
才到云(办公助手)
45.26MB · 2025-12-17

随着 spring-ai-alibaba-graph 模块的广泛应用,社区中出现了许多关于其流式处理实现机制的疑问和使用文档需求。其中最突出的问题是:graph 模块的流式实现如何与当前主流的响应式流(Reactive Streams)框架进行集成。
当前 graph 模块采用传统的迭代器模式实现流式输出,这种实现方式与主流的响应式编程范式存在较大差异。在与 Project Reactor、RxJava 等响应式流框架集成时,开发者需要进行大量额外的适配工作,增加了技术复杂性和维护成本。
为解决这一问题并提升框架的现代化程度,团队对 graph 内核中的流式输出机制进行了重构,采用基于 Project Reactor 的响应式流实现,以更好地与现代响应式生态系统集成,降低开发者的使用门槛并提高整体性能表现。
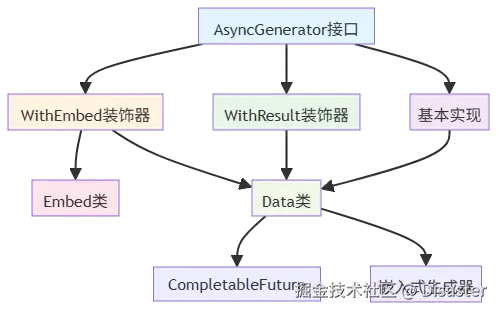
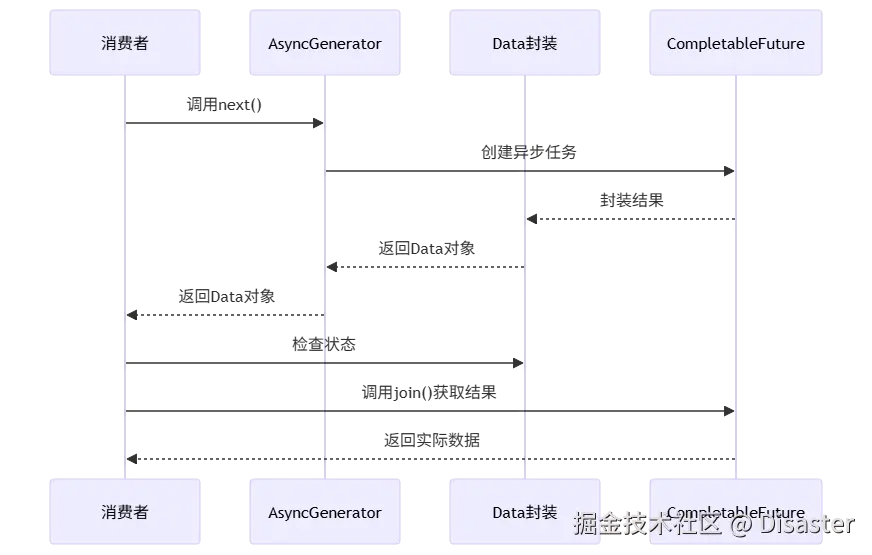
传统迭代器模式在 Spring AI Alibaba 项目的 old_version 包中通过 AsyncGenerator<E> 接口实现流式输出。其核心设计思路是将异步数据流抽象为一个可迭代的对象,消费者通过调用 next() 方法逐个获取数据元素。
该模式遵循以下原则:
Data<E> 类封装异步操作的各种状态(正常数据、完成状态、错误状态)| 维度 | 传统迭代器模式 | 响应式流模式 |
|---|---|---|
| 数据流向 | 拉取(Pull) | 推送(Push) |
| 控制权 | 消费者控制 | 生产者控制 |
| 并发模型 | CompletableFuture 链式调用 | 事件循环驱动 |
| 背压处理 | 手动实现 | 内置支持 |
| 错误处理 | 传统异常传播 | 响应式错误传播 |
传统迭代器模式更符合命令式编程思维,而响应式流模式则体现了声明式编程的理念。
传统迭代器模式主要依赖以下 Java 并发机制:
thenCompose、thenApply 等方法构建异步操作链// AsyncGenerator接口中的toCompletableFuture方法体现了链式调用思想
default CompletableFuture<Object> toCompletableFuture() {
final Data<E> next = next();
if (next.isDone()) {
return completedFuture(next.resultValue);
}
return next.data.thenCompose(v -> toCompletableFuture());
}
AsyncGenerator<E> 接口定义了异步生成器的核心契约:
public interface AsyncGenerator<E> extends Iterable<E> {
Data<E> next(); // 获取下一个异步数据元素
default CompletableFuture<Object> toCompletableFuture() { ... } // 转换为CompletableFuture
default Stream<E> stream() { ... } // 转换为Stream
default Iterator<E> iterator() { ... } // 获取迭代器
}
主要实现类包括:
Data<E> 类是异步数据元素的核心封装,设计上考虑了多种状态:
class Data<E> {
final CompletableFuture<E> data; // 异步数据
final Embed<E> embed; // 嵌入式生成器
final Object resultValue; // 结果值
public boolean isDone() { // 完成状态判断
return data == null && embed == null;
}
public boolean isError() { // 错误状态判断
return data != null && data.isCompletedExceptionally();
}
}
设计考量包括:
class WithResult<E> implements AsyncGenerator<E>, HasResultValue {
protected final AsyncGenerator<E> delegate;
private Object resultValue;
@Override
public final Data<E> next() {
final Data<E> result = delegate.next();
if (result.isDone()) {
resultValue = result.resultValue;
}
return result;
}
}
class WithEmbed<E> implements AsyncGenerator<E>, HasResultValue {
protected final Deque<Embed<E>> generatorsStack = new ArrayDeque<>(2);
private final Deque<Data<E>> returnValueStack = new ArrayDeque<>(2);
@Override
public Data<E> next() {
// 处理嵌套生成器栈
// 实现生成器组合逻辑
}
}
传统迭代器模式的背压处理主要通过以下方式实现:
next() 方法调用会阻塞局限性:
AsyncGenerator 继承 Iterable 接口WithResult 和 WithEmbed 类next() 方法定义算法框架Spring AI Alibaba Graph 模块的流式处理设计采用了响应式编程范式,基于 Project Reactor 框架实现。其核心理念是:
OverAllState 管理流式处理过程中的状态变化Flux 作为流式处理的核心组件具有以下优势:
在 ParallelNode 中,流合并策略采用以下设计:
Flux.zip 操作符合并多个 Flux 流OverAllState.updateState 方法维护状态一致性为保持向后兼容性,项目提供了 AsyncGenerator 与 Flux 的双向转换:
AsyncGenerator.fromFlux:将 Flux 转换为 AsyncGeneratorFlowGenerator.fromPublisher:将 Publisher 转换为 AsyncGenerator在 ParallelNode 中,多个 Flux 流的合并通过以下步骤实现:
// 检查是否有Flux类型的输出
boolean hasFlux = results.stream()
.flatMap(map -> map.values().stream())
.anyMatch(value -> value instanceof Flux);
if (hasFlux) {
// 收集所有Flux流
List<Flux<Object>> fluxList = new ArrayList<>();
// ... 处理非Flux输出 ...
// 合并Flux流
if (!fluxList.isEmpty()) {
Flux<Object> mergedFlux = Flux.zip(fluxList, new Function<Object[], Object>() {
@Override
public Object apply(Object[] objects) {
return null; // 简化的合并逻辑
}
});
mergedState.put("__merged_stream__", mergedFlux);
}
}
StreamingOutput 类封装了流式输出的数据:
public class StreamingOutput extends NodeOutput {
private final String chunk;
private final ChatResponse chatResponse;
public StreamingOutput(ChatResponse chatResponse, String node, OverAllState state) {
super(node, state);
this.chatResponse = chatResponse;
this.chunk = null;
}
public StreamingOutput(String chunk, String node, OverAllState state) {
super(node, state);
this.chunk = chunk;
this.chatResponse = null;
}
}
StreamingChatGenerator 构建流式聊天生成器:
public AsyncGenerator<? extends NodeOutput> buildInternal(Flux<ChatResponse> flux,
Function<ChatResponse, StreamingOutput> outputMapper) {
var result = new AtomicReference<ChatResponse>(null);
Consumer<ChatResponse> mergeMessage = (response) -> {
result.updateAndGet(lastResponse -> {
// 合并消息逻辑
// ...
});
};
var processedFlux = flux
.filter(response -> response.getResult() != null && response.getResult().getOutput() != null)
.doOnNext(mergeMessage)
.map(next -> new StreamingOutput(next.getResult().getOutput().getText(), startingNode, startingState));
return FlowGenerator.fromPublisher(FlowAdapters.toFlowPublisher(processedFlux),
() -> mapResult.apply(result.get()));
}
OverAllState 通过以下方式管理流式处理状态:
public static Map<String, Object> updateState(Map<String, Object> state, Map<String, Object> partialState,
Map<String, KeyStrategy> keyStrategies) {
Objects.requireNonNull(state, "state cannot be null");
if (partialState == null || partialState.isEmpty()) {
return state;
}
Map<String, Object> updatedPartialState = updatePartialStateFromSchema(state, partialState, keyStrategies);
return Stream.concat(state.entrySet().stream(), updatedPartialState.entrySet().stream())
.collect(toMapRemovingNulls(Map.Entry::getKey, Map.Entry::getValue, (currentValue, newValue) -> newValue));
}
AsyncGeneratorUtils 提供多生成器合并功能:
public static <T> AsyncGenerator<T> createMergedGenerator(List<AsyncGenerator<T>> generators,
Map<String, KeyStrategy> keyStrategyMap) {
return new AsyncGenerator<>() {
private final StampedLock lock = new StampedLock();
private AtomicInteger pollCounter = new AtomicInteger(0);
private Map<String, Object> mergedResult = new HashMap<>();
private final List<AsyncGenerator<T>> activeGenerators = new CopyOnWriteArrayList<>(generators);
@Override
public Data<T> next() {
// 轮询各个生成器,合并结果
// ...
}
};
}
在并行执行中,流式数据通过以下方式传递和聚合:
CompletableFuture.allOf 并行执行多个节点OverAllState.updateState 更新全局状态__merged_stream__ 键用于标识合并后的 Flux 流,在后续处理中可以识别和处理合并的流数据。
项目通过类型检查来处理不同数据类型:
instanceof Flux 检查,收集到 fluxList 中进行合并OverAllState.updateState 方法更新状态onBackpressureBuffer() 处理背压CompletableFuture 实现异步执行graph TD
A[StateGraph] --> B[ParallelNode]
B --> C[AsyncParallelNodeAction]
C --> D[Node Actions]
D --> E[Flux Streams]
E --> F[Flux Merge]
F --> G[__merged_stream__]
G --> H[OverAllState]
sequenceDiagram
participant Client
participant ParallelNode
participant NodeAction1
participant NodeAction2
participant FluxMerge
Client->>ParallelNode: Execute
ParallelNode->>NodeAction1: Execute Async
ParallelNode->>NodeAction2: Execute Async
NodeAction1-->>ParallelNode: Return Flux
NodeAction2-->>ParallelNode: Return Flux
ParallelNode->>FluxMerge: Merge Flux Streams
FluxMerge-->>ParallelNode: Merged Flux
ParallelNode->>Client: Return Result
next() 调用可能涉及线程阻塞响应式流模式在资源利用方面具有明显优势:
| 方面 | 传统迭代器模式 | 响应式流模式 |
|---|---|---|
| 扩展性 | 扩展新功能需要修改核心接口 | 通过操作符组合轻松扩展 |
| 维护性 | 手动资源管理增加维护复杂度 | 自动化管理降低维护成本 |
| 调试难度 | 相对简单 | 需要理解响应式编程概念 |
| 社区支持 | 有限 | Project Reactor 有强大生态 |

