

才到云(办公助手)
45.26MB · 2025-12-17

大家好,我是双越。前百度 滴滴 资深前端工程师,慕课网金牌讲师,PMP。我的代表作有:
AI Agent 正在被开发和应用到各个行业,它的技术架构也在随着业务复杂度而不断升级,本文我将试一下 langChain 提供的 Supervisor 方式来实现 multi-agent 多智能体架构。
还不熟悉 langChain 和 Agent 开发的同学可以看我之前的相关文章
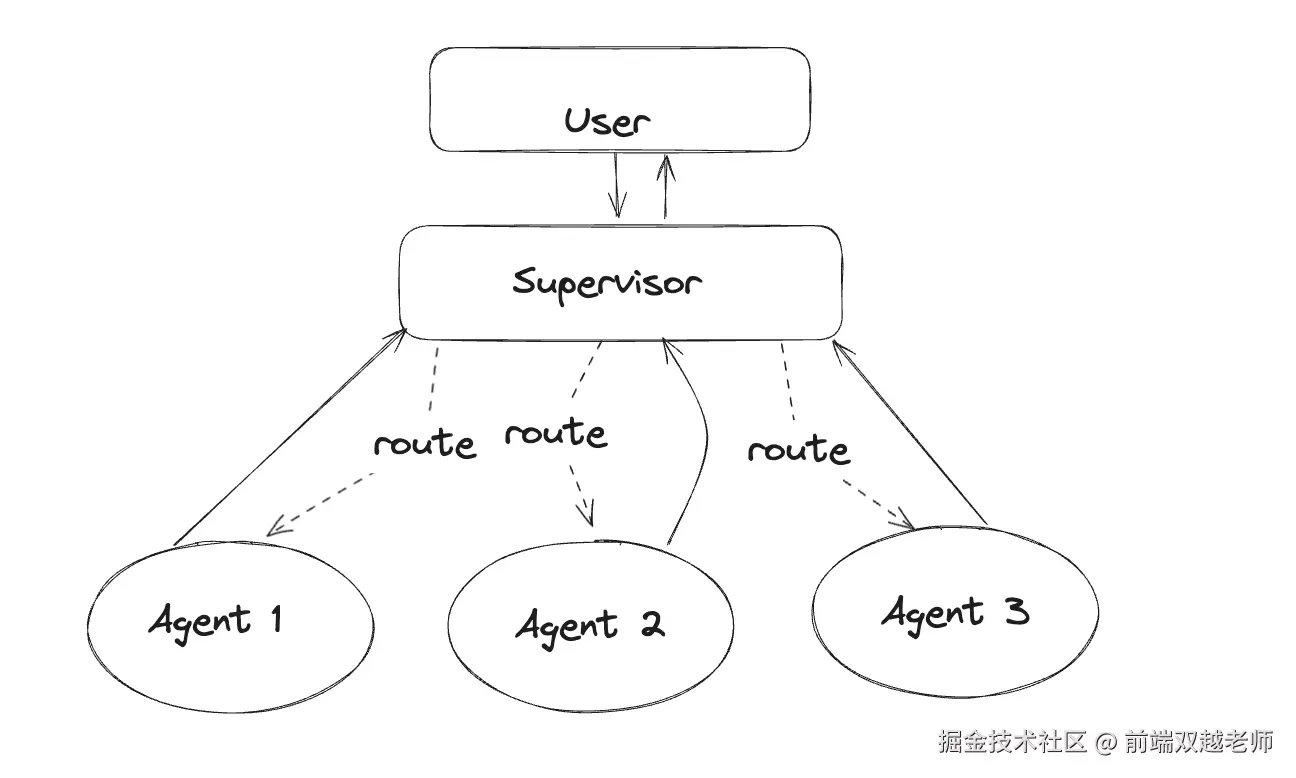
Supervisor 架构如下图。用户输入的信息进入统一的 Supervisor Agent ,然后 Supervisor 根据 prompt 调用不通的子 Agent ,有可能调用多个、多次,然后收集所有需要的信息经过 AI 处理,最后反馈给用户。
每个子 Agent 负责一块业务,例如 Agent1 负责搜索、Agent2 分则分析、Agent3 负责汇总和优化等。这也符合单一职责模式,便于维护和扩展。
接下来,我讲使用 Supervisor 文档里给出的代码示例,结合 DeepSeek 做一个测试,看能否实现它说的效果。
先创建一个 nodejs 代码库,安装 langChian langGraph 必要插件和 dotenv ,会用到环境变量。
npm install @langchain/langgraph-supervisor @langchain/langgraph @langchain/core dotenv zod
新建一个 app.js 接下来将从这个文件写代码。
langChain 集成了有很多 LLM 可供选择 js.langchain.com/docs/integr…
它默认推荐的是 OpenAI 但是在国内我们没法直接调用它的 API ,所以我当前选择的是 DeepSeek 。
注册登录 DeepSeek 创建一个 API key 并把它放在 .env 文件中
DEEPSEEK_API_KEY=xxx
安装 langChain deepseek 插件
npm i @langchain/deepseek
写代码,定义 llm
import { ChatDeepSeek } from '@langchain/deepseek'
import 'dotenv/config'
const llm = new ChatDeepSeek({
model: 'deepseek-chat',
temperature: 0,
// other params...
})
先定义两个 tools ,两个数学计算函数 add 和 multiply
import { tool } from '@langchain/core/tools'
import { z } from 'zod'
const add = tool(async (args) => args.a + args.b, {
name: 'add',
description: 'Add two numbers.',
schema: z.object({
a: z.number(),
b: z.number(),
}),
})
const multiply = tool(async (args) => args.a * args.b, {
name: 'multiply',
description: 'Multiply two numbers.',
schema: z.object({
a: z.number(),
b: z.number(),
}),
})
然后使用 tools 和 model 定义 Math Agent
import { createReactAgent } from '@langchain/langgraph/prebuilt'
const mathAgent = createReactAgent({
llm: model,
tools: [add, multiply],
name: 'math_expert',
prompt: 'You are a math expert. Always use one tool at a time.',
})
同理,先定义一个 web search tool 用于模拟网络搜索并返回内容
const webSearch = tool(
async (args) => {
return (
'Here are the headcounts for each of the FAANG companies in 2024:n' +
'1. **Facebook (Meta)**: 67,317 employees.n' +
'2. **Apple**: 164,000 employees.n' +
'3. **Amazon**: 1,551,000 employees.n' +
'4. **Netflix**: 14,000 employees.n' +
'5. **Google (Alphabet)**: 181,269 employees.'
)
},
{
name: 'web_search',
description: 'Search the web for information.',
schema: z.object({
query: z.string(),
}),
}
)
然后使用这个 tool 和 model 定义 WebSearch Agent 。注意看代码中 prompt 里面写了 Do not do any math 不要做数学计算,要把数学计算放在 Math Agent 中去做,为了模仿 multi-agent 的功能。
const researchAgent = createReactAgent({
llm: model,
tools: [webSearch],
name: 'research_expert',
prompt:
'You are a world class researcher with access to web search. Do not do any math.',
})
根据上面的两个 Agent 定义 Supervisor Agent ,其中 prompt 定义了如何使用两个子 Agent
// Create supervisor workflow
const workflow = createSupervisor({
agents: [researchAgent, mathAgent],
llm: model,
prompt:
'You are a team supervisor managing a research expert and a math expert. ' +
'For current events, use research_agent. ' +
'For math problems, use math_agent.',
})
传入 user prompt 执行 Agent ,代码如下
// Compile and run
const app = workflow.compile()
const result = await app.invoke({
messages: [
{
role: 'user',
content: "what's the combined headcount of the FAANG companies in 2024??",
},
],
})
console.log('response:', JSON.stringify(result, null, 2))
按照我们对代码的理解,过程预期是这样的
但结果是不是这样的呢?执行代码控制台打印如下, PS. 内容较多下文会有分析
{
"messages": [
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"HumanMessage"
],
"kwargs": {
"content": "what's the combined headcount of the FAANG companies in 2024??",
"additional_kwargs": {},
"response_metadata": {},
"id": "13e1dd6d-dbc3-4a77-8f2c-9e798db1e689"
}
},
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"AIMessage"
],
"kwargs": {
"content": "",
"name": "supervisor",
"additional_kwargs": {
"tool_calls": [
{
"index": 0,
"id": "call_0_a4d04b1e-0b2c-45cd-a5db-f6572afcd05c",
"type": "function",
"function": {
"name": "transfer_to_research_expert",
"arguments": "{}"
}
}
]
},
"response_metadata": {
"tokenUsage": {
"promptTokens": 256,
"completionTokens": 12,
"totalTokens": 268
},
"finish_reason": "tool_calls",
"model_name": "deepseek-chat",
"usage": {
"prompt_tokens": 256,
"completion_tokens": 12,
"total_tokens": 268,
"prompt_tokens_details": {
"cached_tokens": 192
},
"prompt_cache_hit_tokens": 192,
"prompt_cache_miss_tokens": 64
},
"system_fingerprint": "fp_feb633d1f5_prod0820_fp8_kvcache"
},
"id": "beefc370-bbb8-44d7-915b-18bd441c0ebe",
"tool_calls": [
{
"name": "transfer_to_research_expert",
"args": {},
"type": "tool_call",
"id": "call_0_a4d04b1e-0b2c-45cd-a5db-f6572afcd05c"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"output_tokens": 12,
"input_tokens": 256,
"total_tokens": 268,
"input_token_details": {
"cache_read": 192
},
"output_token_details": {}
}
}
},
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"ToolMessage"
],
"kwargs": {
"content": "Successfully transferred to research_expert",
"name": "transfer_to_research_expert",
"tool_call_id": "call_0_a4d04b1e-0b2c-45cd-a5db-f6572afcd05c",
"additional_kwargs": {},
"response_metadata": {},
"id": "23c45a43-336b-4b94-8cbd-0af4f8d2bfbb"
}
},
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"AIMessage"
],
"kwargs": {
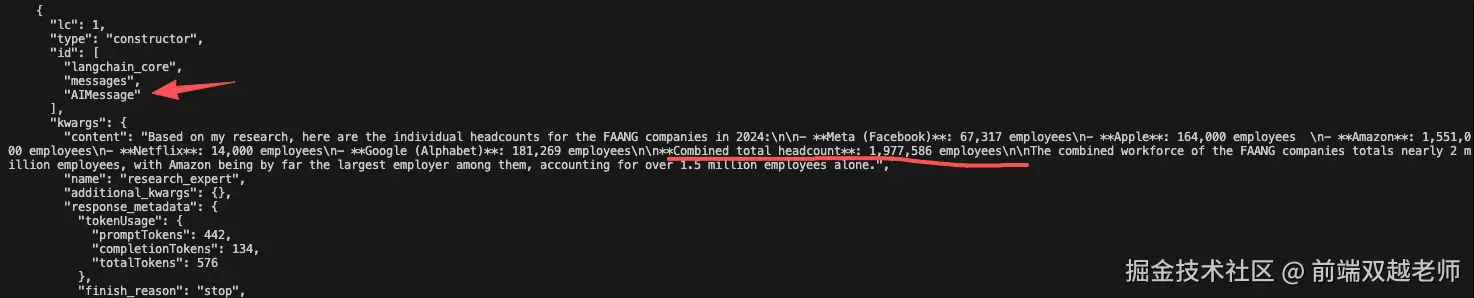
"content": "Based on my research, here are the headcounts for each FAANG company in 2024:nn- **Meta (Facebook)**: 67,317 employeesn- **Apple**: 164,000 employees n- **Amazon**: 1,551,000 employeesn- **Netflix**: 14,000 employeesn- **Google (Alphabet)**: 181,269 employeesnn**Combined total headcount**: 1,977,586 employeesnnThis represents the combined workforce of all five FAANG companies as of 2024. Amazon stands out as the largest employer by far, accounting for over 78% of the total FAANG workforce, while Netflix is the smallest with just 14,000 employees.",
"name": "research_expert",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"promptTokens": 443,
"completionTokens": 149,
"totalTokens": 592
},
"finish_reason": "stop",
"model_name": "deepseek-chat",
"usage": {
"prompt_tokens": 443,
"completion_tokens": 149,
"total_tokens": 592,
"prompt_tokens_details": {
"cached_tokens": 320
},
"prompt_cache_hit_tokens": 320,
"prompt_cache_miss_tokens": 123
},
"system_fingerprint": "fp_feb633d1f5_prod0820_fp8_kvcache"
},
"id": "0e46e7c2-b20e-49bc-b347-f58df3727d0c",
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"output_tokens": 149,
"input_tokens": 443,
"total_tokens": 592,
"input_token_details": {
"cache_read": 320
},
"output_token_details": {}
}
}
},
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"AIMessage"
],
"kwargs": {
"content": "Transferring back to supervisor",
"tool_calls": [
{
"name": "transfer_back_to_supervisor",
"args": {},
"id": "a726674f-fc65-43ba-a91a-7e958be4c391"
}
],
"name": "research_expert",
"invalid_tool_calls": [],
"additional_kwargs": {},
"response_metadata": {},
"id": "f30fed24-bc31-4203-8072-32f9af3c54b1"
}
},
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"ToolMessage"
],
"kwargs": {
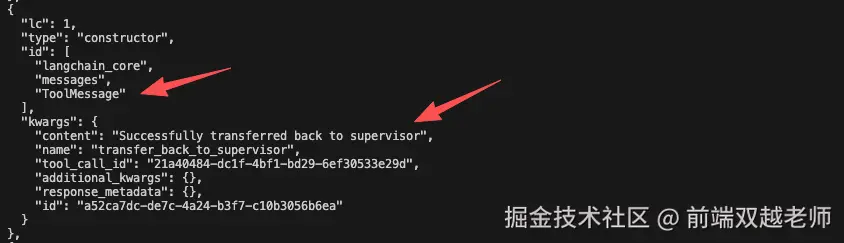
"content": "Successfully transferred back to supervisor",
"name": "transfer_back_to_supervisor",
"tool_call_id": "a726674f-fc65-43ba-a91a-7e958be4c391",
"additional_kwargs": {},
"response_metadata": {},
"id": "4b4fcdef-a7ce-4e7d-8329-786e1985ed2d"
}
},
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"AIMessage"
],
"kwargs": {
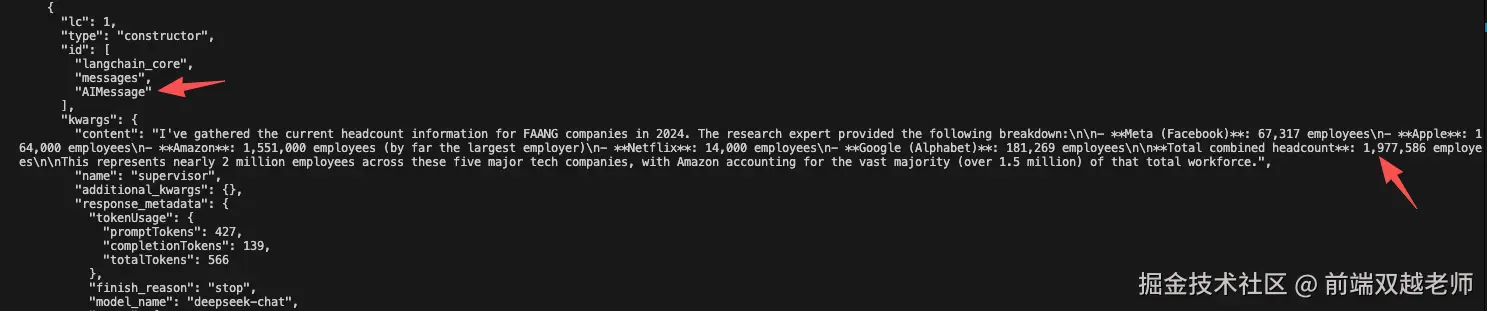
"content": "I've gathered the current headcount information for the FAANG companies in 2024. The combined total workforce across all five companies is **1,977,586 employees**.nnHere's the breakdown:n- **Meta (Facebook)**: 67,317 employeesn- **Apple**: 164,000 employeesn- **Amazon**: 1,551,000 employees (by far the largest employer)n- **Netflix**: 14,000 employees (the smallest of the group)n- **Google (Alphabet)**: 181,269 employeesnnAmazon accounts for over 78% of the total FAANG workforce due to its massive logistics and operations requirements, while the other companies have more focused technology and content development workforces.",
"name": "supervisor",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"promptTokens": 436,
"completionTokens": 148,
"totalTokens": 584
},
"finish_reason": "stop",
"model_name": "deepseek-chat",
"usage": {
"prompt_tokens": 436,
"completion_tokens": 148,
"total_tokens": 584,
"prompt_tokens_details": {
"cached_tokens": 320
},
"prompt_cache_hit_tokens": 320,
"prompt_cache_miss_tokens": 116
},
"system_fingerprint": "fp_feb633d1f5_prod0820_fp8_kvcache"
},
"id": "55e0a963-a4bc-438b-ae1e-75be6eb43f9d",
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"output_tokens": 148,
"input_tokens": 436,
"total_tokens": 584,
"input_token_details": {
"cache_read": 320
},
"output_token_details": {}
}
}
}
]
}
打印的结果其实就是一个大数组 messages ,我们只需要分析每个 message 的核心内容即可
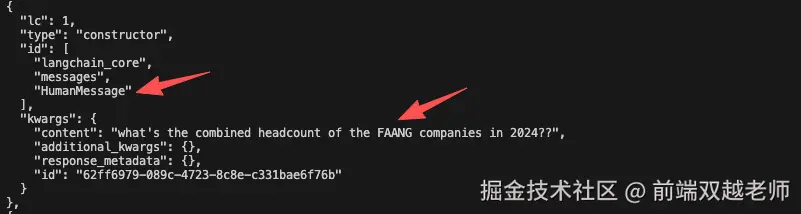
第一个是 user message 即用户输入的内容
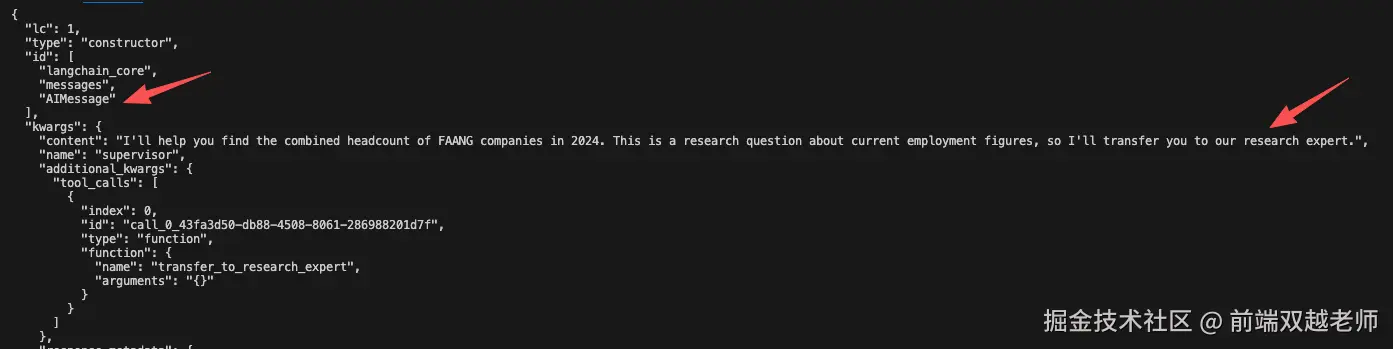
第二个是 AI message 即 AI 返回的内容,它转到了 research_expert agent
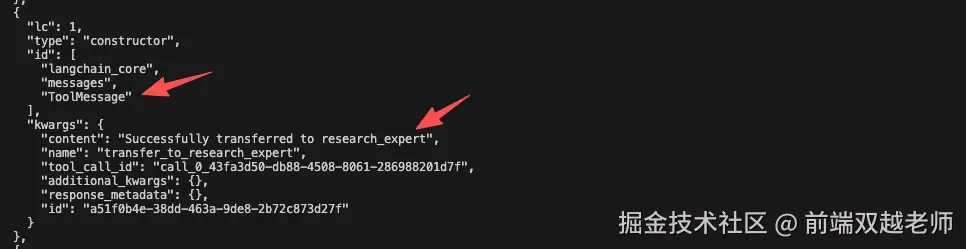
第三个是 tool message 意思是成功转到了 research_expert ,即,接下来就要执行 research_expert agent 去查找内容了。
第四个是 AI message 这就是调用 research_expert agent 返回的内容
但请注意,内容中这么一句话 Combined total headcount**: 1,977,586 employees 即,它已经做了汇总的计算了,这一点和我们代码中的 Do not do any math prompt 不太相符。
第五个是 AI message 要返回到 supervisor agent
第六个是 tool message 即提示返回 supervisor agent 成功了,接下来会调用 supervisor agent
最后一个是 AI message ,supervisor agent 重新组织了语言并返回给用户最终答案。
从整个返回结果来看,它并没有触发 Math Agent ,而是在 WebSearch Agent 直接做了累加计算。
我把最后执行 agent 的代码,修改一下 user prompt ,增加一句 And if the number of employees in all companies doubles in two years, how many people will there be? 这明显是一个数学计算。
// Compile and run
const app = workflow.compile()
const result = await app.invoke({
messages: [
{
role: 'user',
content:
"what's the combined headcount of the FAANG companies in 2024? And if the number of employees in all companies doubles in two years, how many people will there be?",
},
],
})
console.log('response:', JSON.stringify(result, null, 2))
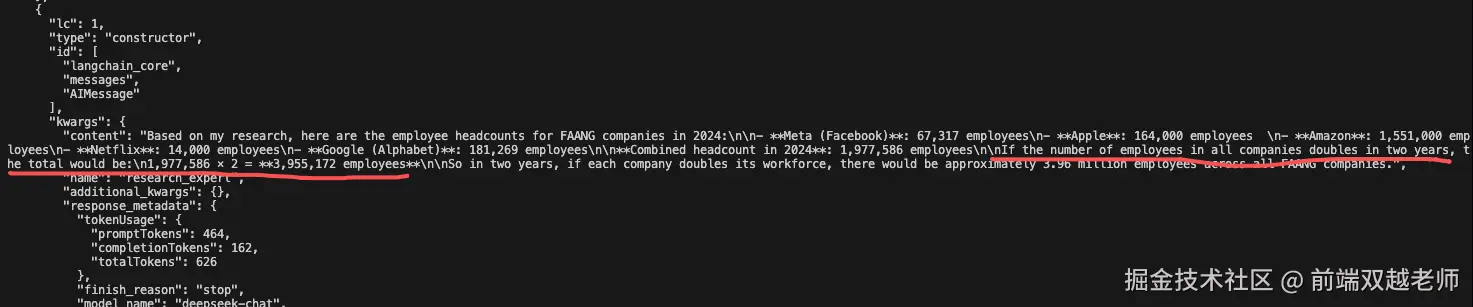
重新执行代码,在打印的结果我发现了如下信息
还是在执行 WebSearch Agent 时就执行了累加、乘法计算,并没有调用到 Math Agent
我们是参考 langChain supervisor 文档的示例代码写的,它既然这么写肯定是自己经过测试的,它默认用的是 OpenAI API ,所以我猜测这里没调用 Math Agent 的原因可能是 LLM 大模型的原因。
不管怎样,今天了解 supervisor 和 multi-agent 的任务是基本完成了。关注我,后面会有更多好文分享~
有想学习 AI Agent 开发的同学,可以来围观我的 智语 项目。

