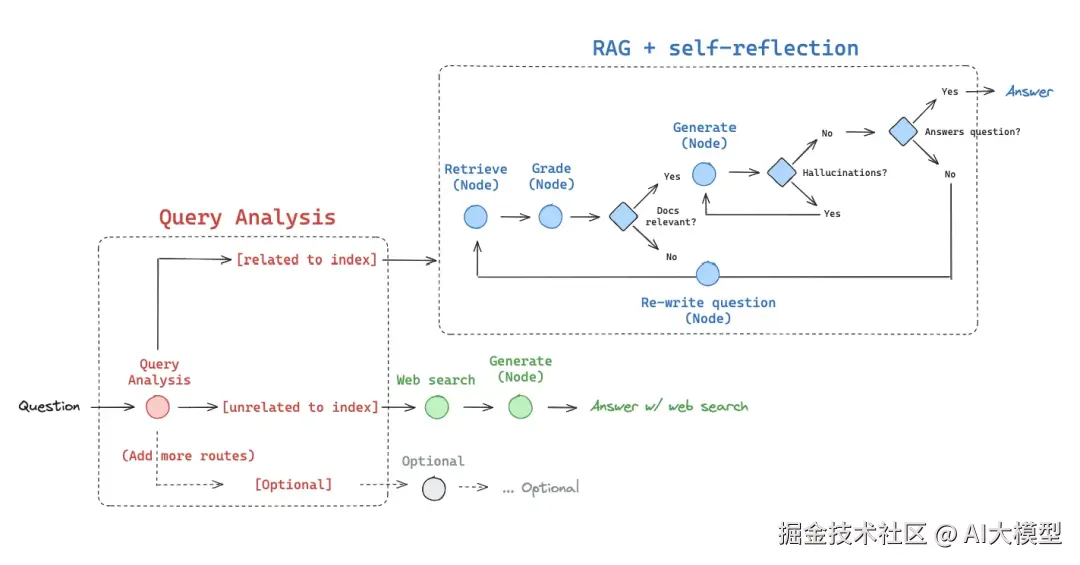
自适应Agent RAG, 与上述Modular RAG中的Adaptive retrieval一样,语义上都是在各个环节引入了LLM判断,并在引入LLM评测实现Loop自迭代。
Graph-Based Agentic RAG在检索中引入了图检索,合并图数据及其他检索数据增强检索效果
| 架构 | 提出动因 | 主要特点 |
| Naive RAG | LLM 容易“幻觉”,参数化知识难更新;需外部检索补充知识并提供可追溯的证据。 | - 三步流程:文档切块 → 向量检索 → 拼接提示生成 - 一体化端到端微调(RAG-Sequence & RAG-Token) - 减少参数化模型的幻觉,提升开放域 QA 准确率 |
| Advanced RAG | 用户查询与知识库语义不对齐;Naive RAG 检索噪声多、生成质量有限。 | - 预检索(Pre Retrieval):查询重写/扩展 (Rewrite) - 检索(Retrieval):语义向量检索 - 后检索(Post Retrieval):结果重排序、摘要压缩 |
| Modular RAG | 随着检索器、LLM 等组件飞速迭代,传统管道难快速集成新功能、维护成本高。 | - 七大模块: Indexing, Pre Retrieval, Retrievel, Post Retrievel, Memory, Generation, Orchestration - 将检索、重排序、压缩、生成等拆分为可插拔模块 - 引入路由、调度、融合算子 - 模块化设计,灵活扩展,支持多种 RAG 模式(线性、条件、分支、循环) |
| Agentic RAG | 需处理复杂多步任务、多轮决策,单轮静态流程不够;希望结合检索与规划能力。 | - 多智能体架构:主智能体协调子智能体 - 动态决策:自主判断何时检索、何时生成 - 支持多轮迭代、任务自校正,提高复杂任务的适应性与鲁棒性 |
Generation模块(LLM回答)的前后处理
在Advanced RAG中,为了提升最终回答效果从而引入了Pre-Retrieval和Post-Retrieval两个流程,或对回答LLM进行微调。从 “garbage in garbage out”理论来看,实际落地时,需要充分考虑业务属性,提升输入LLM的数据质量。
RAG系统设计的模块化&可插拔
由于RAG系统的不确定性(引入LLM),在构建自己的RAG系统时,可参考Modular RAG思维使用模块化设计,便于快速切换某环节中的Module后验证整体系统效果。
Agent的不稳定,实际业务落地存在不确定性
当前由于模型能力的瓶颈,Agent系统存在极大的不确定性,在Agentic RAG系统中,在大的层面引入Agent对实际业务落地不太可取,可考虑在某个小环节中引入,如Generation问答补充(在基于检索出的文档后,动态给定一些tools让其优化回答效果)。

