
口袋妖怪ns腾讯手游
49.97 MB · 2025-11-13

在我们的实际开发中,序列化和反序列化几乎无处不在,今天我们就来聊聊这个知识点。
把对象转换为字节序列的过程称为对象的序列化。
序列化是将对象的状态转换为可存储或可传输格式的过程。对象在内存中一般以特定的数据结构(指针、引用、哈希表、链表等)存在,直接传输内存数据是不可靠的(不同机器架构不同、数据对齐不同、指针无意义等问题)。
通过对象的序列化,我们可以把对象的字节序列永久的保存到硬盘上,通常是存放在一个文件中;我们还可以在网络上传输对象的字节序列;简单来说,序列化就是让数据"离开内存,去旅行"。
在一些应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如,我们可以将应用中的数据持久化存储到文件中,下次程序启动时直接将数据恢复到内存中,这样就不需要重新初始化数据了。这在数据较大或初始化过程复杂时尤为方便。
在分布式系统中,远程方法调用(RMI)常常需要将对象通过网络传输到另一个JVM中。当a服务和b服务进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传输。发送方需要把这个java对象转换为字节序列,才能在网络上传输,接收方则需要把字节序列再恢复为java对象。
把字节序列恢复为对象的过程称为对象的反序列化。
把收到的字节流或文本格式数据,还原成内存中的对象或数据结构,供程序继续操作。比如从磁盘中读取一段json数据,把redis里缓存的对象取出来恢复成原始对象。
我们来看一下常见的场景:
| 应用场景 | 为什么需要序列化 |
|---|---|
| 网络通信 | TCP/UDP传输的数据必须是字节流,无法直接传对象 |
| 本地持久化 | 把程序状态保存到磁盘,下次能恢复 |
| 跨平台数据交换 | 不同系统、不同语言之间必须用标准格式 |
| 缓存系统 | Redis、Memcached存的是序列化后的对象 |
| 消息队列 | Kafka、RabbitMQ里的消息通常也是经过序列化的 |
| RPC调用 | gRPC、Thrift调用远端服务需要将请求和响应序列化 |
| 格式 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|
| JSON | 人类可读、跨平台、广泛支持 | 体积大、解析慢 | 前后端接口、配置文件 |
| XML | 结构复杂、可扩展性好 | 体积更大、解析更慢 | SOAP服务、老系统 |
| Protobuf | 体积小、速度快、强类型定义 | 不易读、需要提前定义proto文件 | gRPC、分布式系统内部通信 |
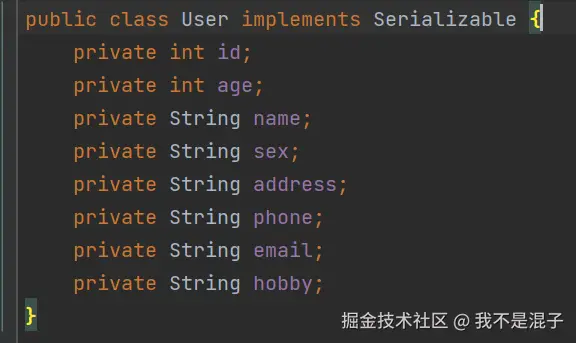
在java中,序列化和反序列化是通过实现Serializable接口来完成的。
对于一个需要序列化的java类,必须实现Serializable接口:
这个接口本身没有任何方法,它只是一个标记接口,用于告诉Java虚拟机这个类可以被序列化。
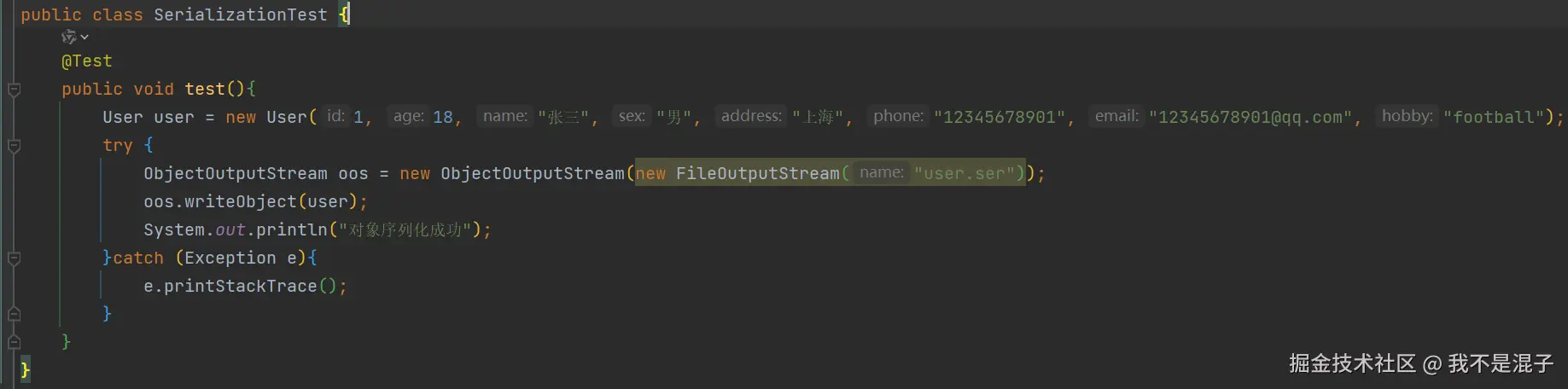
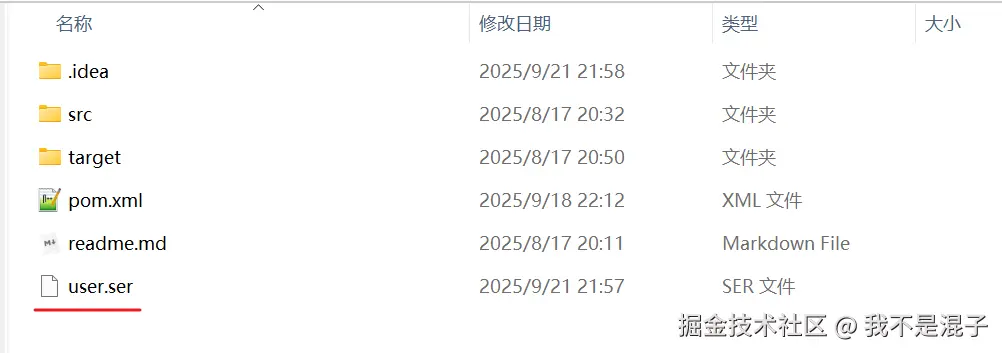
在这个例子中,我们将 user对象序列化并存储在本地文件 user.ser 中。
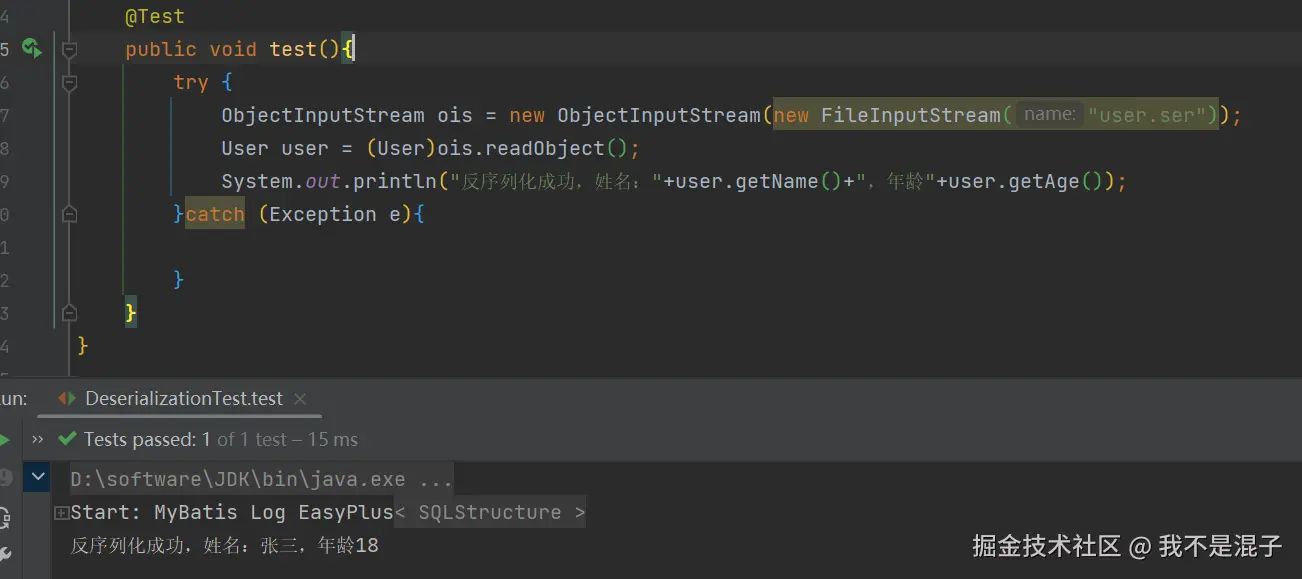
将序列化的文件恢复回对象(反序列化)时,可以使用 ObjectInputStream 类:
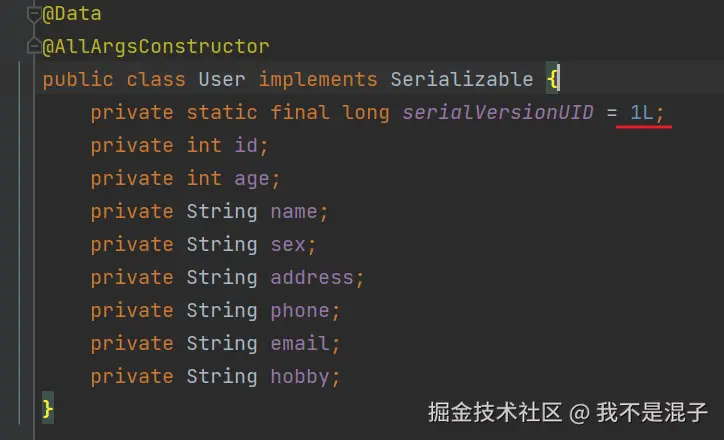
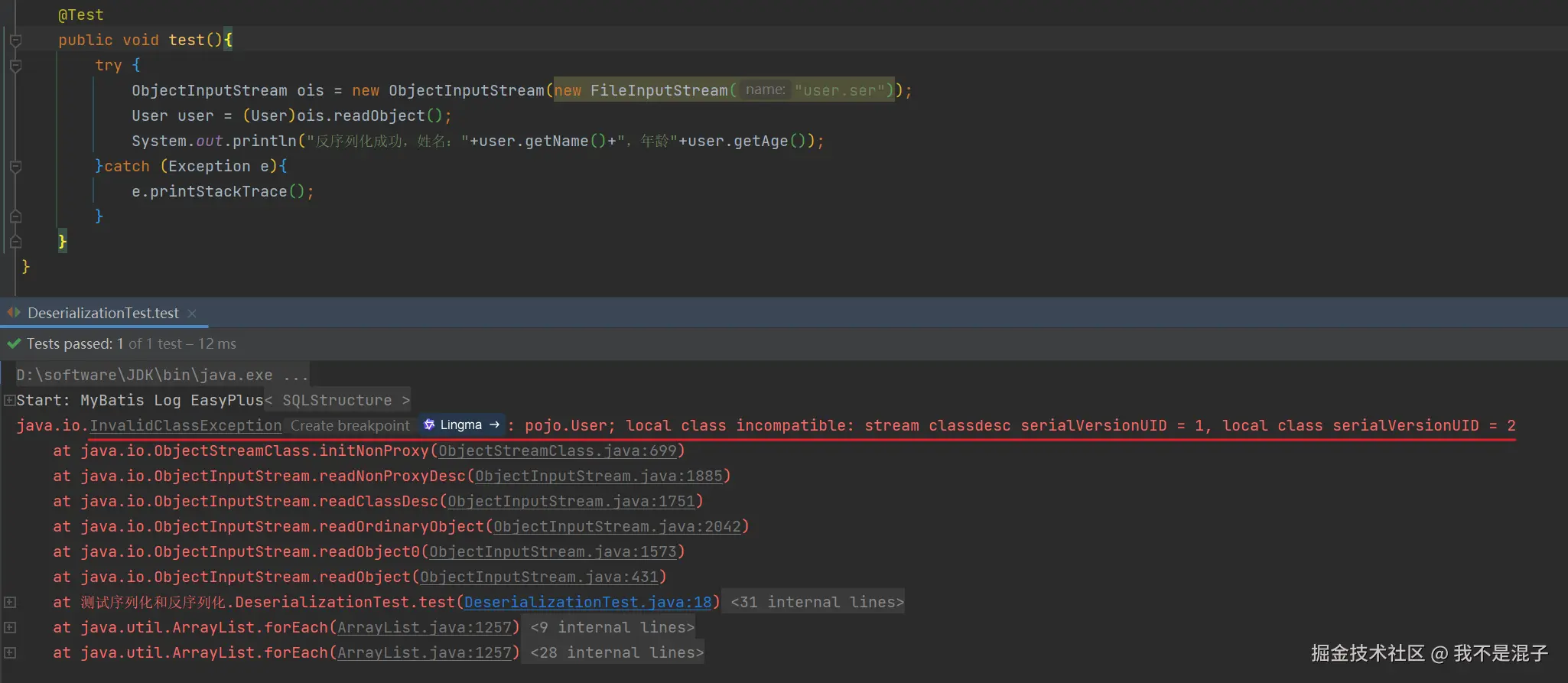
在反序列化过程中,有时会遇到反序列化失败的情况,常见的原因之一是:serialVersionUID 不一致,每个序列化的类都会包含一个 serialVersionUID,它是唯一标识类版本的“身份证”。在反序列化时,Java虚拟机会检查对象的 serialVersionUID 与本地类的 serialVersionUID 是否匹配。如果不一致,Java会抛出 InvalidClassException 异常,表示反序列化失败。实验代码:
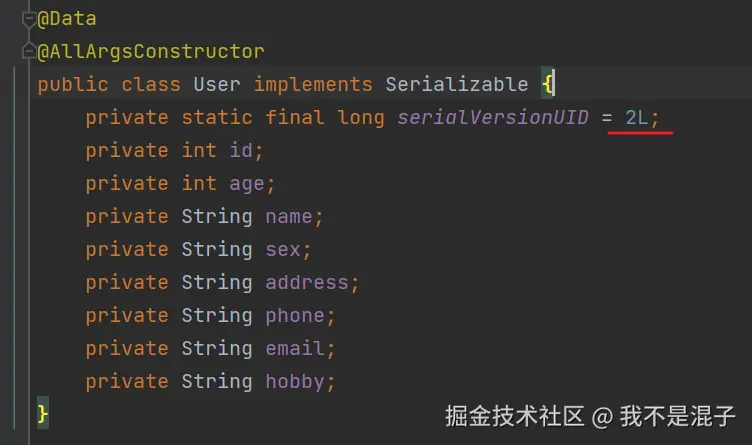
原本是1的,但是我在序列化之后,将1改成了2:
然后去执行反序列化,会抛出异常:
所以,为了保证反序列化的顺利进行,建议在类定义时显式定义 serialVersionUID。
显式声明 serialVersionUID:避免在类结构改变时导致反序列化失败。
避免对敏感字段进行序列化:对于一些敏感信息(如密码),可以使用 transient 关键字修饰,防止这些字段被序列化。
49.97 MB · 2025-11-13
289.01MB · 2025-11-13
60.87MB · 2025-11-13

