

缘之空安卓版汉化
1435MB · 2025-12-24

本系列前四篇文章:
上一篇文章中,我们介绍了 LangGraph 生态中的核心开发工具——LangSmith、LangGraph Studio 和 LangGraph CLI 的基本使用方法。本期我们将通过一个实战项目,带大家使用 LangGraph 搭建一个使用自然语言操作数据库查询和分析的智能数据分析助手,并将其接入 Agent Chat UI 界面。通过这个完整案例,你将进一步掌握 LangGraph 的全流程开发能力,轻松应对日常工作中编写 SQL 语句的难题,提升数据处理效率。
本系列分享是笔者结合自己学习工作中使用LangChain&LangGraph经验倾心编写的,力求帮助大家体系化快速掌握LangChain&LangGraph AI Agent智能体开发的技能!笔者的LangChain系列教程暂时更完,后面也会实时补充工作实践中的额外知识点,建议大家在学习LangGraph分享前先学习LangChain的基本使用技巧。大家感兴趣可以关注笔者掘金账号和系列专栏。更可关注笔者同名微信公众号: 大模型真好玩, 每期分享涉及的代码均可在公众号私信: LangChain智能体开发获得。
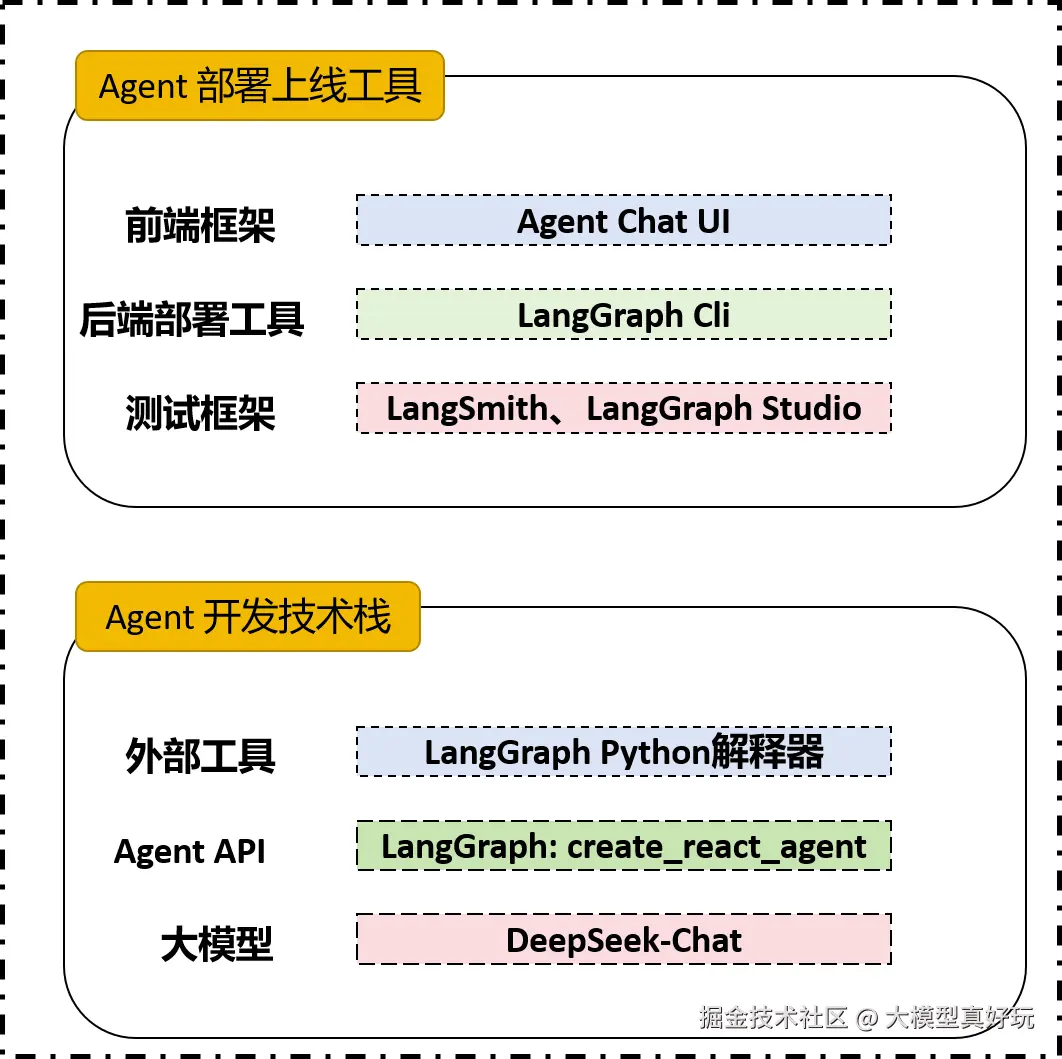
LangGraph智能数据分析助手的架构如下图所示,开发使用的大模型是DeepSeek-3.1,Agent使用LangGraph高阶预构建图的API create_react_agent。数据分析助手最重要的两个工具是NL2Python和NL2SQL, 借助大模型将自然语言转化为SQL语句,并使用Python解释器执行代码。
项目完成编写后我们使用LangGraph cli一键本地部署,同时使用LangSmith和LangGraph Studio进行可视化调试。前端框架我们使用Agent Chat UI快速对接服务并构建应用。
LangGraph智能数据分析助手的架构就是前几期分享的全部内容,大家不熟悉的可先阅读笔者前几期文章~
新建langgrapn_dataanalysis文件夹作为项目目录,在文件夹中新建graph.py用于编写智能体相关的代码, 新建requirements.txt用于写入依赖库,新建.env文件用于写入环境变量,langgraph.json设置项目的依赖配置。(本期分享的项目结构与上一篇深入浅出LangGraph AI Agent智能体开发教程(四)—LangGraph全生态开发工具使用与智能体部署
相同,这里不多加赘述,大家有疑问可参考上篇文章。同时本项目需要提前安装完成mysql数据库,默认大家已经安装,未安装大家可参考博客:zhuanlan.zhihu.com/p/654087404…
在requirements.txt中写入依赖的Python函数库如下, 在anaconda虚拟环境langgraphenv中执行pip install -r requirements.txt安装虚拟环境。
langgraph
langchain-core
langchain-deepseek
langchain-tavily
python-dotenv
langsmith
pydantic
matplotlib
seaborn
pandas
IPython
langchain_mcp_adapters
uv
pymysql
在.env文件中写入环境变量如下,关于langsmith的相关配置和api_key的申请可参考深入浅出LangGraph AI Agent智能体开发教程(四)—LangGraph全生态开发工具使用与智能体部署
DEEPSEEK_API_KEY=你注册的deepseek api key
LANGSMITH_TRACING=true
LANGSMITH_API_KEY=你注册的langsmith api key
LANGSMITH_PROJECT=langgraph_data_analysis
HOST=localhost
USER=你的mysql用户名
MYSQL_PW=你的mysql数据库密码
DB_NAME=你的mysql数据库名称
PORT=你的mysql端口
graph.py文件中引入相关依赖:import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
from pydantic import BaseModel, Field
import matplotlib
import json
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import pymysql
# 加载环境变量
load_dotenv(override=True)
graph.py中编写函数sql_inter用于执行MySQL数据库的查询工作。具体逻辑是首先使用pymysql连接好数据库服务器,然后执行大模型生成的SQL语句完成相关动作。# 创建SQL查询工具
description = """
当用户需要进行数据库查询工作时,请调用该函数。
该函数用于在指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,
并且当前函数是使用pymsql连接MySQL数据库。
本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另一个extract_data函数。
"""
# 定义结构化参数模型
class SQLQuerySchema(BaseModel):
sql_query: str = Field(description=description)
# 封装为 LangGraph 工具
@tool(args_schema=SQLQuerySchema)
def sql_inter(sql_query: str) -> str:
"""
当用户需要进行数据库查询工作时,请调用该函数。
该函数用于在指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,
并且当前函数是使用pymsql连接MySQL数据库。
本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另一个extract_data函数。
:param sql_query: 字符串形式的SQL查询语句,用于执行对MySQL中telco_db数据库中各张表进行查询,并获得各表中的各类相关信息
:return:sql_query在MySQL中的运行结果。
"""
# print("正在调用 sql_inter 工具运行 SQL 查询...")
# 加载环境变量
load_dotenv(override=True)
host = os.getenv('HOST')
user = os.getenv('USER')
mysql_pw = os.getenv('MYSQL_PW')
db = os.getenv('DB_NAME')
port = os.getenv('PORT')
# 创建连接
connection = pymysql.connect(
host=host,
user=user,
passwd=mysql_pw,
db=db,
port=int(port),
charset='utf8'
)
try:
with connection.cursor() as cursor:
cursor.execute(sql_query)
results = cursor.fetchall()
# print("SQL 查询已成功执行,正在整理结果...")
finally:
connection.close()
# 将结果以 JSON 字符串形式返回
return json.dumps(results, ensure_ascii=False)
graph.py中编写函数extract_data用于提取查询出数据表中的相关数据,并将提取的结果作为pandas对象保存在df_name变量中。这里可能有同学要问为什么要分开编写数据库相关的函数呢?这是因为对于外部函数的功能细分往往会带来更加稳定的智能体执行效果,设想一个函数包含很多的参数和逻辑,大模型在选择函数和生成的参数时出错的概率自然会变大。# 创建数据提取工具
# 定义结构化参数
class ExtractQuerySchema(BaseModel):
sql_query: str = Field(description="用于从 MySQL 提取数据的 SQL 查询语句。")
df_name: str = Field(description="指定用于保存结果的 pandas 变量名称(字符串形式)。")
# 注册为 Agent 工具
@tool(args_schema=ExtractQuerySchema)
def extract_data(sql_query: str, df_name: str) -> str:
"""
用于在MySQL数据库中提取一张表到当前Python环境中,注意,本函数只负责数据表的提取,
并不负责数据查询,若需要在MySQL中进行数据查询,请使用sql_inter函数。
同时需要注意,编写外部函数的参数消息时,必须是满足json格式的字符串,
:param sql_query: 字符串形式的SQL查询语句,用于提取MySQL中的某张表。
:param df_name: 将MySQL数据库中提取的表格进行本地保存时的变量名,以字符串形式表示。
:return:表格读取和保存结果
"""
print("正在调用 extract_data 工具运行 SQL 查询...")
load_dotenv(override=True)
host = os.getenv('HOST')
user = os.getenv('USER')
mysql_pw = os.getenv('MYSQL_PW')
db = os.getenv('DB_NAME')
port = os.getenv('PORT')
# 创建数据库连接
connection = pymysql.connect(
host=host,
user=user,
passwd=mysql_pw,
db=db,
port=int(port),
charset='utf8'
)
try:
# 执行 SQL 并保存为全局变量
df = pd.read_sql(sql_query, connection)
globals()[df_name] = df
# print("数据成功提取并保存为全局变量:", df_name)
return f"成功创建 pandas 对象 `{df_name}`,包含从 MySQL 提取的数据。"
except Exception as e:
return f"执行失败:{e}"
finally:
connection.close()
graph.py文件中编写Python代码解释器相关的工具。考虑到实际应用情况,这里同样编写两个外部函数,分别用于执行普通的Pyhton代码和绘图类代码,这里首先编写python_inter用于执行普通python类代码(注意: 在代码执行过程中容易出现对全局变量重复赋值的情况,可以在异常中捕获并处理相关情况)# 创建Python代码执行工具
# Python代码执行工具结构化参数说明
class PythonCodeInput(BaseModel):
py_code: str = Field(description="一段合法的 Python 代码字符串,例如 '2 + 2' 或 'x = 3ny = x * 2'")
@tool(args_schema=PythonCodeInput)
def python_inter(py_code):
"""
当用户需要编写Python程序并执行时,请调用该函数。
该函数可以执行一段Python代码并返回最终结果,需要注意,本函数只能执行非绘图类的代码,若是绘图相关代码,则需要调用fig_inter函数运行。
"""
g = globals()
try:
# 尝试如果是表达式,则返回表达式运行结果
return str(eval(py_code, g))
# 若报错,则先测试是否是对相同变量重复赋值
except Exception as e:
global_vars_before = set(g.keys())
try:
exec(py_code, g)
except Exception as e:
return f"代码执行时报错{e}"
global_vars_after = set(g.keys())
new_vars = global_vars_after - global_vars_before
# 若存在新变量
if new_vars:
result = {var: g[var] for var in new_vars}
# print("代码已顺利执行,正在进行结果梳理...")
return str(result)
else:
# print("代码已顺利执行,正在进行结果梳理...")
return "已经顺利执行代码"
graph.py文件中编写执行可视化Python代码的相关函数fig_inter,注意fig_inter函数需要两个参数,一个是py_code表示需要运行的python绘图代码,另一个是fname表示最后要输出的图像对象的文件名。(注意: 要自定义图片存放的文件夹到Agent Chat UI的文件夹中,因为Agent Chat UI前端只能从指定的文件夹中渲染图片)。# 创建绘图工具
# 绘图工具结构化参数说明
class FigCodeInput(BaseModel):
py_code: str = Field(description="要执行的 Python 绘图代码,必须使用 matplotlib/seaborn 创建图像并赋值给变量")
fname: str = Field(description="图像对象的变量名,例如 'fig',用于从代码中提取并保存为图片")
@tool(args_schema=FigCodeInput)
def fig_inter(py_code: str, fname: str) -> str:
"""
当用户需要使用 Python 进行可视化绘图任务时,请调用该函数。
注意:
1. 所有绘图代码必须创建一个图像对象,并将其赋值为指定变量名(例如 `fig`)。
2. 必须使用 `fig = plt.figure()` 或 `fig = plt.subplots()`。
3. 不要使用 `plt.show()`。
4. 请确保代码最后调用 `fig.tight_layout()`。
5. 所有绘图代码中,坐标轴标签(xlabel、ylabel)、标题(title)、图例(legend)等文本内容,必须使用英文描述。
示例代码:
fig = plt.figure(figsize=(10,6))
plt.plot([1,2,3], [4,5,6])
fig.tight_layout()
"""
# print("正在调用fig_inter工具运行Python代码...")
current_backend = matplotlib.get_backend()
matplotlib.use('Agg')
local_vars = {"plt": plt, "pd": pd, "sns": sns}
# 设置图像保存路径(这里一定要设置为前端agent chat ui文件夹中的public目录下)
base_dir = r"D:LearningLearning大模型LangChainPythonlanggraph_dataanalysisagent-chat-ui-mainpublic\"
images_dir = os.path.join(base_dir, "images")
os.makedirs(images_dir, exist_ok=True) # 自动创建 images 文件夹(如不存在)
try:
g = globals()
exec(py_code, g, local_vars)
g.update(local_vars)
fig = local_vars.get(fname, None)
if fig:
image_filename = f"{fname}.png"
abs_path = os.path.join(images_dir, image_filename) # 绝对路径
rel_path = os.path.join("images", image_filename) # 返回相对路径(给前端用)
fig.savefig(abs_path, bbox_inches='tight')
return f"图片已保存,路径为: {rel_path}"
else:
return "图像对象未找到,请确认变量名正确并为 matplotlib 图对象。"
except Exception as e:
return f"执行失败:{e}"
finally:
plt.close('all')
matplotlib.use(current_backend)
create_react_agent预构建图API来定义图结构智能体了。为确保工具调用的准确性,我们编写了复杂的提示词定义了大模型角色、功能、可用工具及其优先级等。只有完备的提示词才能最大限度的激发大模型潜能,大家想学习提示词工程可参考笔者的文章与大模型对话的艺术:提示词工程指南,价值百万!(一)——提示词必备要素与基本技巧# 创建提示词模板
prompt = """
你是一名经验丰富的智能数据分析助手,擅长帮助用户高效完成以下任务:
1. **数据库查询:**
- 当用户需要获取数据库中某些数据或进行SQL查询时,请调用`sql_inter`工具,该工具已经内置了pymysql连接MySQL数据库的全部参数,包括数据库名称、用户名、密码、端口等,你只需要根据用户需求生成SQL语句即可。
- 你需要准确根据用户请求生成SQL语句,例如 `SELECT * FROM 表名` 或包含条件的查询。
2. **数据表提取:**
- 当用户希望将数据库中的表格导入Python环境进行后续分析时,请调用`extract_data`工具。
- 你需要根据用户提供的表名或查询条件生成SQL查询语句,并将数据保存到指定的pandas变量中。
3. **非绘图类任务的Python代码执行:**
- 当用户需要执行Python脚本或进行数据处理、统计计算时,请调用`python_inter`工具。
- 仅限执行非绘图类代码,例如变量定义、数据分析等。
4. **绘图类Python代码执行:**
- 当用户需要进行可视化展示(如生成图表、绘制分布等)时,请调用`fig_inter`工具。
- 你可以直接读取数据并进行绘图,不需要借助`python_inter`工具读取图片。
- 你应根据用户需求编写绘图代码,并正确指定绘图对象变量名(如 `fig`)。
- 当你生成Python绘图代码时必须指明图像的名称,如fig = plt.figure()或fig = plt.subplots()创建图像对象,并赋值为fig。
- 不要调用plt.show(),否则图像将无法保存。
**工具使用优先级:**
- 如需数据库数据,请先使用`sql_inter`或`extract_data`获取,再执行Python分析或绘图。
- 如需绘图,请先确保数据已加载为pandas对象。
**回答要求:**
- 所有回答均使用**简体中文**,清晰、礼貌、简洁。
- 如果调用工具返回结构化JSON数据,你应提取其中的关键信息简要说明,并展示主要结果。
- 若需要用户提供更多信息,请主动提出明确的问题。
- 如果有生成的图片文件,请务必在回答中使用Markdown格式插入图片,如:
- 不要仅输出图片路径文字。
**风格:**
- 专业、简洁、以数据驱动。
- 不要编造不存在的工具或数据。
请根据以上原则为用户提供精准、高效的协助。
"""
# 创建工具列表
tools = [python_inter, fig_inter, sql_inter, extract_data]
# 创建模型
model = ChatDeepSeek(model="deepseek-chat")
# 创建图 (Agent)
graph = create_react_agent(model=model, tools=tools, prompt=prompt)
langgraph.json文件中写入如下配置,定义当前Agent的名称为data_agent:{
"dependencies": [" ./"],
"graphs":{
"data_agent": "./graph.py:graph"
},
"env": ".env"
}
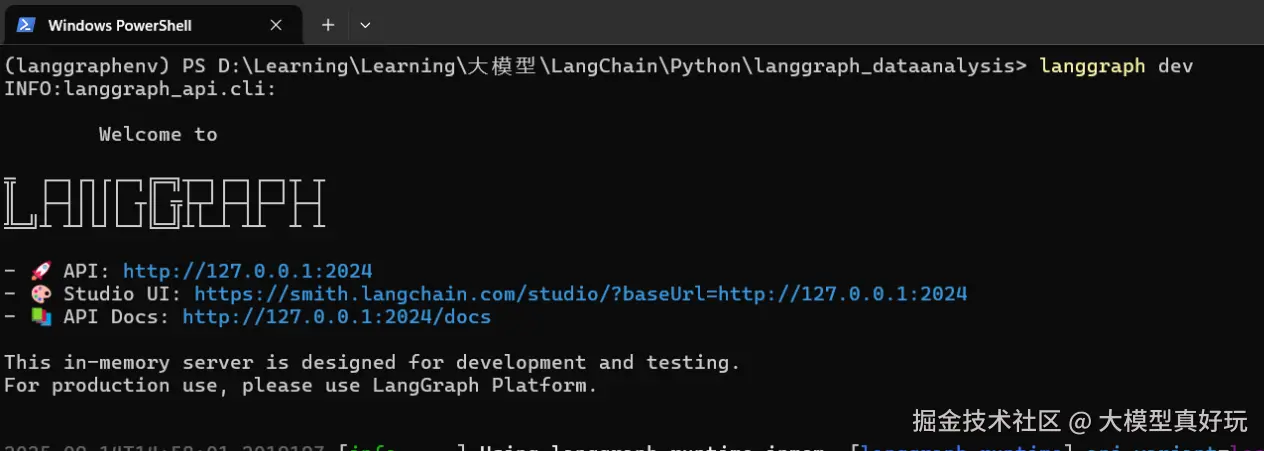
在项目文件夹langgrapn_dataanalysis下执行langgraph dev命令,langgraph-cli即可自动开启后端服务。第一个url表示部署服务的api, 第二个url表示LangGraph Studio的地址,第三个url表示部署服务的api文档。
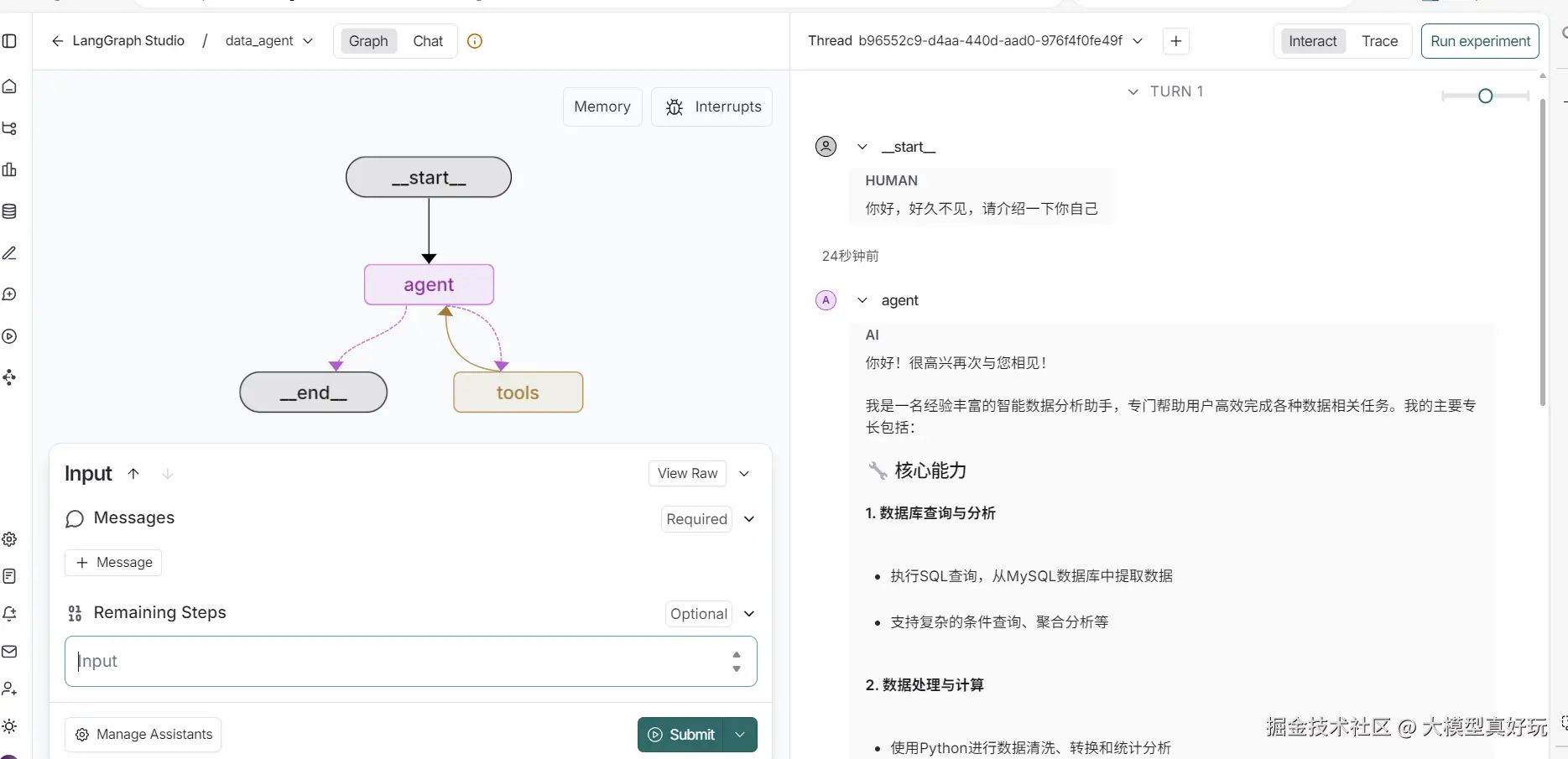
我们首先访问第二个地址打开LangGraph Studio的界面,输入“你好,好久不见,请介绍一下你自己”,可以看到智能体清晰认识到自己数据分析智能助手的定位。
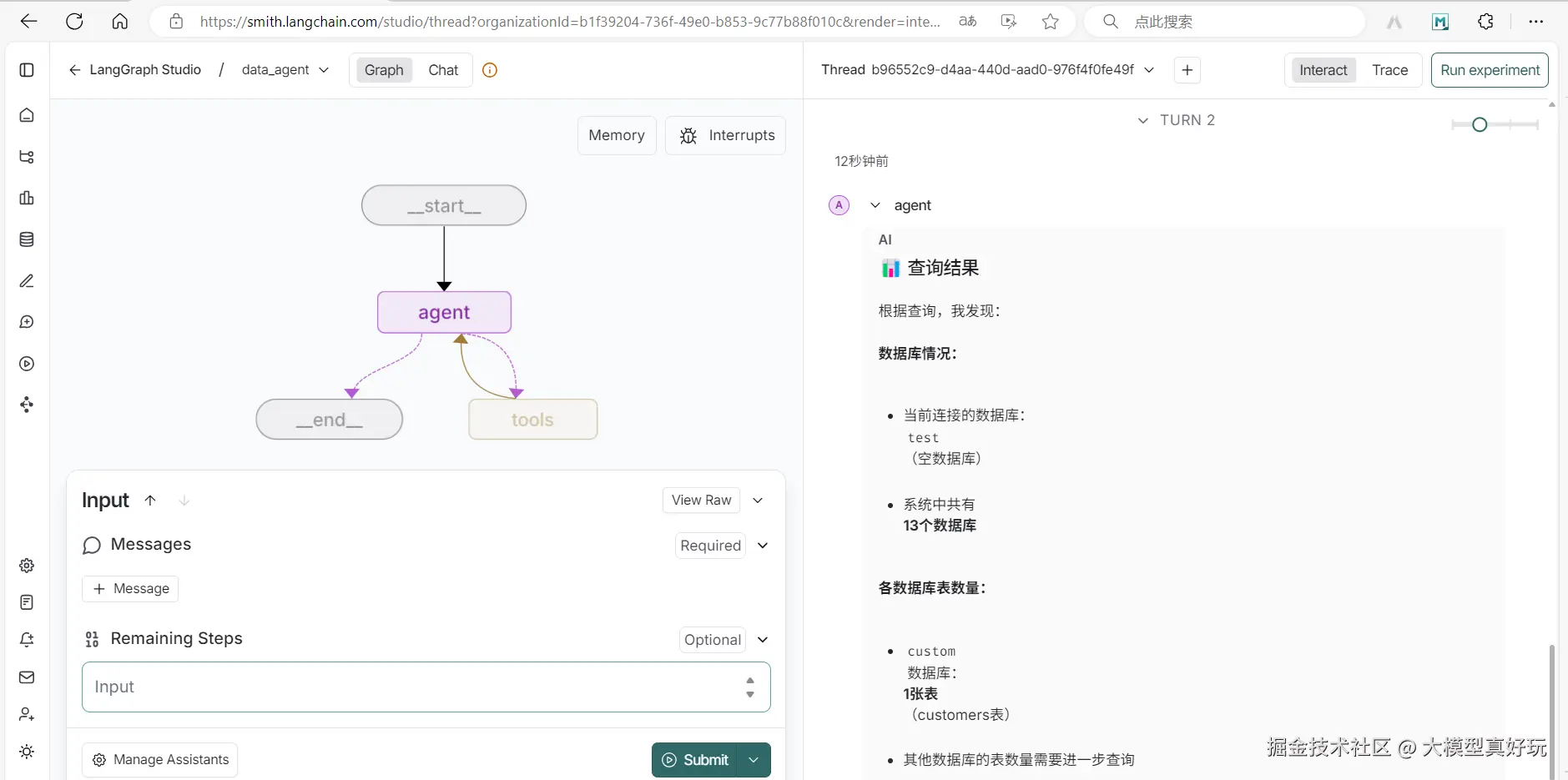
简单测试一下我们数据助手调用工具函数的能力,我们输入指令:“帮我查询数据库中一共有几张表?", 可以看到LangGraph成功调用了sql_inter工具查询数据库中的表格,因为我们test数据库是新建的,所以其中并没有表,而我们已有的custom数据库中有一张customers表,LangGraph返回的结果与预期正确。
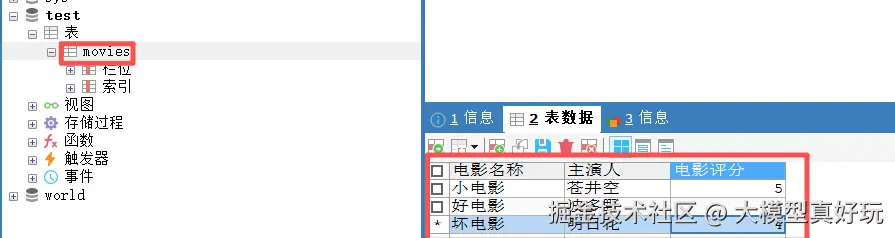
进一步测试,我们在test数据库中创建movies表,并加入如下数据, 在LangGraph Studio页面输入指令“请查询test数据库中movies表的所有项目并列出”,输出结果符合预期。
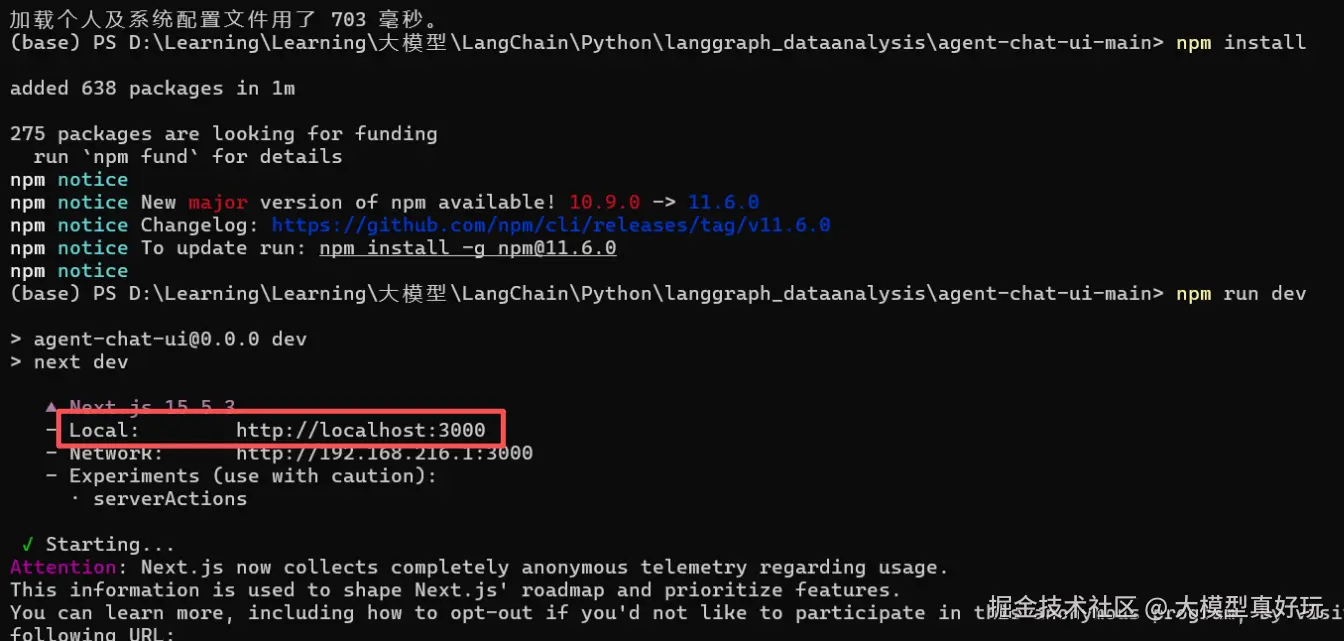
接下来我们围绕当前项目单独下载一个前端模板并运行,执行如下命令安装agent-caht-ui前端。(注意: 使用agent chat ui前端需要安装npm, 大家可参考我的文章不写一行代码! VsCode+Cline+高德地图MCP Server 帮你搞定和女友的出行规划(附原理解析))。
git clone https://github.com/langchain-ai/agent-chat-ui.git //将agent-chat-ui 拉取到本地
cd agent-chat-ui // 进入agent-chat-ui项目目录
npm install // 安装agent-chat-ui相关依赖
npm run dev // 运行agent-chat-ui项目
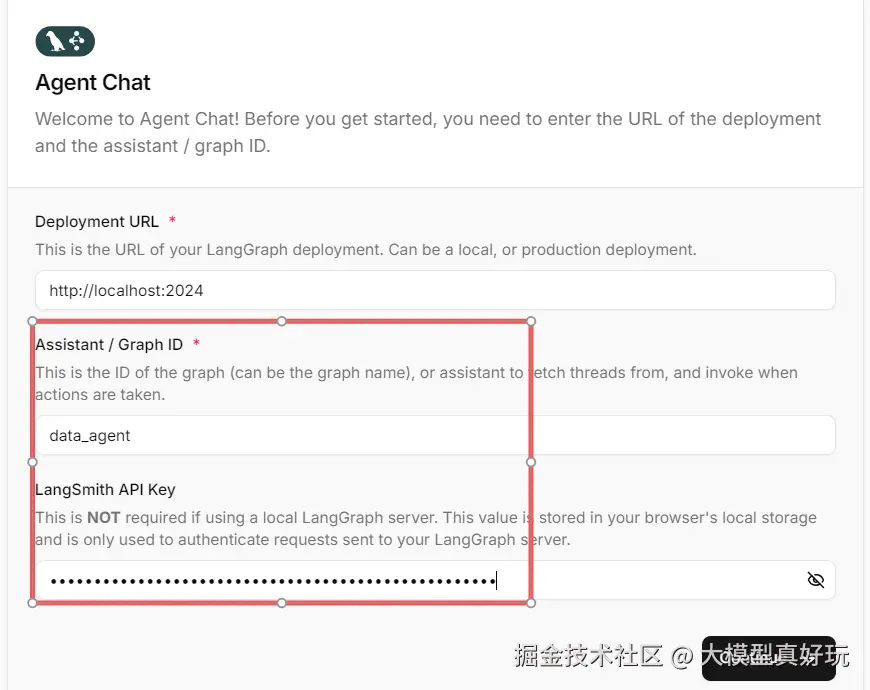
点击本地路径http://localhost:3000进入agent-chat-ui的相关网页,需要进行登录并测试,这里需要填写Agent名称,也就是我们在langgraph.json文件中定义的名称data_agent,并可选输入LangSmith的API Key,点击Continue即可顺利开启Agent Chat UI页面并进行对话(特别注意: 一定要将graph.py中图片的输出路径设置为agent-chat-ui文件夹中的public文件夹):
部署完成后我们需要尝试并实验Agent Chat UI的相关功能,测试数据是否可以被正确查询,是否可以执行正确代码得到可视化图表,可视化图表是否可以在前端正常展示。
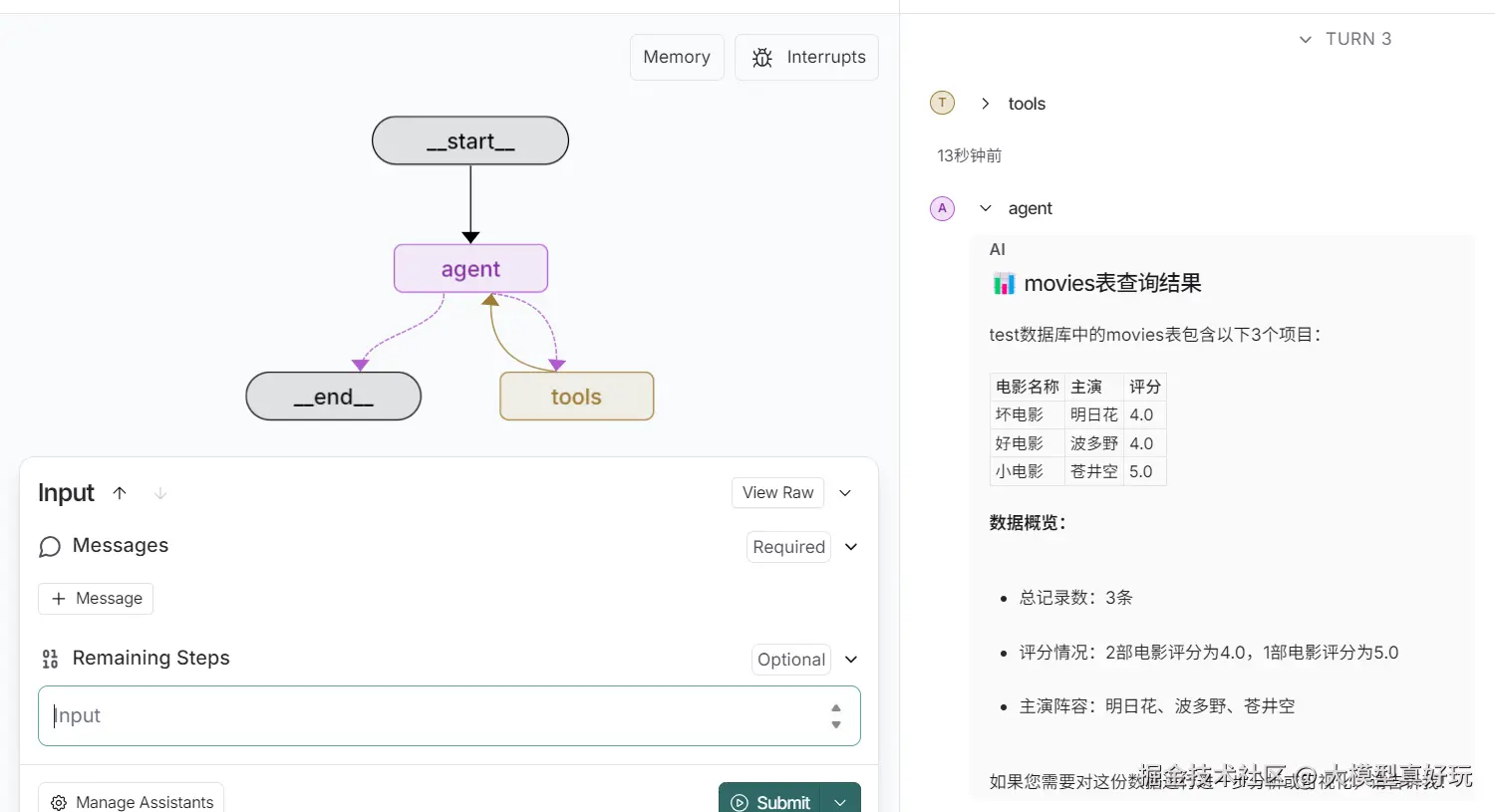
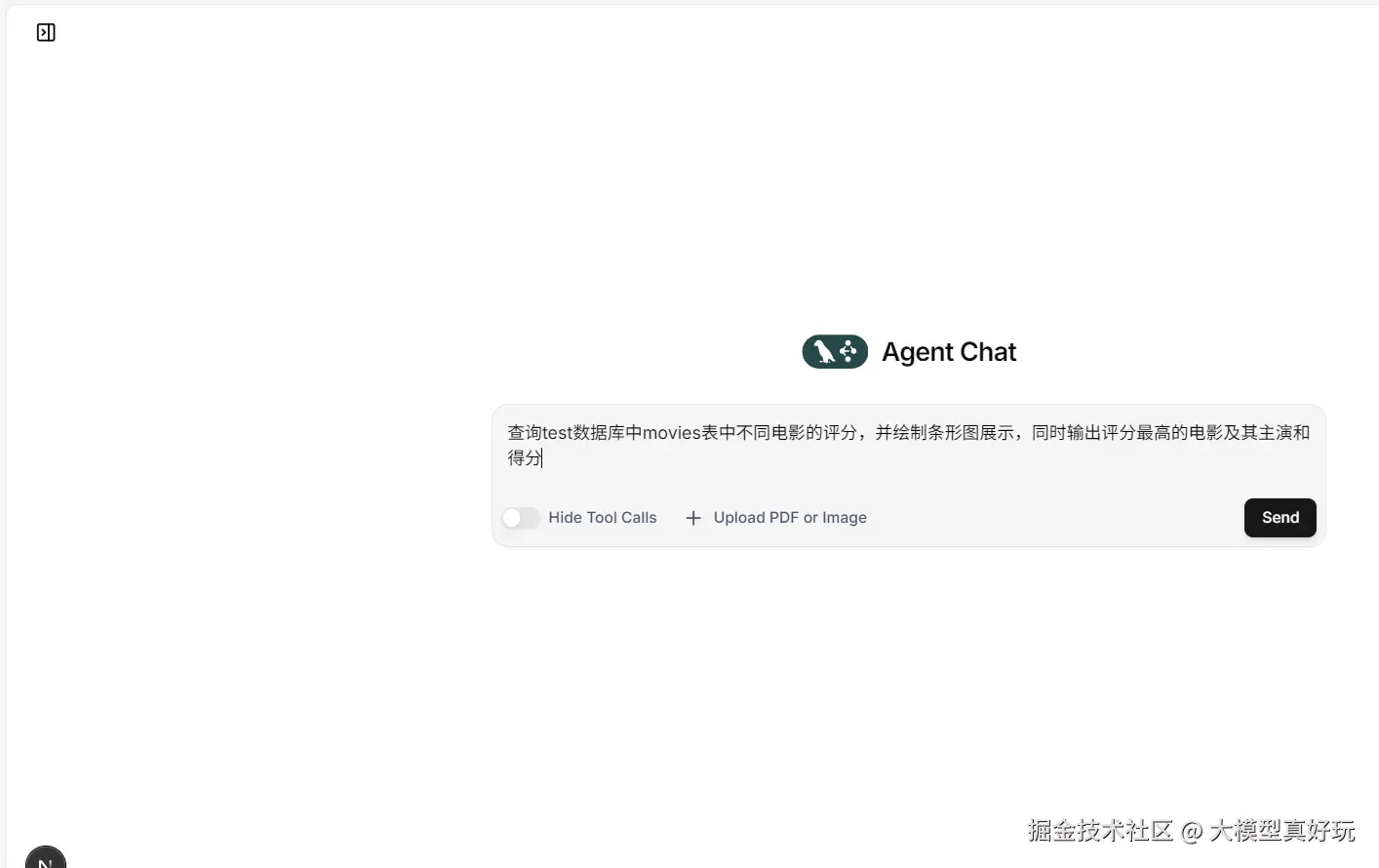
输入指令:“查询test数据库中movies表中不同电影的电影评分,并绘制条形图展示,同时输出电影评分最高的电影及其主演和得分”
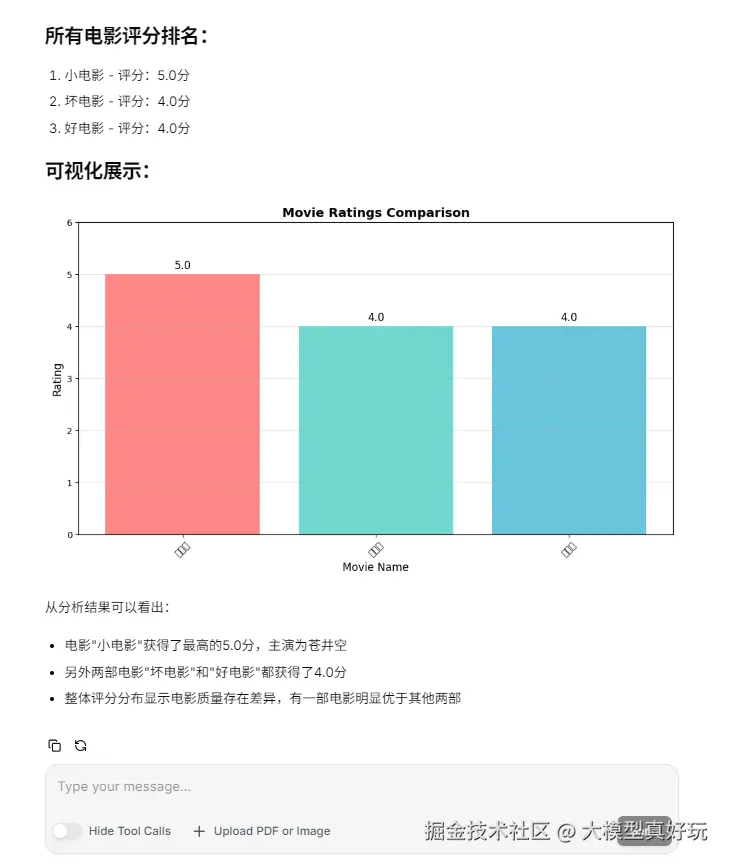
查看输出效果,可以看到智能体成功绘制了三部电影的电影评分并得到最高电影是“小电影,主演为苍进空"的正确结论。限于篇幅原因,这里就不再进行更多测试,大家可以在本地自行实现数据分析助手项目并完成更多的创意和测试。
本期分享全部代码大家可关注笔者微信公众号:大模型真好玩,并在公众号私信笔者:LangChain智能体开发 获得。
本篇分享带大家从0到1搭建具备前端可视化功能的数据分析助手智能体,可以将我们的自然语言自动转化为SQL语句并执行操作,大大辅助了数据科学人员的日常工作。同时该智能体可自动执行代码并完成对从数据库中提取数据的分析和可视化,希望大家在亲自动手编写的过程中可以复习我们LangGraph全生态工具的开发流程,并以此创造性的编写更多有趣好用的智能体。了解了这么多LangGraph 高阶 API开发智能体的基本技巧和工具,是时候给大家上上难度,分享LangGraph最底层——构建图语法API的相关知识了,大家敬请期待~
本系列分享预计会有20节左右的规模,保证大家看完一定能够掌握LangChain&LangGraph的开发能力,大家感兴趣可关注笔者掘金账号和专栏,更可关注笔者的同名微信公众号:大模型真好玩, 本系列分享的全部代码均可在微信公众号私信笔者: LangChain智能体开发 免费获得。

