
凹凸世界追寻计划官方正版
1.37GB · 2025-12-07

前阵子,社区有小伙伴在使用 Easysearch 的数据压缩功能时发现,在开启 source_reuse 和 ZSTD 后,一个字段的内容看不到了。
索引的设置如下:
{ ...... "settings": { "index": { "codec": "ZSTD", "source_reuse": "true" } }, "mappings": { "dynamic_templates": [ { "message_field": { "path_match": "message", "mapping": { "norms": false, "type": "text" }, "match_mapping_type": "string" } }, { "string_fields": { "mapping": { "norms": false, "type": "text", "fields": { "keyword": { "ignore_above": 256, "type": "keyword" } } }, "match_mapping_type": "string", "match": "*" } } ] ......}然后产生的一个多字段内容能被搜索到,但是不可见。
类似于下面的这个情况: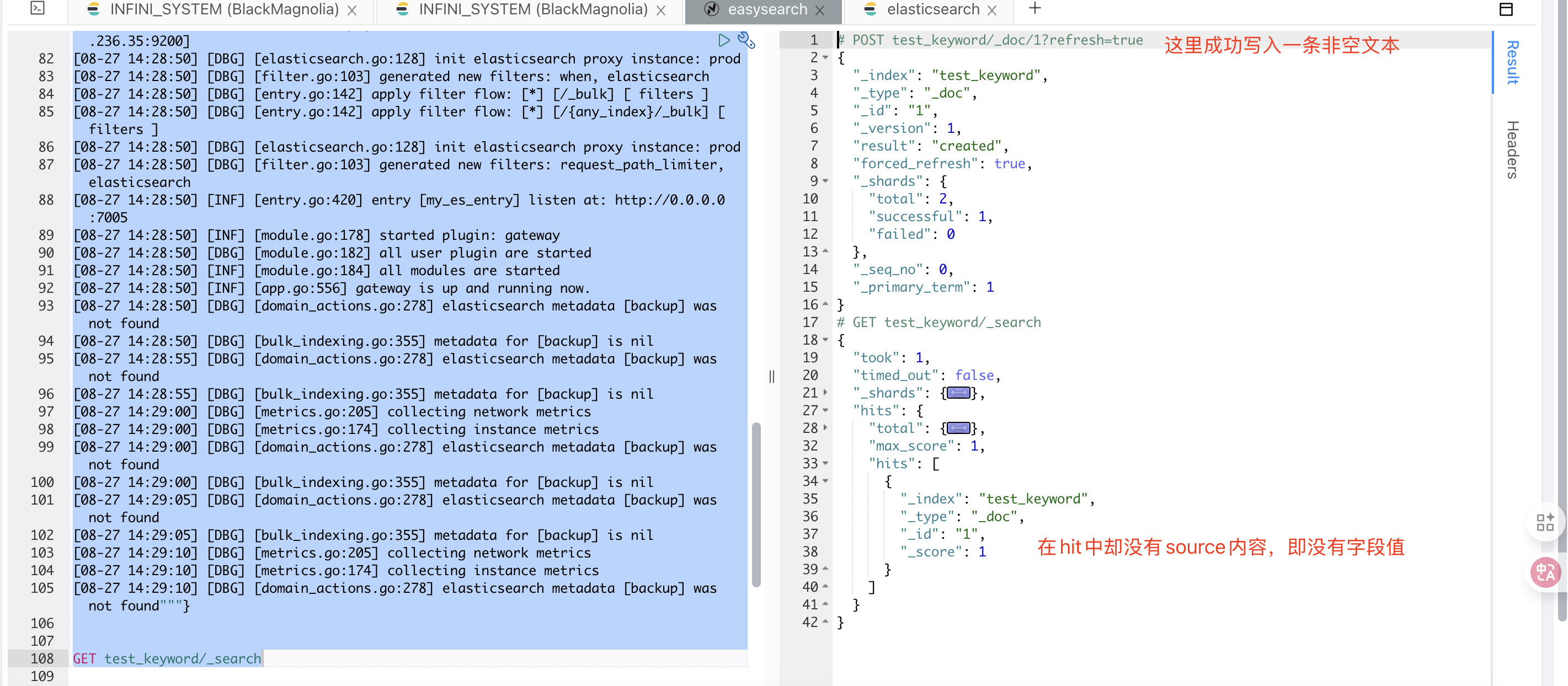
我们先来看看整个字段展示经历的环节: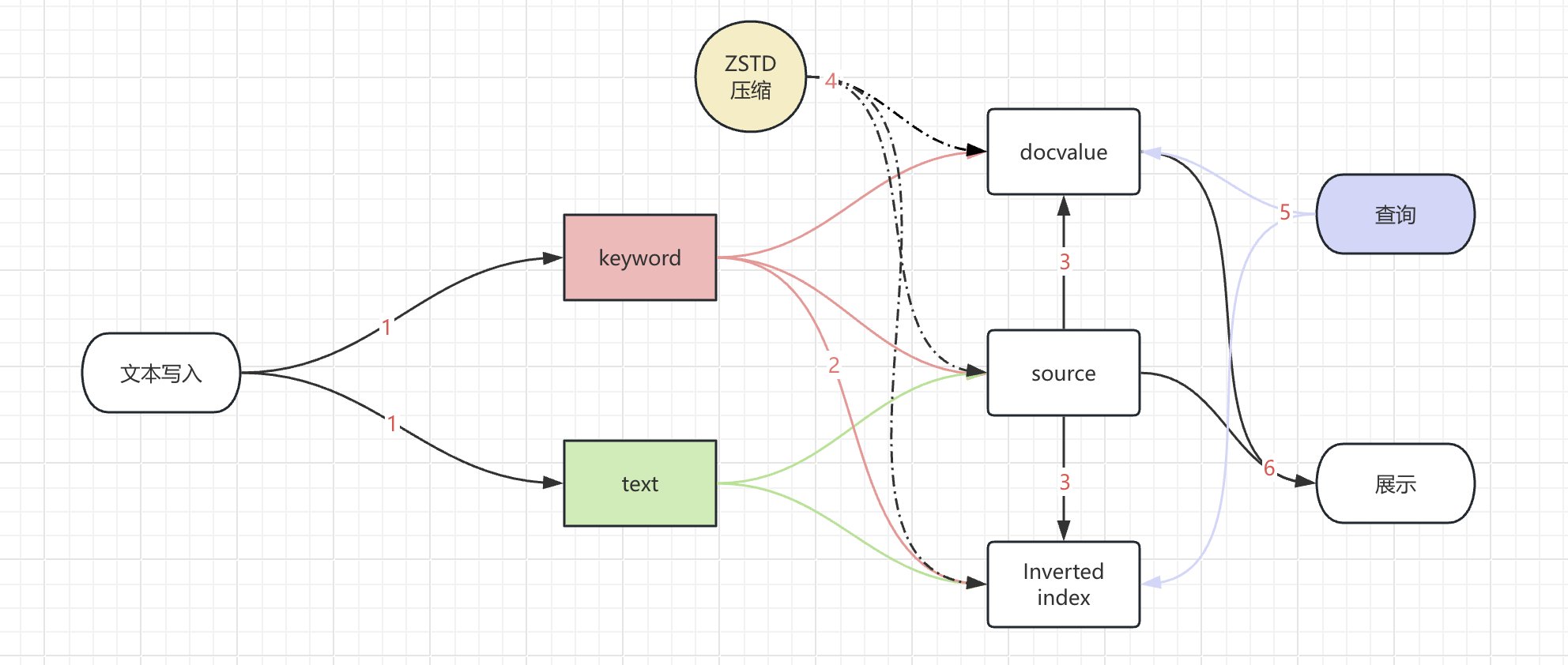
_source或者docvalues_fields的内容来展示文本,但是文本内容是空的。其中步骤 4 中的 ZSTD 压缩,是作用于数据文件的,并不对数据内容进行修改。因此,我们来专注于其他环节。
首先,这个字段索引的配置也是一个 es 常见的设置,并不会带来内容显示缺失的问题。
"mapping": { "type": "text", "fields": { "keyword": { "ignore_above": 256, "type": "keyword" } } },那么,source_reuse 就成了我们可以重点排查的环节。
source_reuse 的作用描述如下:
source_reuse: 启用 source_reuse 配置项能够去除 _source 字段中与 doc_values 或倒排索引重复的部分,从而有效减小索引总体大小,这个功能对日志类索引效果尤其明显。source_reuse 支持对以下数据类型进行压缩:keyword,integer,long,short,boolean,float,half_float,double,geo_point,ip, 如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这是一个对 _source 字段进行产品化的功能实现。为了减少索引的存储体量,简单粗暴的操作是直接将_source字段进行关闭,利用其他数据格式去存储,在查询的时候对应的利用 docvalue 或者 indexed 去展示文本内容。
那么 _source关闭后,会不会也有这样的问题呢?
测试的步骤如下:
# 1. 创建不带source的双字段索引PUT test_source{ "mappings": { "_source": { "enabled": false }, "properties": { "msg": { "type": "text", "fields": { "keyword": { "ignore_above": 256, "type": "keyword" } } } } }}# 2. 写入测试数据POST test_source/_doc/1{"msg":"""[08-27 14:28:45] [DBG] [config.go:273] config contain variables, try to parse with environments[08-27 14:28:45] [DBG] [config.go:214] load config files: [][08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: pipeline_logging_merge[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_pipeline_logging[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_messages_merge[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: metrics_merge[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: request_logging_merge[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_merged_requests[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_ingest_bulk_requests[08-27 14:28:45] [INF] [module.go:159] started module: pipeline[08-27 14:28:45] [DBG] [module.go:163] all system module are started[08-27 14:28:45] [DBG] [floating_ip.go:348] setup floating_ip, root privilege are required[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: metrics_merge[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: when[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_merged_requests[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: request_logging_merge[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_messages_merge[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_pipeline_logging[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:1216c96eb876eee5b177d45436d0a362,gateway-pipeline-logs[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: pipeline_logging_merge[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_ingest_bulk_requests[08-27 14:28:45] [DBG] [badger.go:110] init badger database [queue_consumer_commit_offset][08-27 14:28:45] [INF] [floating_ip.go:290] floating_ip entering standby mode[08-27 14:28:45] [DBG] [badger.go:110] init badger database [dis_locker][08-27 14:28:45] [DBG] [time.go:208] refresh low precision time in background[08-27 14:28:45] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found[08-27 14:28:45] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil[08-27 14:28:50] [INF] [module.go:178] started plugin: floating_ip[08-27 14:28:50] [INF] [module.go:178] started plugin: force_merge[08-27 14:28:50] [DBG] [network.go:78] network io stats will be included for map[][08-27 14:28:50] [INF] [module.go:178] started plugin: metrics[08-27 14:28:50] [INF] [module.go:178] started plugin: statsd[08-27 14:28:50] [DBG] [entry.go:100] reuse port 0.0.0.0:7005[08-27 14:28:50] [DBG] [metrics.go:205] collecting network metrics[08-27 14:28:50] [DBG] [metrics.go:174] collecting instance metrics[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: when, elasticsearch[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/_bulk] [ filters ][08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/{any_index}/_bulk] [ filters ][08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: request_path_limiter, elasticsearch[08-27 14:28:50] [INF] [module.go:178] started plugin: gateway[08-27 14:28:50] [DBG] [module.go:182] all user plugin are started[08-27 14:28:50] [INF] [module.go:184] all modules are started[08-27 14:28:50] [INF] [app.go:556] gateway is up and running now.[08-27 14:28:50] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found[08-27 14:28:50] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil[08-27 14:28:55] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found[08-27 14:28:55] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil[08-27 14:29:00] [DBG] [metrics.go:205] collecting network metrics[08-27 14:29:00] [DBG] [metrics.go:174] collecting instance metrics[08-27 14:29:00] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found[08-27 14:29:00] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil[08-27 14:29:05] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found[08-27 14:29:05] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil[08-27 14:29:10] [DBG] [metrics.go:205] collecting network metrics[08-27 14:29:10] [DBG] [metrics.go:174] collecting instance metrics[08-27 14:29:10] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found"""}# 3. 查询数据GET test_source/_search此时,可以看到,存入的文档检索出来是空的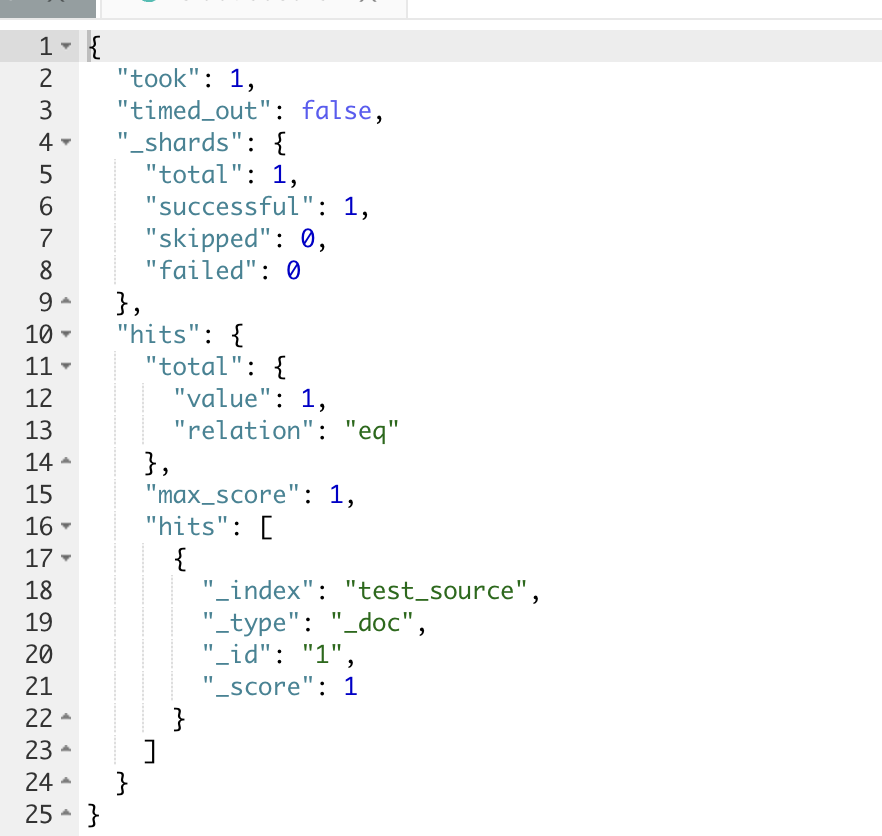
_source 字段是用于索引时传递的原始 JSON 文档主体。它本身未被索引成倒排(因此不作用于 query 阶段),只是在执行查询时用于 fetch 文档内容。
对于 text 类型,关闭_source,则字段内容自然不可被查看。
而对于 keyword 字段,查看_source也是不行的。可是 keyword 不仅存储source,还存储了 doc_values。因此,对于 keyword 字段类型,可以考虑关闭_source,使用 docvalue_fields 来查看字段内容。
测试如下:
# 1. 创建测试条件的索引PUT test_source2{ "mappings": { "_source": { "enabled": false }, "properties": { "msg": { "type": "keyword" } } }}# 2. 写入数据POST test_source2/_doc{"msg":"1111111"}# 3. 使用 docvalue_fields 查询数据POST test_source2/_search{"docvalue_fields": ["msg"]}# 返回结果{ "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "test_source2", "_type": "_doc", "_id": "yBvTj5kBvrlGDwP29avf", "_score": 1, "fields": { "msg": [ "1111111" ] } } ] }}在如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这句介绍里,也可以看到 source_reuse 的正常使用需要 doc_values。那是不是一样使用 doc_values 进行内容展示呢?既然用于 docvalue_fields 内容展示,为什么还是内容看不了(不可见)呢?
仔细看问题场景里 keyword 的配置,它使用了 ignore_above。那么,会不会是这里的问题?
我们将 ignore_above 配置带入上面的测试,这里为了简化测试,ignore_above 配置为 3。为区分问题现象,这里两条长度不同的文本进去,一条为 11,一条为1111111,可以作为参数作用效果的对比。
# 1. 创建测试条件的索引,ignore_above 设置为3PUT test_source3{ "mappings": { "_source": { "enabled": false }, "properties": { "msg": { "type": "keyword", "ignore_above": 3 } } }}# 2. 写入数据,POST test_source3/_doc{"msg":"1111111"}POST test_source3/_doc{"msg":"11"}# 3. 使用 docvalue_fields 查询数据POST test_source3/_search{"docvalue_fields": ["msg"]}# 返回内容{ "took": 363, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "test_source3", "_type": "_doc", "_id": "yhvjj5kBvrlGDwP22KsG", "_score": 1 }, { "_index": "test_source3", "_type": "_doc", "_id": "yxvzj5kBvrlGDwP2Nav6", "_score": 1, "fields": { "msg": [ "11" ] } } ] }}OK! 问题终于复现了。我们再来看看作为关键因素的 ignore_above 参数是用来干嘛的。
ignore_above:任何长度超过此整数值的字符串都不应被索引。默认值为 2147483647。默认动态映射会创建一个 ignore_above 设置为 256 的 keyword 子字段。也就是说,ignore_above 在(倒排)索引时会截取内容,防止产生的索引内容过长。
但是从测试的两个文本来看,面对在参数范围内的文档,docvalues 会正常创建,而超出参数范围的文本而忽略创建(至于这个问题背后的源码细节我们可以另外开坑再鸽,此处省略)。
那么,在 source_reuse 下,keyword 的 ignore_above 是不是起到了相同的作用呢?
我们可以在问题场景上去除 ignore_above,参数试试,来看下面的测试:
# 1. 创建测试条件的索引,使用 source_reuse,设置 ignore_above 为3PUT test_source4{ "settings": { "index": { "source_reuse": "true" } }, "mappings": { "properties": { "msg": { "type": "text", "fields": { "keyword": { "ignore_above": 3, "type": "keyword" } } } } }}# 2. 写入数据POST test_source4/_doc{"msg":"1111111"}POST test_source4/_doc{"msg":"11"}# 3. 使用 docvalue_fields 查询数据POST test_source4/_search# 返回内容{ "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "test_source4", "_type": "_doc", "_id": "zBv2j5kBvrlGDwP2_au-", "_score": 1, "_source": {} }, { "_index": "test_source4", "_type": "_doc", "_id": "zRv2j5kBvrlGDwP2_qsO", "_score": 1, "_source": { "msg": "11" } } ] }}可以看到,数据“不可见”的问题被完整的复现了。
从上面一系列针对数据“不可见”问题的测试,我们可以总结以下几点:
特别感谢:社区@牛牪犇群
更多 Easysearch 资料请查看 官网文档。
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/invisibility-in-easysearch-field/

