



才到云(办公助手)
45.26MB · 2025-12-17

LLM 在处理实时性问题、数学计算等方面往往表现不佳。为了弥补这些不足,一个合格的 Agent 应当具备调用外部工具的能力。
本文将从最常见的 Web 搜索工具 入手,带你快速上手 LangGraph 的工具调用。这里我们使用 TavilySearch(app.tavily.com) 作为示例(新用户有 1000 次免费搜索额度)。
在上一篇构建聊天机器人的基础上,只需少量新增代码,即可完成工具调用。LangGraph 已经帮我们封装了大部分复杂逻辑。
from typing import Annotated
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from pydantic import SecretStr
from langchain_tavily import TavilySearch
from langgraph.prebuilt import ToolNode, tools_condition
# 此处定义你自己的模型
llm = ChatOpenAI(base_url="http://127.0.0.1:8000/v1", api_key=SecretStr("123123"), model="qwen3_32")
# 定义工具
tool = TavilySearch(tavily_api_key="你的tavily apikey", max_results=2)
tools = [tool]
# 工具绑定到模型
llm_with_tools = llm.bind_tools(tools)
# 定义图状态
classState(TypedDict):
messages: Annotated[list, add_messages] # 此处维护完整的消息历史
graph = StateGraph(State)
defchatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 使用LangGraph提供的工具节点
tool_node = ToolNode(tools=tools)
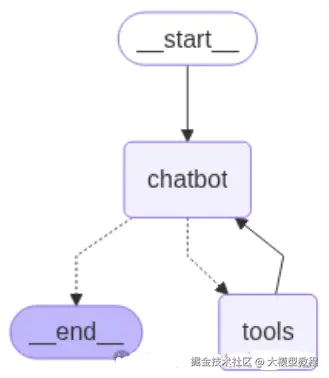
graph.add_node("chatbot", chatbot)
# 添加工具节点
graph.add_node("tools", tool_node)
# 添加工具 条件分支
graph.add_conditional_edges(
"chatbot",
tools_condition,
)
graph.add_edge("tools", "chatbot")
graph.add_edge(START, "chatbot")
app = graph.compile()
if __name__ == "__main__":
messages = []
whileTrue:
user_input = input(": ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Exiting...")
break
messages.append({"role": "user", "content": user_input})
response = app.invoke({"messages": messages})
messages = response["messages"]
print(f': {response["messages"][-1].content}')
LangChain为我们预构建了很多工具,常用的有
不过,在真实的企业开发场景中,更常见的做法是开发 自定义工具,以满足个性化需求。
下面演示一个基于 BaseTool 的自定义 Tavily 搜索工具,以及如何在 LangGraph 中接入。
import json
from langchain_core.messages import ToolMessage
from langgraph.constants import END
from typing import Annotated, Type, Optional
from langchain_core.callbacks import CallbackManagerForToolRun, AsyncCallbackManagerForToolRun
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from pydantic import SecretStr, BaseModel, Field
from langchain_core.tools import BaseTool
from tavily import TavilyClient, AsyncTavilyClient
# 自定义工具部分
classTavilySearchInput(BaseModel):
query: str = Field(description=("搜索查询"))
classTavilySearchTool(BaseTool):
name: str = "tavily_search"
description: str = """一个针对全面、准确和可信的结果进行了优化的搜索引擎。
当需要回答有关时事的问题时很有用。
输入应该是搜索查询。"""
args_schema: Type[BaseModel] = TavilySearchInput
# return_direct: bool = True
def_run(
self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None
) -> int:
client = TavilyClient()
search_r = client.search(query=query, max_results=2)
return search_r
asyncdef_arun(
self,
query: str,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> int:
client = AsyncTavilyClient()
search_r = await client.search(query=query, max_results=2)
return search_r
# 自定义的工具执行节点
classToolNode:
def__init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def__call__(self, inputs: dict):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
print(f'正在执行工具 {tool_call["name"]},参数 {tool_call["args"]}')
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
print(f'工具{tool_call["name"]}, 执行结果{json.dumps(tool_result, ensure_ascii=False)}')
outputs.append(
ToolMessage(
content=json.dumps(tool_result, ensure_ascii=False),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
# 此处定义你自己的模型
llm = ChatOpenAI(base_url="http://127.0.0.1:8000/v1", api_key=SecretStr("123123"), model="qwen3_32")
# 定义工具
tool = TavilySearchTool()
tools = [tool]
# 工具绑定到模型
llm_with_tools = llm.bind_tools(tools)
# 定义图状态
classState(TypedDict):
messages: Annotated[list, add_messages] # 此处维护完整的消息历史
graph = StateGraph(State)
defchatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 工具路由
defroute_tools(state: State):
ifisinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
ifhasattr(ai_message, "tool_calls") andlen(ai_message.tool_calls) > 0:
return"tools"
return END
# 使用LangGraph提供的工具节点
tool_node = ToolNode(tools=tools)
graph.add_node("chatbot", chatbot)
# 添加工具节点
graph.add_node("tools", tool_node)
# 添加工具条件边
graph.add_conditional_edges(
"chatbot",
route_tools,
{"tools": "tools", END: END},
)
graph.add_edge("tools", "chatbot")
graph.add_edge(START, "chatbot")
app = graph.compile()
if __name__ == "__main__":
messages = []
whileTrue:
user_input = input(": ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Exiting...")
break
messages.append({"role": "user", "content": user_input})
response = app.invoke({"messages": messages})
messages = response["messages"]
print(f': {response["messages"][-1].content}')
除了继承 BaseTool 的方式,LangChain 还支持通过 @tool 装饰器 来快速定义工具。相比之下,这种方法更简洁,适合轻量级工具
from typing import Annotated
from tavily import TavilyClient
from langchain_core.tools import tool
@tool("tavily_search")
def tavily_search_tool(query: Annotated[str, "搜索查询"]):
"""一个针对全面、准确和可信的结果进行了优化的搜索引擎。当需要回答有关时事的问题时很有用。输入应该是搜索查询。"""
client = TavilyClient()
search_r = client.search(query=query)
return search_r
tavily_search_tool.invoke({"query": "北京2025年8月27日天气怎么样?"})
除了自定义工具之外,LangGraph 还支持 MCP(Model Context Protocol),这使得工具的复用和扩展性更强。
要在 LangGraph 中使用 MCP,需要额外安装依赖包:
pip install langchain-mcp-adapters
依旧是以Tavily搜索为例
import json
from mcp.server.fastmcp import FastMCP
from tavily import TavilyClient
mcp = FastMCP("search")
@mcp.tool()
async def tavily_search(query: str) -> str:
"""一个针对全面、准确和可信的结果进行了优化的搜索引擎。当需要回答有关时事的问题时很有用。输入应该是搜索查询。"""
client = TavilyClient()
search_r = client.search(query=query, max_results=2)
return json.dumps(search_r, ensure_ascii=False)
if __name__ == "__main__":
mcp.run(transport="streamable-http")
import asyncio
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import ToolNode, tools_condition
from typing import Annotated
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from pydantic import SecretStr
# 此处定义你自己的模型
llm = ChatOpenAI(base_url="http://127.0.0.1:8000/v1", api_key=SecretStr("123123"), model="qwen3_32")
# 配置MCP Server
client = MultiServerMCPClient(
{
"search": {
"url": "http://localhost:8000/mcp/",
"transport": "streamable_http",
}
}
)
classState(TypedDict):
messages: Annotated[list, add_messages] # 此处维护完整的消息历史
graph = StateGraph(State)
asyncdefmain():
tools = await client.get_tools()
# 工具绑定到模型
llm_with_tools = llm.bind_tools(tools)
defchatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
graph = StateGraph(State)
graph.add_node(chatbot)
graph.add_node(ToolNode(tools))
graph.add_edge(START, "chatbot")
graph.add_conditional_edges(
"chatbot",
tools_condition,
)
graph.add_edge("tools", "chatbot")
app = graph.compile()
messages = []
whileTrue:
user_input = input(": ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Exiting...")
break
messages.append({"role": "user", "content": user_input})
response = await app.ainvoke({"messages": messages})
messages = response["messages"]
print(f': {response["messages"][-1].content}')
asyncio.run(main())
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。

