

不一样战机游戏
116.03 MB · 2025-11-18

GraalVM 基于 Java HotSpot 虚拟机,因此任何在 Java HotSpot 虚拟机上运行的应用程序也会在 GraalVM 上运行。
GraalVM 包含一个用 Java 编写的先进编译器,称为 Graal 编译器。在运行时,就像任何其他 Java 虚拟机(JVM)一样,GraalVM 加载应用程序并分析其代码以检测性能瓶颈或热点。GraalVM 将性能关键代码传递给 Graal 即时(JIT)编译器,后者将其编译为机器码然后返回。
Graal 编译器可以通过其独特的代码分析和优化方法提高用 Java、Scala、Kotlin 或其他 JVM 语言编写的应用程序的效率和速度。例如,由于其能够消除昂贵的对象分配,它确保了高度抽象应用程序的性能优势。有关平台无关编译器优化的更多信息,请参阅 GraalVM 社区版 GitHub 仓库中的 CEOptimization enum。
GraalVM 还包括 Truffle 语言实现框架——一个用 Java 编写的库——用于构建编程语言的解释器,然后在 GraalVM 上运行。这些"Graal 语言"因此可以从 Graal 编译器的优化可能性中受益。这种编译的流水线是:
有关与其他编程语言互操作性的更多信息,请参阅 多语言编程 和 嵌入语言 指南。
除了 Truffle 框架,GraalVM 还将其编译器纳入先进的预先(AOT)编译技术——Native Image——它将 Java 和基于 JVM 的代码转换为本机平台可执行文件。这些本机可执行文件几乎可以瞬时启动,体积更小,消耗的资源比其 JVM 对应物更少,使它们非常适合云部署和微服务。有关 AOT 编译的更多信息,请参阅 Native Image。
Graal 编译器是一个用 Java 编写的动态编译器,它将字节码转换为机器码。Graal 即时(JIT)编译器与 Java HotSpot 虚拟机和 GraalVM 集成。有关更多信息,请参阅 Java 虚拟机指南 和 GraalVM 作为虚拟机 部分。(Graal JIT 编译器的开源代码可在 GitHub 上获得。)
Graal JIT 编译器通过独特的代码分析和优化方法为在 Java 虚拟机(JVM)上运行的应用程序提供优化性能。它包括多种优化算法(称为"阶段"),如激进内联、多态内联等。
Graal 编译器可以为高度抽象的程序带来性能优势。例如,它包括一个部分逃逸分析优化,可以消除某些对象的昂贵分配。有关更多信息,请参阅 GraalVM GitHub 仓库中 CEOptimization enum 中的 PartialEscapeAnalysis 值。该优化确定新对象何时在编译单元外部可访问,并且仅在"逃逸"编译单元的路径上分配它(例如,如果对象作为参数传递、存储在字段中或从方法返回)。这种方法可以通过减少堆分配的数量大大提高应用程序的性能。使用更现代 Java 特性(如 Stream 或 Lambda)的代码将看到更大的性能改进,因为这种类型的代码涉及大量这样的非逃逸或部分逃逸对象。受 I/O 或编译器无法消除的内存分配等特性约束的代码将看到较少的改进。有关性能调优的更多信息,请参阅 Graal JIT 编译器配置。
为了在与主机基于 JVM 的语言相同的运行时中运行客户编程语言(即 JavaScript、Python 和 Ruby),编译器使用源语言和要生成的机器码之间的语言无关中间图表示。(有关语言互操作性的更多信息,请参阅 互操作性。)
图可以以相同的方式表示不同语言的类似语句,如"if"语句或循环,这使得在同一应用程序中混合语言成为可能。然后 Graal 编译器可以在此图上执行语言无关优化并生成机器码。
如果编译器抛出未捕获的异常,编译通常会被丢弃并继续执行。Graal 编译器可以改为产生诊断数据(如即时表示图),可以与错误报告一起提交。这通过 -Djdk.graal.CompilationFailureAction=Diagnose 选项启用。诊断输出的默认位置在进程当前工作目录下的 graal_dumps/ 目录中,但可以通过 -Djdk.graal.DumpPath 选项更改。在 JVM 关闭期间,包含诊断数据的归档位置将打印到控制台。
此外,可以为 Graal 编译器执行的任何编译生成诊断数据,使用 -Djdk.graal.Dump 选项。这将为编译器编译的每个方法产生诊断数据。
要细化产生诊断数据的方法集,使用 -Djdk.graal.MethodFilter=<class>.<method> 选项。例如,-Djdk.graal.MethodFilter=java.lang.String.*,HashMap.get 将仅为 java.lang.String 类中的方法以及非限定名称为 HashMap 的类中名为 get 的方法产生诊断数据。
配置 Graal JIT 编译器的选项分为三类:通用、性能调优和诊断。
这些是用于设置/获取配置详细信息的通用选项。
-XX:-UseJVMCICompiler:禁用使用 Graal 编译器作为顶层 JIT 编译器。当您想要比较 Graal JIT 编译器与本机 JIT 编译器的性能时,这很有用。
-Djdk.graal.CompilerConfiguration=<name>:选择要使用的 Graal JIT 编译器配置。如果省略,将选择具有最高自动选择优先级的编译器配置。要查看可用配置,请为此选项提供值 help。
编译器配置的名称及其语义是:
enterprise:生成高度优化的代码,可能在编译时间上有所权衡(仅在 Oracle GraalVM 中可用)。community:以更快的编译时间生成合理优化的代码。economy:以尽可能快的速度编译,生成代码的吞吐量较低。-Djdk.graal.ShowConfiguration=<level>:打印关于所选 Graal JIT 编译器配置的信息。此选项仅在编译器初始化时产生输出。默认情况下,Graal JIT 编译器在第一次顶层编译时初始化。因此,使用此选项的方法如下:java -XX:+EagerJVMCI -Djdk.graal.ShowConfiguration=info -version。
接受的参数是:
none:不显示信息。info:打印一行输出,描述正在使用的编译器配置以及从何处加载。verbose:打印详细的编译器配置信息。-Djdk.graal.SpectrePHTBarriers=<strategy>:选择缓解推测边界检查绕过(也称为 Spectre-PHT 或 Spectre V1)的策略。
接受的参数是:
None:在 JIT 编译代码中不使用缓解措施。(默认。)AllTargets:使用推测执行屏障指令在所有分支目标上停止推测执行。此选项等同于将 SpeculativeExecutionBarriers 设置为 true。(这会对性能产生很大影响。)GuardTargets:使用屏障指令对与 Java 内存安全相关的分支目标进行检测。仅保护那些保持 Java 内存安全的分支。(此选项的性能影响比 AllTargets 低。)NonDeoptGuardTargets:与 GuardTargets 相同,但不保护被反优化的分支,因为它们无法重复执行,因此在攻击中成功利用的可能性较小。请注意,除 None 外的所有模式还使用屏障指令对包含 UNSAFE 内存访问的分支目标块进行检测。
-Djdk.graal.Vectorization={ true | false }:禁用自动向量化优化(仅在 Oracle GraalVM 中可用)。(默认:true。)-Djdk.graal.OptDuplication={ true | false }:禁用路径复制优化(仅在 Oracle GraalVM 中可用)。(默认:true。)-Djdk.graal.TuneInlinerExploration=<value>:调优以获得更好的峰值性能或更快的预热。它自动调整控制内联期间花费的努力的值。选项的值是一个限制在 -1 和 1 之间(包括)的浮点数。低于 0 的任何值都会减少内联努力,高于 0 的任何值都会增加内联努力。一般来说,更多的内联努力可以提高峰值性能,而较少的内联努力可以改善预热(尽管峰值较低)。请注意,此选项仅是启发式的,最佳值可能因应用程序而异(仅在 Oracle GraalVM 中可用)。-Djdk.graal.CompilationFailureAction=<action>:指定编译因抛出异常而失败时要采取的操作。
接受的操作:
Silent:不向控制台打印任何内容。(默认。)
Print:向控制台打印堆栈跟踪。
Diagnose:使用启用的额外诊断重试编译。在 JVM 退出时,收集的诊断保存到 ZIP 文件中,可以与错误报告一起提交。控制台上会打印一条消息,描述诊断文件保存的位置:
Graal diagnostic output saved in /Users/graal/graal_dumps/1549459528316/graal_diagnostics_22774.zip
ExitVM:与 Diagnose 相同,但 JVM 进程在重试后退出。
对于除 ExitVM 外的所有值,JVM 都会继续。
-Djdk.graal.CompilationBailoutAsFailure={ true | false }:编译器可能由于方法中的某些属性或代码形状(例如,异常使用 jsr 和 ret 字节码)而无法完成方法的编译。在这种情况下,编译退出。如果您想要了解此类退出,此选项使 Graal JIT 编译器将退出视为失败,因此受 -Djdk.graal.CompilationFailureAction 选项指定的操作约束。(默认:false。)
上述 Graal JIT 编译器属性可与其他一些 GraalVM 启动器(如 node 和 js)一起使用。指定属性的前缀略有不同。例如:
java -XX:+EagerJVMCI -Djdk.graal.ShowConfiguration=info -version
变成:
js --vm.Djdk.graal.ShowConfiguration=info -version
测量性能时首先要确认的是 Java 虚拟机(JVM)正在使用 Graal JIT 编译器。
GraalVM 默认配置为使用 Graal JIT 编译器作为顶层编译器。
要在 Java HotSpot 虚拟机 中启用 Graal JIT 编译器,请使用 -XX:+UseGraalJIT 选项。(-XX:+UseGraalJIT 选项必须与解锁此实验性集成的 -XX:+UnlockExperimentalVMOptions 选项一起使用。)
以下示例使用启用的 Graal JIT 编译器运行 Java 应用程序 com.example.myapp:
java -XX:+UnlockExperimentalVMOptions -XX:+UseGraalJIT com.example.myapp
您可以通过在命令行中添加 -Djdk.graal.ShowConfiguration=info 选项来确认您正在使用 Graal JIT 编译器。当编译器初始化时,它会产生类似于下面的一行输出:
Using "Graal Enterprise compiler with Truffle extensions" loaded from a PGO optimized Native Image shared library
优化基于 JVM 的应用程序本身就是一门科学。编译甚至可能不是性能不佳的因素,因为问题可能出现在 JVM 的任何其他部分(I/O、垃圾收集、线程等),或者在编写不当的应用程序或第三方库代码中。因此,值得使用 JDK Mission Control 工具链来诊断您的应用程序行为。
您还可以通过在命令行中添加 -XX:-UseJVMCICompiler 来比较与 JVM 中本机顶层编译器的性能。
如果您在使用 Graal JIT 编译器时观察到显著的性能退化,请在 GitHub 上开启问题。附上 Java Flight Recorder 日志和重现问题的说明——这使调查更容易,从而增加修复的机会。更好的是,如果您可以提交一个代表应用程序最热部分(由分析器识别)的 JMH 基准测试。这使我们能够快速精确定位缺失的优化机会或提供关于如何重构代码以避免或减少性能瓶颈的建议。
如果您发现安全漏洞,请不要通过 GitHub Issues 或公共邮件列表报告,而是通过 报告漏洞指南 中概述的流程报告。
编译器用 Java 编写的一个优势是编译期间的 Java 异常不是致命的 JVM 错误。相反,每个编译都有一个异常处理程序,该处理程序根据 graal.CompilationFailureAction 属性采取操作。
默认值是 Silent。如果您指定 Diagnose,失败的编译将使用额外的诊断重试。在这种情况下,就在 JVM 退出之前,重试编译期间捕获的所有诊断输出都会写入 ZIP 文件,其位置会在控制台上打印,例如:
Graal diagnostic output saved in /Users/demo/graal-dumps/1499768882600/graal_diagnostics_64565.zip
然后您可以将 ZIP 文件附加到 GitHub 上的问题。
除了 Silent 和 Diagnose 外,graal.CompilationFailureAction 还有以下可用值:
Print:向控制台打印消息和堆栈跟踪,但不执行重新编译。ExitVM:与 Diagnose 相同,但 JVM 进程在重新编译后退出。您可能遇到的编译器的另一种错误类型是生成不正确的机器码。此错误可能导致 JVM 崩溃,在 JVM 进程的当前工作目录中生成以 hs_err_pid 开头的文件。在大多数情况下,文件中有一个部分显示崩溃时的堆栈,包括堆栈中每个帧的代码类型,如以下示例:
Stack: [0x00007000020b1000,0x00007000021b1000], sp=0x00007000021af7a0, free space=1017k
Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code)
J 761 JVMCI jdk.graal.compiler.core.gen.NodeLIRBuilder.matchComplexExpressions(Ljava/util/List;)V (299 bytes) @ 0x0000000108a2fc01 [0x0000000108a2fac0+0x141] (null)
j jdk.graal.compiler.core.gen.NodeLIRBuilder.doBlock(Ljdk.graal.compiler/nodes/cfg/Block;Ljdk.graal.compiler/nodes/StructuredGraph;Ljdk.graal.compiler/core/common/cfg/BlockMap;)V+211
j jdk.graal.compiler.core.LIRGenerationPhase.emitBlock(Ljdk.graal.compiler/nodes/spi/NodeLIRBuilderTool;Ljdk.graal.compiler/lir/gen/LIRGenerationResult;Ljdk.graal.compiler/nodes/cfg/Block;Ljdk.graal.compiler/nodes/StructuredGraph;Ljdk.graal.compiler/core/common/cfg/BlockMap;)V+65
此示例显示顶层帧由 JVMCI 编译器编译(J),即 Graal JIT 编译器。崩溃发生在为以下内容生成的机器码中的偏移量 0x141 处:
jdk.graal.compiler.core.gen.NodeLIRBuilder.matchComplexExpressions(Ljava/util/List;)V
堆栈中的接下来两个帧是解释的(j)。崩溃的位置通常也在文件顶部附近指示,类似于:
# Problematic frame:
# J 761 JVMCI jdk.graal.compiler.core.gen.NodeLIRBuilder.matchComplexExpressions(Ljava/util/List;)V (299 bytes) @ 0x0000000108a2fc01 [0x0000000108a2fac0+0x141] (null)
在此示例中,NodeLIRBuilder.matchComplexExpressions 的 Graal JIT 编译器生成的代码中可能存在错误。
当在 GitHub 上为此类崩溃提交问题时,您应该首先尝试为有问题方法的编译启用额外诊断来重现崩溃。在此示例中,您将在命令行中添加以下选项:
-Djdk.graal.MethodFilter=NodeLIRBuilder.matchComplexExpressions, -Djdk.graal.Dump=:2
这些选项在编译器调试文档中有更详细的描述。简而言之,这些选项告诉 Graal JIT 编译器在编译简单名称为 NodeLIRBuilder 的类中名为 matchComplexExpressions 的任何方法时,以详细级别 2 捕获其状态快照。MethodFilter 选项的完整格式在 MethodFilterHelp.txt 中描述。
通常,崩溃位置不是直接存在于崩溃日志中提到的有问题方法中,而是来自内联方法。
在这种情况下,仅过滤有问题的方法可能无法捕获导致崩溃的错误编译。
为了提高捕获错误编译的可能性,请扩大 MethodFilter 值。为了指导这一点,在尝试重现崩溃时添加 -Djdk.graal.PrintCompilation=true 选项,这样您可以看到崩溃前编译了什么。
以下显示控制台的示例输出:
HotSpotCompilation-1218 Ljdk.graal.compiler/core/amd64/AMD64NodeLIRBuilder; peephole (Ljdk.graal.compiler/nodes/ValueNode;)Z | 87ms 428B 447B 1834kB
HotSpotCompilation-1212 Ljdk.graal.compiler/lir/LIRInstructionClass; forEachState (Ljdk.graal.compiler/lir/LIRInstruction;Ljdk.graal.compiler/lir/InstructionValueProcedure;)V | 359ms 92B 309B 6609kB
HotSpotCompilation-1221 Ljdk.graal.compiler/hotspot/amd64/AMD64HotSpotLIRGenerator; getResult ()Ljdk.graal.compiler/hotspot/HotSpotLIRGenerationResult; | 54ms 18B 142B 1025kB
#
# A fatal error has been detected by the Java Runtime Environment:
#
# SIGSEGV (0xb) at pc=0x000000010a6cafb1, pid=89745, tid=0x0000000000004b03
#
# JRE version: OpenJDK Runtime Environment (8.0_121-b13) (build 1.8.0_121-graalvm-olabs-b13)
# Java VM: OpenJDK 64-Bit GraalVM (25.71-b01-internal-jvmci-0.30 mixed mode bsd-amd64 compressed oops)
# Problematic frame:
# J 1221 JVMCI jdk.graal.compiler.hotspot.amd64.AMD64HotSpotLIRGenerator.getResult()Ljdk.graal.compiler/hotspot/HotSpotLIRGenerationResult; (18 bytes) @ 0x000000010a6cafb1 [0x000000010a6caf60+0x51] (null)
#
# Failed to write core dump. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again
这里,崩溃发生在与第一次崩溃不同的方法中。因此,我们将过滤器参数扩展为 -Djdk.graal.MethodFilter=NodeLIRBuilder.matchComplexExpressions,AMD64HotSpotLIRGenerator.getResult 并再次运行。
当 JVM 以这种方式崩溃时,它不运行归档 Graal 编译器诊断输出或删除写入它的目录的关闭代码。这必须在崩溃后手动完成。
默认情况下,目录是 $PWD/graal-dumps/timestamp(例如,./graal-dumps/1499938817387)。但是,您可以使用 -Djdk.graal.DumpPath=<path> 选项指定目录。
当编译器首次使用此目录时,会向控制台打印一条消息,例如:
Dumping debug output in /Users/demo/graal-dumps/1499768882600
此目录应包含与崩溃方法相关的内容,例如:
ls -l /Users/demo/graal-dumps/1499768882600
-rw-r--r-- 1 demo staff 144384 Jul 13 11:46 HotSpotCompilation-1162[AMD64HotSpotLIRGenerator.getResult()].bgv
-rw-r--r-- 1 demo staff 96925 Jul 13 11:46 HotSpotCompilation-1162[AMD64HotSpotLIRGenerator.getResult()].cfg
-rw-r--r-- 1 demo staff 12600725 Jul 13 11:46 HotSpotCompilation-791[NodeLIRBuilder.matchComplexExpressions(List)].bgv
-rw-r--r-- 1 demo staff 1727409 Jul 13 11:46 HotSpotCompilation-791[NodeLIRBuilder.matchComplexExpressions(List)].cfg
您应该将此目录的 ZIP 文件附加到 GitHub 上的问题。
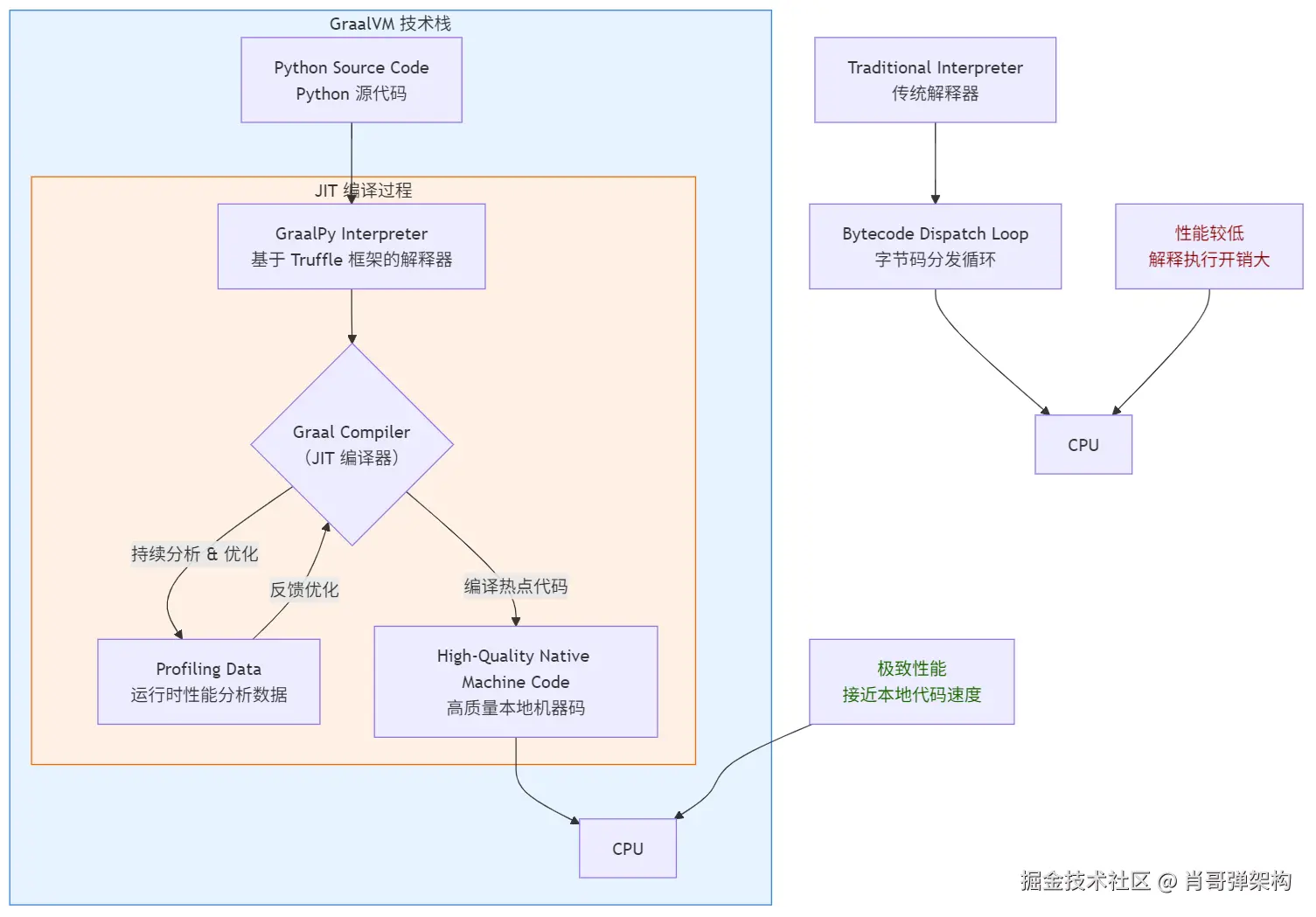
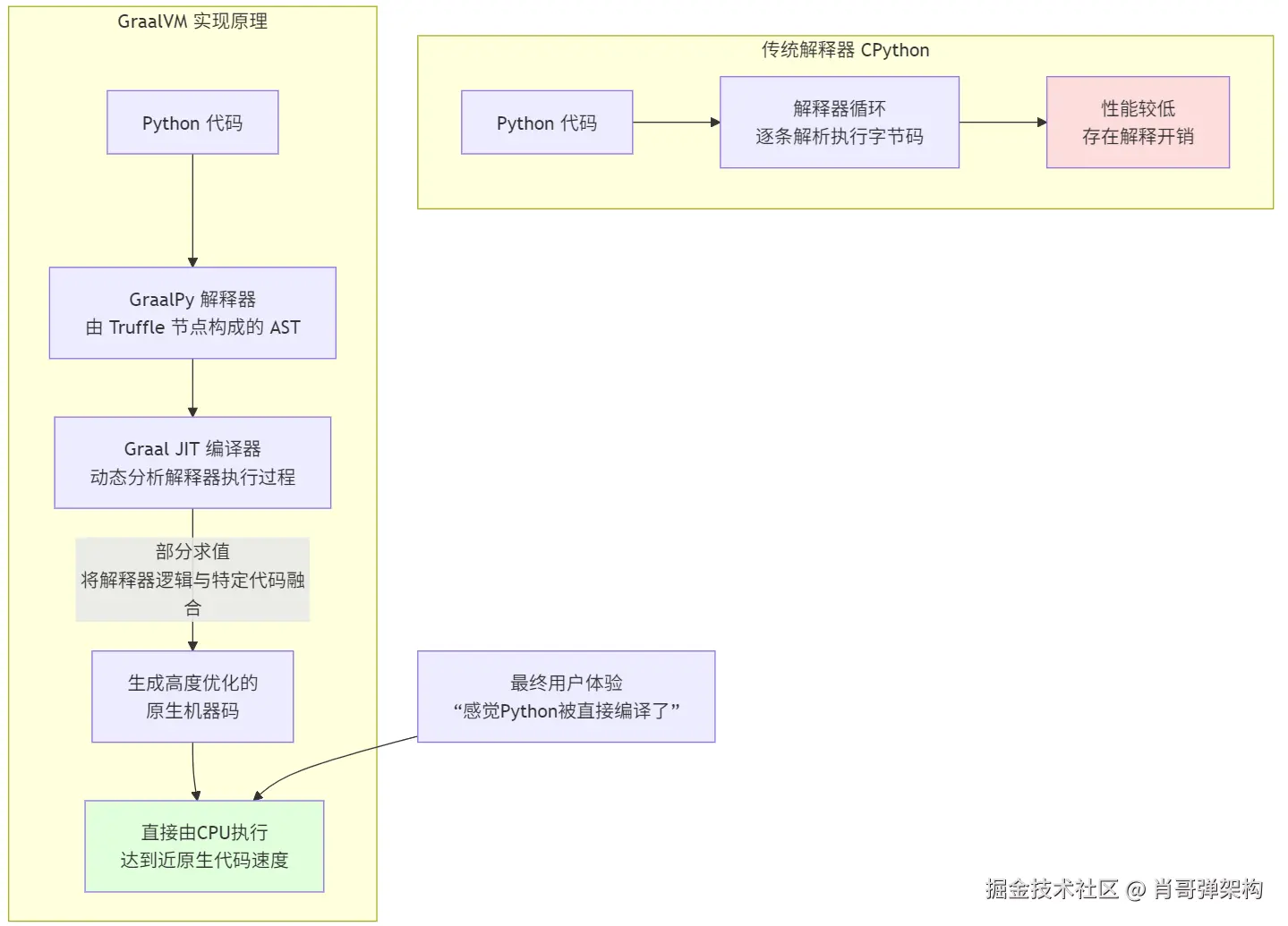
“Graal JIT 将 Python 编译为原生代码” 这个说法并不完全准确。
更准确的描述是:
GraalVM 利用 Graal JIT 编译器,将基于 Truffle 框架编写的 GraalPy Python 解释器本身(以及它正在执行的 Python 代码)动态地编译并优化为高质量的原生机器码。
原理极其精妙。下面我们通过一个流程图和分步解释来彻底搞懂它是如何做到的。
GraalPy 并不是一个传统的 Python 解释器。它是一个用 Java 编写的、实现了 Python 语言语义的库,这个库是构建在 Truffle 语言实现框架 之上的。
if, while, 函数调用、算术运算等)定义为一个一个的 “节点”(Nodes) 组成的抽象语法树(AST)。print(1 + 2) 时,它会先解析代码,生成一个由多个 Truffle 节点组成的 AST。例如,可能有一个 PrintNode,一个 AddNode,两个 LiteralNode。AddNode 的 execute 方法会被调用,它从子节点获取值 1 和 2,执行加法,返回 3。AddNode 会记录它通常处理的是什么类型的数字(是整数还是浮点数?)。execute 方法会记录它经常被哪些具体的参数类型调用。AddNode)变成了“热点”,它就会启动它的魔法:
AddNode 的分析数据,发现它总是在处理两个整数。于是,它会生成一份高度特化的机器码,这份机器码不再是通用的“加法操作”**,而是一份 “整数加法操作” 的快速路径代码。它移除了所有类型检查、分支预测失败的可能,因为编译器“知道”这里总是整数。AddNode.execute 的逻辑)和当前正在执行的 Python 代码 (即 1 + 2)进行部分求值**。
AddNode)和它要解释的数据(1 和 2)一起编译。最终生成的机器码,就像是手写了一个专门计算 1 + 2 的本地函数一样高效。它完全绕过了解释器的开销。1 + 2 这个代码路径时,CPU 不再需要一步步地走解释器的逻辑,而是直接执行那份为其量身定制的、缓存中的原生机器码。所以,结论是:
GraalPy 并没有直接将 Python 代码编译成原生代码。而是通过 Truffle 框架和 Graal JIT 编译器的协同工作,将解释器对特定Python代码的执行逻辑,动态地编译并优化成了原生机器码。 它通过部分求值技术,抹平了“解释器”和“被解释的程序”之间的界限,最终让Python代码以近乎原生代码的速度运行。
核心原理:不是编译Python代码,而是编译“解释器”
GraalPy(GraalVM 的 Python 实现)的核心魔法在于一项叫做 “部分求值” 的技术。简单来说,它的工作流程如下图所示:
GraalVM 并没有一个直接将 .py 文件变成 .exe 的编译器。它的秘诀是:
x + 1)解析成一个由许多小节点组成的抽象语法树。每个节点负责一个小操作(比如加法、变量读取等)。x + 1)被反复执行(成为“热点”)时,它会启动优化。
x 当前是整数 5)一起进行编译优化。5 + 1 = 6 这样的原生机器码。它完全绕过了解释器的开销,就像这段代码是原本就用 C 写好的一样。x + 1,CPU 都会直接运行这份缓存中的、为它量身定制的原生机器码,从而实现近乎原生代码的执行速度。小米端到端辅助驾驶“Xiaomi HAD 增强版”广州车展发布,11 月 21 日见
4499 元华硕 Pro WS B850M-ACE SE 工作站主板上市:10+2.5G 双网口,支持锐龙及 EPYC Embedded 4005 系列 CPU

