




手机亦云小慧
117.33MB · 2025-12-20

vue3.5.13
core
├─ packages
│ ├─ compiler-core # 核心编译器: 模板编译优化、AST转换、静态提升、Block Tree
│ ├─ compiler-dom # dom编译器: 浏览器端渲染,DOM操作API封装
│ ├─ compiler-sfc # 把单文件组件编译成为js代码. SFC: single file Component 单文件组件,以 .vue 进行结尾, SFC中包含三块,template、script、style等三块代码
│ ├─ compiler-ssr # 服务端渲染编译
│ ├─ reactivity # 响应式模式,可以和其它框架配合使用
│ ├─ runtime-core # 运行时核心实例相关代码: 组件渲染、虚拟DOM、VNode、patch、调度器
│ ├─ runtime-dom # 运行时dom相关API、属性、事件处理
│ ├─ runtime-test # 运行时测试相关代码
│ ├─ server-renderer # 服务器渲染
│ ├─ shared # 内部工具库,不对外暴露
│ ├─ vue # 面向公众的完整版本,包含运行时和编译器
│ └─ vue-compat # (即“迁移构建版本”) 是一个 Vue 3 的构建版本,提供了可配置的兼容 Vue 2 的行为。
源码三大核心 compiler丨reactivity丨runtime
compiler:程序编译时,源代码在被编译成为目标文件这段时间,在这里可以理解为我们将.vue文件编译成浏览器能识别的.js文件的一些工作。
runtime:程序运行时,即程序被编译了之后,在浏览器打开程序并运行它,直到程序关闭的这段时间的系列处理。
reactivity是响应式模块的源码
副作用函数:会产生副作用的函数,effect 函数的执行会直接或间接影响其他函数的执行,这时我们说 effect 函数产生了副作用, 例如一个函数修改了全局变量,这其实也是一个副作用.
响应式数据:
const obj = {name: '张三', age:34}
function effect () {
document.body.innerText = obj.name;
}
obj.name = '李梅';
如上面的代码所示,副作用函数 effect 会设置 body 元素的 innerText 属性,其值为 obj.name,当 obj.name 的值发生变化时,我们希望副作用函数 effect 会自动重新执行, obj就是响应式数据
当 obj.name 的值发生变化时, 我们希望副作用函数自动重新执行
如何才能让 obj 变成响应式数据呢?通过观察我们能发现两点线索:
使用Proxy劫持对象的读写操作(get/set/deleteProperty等)
Vue 3 使用 ES6 的 Proxy 代替 Vue 2 的Object.defineProperty() 来实现响应式,主要区别在于:
| 特性 | Vue 2 (Object.defineProperty) | Vue 3 (Proxy) |
|---|---|---|
| 核心方法 | Object.defineProperty | Proxy 和 Reflect |
| 性能 | 需要递归遍历所有属性,导致初始化慢 | 按需劫持,只在属性被访问时进行处理,性能更好 |
| 对象属性 | 无法监听新增或删除的属性 | 可以监听和响应新增或删除的属性 |
| 数组 | 无法监听通过下标设置新值或改变 length | 可以通过下标设置新值,也可以直接改变 length |
| 数据结构 | 不支持 Map 和 Set | 支持 Map 和 Set |
| 代码实现 | 需要将响应式数据放在 data 函数中返回的对象里 | 可以通过 reactive()、ref() 等函数来声明响应式数据 |
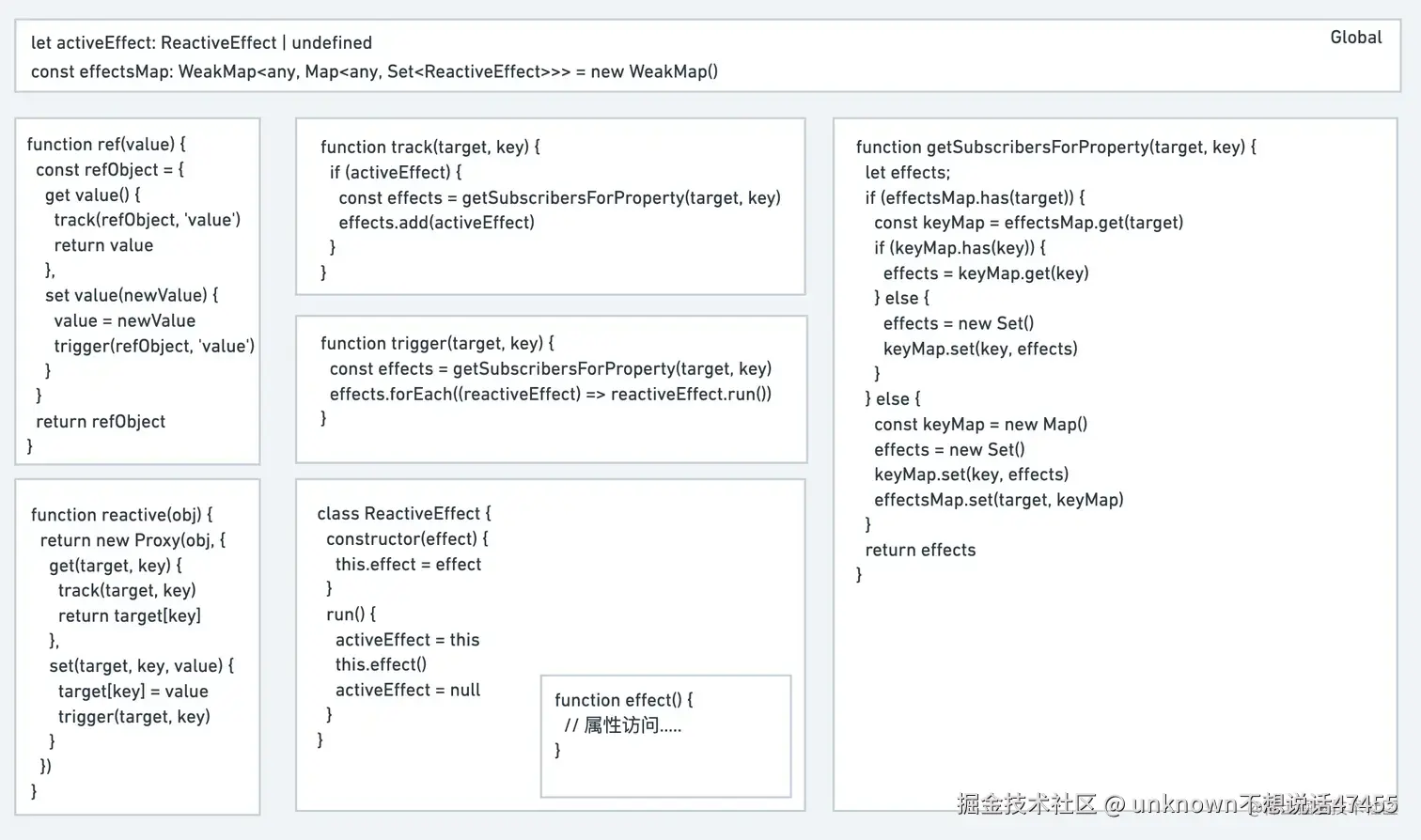
创建了一个用于存储副作用函数的桶 bucket,它是 Set 类型, 这样可以有多个effect函数
bucket需要考虑什么问题: 收集副作用函数依赖了哪几个属性; 某个属性又依赖了哪个副作用函数; 嵌套的effect与effect栈; 使用调度器解决: 连续多次修改响应式数据但只会触发一次更新;
一个响应数据,有多个副作用函数, 所以需要使用依赖收集和触发更新
Track:在属性被读取时,收集当前运行的副作用(effect)。
Trigger:在属性被修改时,触发所有关联的副作用重新执行。
bucket的层级化的依赖存储结构, obj内只更新变更的key的副作用函数们, 其他key没有变,对应的副作用函数们不要执行, 注意垃圾回收
通过WeakMap → Map → Set三级结构存储依赖关系,避免内存泄漏:
targetMap: WeakMap<Target, KeyToDepMap>
KeyToDepMap: Map<PropertyKey, Dep>
Dep: Set
reactivity/src
├── arrayInstrumentations.ts
├── baseHandlers.ts
├── collectionHandlers.ts
├── computed.ts
├── constants.ts
├── dep.ts
├── effect.ts
├── effectScope.ts
├── index.ts
├── reactive.ts
├── ref.ts
├── warning.ts
└── watch.ts
原文
图中右侧的一列是一些全局变量以及公共引用的函数,首先activeEffect和targetMap用于标识当前执行的Effect和存储对象属性和Effect绑定关系。createDep()用于首次新建一个集合保存Effect。trackEffects和triggerEffects用于绑定Effect和触发Effect。ReactiveEffect用于封装副作用。
图中左侧有三块,前两块分别对应了两类响应式对象reactive和ref的实现原理,第三块则是三种响应式副作用的实现原理,分别是:watch,watchEffect和页面渲染。角色都到齐了,接下来我们把他们之间的关系串一下。
reactive()基于Proxy实现,源码中创建了一个mutableHandler进行代理配置。在get中从targetMap中获取已有的Effect数据,然后通过trackEffects往里面追加activeEffect函数。在set中同样从tragetMap中获取已有的Effect数据,然后通过triggerEffects遍历执行。
ref()基于对象的Getter和Setter实现,源码中创建了一个类RefImpl进行封装,在getter中通过trackRefValue()->trackEffects()实现Effects的追加,在setter中通过triggerRefValue()->triggerEffects()实现Effect的触发。不同于reactive,ref将dep绑定在自己身上,并没有放在全局的tagetMap,这也比较合理,因为ref通常用于基础类型值的封装,只有一个属性value,并不需要一个Map来保存关系。
接下来介绍三种响应式副作用的创建原理,他们的共同点在于最终都是通过new ReactiveEffect()和effect.run()来实现Effect创建和绑定,而这个run()的过程就和上述讨论的一样,通过赋值activeEffect来实现。
首先我们分析watch()和watchEffect(),他们最大的不同在于watch不会立即执行副作用,watchEffect会立即执行。在源码中,两种都通过doWatch()实现,doWatch根据入参的不同区分要执行的是watch还是watchEffect。doWatch的源码比较复杂,这里我用了伪代码来代替,其中的关键在于doWatch会在传入的副作用基础上自行创建一个新的effect,如果是watch逻辑,那么effect就是()=>source.value,只用于激活绑定,如果是watchEffect逻辑,那么effect就等于source,直接执行传入的副作用。
那对于watch来说,effect既然是()=>source.value,那传入的副作用怎么执行呢?这就要说道ReactiveEffect的第二个参数scheduler了,doWatch将传入的副作用暂存在scheduler里面,当triggerEffects()执行的时候,会优先执行effect.scheduler()。
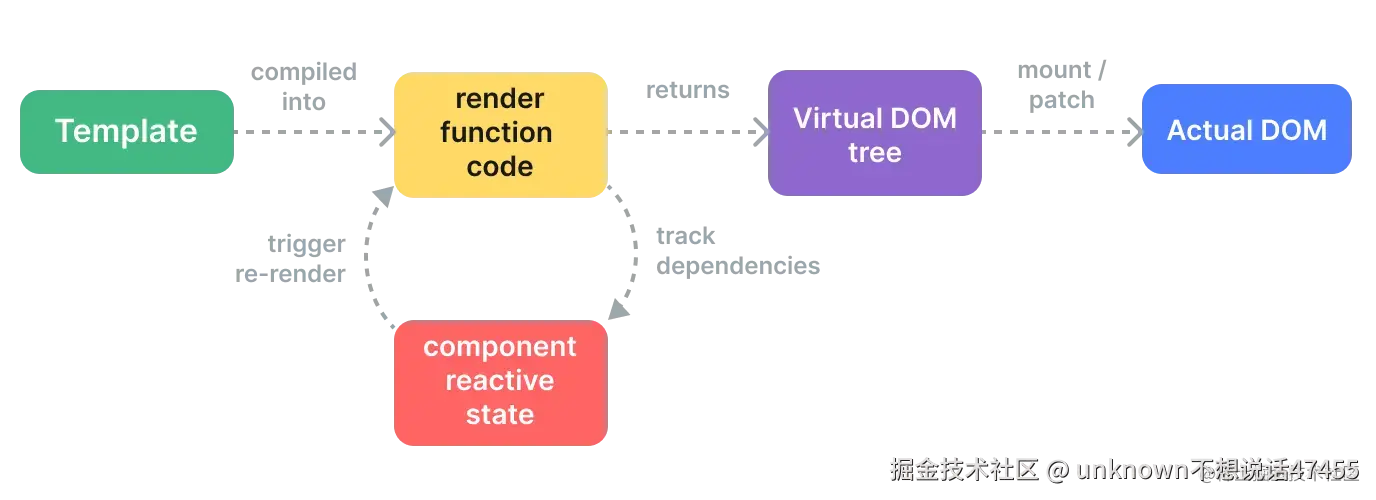
最后再谈谈页面渲染,MVVM最显著的特性就是数据驱动页面渲染,其实页面渲染也是一个函数,在Vue3中这个函数是patch(),作用是比对Vnode并生成DOM。既然页面渲染也是个函数,那就跟watch和watchEffect没什么两样,同样可以通过new ReactiveEffect()绑定到响应式对象上。
Vue3在创建页面过程中,首先会创建一个渲染器,渲染器内部最核心的就是patch()。渲染器创建的过程中会将patch()和createVNode()打包在componentUpdateFn()作为一个副作用进行类似watchEffect的绑定,核心逻辑在setupRenderEffect()之中,这样当数据发生变化的时候就会重新生成VNode,重新渲染页面。
通过分析源码,我们可以确认Vue3的响应式部分的确是围绕着响应式对象和响应式副作用这两个系统来进行架构的。
渲染流程原文
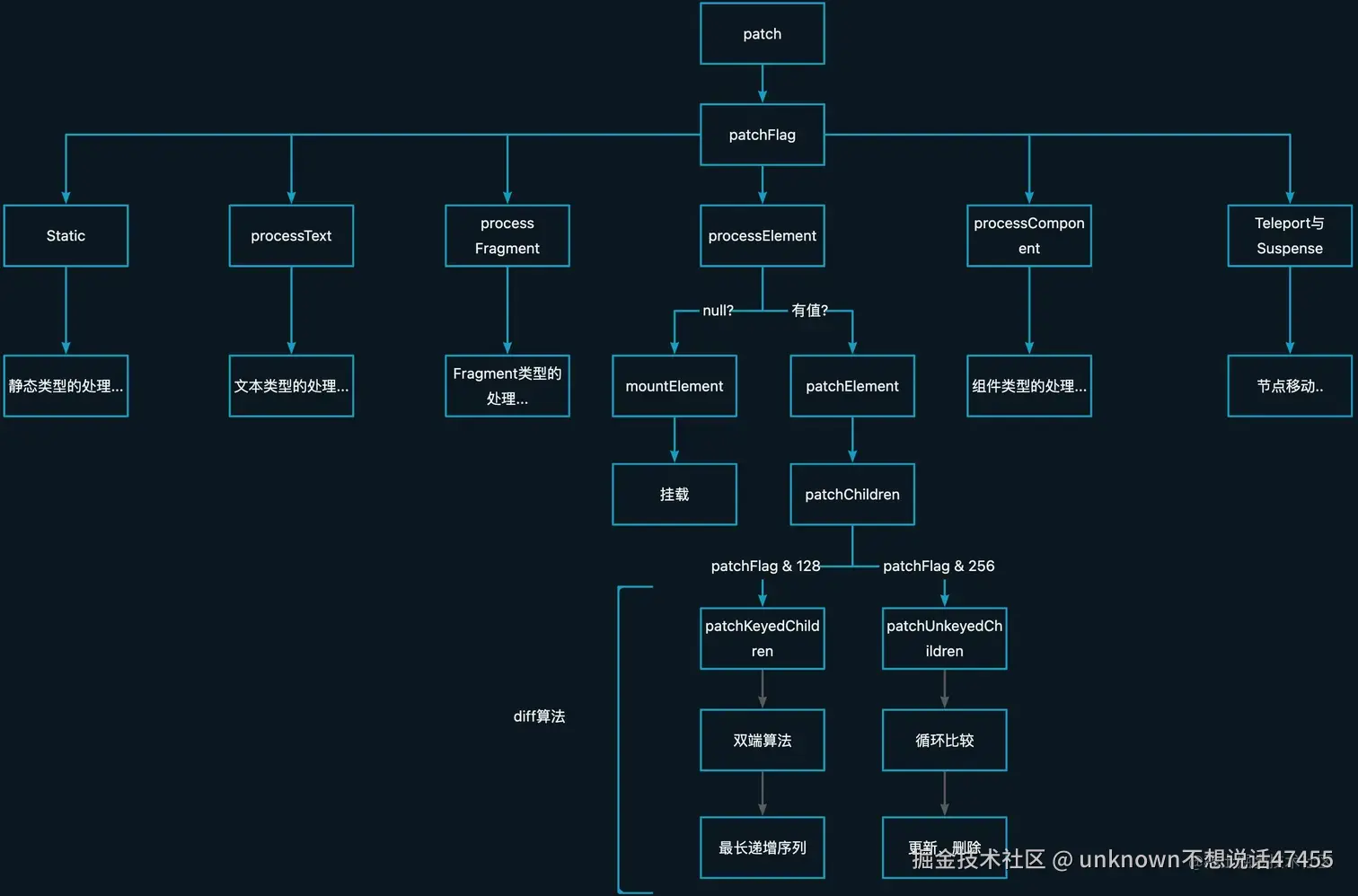
patch函数的核心处理逻辑图片原文
含有key属性主要用patchKeyedChildren策略进行新旧节点对比。 原理看下面的双端和快速diff原理
如果不使用key,Vue会使用一种最大限度减少动态元素并且尽可能的尝试就地修改/复用相同类型元素的策略。
这样就完成了patchUnkeyedChildren比较的过程。
const patchUnkeyedChildren = (
c1: VNode[],
c2: VNodeArrayChildren,
container: RendererElement,
anchor: RendererNode | null,
parentComponent: ComponentInternalInstance | null,
parentSuspense: SuspenseBoundary | null,
namespace: ElementNamespace,
slotScopeIds: string[] | null,
optimized: boolean,
) => {
c1 = c1 || EMPTY_ARR
c2 = c2 || EMPTY_ARR
const oldLength = c1.length
const newLength = c2.length
const commonLength = Math.min(oldLength, newLength)
let i
for (i = 0; i < commonLength; i++) {
const nextChild = (c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i]))
patch(
c1[i],
nextChild,
container,
null,
parentComponent,
parentSuspense,
namespace,
slotScopeIds,
optimized,
)
}
if (oldLength > newLength) {
// remove old
unmountChildren(
c1,
parentComponent,
parentSuspense,
true,
false,
commonLength,
)
} else {
// mount new
mountChildren(
c2,
container,
anchor,
parentComponent,
parentSuspense,
namespace,
slotScopeIds,
optimized,
commonLength,
)
}
}
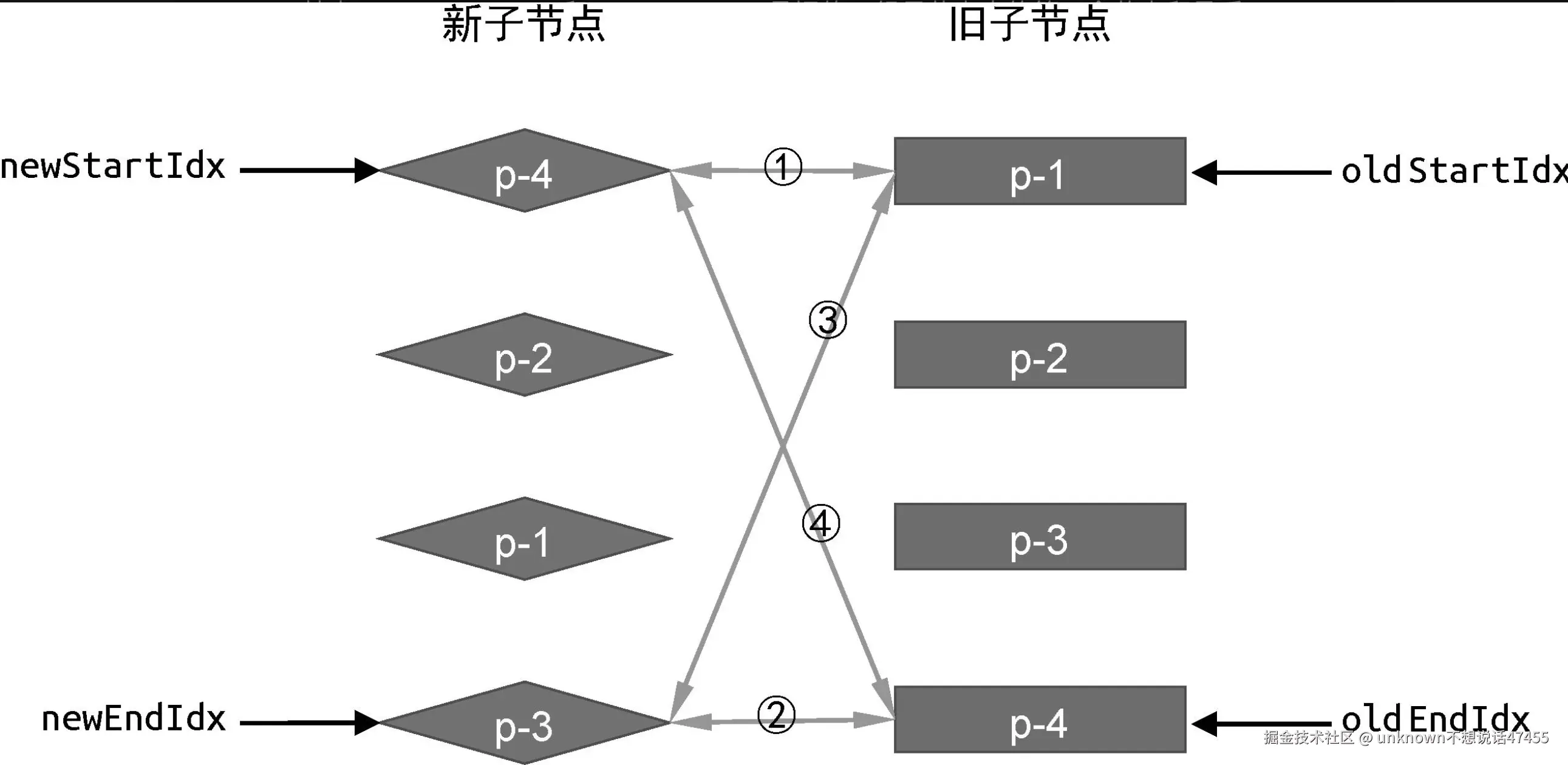
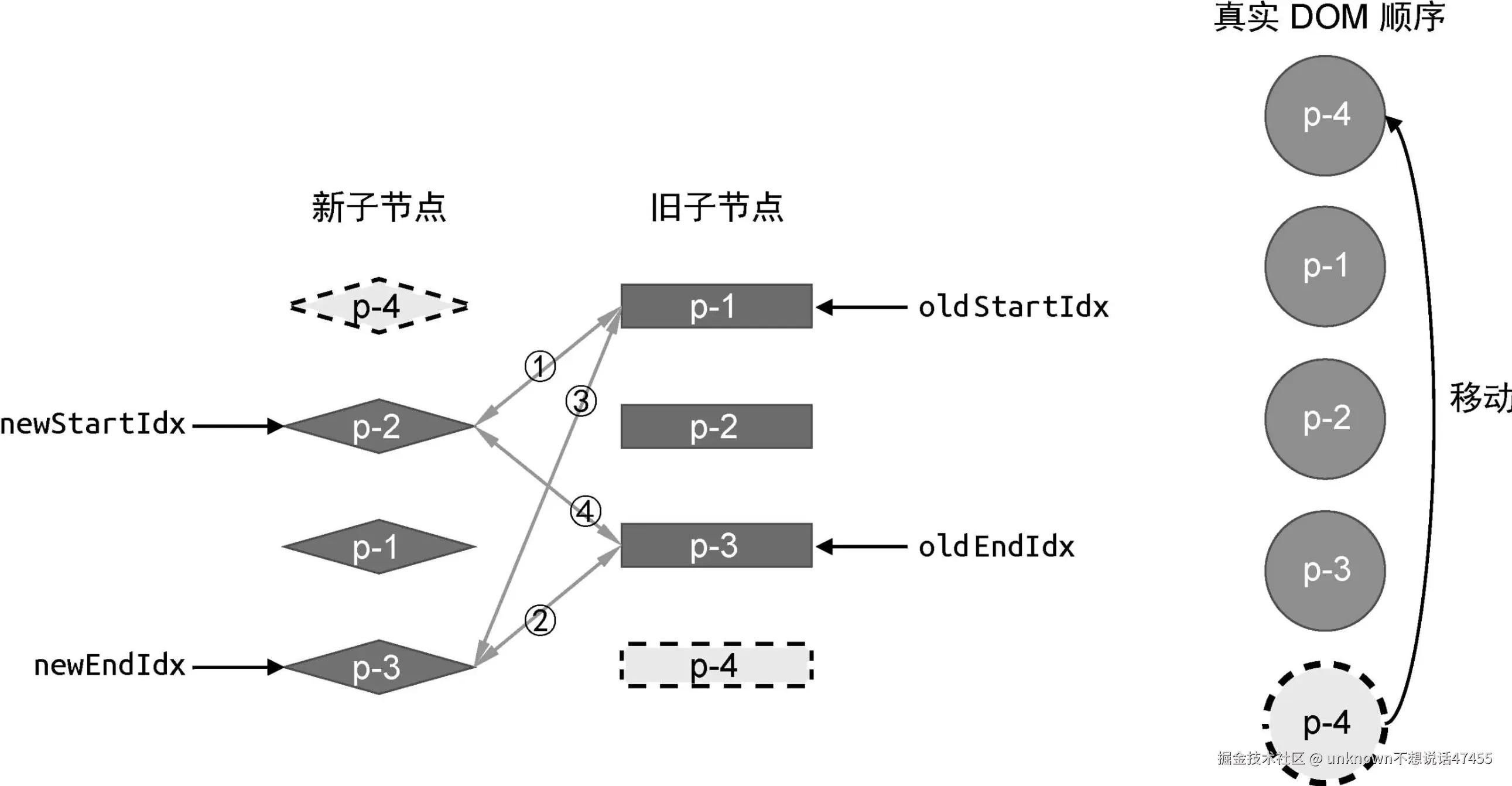
在双端比较中,每一轮比较都分为四个步骤:
第一步:比较旧的一组子节点中的第一个子节点 p-1 与新的一组子节点中的第一个子节点 p-4,看看它们是否相同。由于两者的 key 值不同,因此不相同,不可复用,于是什么都不做。
第二步:比较旧的一组子节点中的最后一个子节点 p-4 与新的一组子节点中的最后一个子节点 p-3,看看它们是否相同。由于两者的 key 值不同,因此不相同,不可复用,于是什么都不做。
第三步:比较旧的一组子节点中的第一个子节点 p-1 与新的一组子节点中的最后一个子节点 p-3,看看它们是否相同。由于两者的 key 值不同,因此不相同,不可复用,于是什么都不做。
第四步:比较旧的一组子节点中的最后一个子节点 p-4 与新的一组子节点中的第一个子节点 p-4。由于它们的 key 值相同,因此可以进行 DOM 复用.
可以看到,我们在第四步时找到了相同的节点,这说明它们对应的真实 DOM 节点可以复用。对于可复用的 DOM 节点,我们只需要通过 DOM 移动操作完成更新即可。
那么应该如何移动 DOM 元素呢?为了搞清楚这个问题,我们需要分析第四步比较过程中的细节。我们注意到,第四步是比较旧的一组子节点的最后一个子节点与新的一组子节点的第一个子节点,发现两者相同。这说明:节点 p-4 原本是最后一个子节点,但在新的顺序中,它变成了第一个子节点。换句话说,节点 p-4 在更新之后应该是第一个子节点。对应到程序的逻辑,可以将其翻译为:将索引 oldEndIdx 指向的虚拟节点所对应的真实 DOM 移动到索引 oldStartIdx 指向的虚拟节点所对应的真实 DOM 前面。
相同的前置元素和后置元素不同于简单 Diff 算法和双端 Diff 算法,快速 Diff 算法包含预处理步骤,这其实是借鉴了纯文本 Diff 算法的思路
快速 Diff 算法包含预处理步骤,这其实是借鉴了纯文本 Diff 算法的思路。在纯文本 Diff 算法中,存在对两段文本进行预处理的过程。
在这个过程中,会 分别查找头部完全一致的内容与尾部完全一致的内容,将其排除后再比较剩余内容
可以看到, 这两段文本的头部和尾部分别有一段相同的内容, 经过预处理,去掉这两段文本中相同的前缀内容和后缀内容之后, 真正需要进行 Diff 操作的部分是 vue -> react,
vue2核心diff算法采用的是双端比较算法
vue3核心diff算法采用的是去头尾的最长递增子序列算法
vue2、vue3 的 diff 算法实现差异主要体现在:处理完首尾节点后,对剩余节点的处理方式。
vue2 是通过对旧节点列表建立一个 { key, oldVnode } 的映射表,然后遍历新节点列表的剩余节点,根据newVnode.key在旧映射表中寻找可复用的节点,然后打补丁并且移动到正确的位置。
vue3 则是建立一个存储新节点数组中的剩余节点在旧节点数组上的索引的映射关系数组,建立完成这个数组后也即找到了可复用的节点,然后通过这个数组计算得到最长递增子序列,这个序列中的节点保持不动,然后将新节点数组中的剩余节点移动到正确的位置。
h函数的实现用于创建虚拟 DOM 节点,它是 Vue 渲染函数的基础,允许开发者用编程方式(通过 JavaScript)来描述组件结构,从而生成真实的 DOM
import { h, render } from 'vue';
const VNode = h('div', { class: 'my-element' }, [
h('span', 'Hello'),
h('p', 'Vue 3'),
]);
render(VNode, document.getElementById('app'));
源码
// Actual implementation
export function h(type: any, propsOrChildren?: any, children?: any): VNode {
const l = arguments.length
if (l === 2) {
if (isObject(propsOrChildren) && !isArray(propsOrChildren)) {
// single vnode without props
if (isVNode(propsOrChildren)) {
return createVNode(type, null, [propsOrChildren])
}
// props without children
return createVNode(type, propsOrChildren)
} else {
// omit props
return createVNode(type, null, propsOrChildren)
}
} else {
if (l > 3) {
children = Array.prototype.slice.call(arguments, 2)
} else if (l === 3 && isVNode(children)) {
children = [children]
}
return createVNode(type, propsOrChildren, children)
}
}
graph LR
Start --> A{2个参数}
A --> A1{对象且非数组}
A1 --> VNode{VNode}
VNode --Y--> 入参3child
VNode --N--> e(入参2prop)
A --> A2{非对象或数组}
A2 --> f(入参2prop)
Start --> B{3个及以上参数}
B --> 入参2prop,入参3child
1 + 2这里的1、+、2分别会看作一个词法单元。AST是 abstract syntax tree 的首字母缩写,即抽象语法树。所谓模板 AST,其实就是用来描述模板的抽象语法树
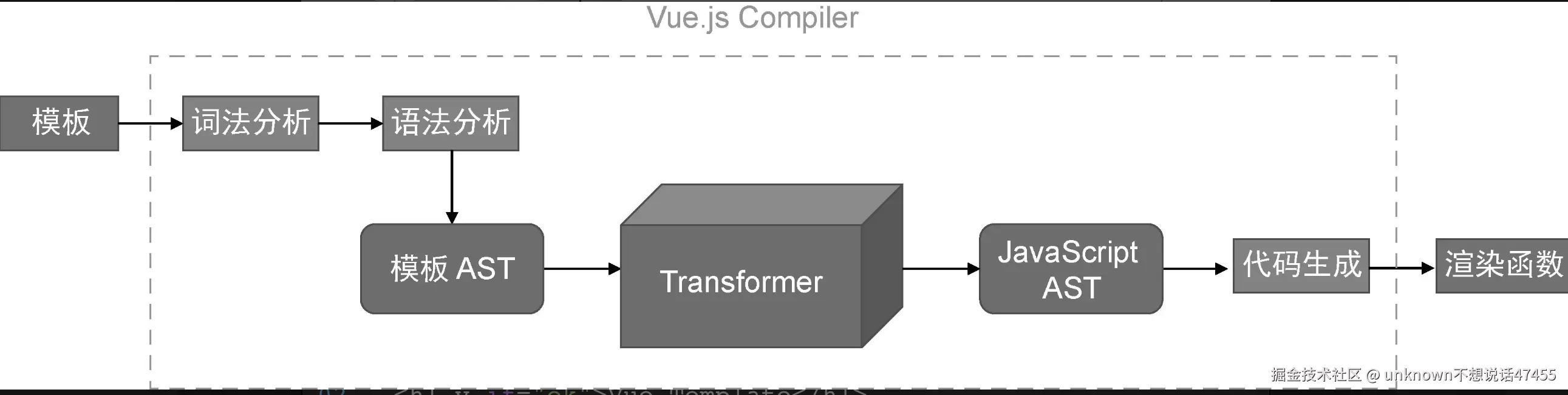
解析(Parsing):Vue3 的编译器会将模板字符串解析成一个抽象语法树(AST)。
转换(Transforming):用来将模板 AST 转换为 JavaScript AST 的转换器。将 v-if、v-for 等指令转换为 JavaScript 代码。
代码生成(Code Generation):用来根据 JavaScript AST 生成渲染函数代码, 代码生成器会遍历 AST,并为每个节点生成相应的 JavaScript 代码。
diy4869.github.io/vue-next-an…
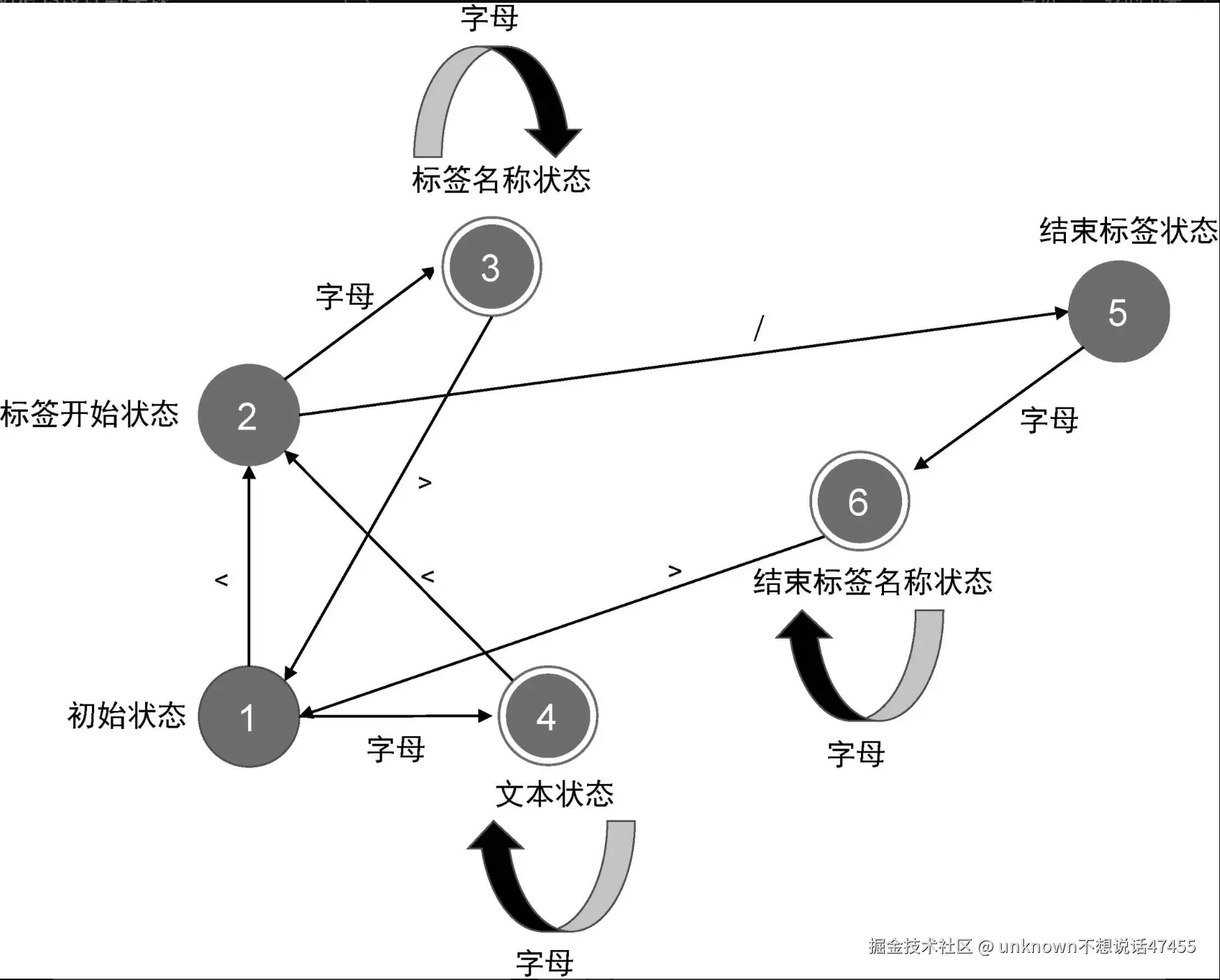
解析器是如何对模板进行切割的呢?依据什么规则?这就不得不提到有限状态自动机。千万不要被这个名词吓到,它理解起来并不难。所谓“有限状态”,就是指有限个状态,而“自动机”意味着随着字符的输入,解析器会自动地在不同状态间迁移。拿上面的模板来说,当我们分析这段模板字符串时,parse 函数会逐个读取字符,状态机会有一个初始状态,我们记为“初始状态 1”。图给出了状态迁移的过程。
解析示例: <p>Vue</p>
我们用自然语言来描述上图给出的状态迁移过程。
<,状态机会进入下一个状态,即“标签开始状态 2”。p。由于字符 p 是字母,所以状态机会进入“标签名称状态 3”。>,此时状态机会从“标签名称状态 3”迁移回“初始状态 1”,并记录在“标签名称状态”下产生的标签名称 p。V,此时状态机会进入“文本状态 4”。< 时,状态机会再次进入“标签开始状态 2”,并记录在“文本状态 4”下产生的文本内容,即字符串“Vue”。/,状态机会进入“结束标签状态 5”。p,状态机会进入“结束标签名称状态6”。>,它是结束标签的闭合字符,于是状态机迁移回“初始状态 1”,并记录在“结束标签名称状态 6”下生成的结束标签名称。经过这样一系列的状态迁移过程之后,我们最终就能够得到相应的 Token 了。有的圆圈是单线的,而有的圆圈是双线的。双线代表此时状态机是一个合法的 Token。
vue.js设计与实现

