
缘之空安卓版汉化
1435MB · 2025-12-24

最近在开发一个智能体,核心能力之一是数据可视化。用户需要直观的图表来理解数据,而不仅仅是数字。
现实很快证明,这个“分分钟”的项目需要持续优化。以下是经历的五个主要版本及其中的挑战:
chartOptions 参数(看起来参数极简但是功能强大)chartOptions (JSON字符串),智能体需生成完整的ECharts配置项JSON,工具将其嵌入HTML模板返回。{
"title": {
"text": "示例图表"
},
"tooltip": {
"trigger": "axis"
},
"legend": {
"data": ["蒸发量", "降水量"]
},
"xAxis": {
"type": "category",
"data": ["一月", "二月", "三月", "四月", "五月", "六月", "七月"]
},
"yAxis": [
{
"type": "value",
"name": "蒸发量",
"axisLabel": {
"formatter": "{value} ml"
}
},
{
"type": "value",
"name": "降水量",
"axisLabel": {
"formatter": "{value} °C"
}
}
],
"series": [
{
"name": "蒸发量",
"type": "bar",
"data": [2.0, 4.9, 7.0, 23.2, 25.6, 76.7, 135.6]
},
{
"name": "降水量",
"type": "line",
"yAxisIndex": 1,
"data": [2.0, 2.2, 3.3, 4.5, 6.3, 10.2, 20.3]
}
]
}
这个JSON字符串长度已接近1000字符,更复杂的图表会轻松突破数千甚至上万字符。chartType (图表类型)、title (标题)、xAxisData (X轴数据)、yAxisData (Y轴数据)、seriesData (系列数据)等。
这样一来,生成同样的双Y轴图表,调用参数可以简化为:{
"templateId": "line-chart-tech-blue",
"data": {
"categories": ["一月", "二月", "三月", "四月", "五月", "六月", "七月"],
"series": [
{
"name": "蒸发量",
"data": [2.0, 4.9, 7.0, 23.2, 25.6, 76.7, 135.6]
},
{
"name": "降水量",
"data": [2.0, 2.2, 3.3, 4.5, 6.3, 10.2, 20.3]
}
]
}
}
参数字符数减少了80%以上,核心信息(数据)被清晰分离出来。
{
"templateId": "line-chart-tech-blue",
"data": {
"categories": ["一月", "二月", "三月"],
"series": [
{
"name": "蒸发量",
"data": [2.0, 4.9, 7.0]
},
{
"name": "降水量",
"data": [2.0, 2.2, 3.3] // <--- 此处可能多一个逗号
}, // <--- 或此处多一个逗号
]
}
}
这种细微错误在复杂场景下仍会触发工具校验失败。例如,LLM因上下文截断生成:
{
"templateId": "line-chart-tech-blue",
"data": {
"categories": ["一月", "二月", "三月"],
"series": [
{
"name": "蒸发量",
"data": [2.0, 4.9, 7.0]
},
{
"name": "降水量",
"data": [2.0, 2.2 // <--- 数据点被截断
}
]
}
}
修复器可能补全 }使JSON合法,但丢失的3.3 数据点永远无法恢复,导致图表展示错误信息。titles: string[] (标题数组)xAxisLabels: string[] (X轴标签数组)seriesNames: string[] (系列名称数组)seriesData: number[][] (核心数据二维数组)chartTypes: string[] (系列类型数组)实际调用参数示例(类似函数调用风格):
# 伪代码表示实际工具调用参数结构
tool_call(
chart_type='bar_line_chart', # 指定组合图表类型
title='蒸发量与降水量', # 单一标题
categories=['一月', '二月', '三月', '四月', '五月', '六月', '七月'],
series_names=['蒸发量', '降水量'],
series_types=['bar', 'line'], # 指定每个系列的类型
series_data=[[2.0, 4.9, 7.0, 23.2, 25.6, 76.7, 135.6],[2.0, 2.2, 3.3, 4.5, 6.3, 10.2, 20.3]] # 系列数据
y_axis_names=['蒸发量 (ml)', '降水量 (°C)'] # Y轴名称
)
这种结构将嵌套关系转化为命名约定(如series_data_0对应series_names[0]),极大降低了LLM生成复杂符号的负担。
{}, :, "key" 等符号显著减少,大模型生成错误概率大幅降低。工具返回结果示例:"https://your-cos-bucket.com/charts/a1b2c3d4-e5f6-7890-g1h2-i3j4k5l6m7n8.html"
这个“分分钟”项目,最终演变为对“如何设计大模型友好工具”的深度探索。以下几点认知,我认为比代码实现本身更具普适价值:
工具规划:精简胜于冗余,职责必须分明
参数设计:极简是王道,ID是理想态
dataId, templateId)。所有复杂数据或配置通过此ID在系统其他地方(数据库、缓存、配置文件)预先定义或准备好。工具仅执行与ID关联的确定性操作。这彻底消除了参数层面的噪声和错误风险。 虽然当前版本未完全实现,但这是未来优化方向(如让智能体先生成数据配置ID,再调用图表工具)。参数描述:清晰、简短、示例、扁平化
例如,对 series_data 参数的描述:
"series_data": {
"type": "array",
"items": {"type": "number"},
"description": "第一个数据系列的数据点数组,数值类型。例如: [10, 20, 30]"
}错误处理:明确原因,给出建议,指引路径
message)至关重要。它直接影响智能体(尤其是基于ReAct等框架的智能体)能否理解问题并尝试修复。例如,当 series_data_0 包含非数字时的错误响应:{
"error": "Parameter 'series_data_0' contains non-numeric value 'N/A' at index 3.",
"suggestion": "Please ensure all values in 'series_data' arrays are valid numbers. You may need to clean the source data or set a default value like 0 for missing data points."
}
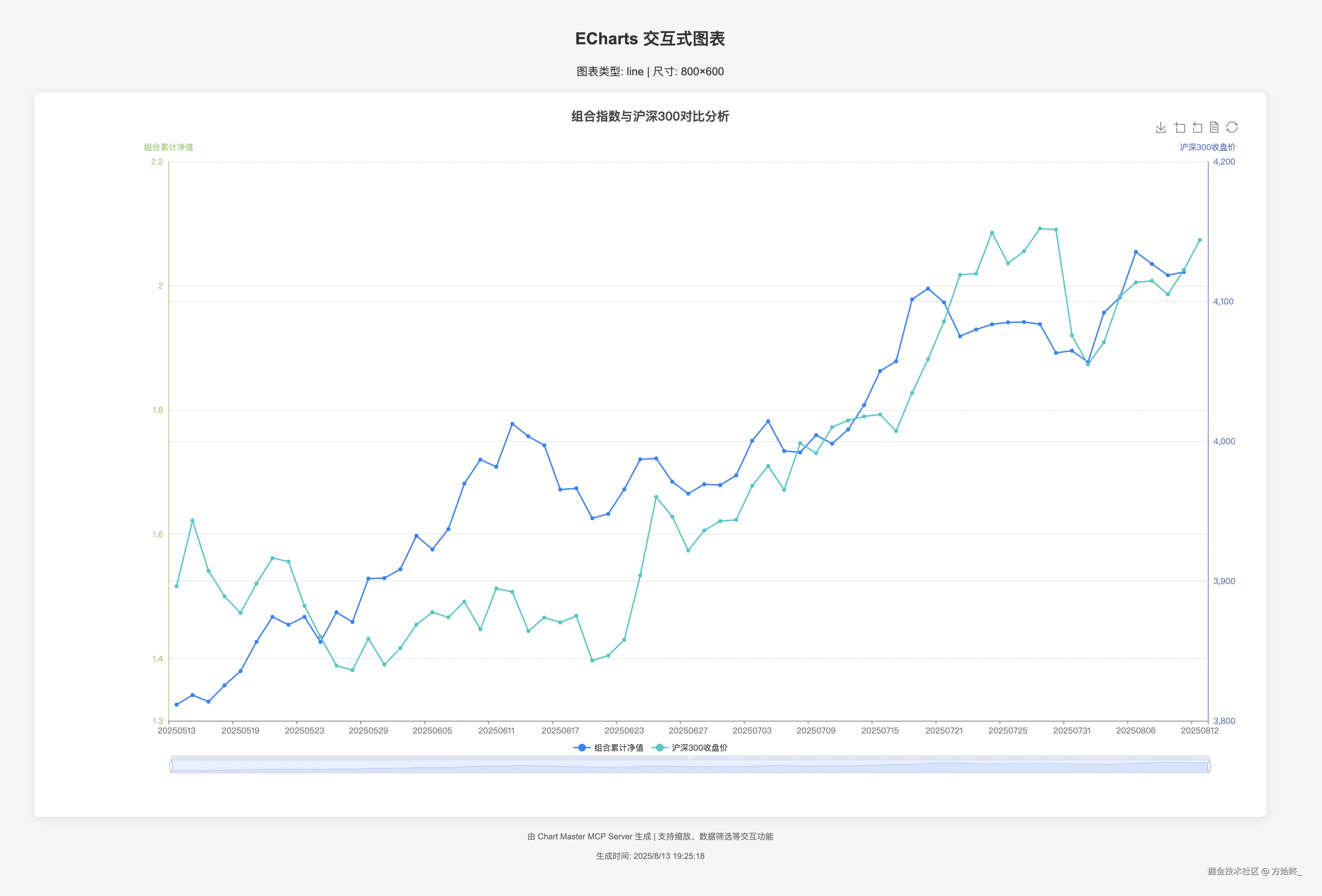
这是一个生成的图表的示例:
回到标题:“做一个图表MCP Server,分分钟的事儿?” 答案显然是否定的。它绝非一个“分分钟”就能完美交付的简单任务。它是一个需要经历需求分析、技术选型、原型验证、问题暴露、迭代优化、认知升级的完整工程过程。
然而,这个过程的价值远超预期。我们不仅最终交付了一个稳定、可用、用户体验良好的可交互图表MCP Server,更重要的是,我们深刻理解了如何设计“大模型友好”的工具。那些关于工具规划、参数设计、描述规范、错误处理的认知更新,是可以在未来所有大模型应用开发中复用的宝贵经验。
所以,下次听到“分分钟搞定”的说法时,不妨理性看待。因为真正的价值,往往就藏在那些看似“分分钟”背后,需要“分阶段”去克服的挑战和沉淀的工程智慧之中。
模型,平台,工具都在迅速进化,我遇到的问题可能很快就会(或许已经)“不成问题”。
希望我的这些实践经验和思考,能为大家在构建更强大的AI应用时提供一些参考。

