
剑侠世界3vivo版
1.83GB · 2025-12-10

随着业务量的爆炸式增长,我们不得不面对一个甜蜜的烦恼:数据库的性能瓶颈。当单表数据达到千万甚至上亿级别时,查询效率直线下降,商家在后台查询订单时经常慢到让人抓狂。
分库分表(Sharding) 是解决这一问题的“银弹”之一。它将数据分散到多个数据库或数据表中,显著提升了系统的并发能力和存储能力。
然而,分库分表并非没有代价。最直接的挑战就是:跨库查询变得困难,尤其对于商家后台的复杂查询场景。
那么,在分库分表之后,商家如何才能高效、快速地查询到自己的订单呢?
分库分表通常会选择一个分片键(如user_id或order_id)来决定数据落在哪一个库/表。通过分片键查询时效率极高。(一般都是根据C端用户选择分片键,参考文章:为什么淘宝订单号后6位始终一样?)
但商家后台的查询往往是非分片键查询:
如果每次查询都要广播(即向所有库发送查询请求),性能将不堪设想。
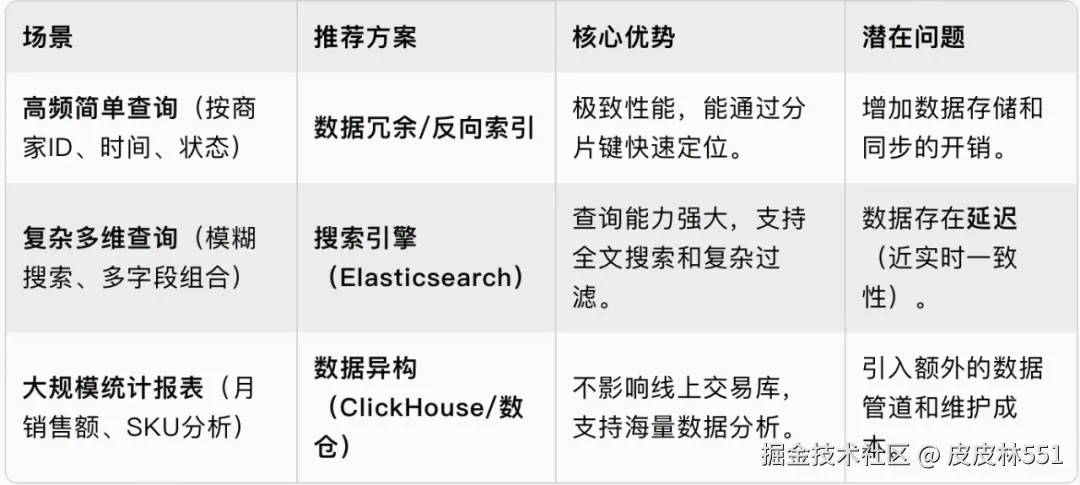
为了解决分库分表后的查询难题,业界总结出了一套行之有效的“组合拳”。
这是解决非分片键查询最常见和高效的手段。其核心思想是:以空间换时间。
在分库分表的主订单表之外,额外建立一张专门用于后台查询的表,这张表不再按照用户ID分片,而是根据查询维度来设计。
order_id、create_time、status、shop_id等,并以shop_id(商家ID)作为分片键。shop_id定位到唯一的库,在这个库中进行高效的范围或状态查询。如果商家需要根据“买家昵称”或“手机号”查询,由于这些字段和订单表不在同一个分片上,可以使用反向索引:
买家手机号 → user_id或order_id。order_id。order_id(如果是分片键)或预设的查询逻辑,到主订单库查询详情。对于像“模糊查询买家昵称”、“全文搜索备注信息”以及对时效性要求不那么极致的复杂多维度查询,ElasticSearch (ES) 是最佳选择。
对于需要进行大量聚合、统计分析(如月度销售报表、SKU销量统计)的场景,如果直接在业务数据库上操作,仍会对业务造成压力。
使用 数据仓库(Data Warehouse) 或专业的 OLAP(在线分析处理) 数据库,如ClickHouse。
分库分表是系统架构升级的必经之路,而查询优化则是分库分表后必须解决的“后遗症”。通过合理地使用冗余表、搜索引擎和数据异构这三大武器,我们就能在保证系统高并发的同时,为商家提供如丝般顺滑的订单查询体验。

