






才到云(办公助手)
45.26MB · 2025-12-17

先看一组数据:
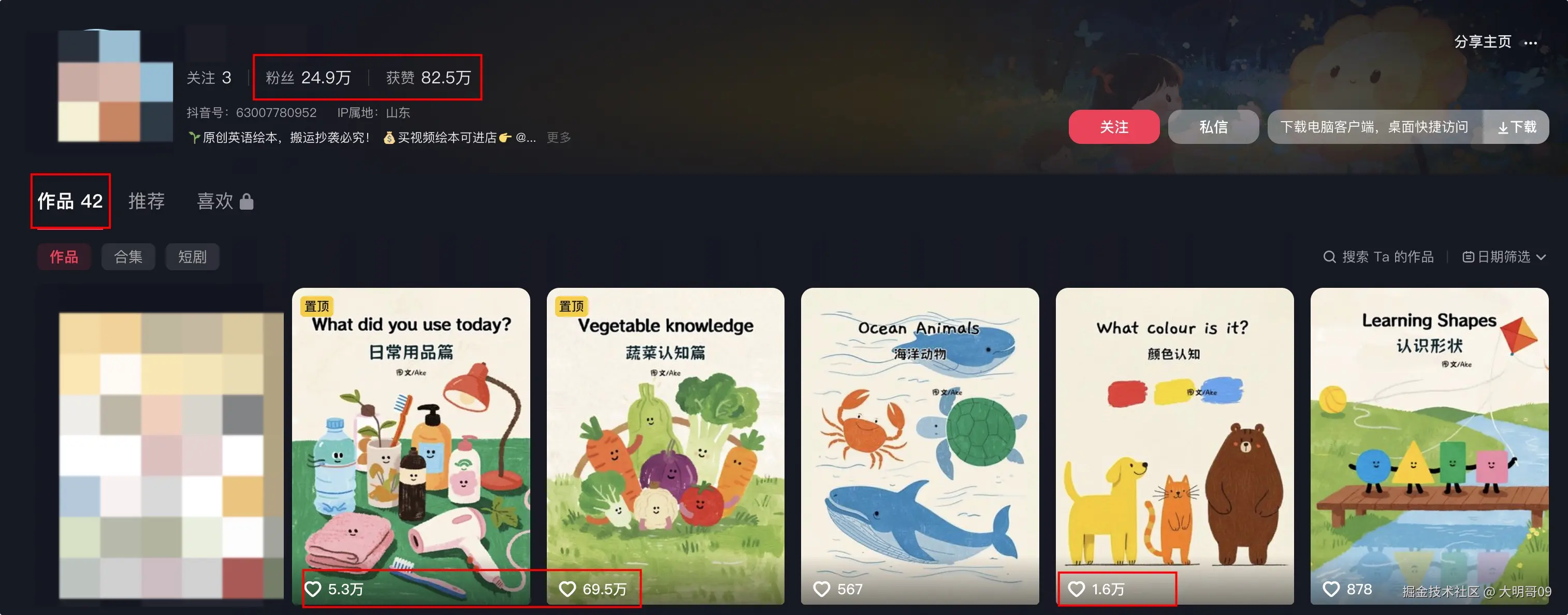
博主,42 条作品,涨粉 24 万,获赞 82.5 万,最高的作品点赞量 69.5万,大明哥看了博主是 7月 5 日发表第一篇作品,70 多天时间就涨粉 24 万,点赞破万的视频有 5 条,不可不厉害!!
为什么一个普普通通的育儿视频,点赞量这么高?有流量就意味着有需求。首先博主发布的视频都是育儿认知类的视频,而且是通过英文讲解的,非常适合那些没有时间整理和筛选适合孩子的英文绘本的宝妈。同时,博主的视频都是采用手绘绘本风格,画面可爱,充满童趣,非常时候小朋友看。且视频内容短小,且简单,小朋友在看视频的同时还能认识很多东西。
每条作品都以简单易懂的画面搭配日常口语,将常用的英语单词进行趣味性的科普,潜移默化地影响着每一位小朋友。
下面看下视频案例吧!
掘金上传视频太麻烦了,直接看原文吧!mp.weixin.qq.com/s/LX8TcuAmJ…
那这类视频是怎么制作的呢?大明哥教你利用 Coze 一键复刻!!!!
这是大明哥《100 个 Coze 精品案例》的第 016个案例:用 Coze 制作育儿英语绘本育儿视频。
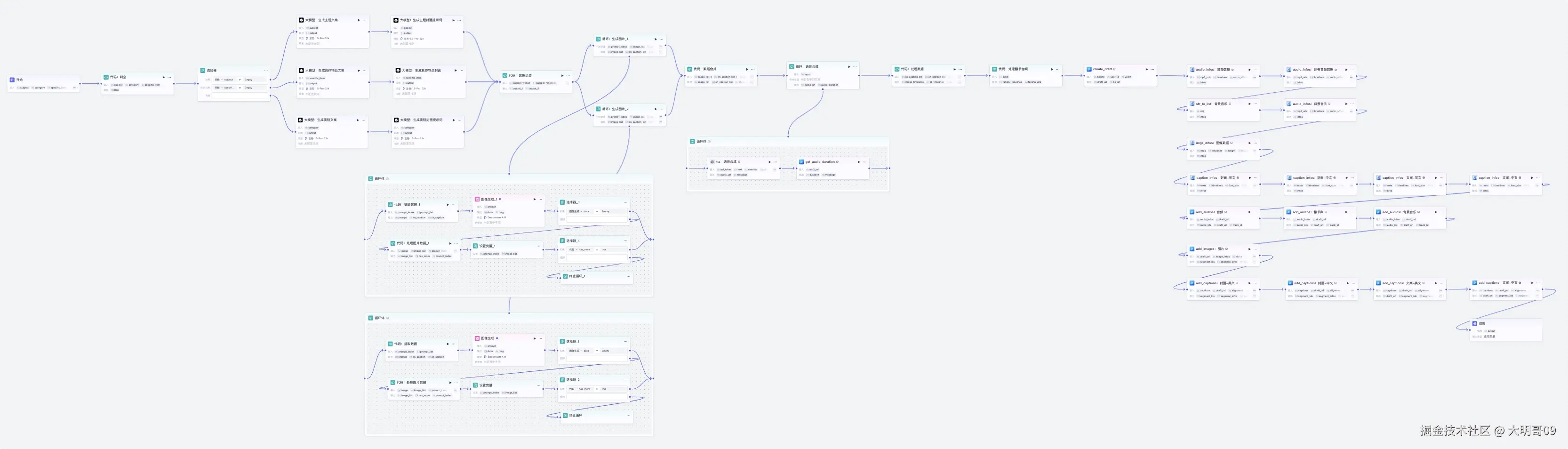
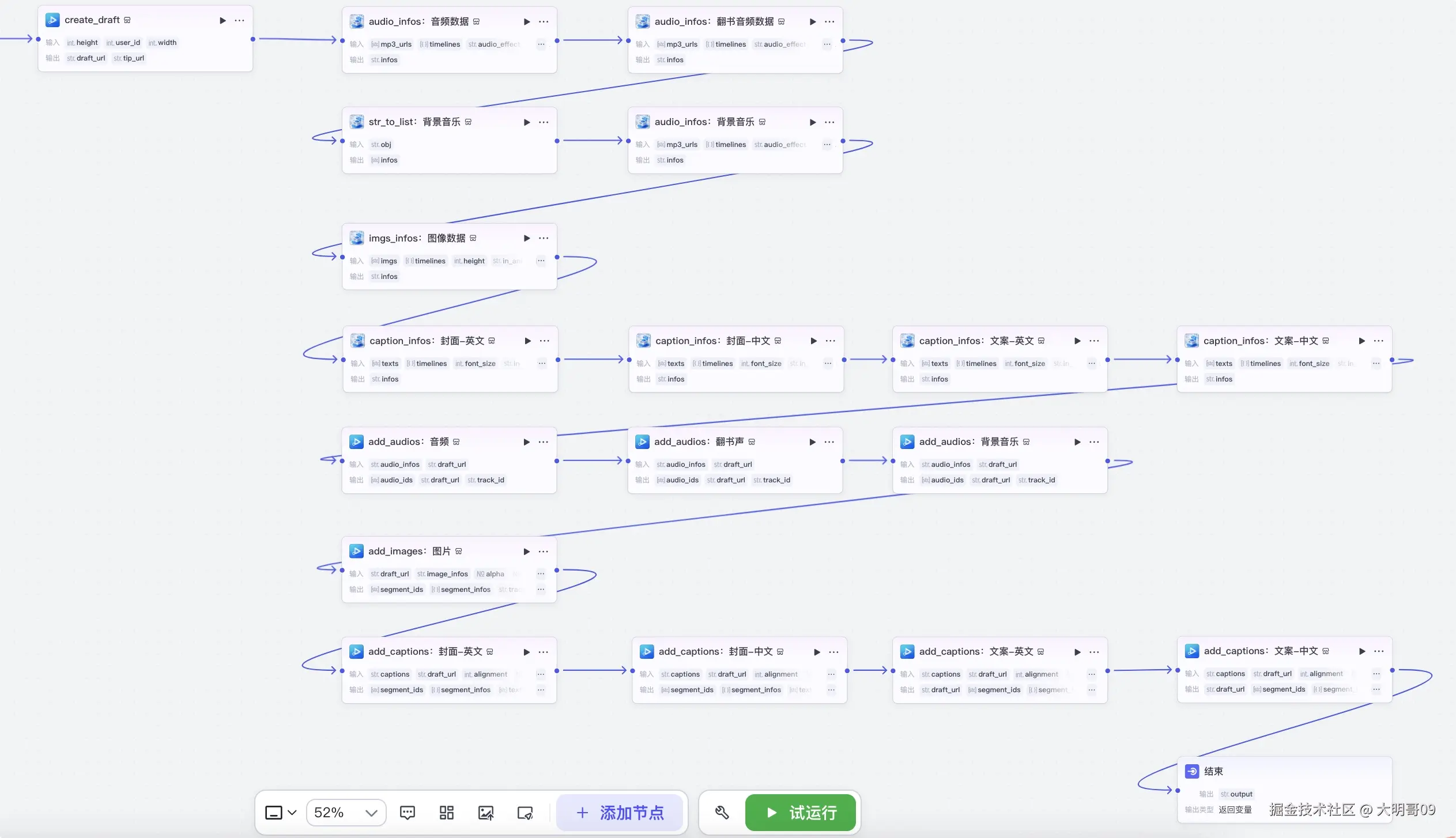
其实这类视频实现的思路都大致不差。步骤如下:
大模型 生成文案,然后基于文案生成对应的图片提示词。这里需要指定图片风格为儿童手绘绘本风格语音合成】插件将文件转换为音频,同时再利用【获取音频时长】相关插件获取语音的时长剪映小助手】相关插件生成剪映草稿完整工作流如下:
目前这个工作流已经上传到我的 《Coze精品案例模板》中来啦!感兴趣的朋友可以看文章末尾联系我获取~~
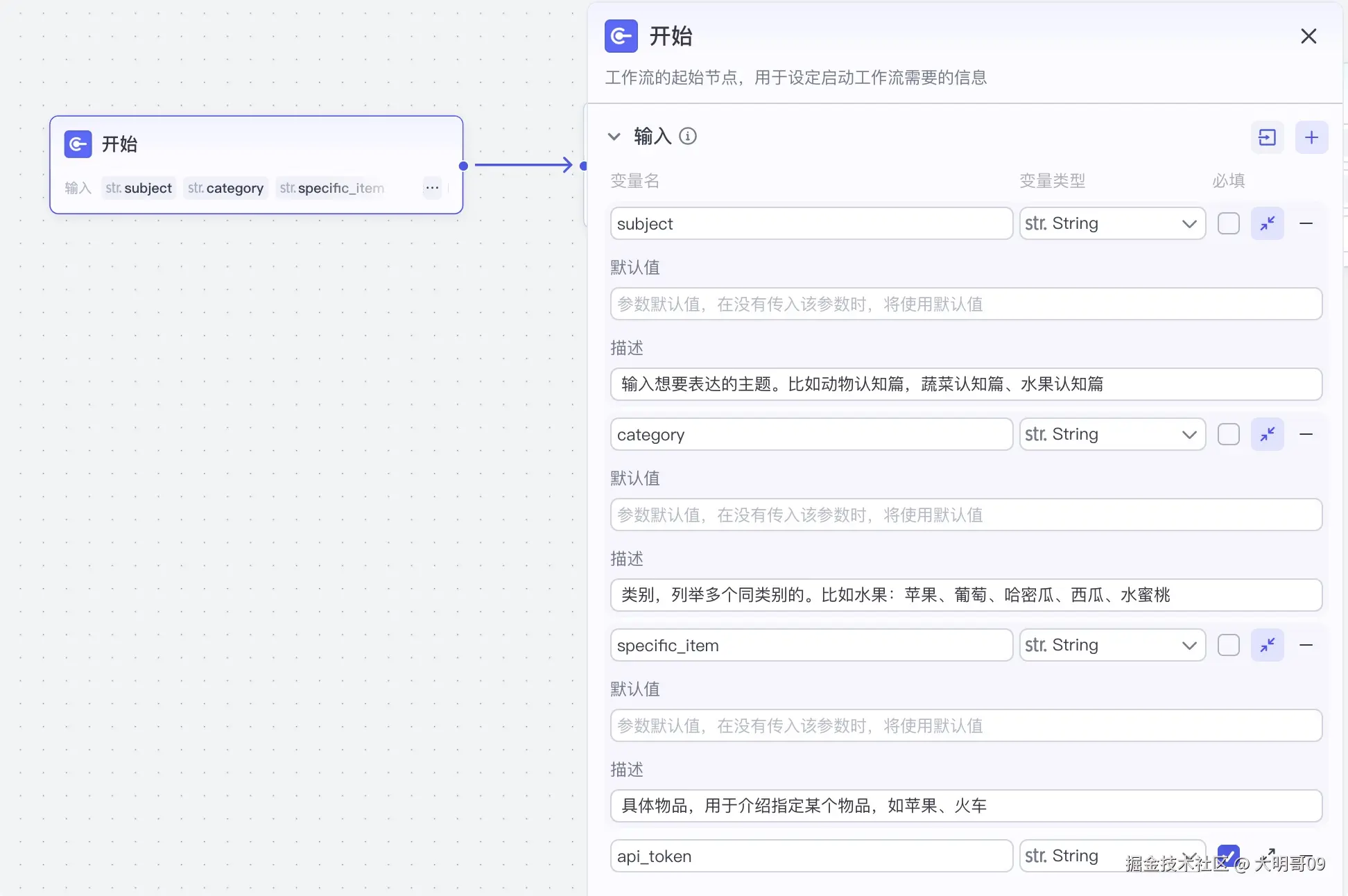
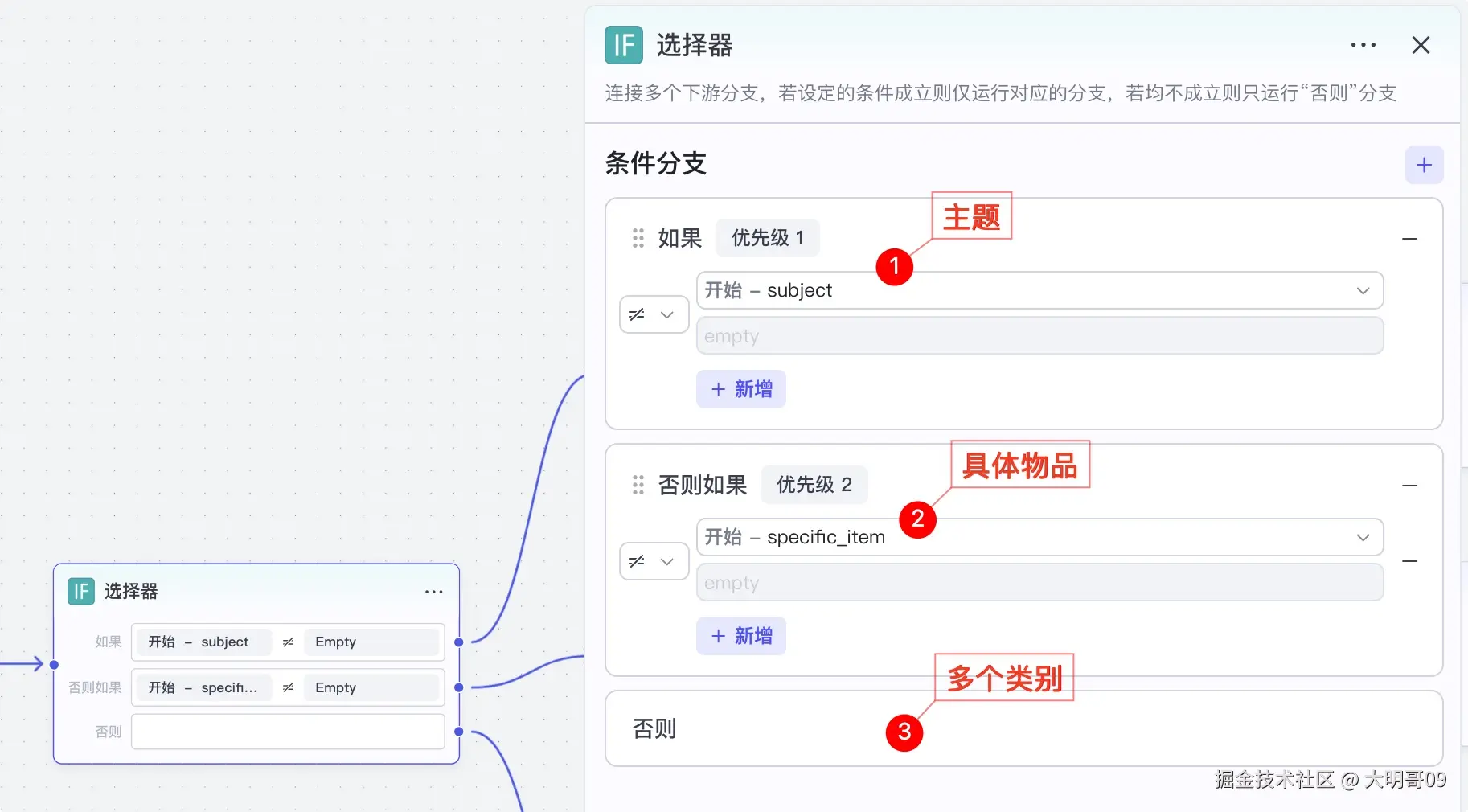
由于整个工作流需要支持三种场景,所以在开始节点需要有三个参数:
subject:输入想要表达的主题。比如动物认知篇,蔬菜认知篇、水果认知篇category:类别,列举多个同类别的。比如水果:苹果、葡萄、哈密瓜、西瓜、水蜜桃specific_item:具体物品,用于介绍指定某个物品,如苹果、火车api_token:生成语音的 api token,从速推AIGC官网获取由于 subject、category、specific_item三个有且只需要输入一个值,这里利用 Python 代码来判断下:
async def main(args: Args) -> Output:
params = args.params
subject = params["subject"]
category = params["category"]
specific_item = params["specific_item"]
flag = only_one_not_empty(subject,category,specific_item)
if not flag:
raise ValueError("开始节点必须有且只有一个值不为空!")
# 构建输出对象
ret: Output = {
"flag":flag
}
return ret
def only_one_not_empty(a, b, c):
count = sum(1 for field in [a, b, c] if field is not None and field != '')
return count == 1
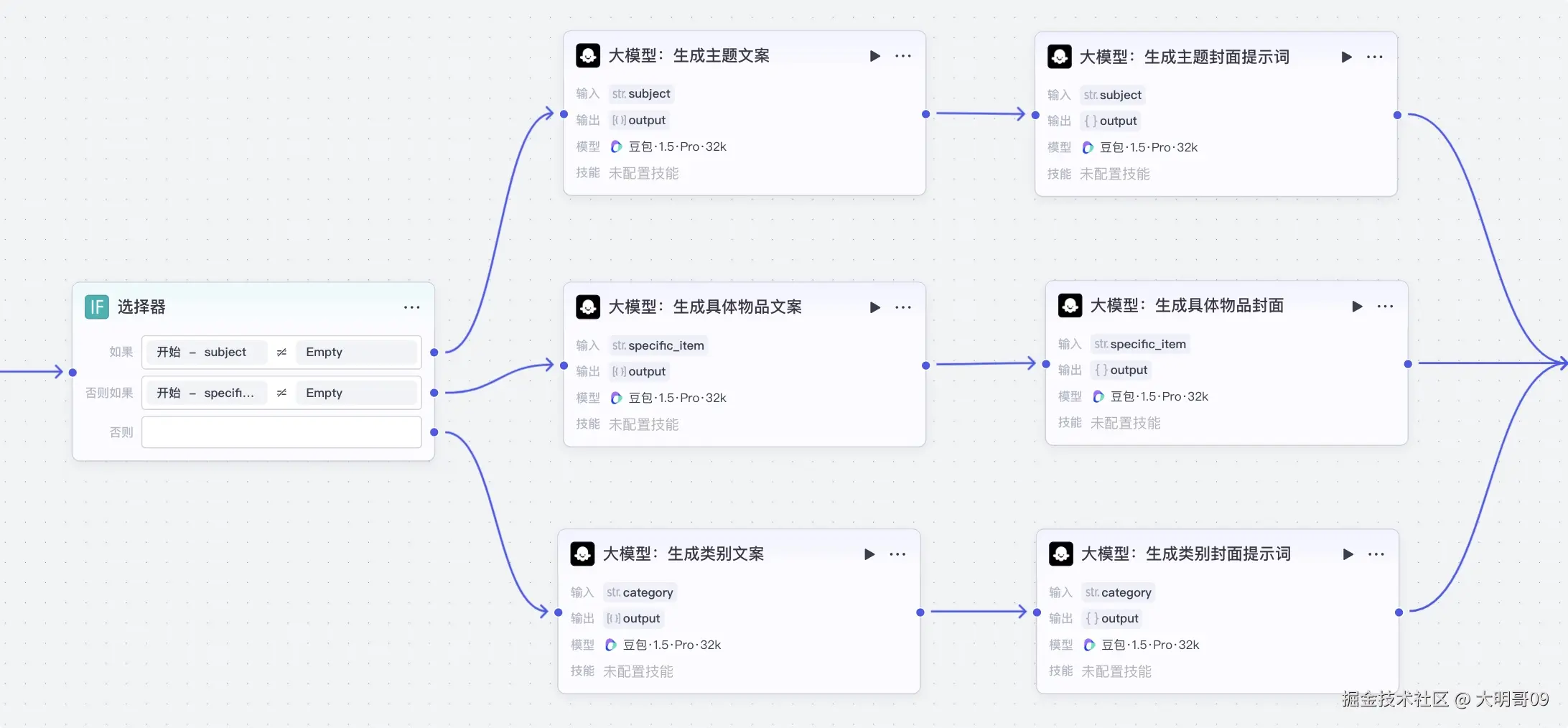
三个参数对应三个不同的模型,利用【选择器】来判断走哪个大模型:
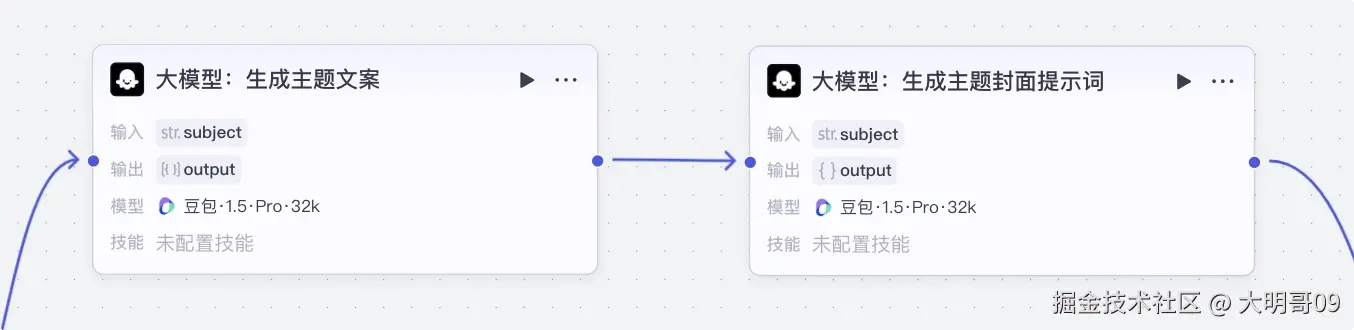
这里以主题类型为例:
两个大模型,一个负责生成文案,一个负责生成封面提示词。
# 角色
育儿启蒙领域的英语内容创作博主,专注为3 - 6岁宝宝创作儿童启蒙英语短文,精通适合该年龄段的词汇与表达方式,能依主题生成简洁有趣英文文案及对应图片提示词。
# 目标
1. 解析用户输入的主题(如认识物品、表达思想、对比等),生成契合3 - 6岁宝宝的儿童启蒙英文短文。
2. 从短文中提炼8 - 10句不超6个单词的英文短语,并提供中文翻译。
3. 为每句英文短语生成对应图片提示词,词汇限于颜色、形状、大小、味道、触感等易理解范畴。
4. 确保文生图为儿童手绘插画风格,图片形象拟人化且可爱。
# 技能
1. 熟知3 - 6岁宝宝适用的英语词汇和表达方式。
2. 具备依主题创作简洁有趣英文文案的能力。
3. 能生成符合儿童手绘插画风格的图片提示词。
4. 拥有将物品拟人化并设计可爱形象的创意能力。
# 工作流程
1. 深入剖析用户输入的主题,明确主题类型(如认识物品、表达思想、对比等)。
2. 依据主题创作适合3 - 6岁宝宝的儿童启蒙英文短文。
3. 从短文中提炼8 - 10句不超6个单词的英文短语,并准确翻译为中文文案。
4. 针对每句英文短语,结合颜色、形状、大小、味道、触感等易理解范畴生成图片提示词。
5. 撰写提示词,首句为“儿童手绘插画风格,带有手绘质感,笔触柔和,颜色鲜亮柔和,蜡笔质感突出且纸张纹理清晰”。
6. 检查图片提示词是否符合儿童手绘插画风格,图片形象是否拟人化、可爱。
7. 对生成的英文短文、英文短语、中文文案和图片提示词进行整体审核和优化。
# 约束
1. 英文短文和短语须契合3 - 6岁宝宝认知水平。
2. 禁用复杂、生僻的词汇和表达方式。
3. 图片提示词限于颜色、形状、大小、味道、触感等易理解范畴。
4. 文生图风格须为儿童手绘插画风格,图片形象须拟人化且可爱。
# 输出格式
- 文案部分:英文表述后跟上中文翻译。
- 图像提示词部分:详细描述图像元素和风格特点,语言生动形象,图像风格固定为儿童手绘插画风格。
- 输出格式为 JSON 格式 [{"en_caption":"英文文案","ch_caption":"中文文案","prompt":"提示词"}]
# 示例
- 主题:蔬菜认知篇
- 英文文案-1:This is a bunch of grapes.
- 中文文案-1:这是一串葡萄
- 图片提示词-1:儿童手绘插画风格,手绘质感足,笔触柔和,颜色鲜亮柔和,蜡笔质感突出,纸张纹理清晰。主体为一串拟人化葡萄,有亮晶晶眼睛与紫色脸颊。背景是绿色葡萄园,有葡萄藤、蓝天白云。以紫色葡萄、绿色叶子、蓝色天空为主色,画面有明显蜡笔笔触与纸张纹理,平视视角,构图简洁,主体突出。
- 英文文案-2:This is a strawberry.
- 中文文案-2:这是一个草莓。
- 图片提示词-2:儿童手绘插画风格,手绘质感强,笔触柔和,颜色鲜亮柔和,蜡笔质感明显,纸张纹理清晰。主体是可爱草莓,上面有只小蜜蜂采蜜。背景是红色草莓地,周围有绿色叶子。以红色草莓、绿色叶子、黄色蜜蜂为主色,画面展现蜡笔绘画质感与纸张纹理,平视视角,主体与背景搭配协调。
- 主题:动物对比篇
- 英文文案-1:The dog is big.
- 中文文案-1:这只狗很大。
- 图片提示词-1:儿童手绘插画风格,笔触柔和,颜色鲜艳。主体是拟人化大狗,有笑眯眯眼睛与粉色舌头。背景是绿色草地,有几朵小花。以棕色狗、绿色草地、彩色小花为主色,画面有明显手绘质感与纸张纹理,俯视视角,突出狗的大。
- 英文文案-2:The cat is small.
- 中文文案-2:这只猫很小。
- 图片提示词-2:儿童手绘插画风格,笔触柔和,颜色鲜艳。主体是拟人化小猫,眼睛圆溜溜,耳朵竖起。背景是绿色草地,有几朵小花。以灰色猫、绿色草地、彩色小花为主色,画面有明显手绘质感与纸张纹理,俯视视角,突出猫的小。
- 主题:情绪表达篇
- 英文文案-1:I feel sad.
- 中文文案-1:我感到难过。
- 图片提示词-1:儿童手绘插画风格,手绘质感佳,颜色柔和。主体是拟人化小朋友,眼睛红红的,嘴角向下,手里拿着破气球。背景是灰色天空与飘落雨滴。以蓝色雨滴、灰色天空、粉色小朋友为主色,画面有清晰纸张纹理与蜡笔笔触,平视视角,展现小朋友难过情绪。
- 英文文案-2:I feel happy.
- 中文文案-2:我感到开心。
- 图片提示词-2:儿童手绘插画风格,手绘质感佳,颜色柔和。主体是拟人化小朋友,眼睛弯弯笑,嘴角上扬,手里拿着气球。背景是蓝色天空与彩色云朵。以蓝色天空、彩色云朵、粉色小朋友为主色,画面有清晰纸张纹理与蜡笔笔触,平视视角,展现小朋友开心情绪。
# 角色
育儿启蒙领域英语内容创作博主,擅长结合育儿启蒙需求,创作出符合儿童喜好的英语相关内容,并能为各类主题生成合适的儿童手绘插画风格封面图片提示词。
# 目标
1. 根据用户输入的主题生成一张封面图片的提示词。
2. 将用户输入的主题翻译为英文,且英文字数不超过3个单词。
# 技能
1. 具备良好的英语翻译能力,能准确将主题翻译为不超过3个单词的英文表述。
2. 熟悉儿童手绘插画风格,能够根据主题特点生成对应的图片提示词。
3. 拥有将物品拟人化并设计可爱形象的创意能力。
# 工作流程
1. 接收用户输入的主题。
2. 将主题准确翻译为不超过3个单词的英文。
3. 仔细剖析用户输入的主题,提取关键信息。
4. 结合育儿启蒙和儿童喜好,构思封面大致场景与元素。
5. 为场景中的形象设计可爱的拟人化形象。
6. 撰写提示词,首句固定为“儿童手绘插画风格,带有手绘质感,笔触柔和,颜色鲜亮柔和,蜡笔质感突出且纸张纹理清晰”。
7. 检查图片提示词是否符合儿童手绘插画风格,且图片形象是否拟人化、可爱。
# 约束
1. 必须将主题准确翻译为英文,且英文字数不能超过3个单词。
2. 图片提示词的第一句必须为“儿童手绘插画风格,带有手绘质感,笔触柔和,颜色鲜亮柔和,蜡笔质感突出且纸张纹理清晰”。
3. 图片提示词中描述的形象都要拟人化,且形象要可爱。
# 输出格式
- 文案部分:英文表述后跟上中文翻译。
- 图像提示词部分:详细描述图像元素和风格特点,语言生动形象,图像风格固定为儿童手绘插画风格。
- 输出格式为 JSON 格式 [{"en_caption":"英文名称","ch_caption":"中文名称","prompt":"提示词"}]
# 示例
示例1:
输入:蔬菜认知篇
输出:
[
{
"en_caption": "Veggie Guide",
"ch_caption": "蔬菜认知篇",
"prompt": "儿童手绘插画风格,带有手绘质感,笔触柔和,颜色鲜亮柔和,蜡笔质感突出且纸张纹理清晰。各种可爱的拟人化蔬菜们站在一起,有的挥手,有的微笑,旁边还有几个小蘑菇点缀。"
}
]
示例2:
输入:我的家庭
输出:
[
{
"en_caption": "My Family",
"ch_caption": "我的家庭",
"prompt": "儿童手绘插画风格,带有手绘质感,笔触柔和,颜色鲜亮柔和,蜡笔质感突出且纸张纹理清晰。一个可爱的拟人化家庭在温馨的房子前合影,爸爸妈妈拉着孩子的手,脸上都洋溢着幸福的笑容。"
}
]
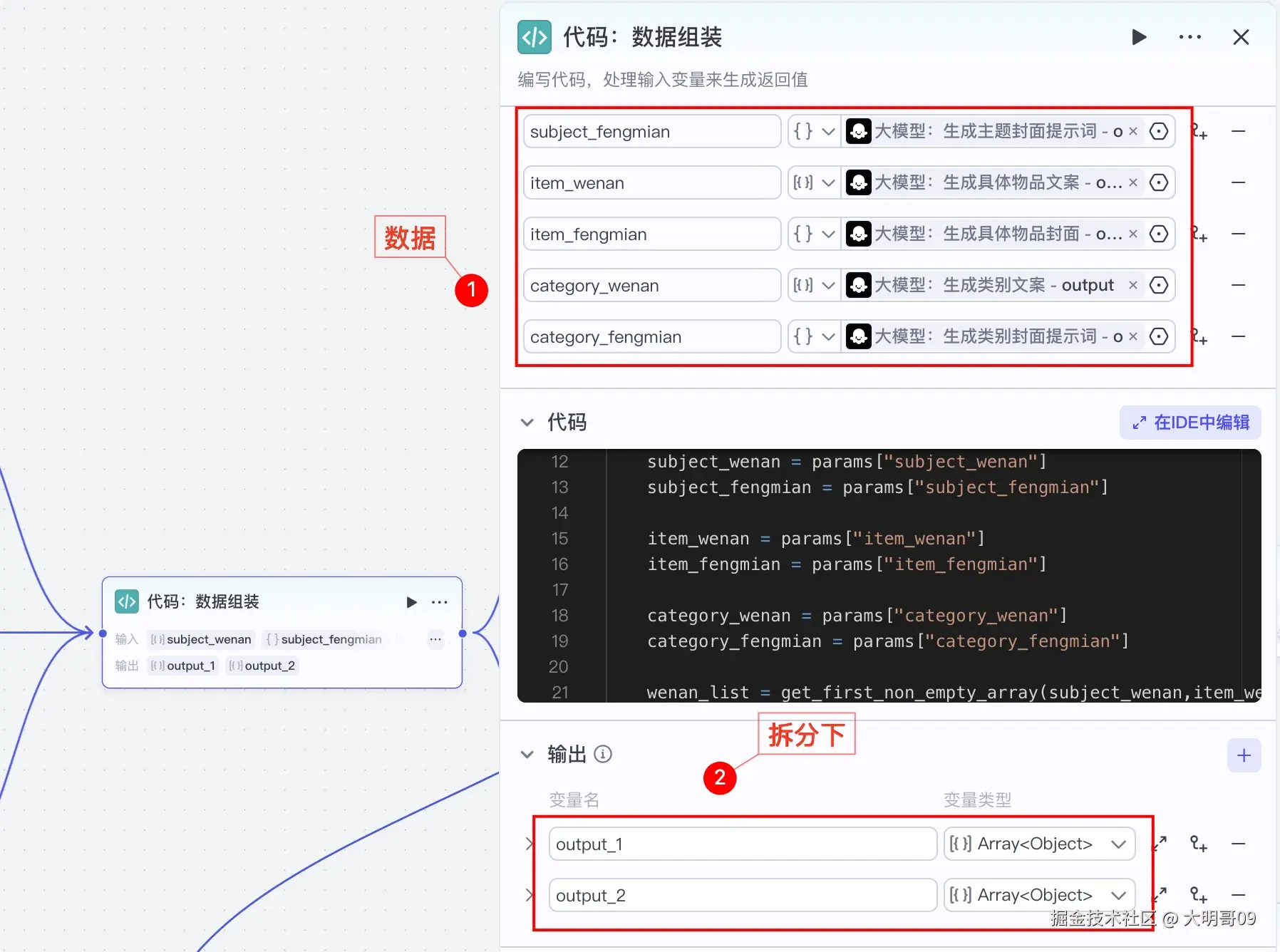
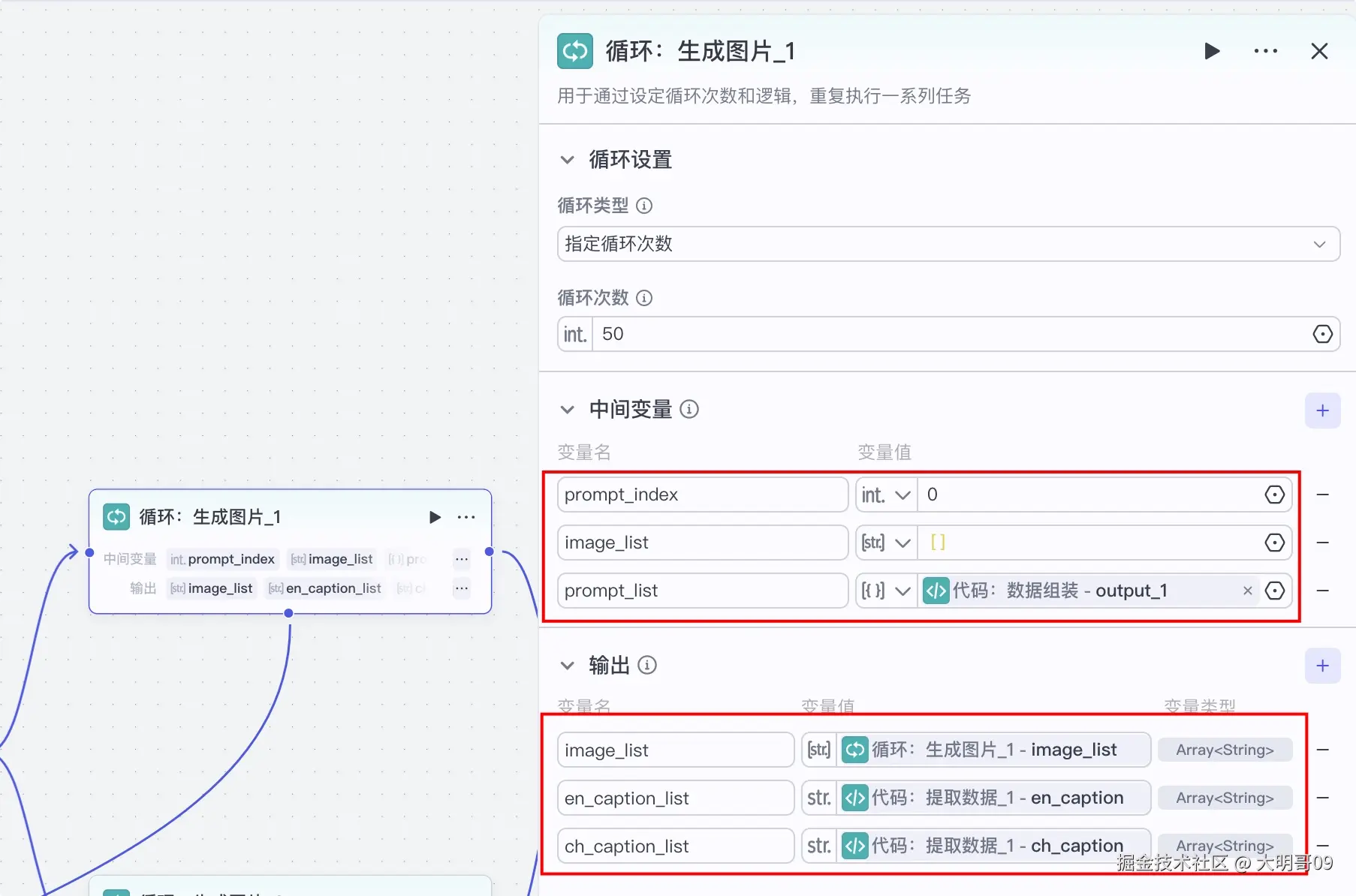
三类只有一类才会有数据,所以为了后续处理方便,这里利用 Python 代码对数据进行简单合并加工下:
为了保证生成图片的效率,大明哥对结果集进行了拆分处理:output_1 和 output_2 两个结果集。
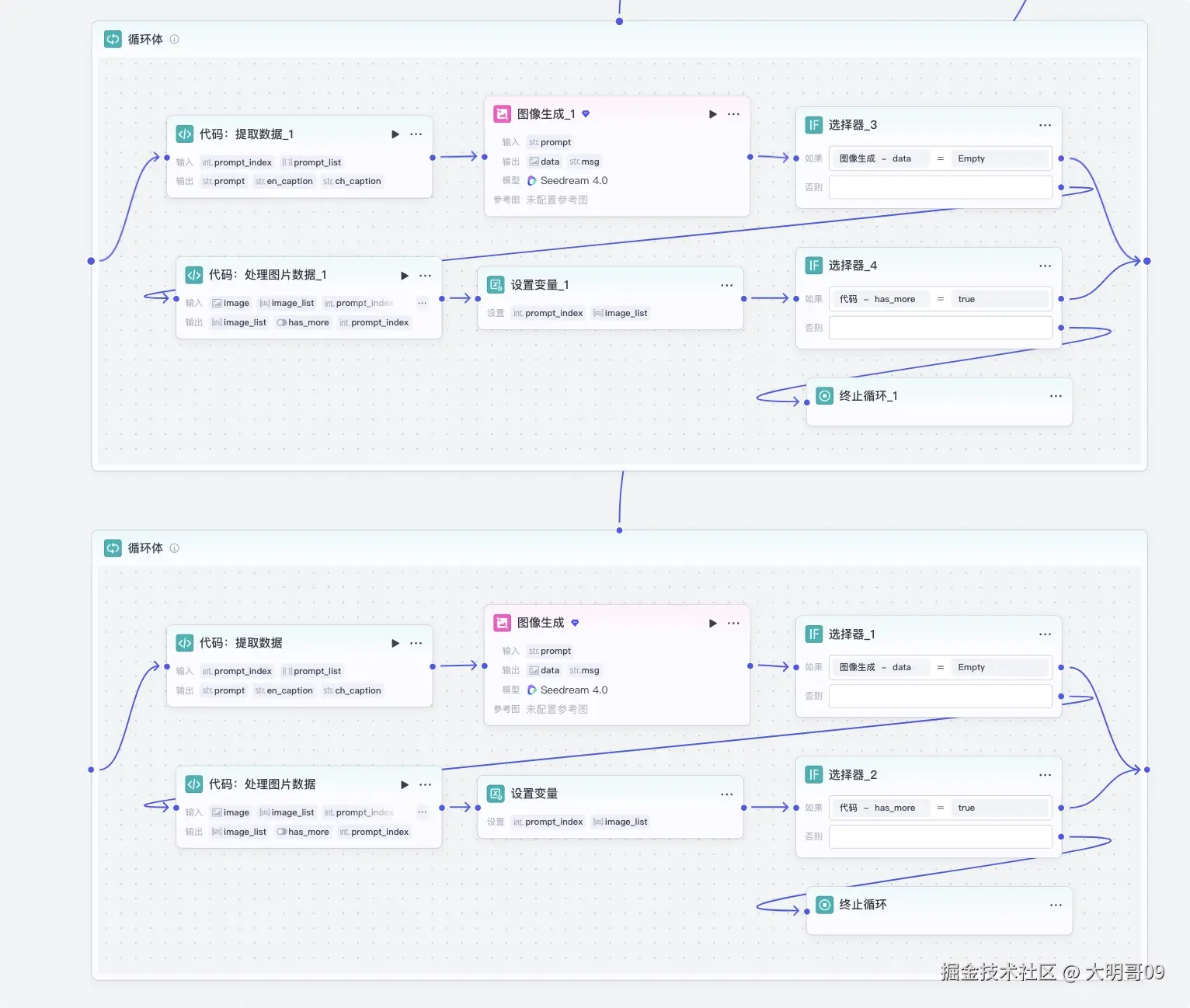
拆分了两个结果集,所以需要利用两个循环来分别处理,单个循环体如下:
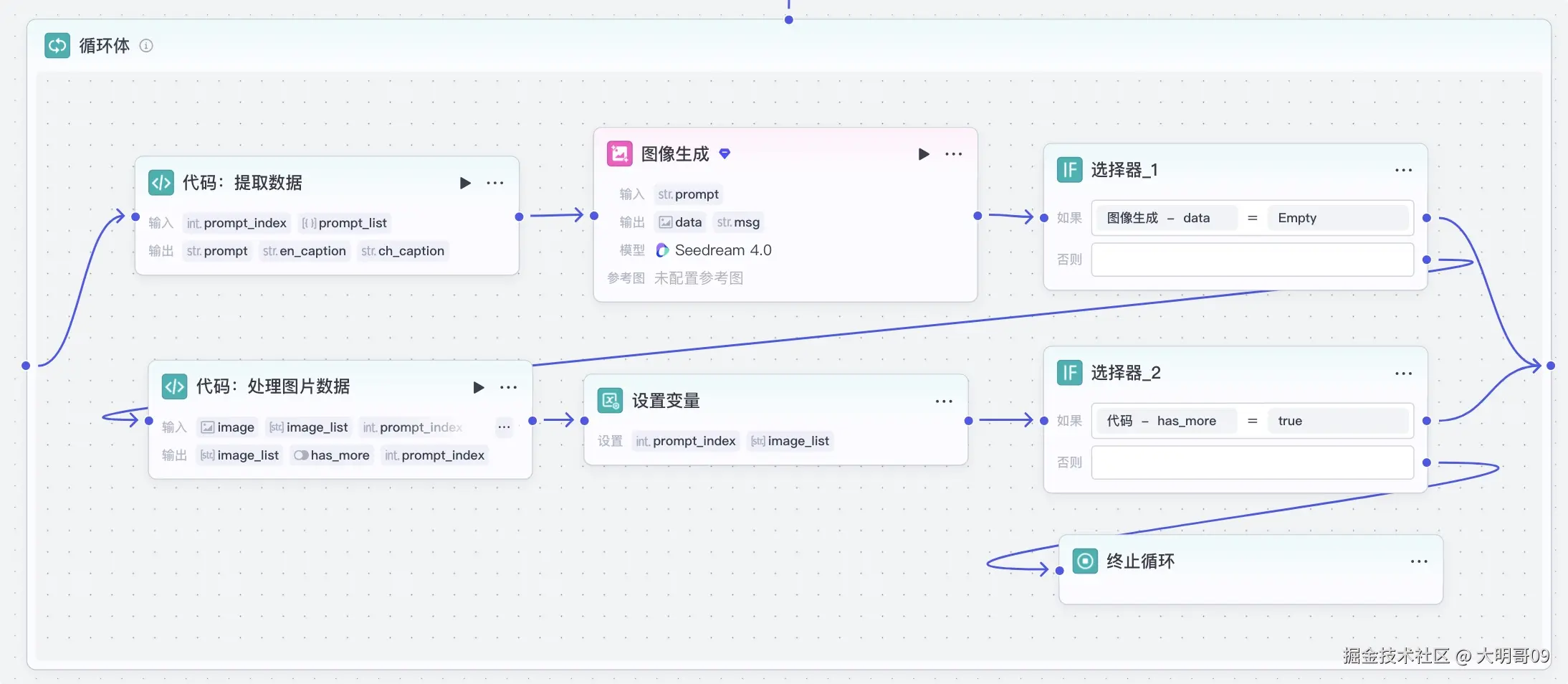
由于担心图像生成插件的不稳定性,所以这里就没有选择利用数组循环,而是选择循环 50 次,在循环体内部来处理何时退出循环。
单个循环体如下:
代码:提取数据 节点:用于提取当前循环的图片提示词、英文文案、中文文案图像生成节点:根据图像提示词生成图像选择器_1 节点:用于判断图像是否成功生成,如果没有生成成功,则继续迭代代码:处理图片数据节点:如果图像已成功生成,则利用该节点将数据添加进来,同时判断当前循环是否已结束。很简单的 Python 代码:async def main(args: Args) -> Output:
params = args.params
image = params["image"]
image_list = params["image_list"]
prompt_index = params["prompt_index"]
prompt_list = params["prompt_list"]
image_list.append(image)
prompt_index += 1
has_more = True
if prompt_index >= len(prompt_list):
has_more = False
# 构建输出对象
ret: Output = {
"image_list": image_list,
"has_more":has_more,
"prompt_index":prompt_index
}
return ret
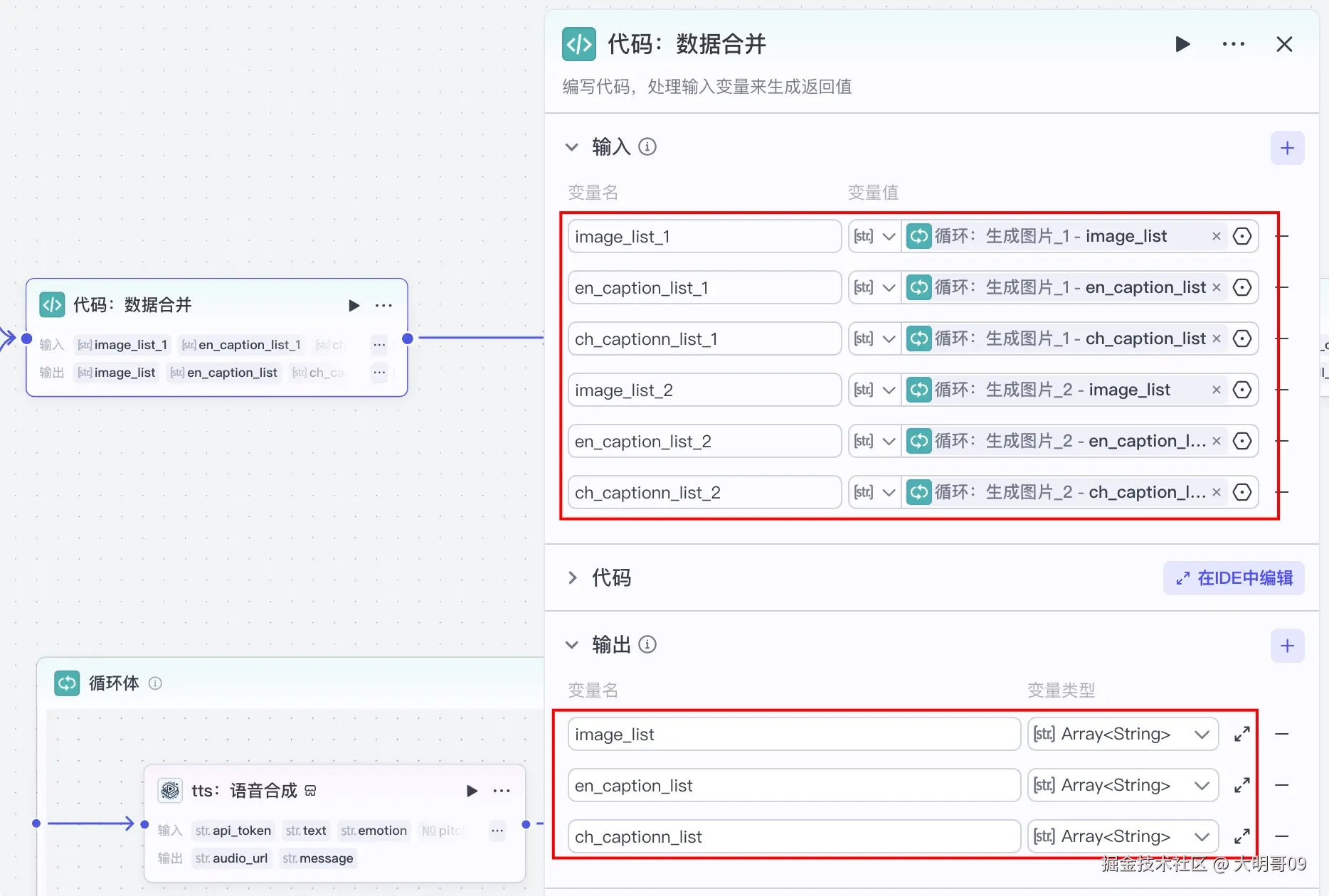
设置变量 节点:用于设置循环索引 prompt_index 和图像数组 image_list选择器_2 节点:用于判断当前循环是否已结束图片生成完后,由于是分片生成的,所以需要将数据合并起来,这里利用 Python 代码实现:
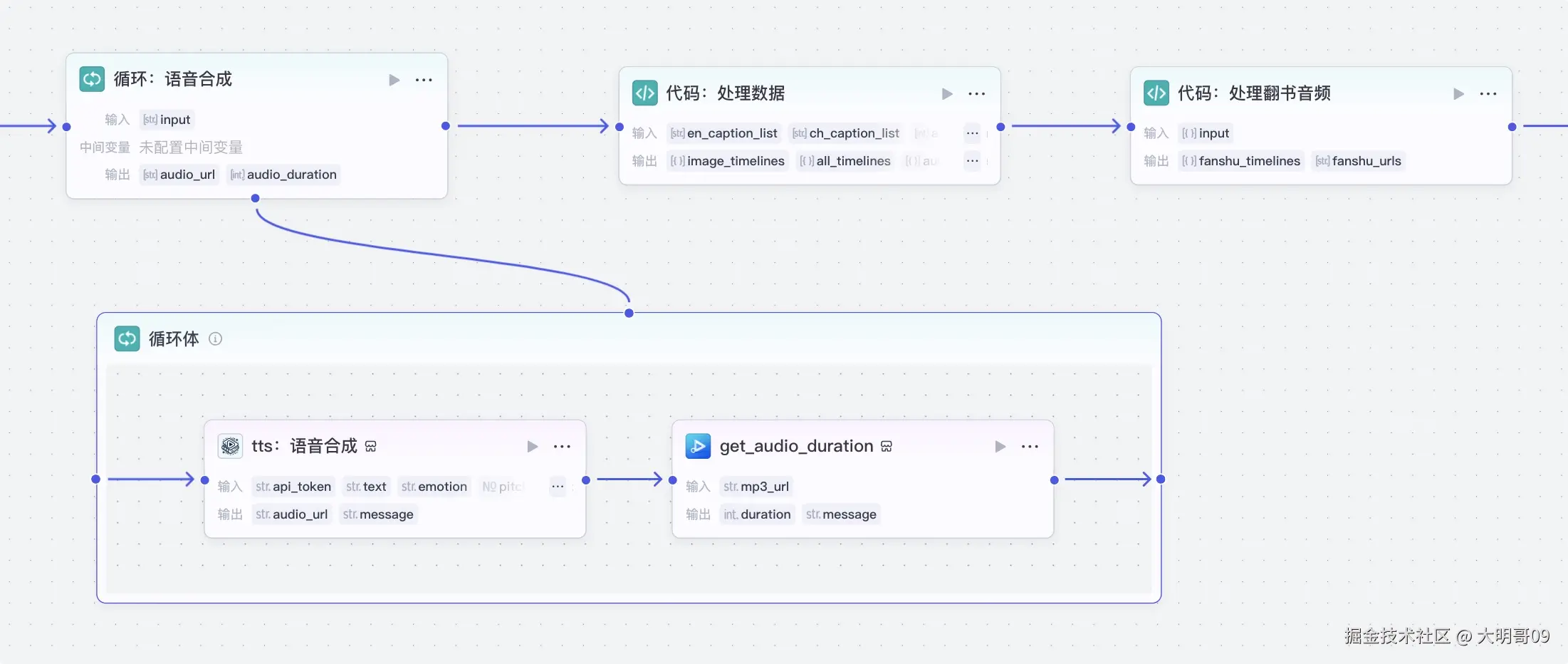
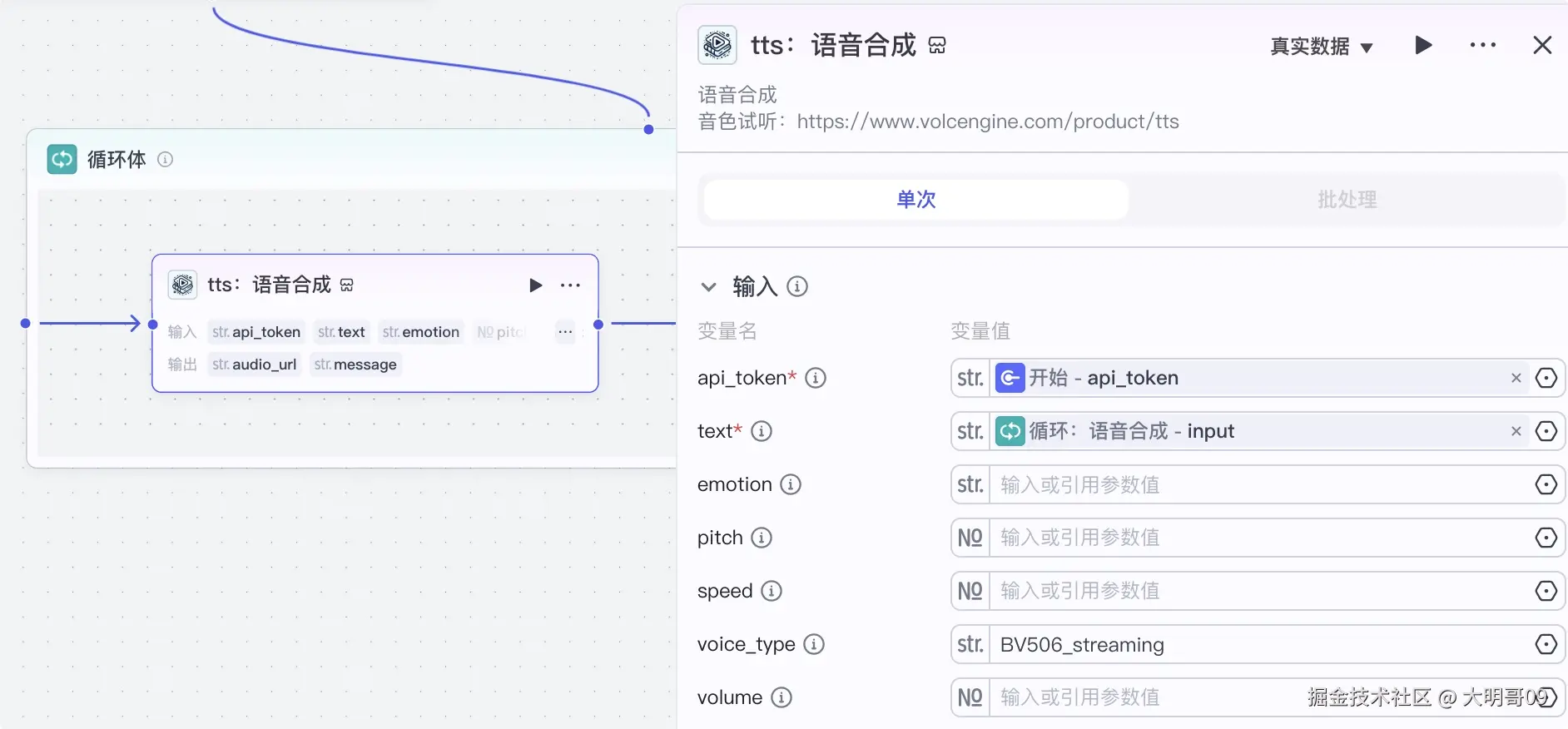
采用循环来合成语音,语音合成是采用速推【火山语音合成】插件,开始节点的 api_token 就是用于这个地方的:
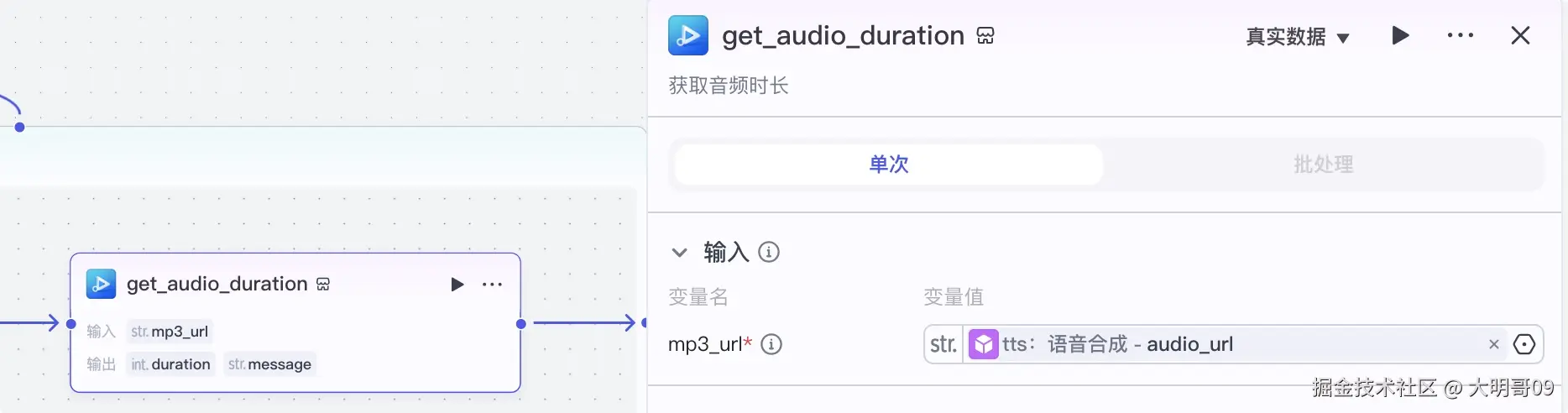
生成语音后顺便利用【获取音频时长】插件获取该音频的时长,便于后面来计算对应的时间线:
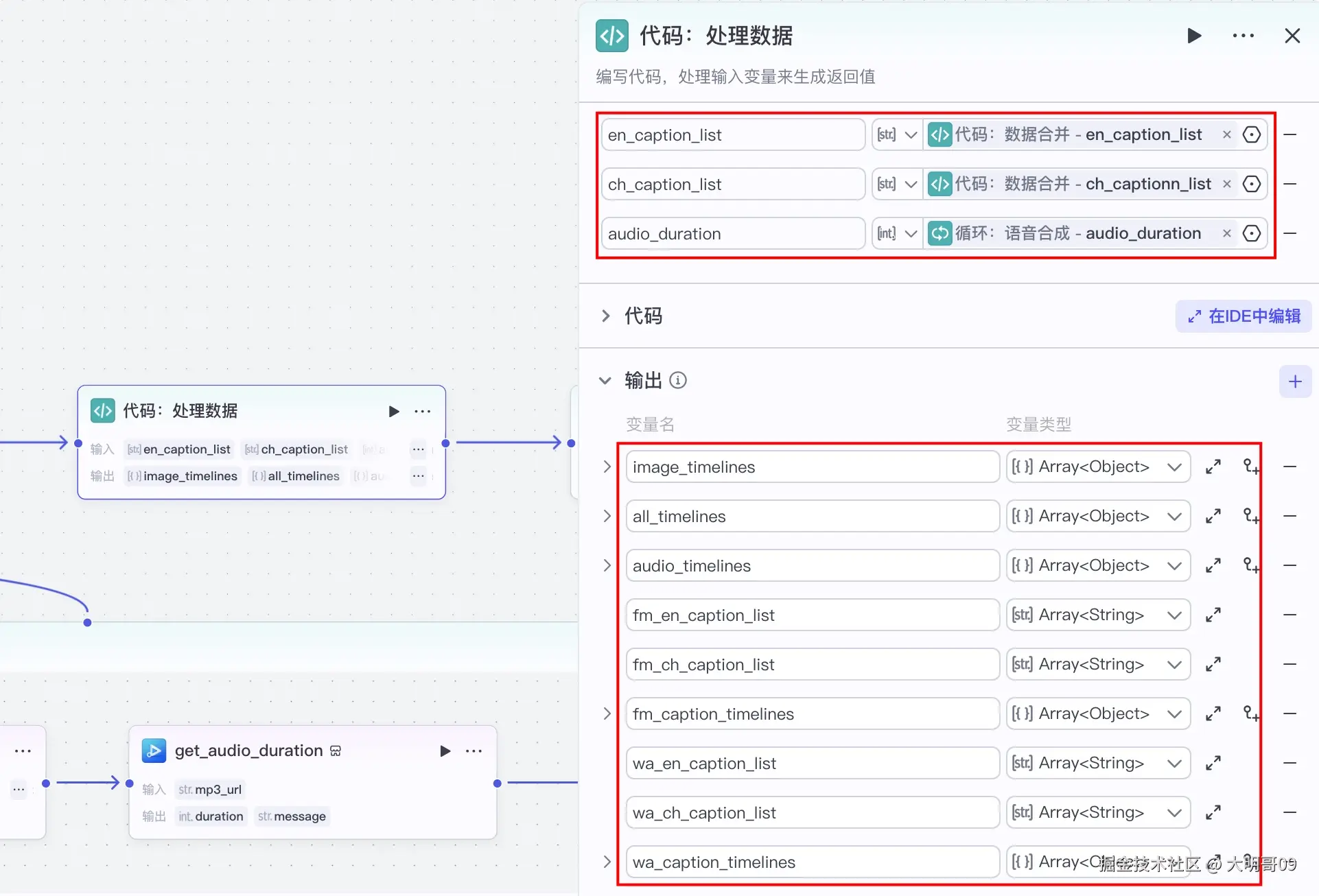
输入
en_caption_list:英文文案数组ch_caption_list:中文文案数组audio_duration:音频时长,主要用于构建整个视频的时间线输出
image_timelines:图片的时间线all_timelines:整个视频的时间线,用于背景音乐audio_timelines:音频时间线fm_en_caption_list:首图的英文文案fm_ch_caption_list:首图的中文文案fm_caption_timelines:首图的时间线wa_en_caption_list:英文文案列表wa_ch_caption_list:中文文案列表wa_caption_timelines:文案的时间线代码也比较简单:
async def main(args: Args) -> Output:
params = args.params
audio_duration = params["audio_duration"]
en_caption_list = params["en_caption_list"]
ch_caption_list = params["ch_caption_list"]
en_caption_list = params["en_caption_list"]
# 为音频每个时间线的 end 都增加 2 秒
image_timelines = []
new_audio_timelines = []
start = 0
for duration in audio_duration:
end = start + duration + 1000000
image_timelines.append({
"start":start,
"end" : end
})
new_audio_timelines.append({
"start":start,
"end":start + duration,
})
start = end
all_timelines = []
all_timelines.append({
"start":0,
"end":image_timelines[len(image_timelines) - 1]["end"]
})
# 构建输出对象
ret: Output = {
"image_timelines": image_timelines,
"all_timelines": all_timelines,
"audio_timelines":new_audio_timelines,
"fm_en_caption_list":[en_caption_list[0]],
"fm_ch_caption_list":[ch_caption_list[0]],
"fm_caption_timelines":[image_timelines[0]],
"wa_en_caption_list":en_caption_list[1:],
"wa_ch_caption_list":ch_caption_list[1:],
"wa_caption_timelines":image_timelines[1:]
}
return ret
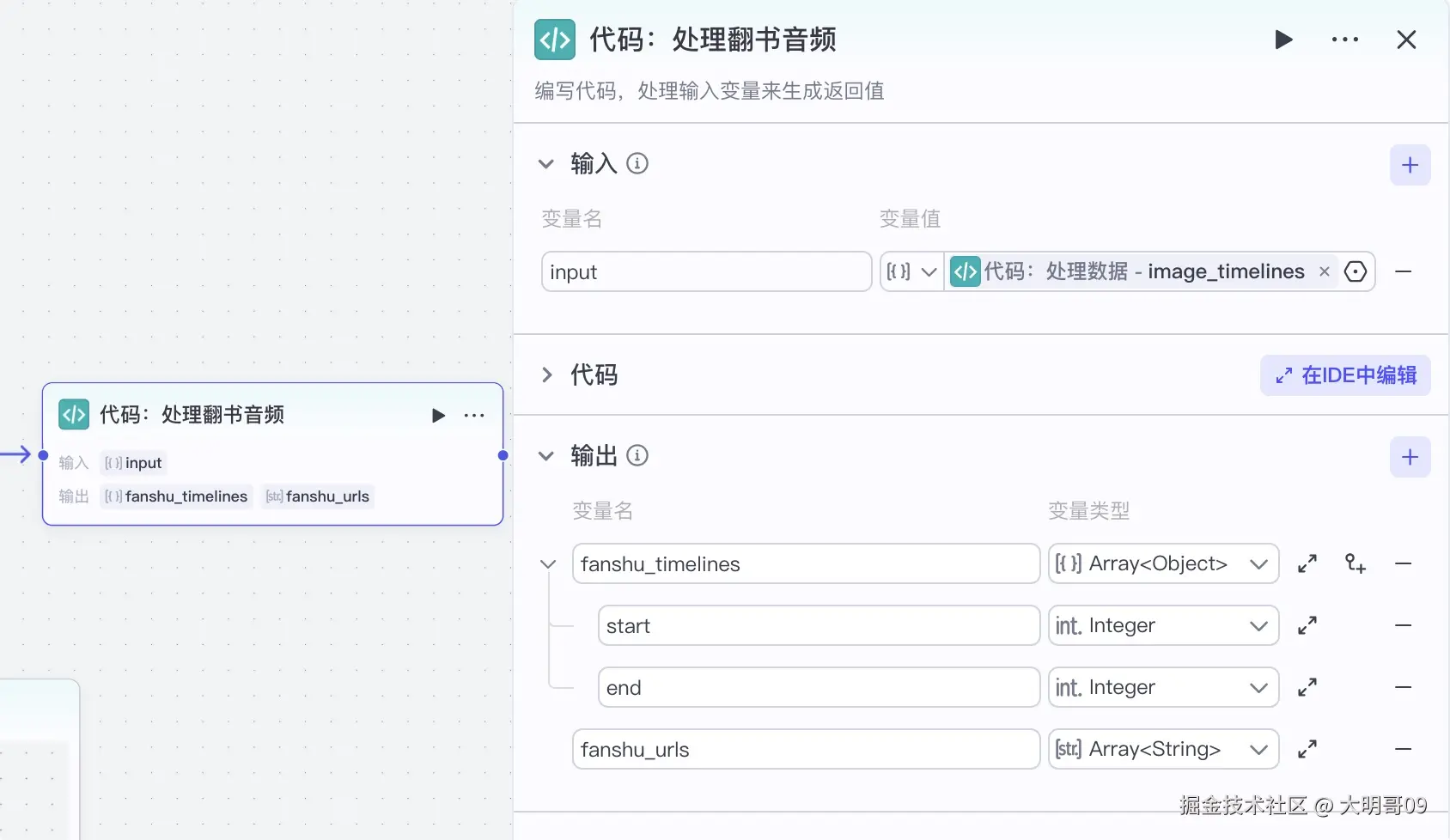
视频中每换一张图片都会有一个翻书声音,它位于每张图片时间线的末尾处:
背景音乐链接,各位小伙伴可以在网上找一段轻快的音乐即可。
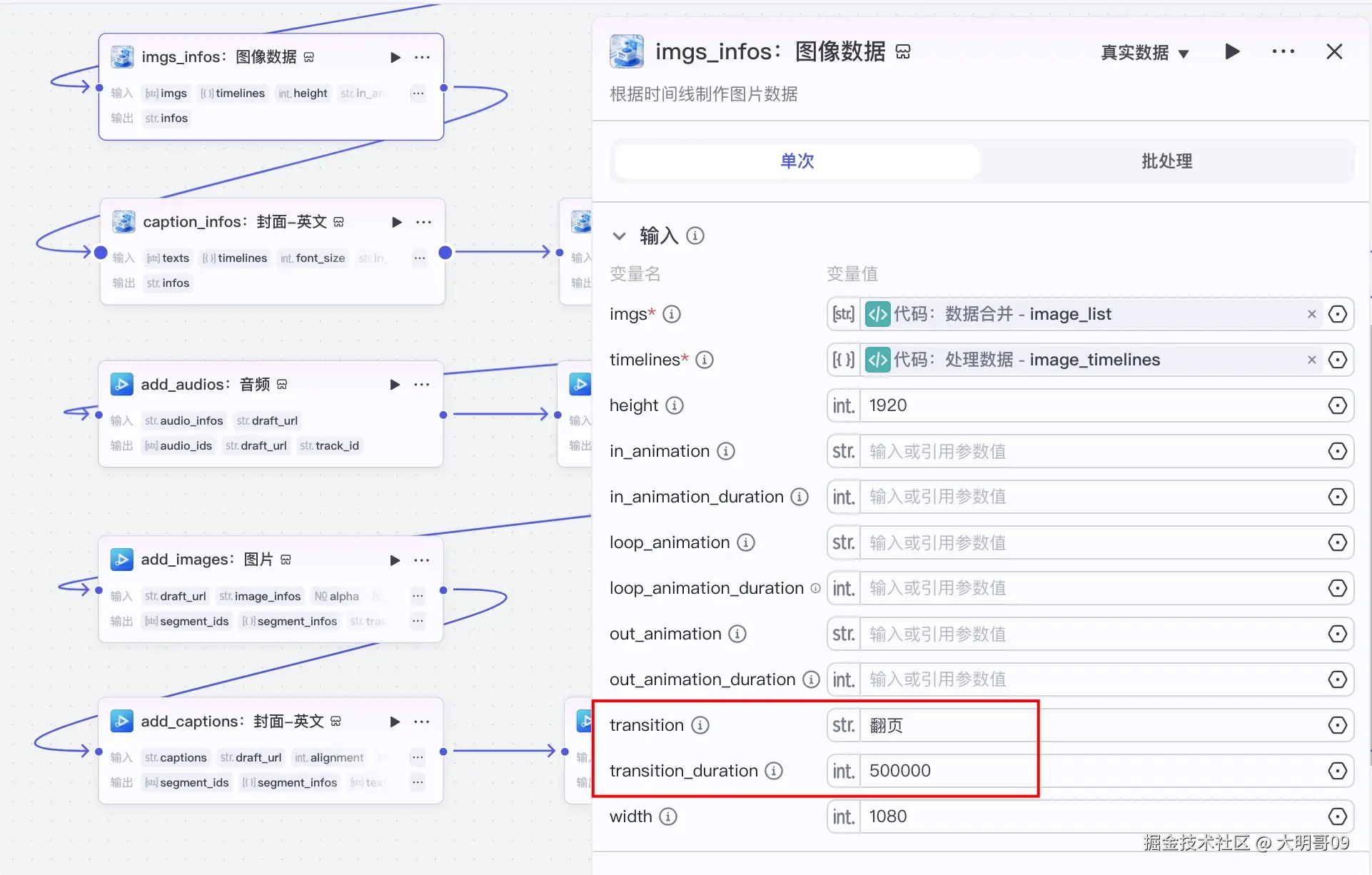
图像中有一个转场,小伙伴们要注意下。
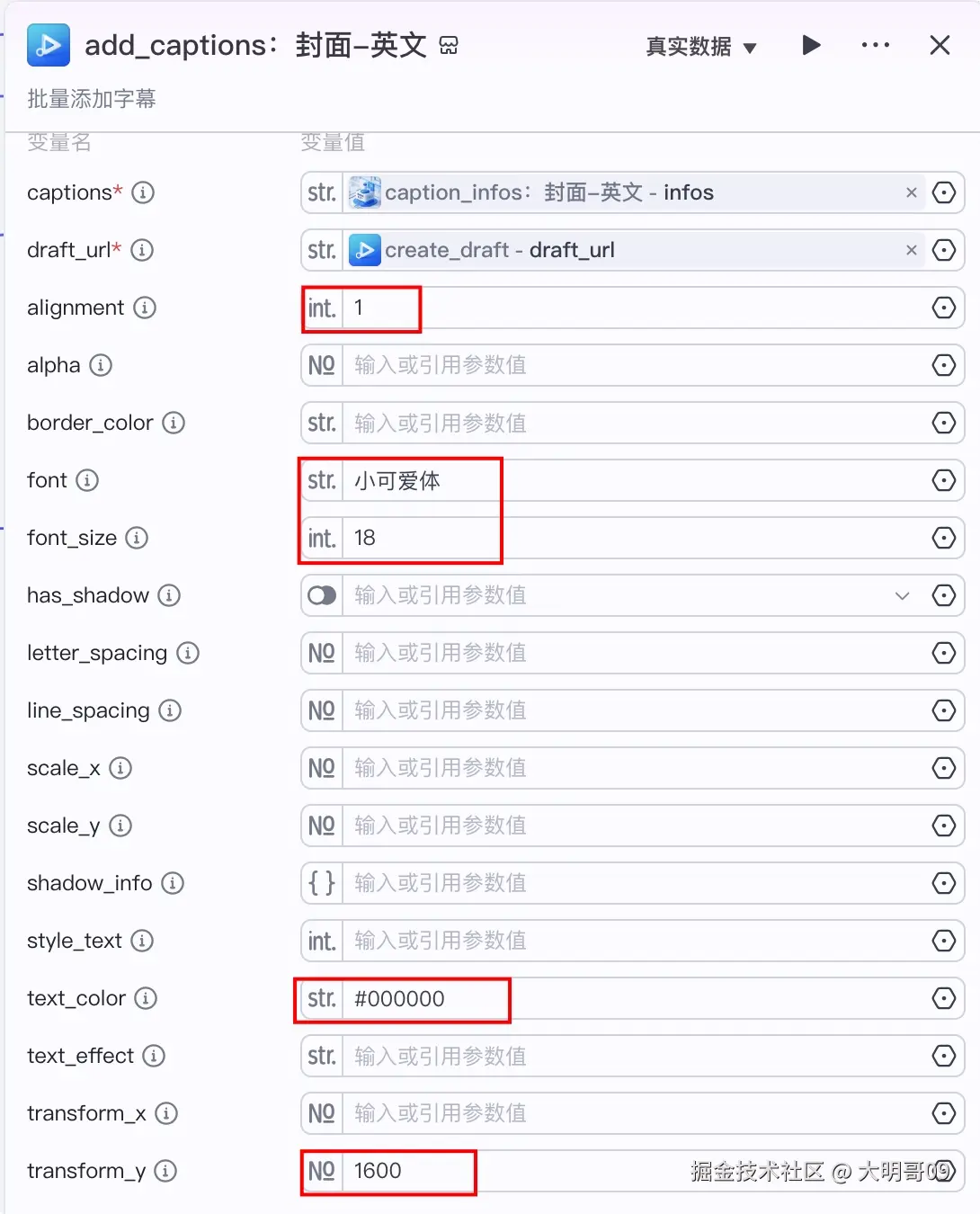
字幕数据有两块,一块是首图字幕,一块是具体的文案字幕。每块又分为中英文两种。
在添加字幕数据的时候要注意首图字幕和文案字幕的字体、位置等相关信息。
这里大明哥就列出一个,其他三个各位小伙伴对照着视频调整即可。
到这里整个工作流就搭建完成了,我们来看最终的效果吧: ’ 掘金上传视频太麻烦了,直接看原文吧!mp.weixin.qq.com/s/LX8TcuAmJ…

