
倩女幽魂vivo手机版
1.87 GB · 2025-11-15

其实缓存的逻辑特简单,就像你工位上的 “零食抽屉”:
用技术话讲:缓存是 “暂存高频访问数据的临时存储器” ,速度比数据库快 N 倍(比如内存缓存比硬盘数据库快 100-1000 倍),核心作用就一个 —— 帮数据库 “减负”,让接口跑得飞起。
后端写多了就知道,缓存不是 “一刀切”,得看场景选 —— 主要分 “自己用的” 和 “大家共用的” 两种。
本地缓存就是把数据存在当前服务器的内存里,比如 Java 里的Guava Cache、Caffeine,Python 的functools.lru_cache。
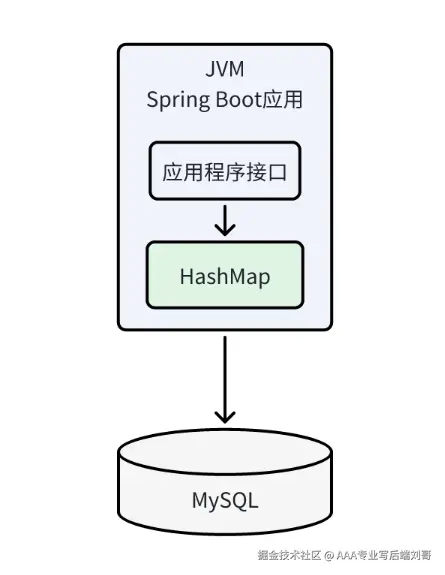
不用走网络,直接读内存,响应时间能压到毫秒甚至微秒级 —— 比如你写个定时任务,把热门配置加载到本地缓存,接口查配置时根本不用碰数据库,爽歪歪。
就像你工位的零食抽屉,只有你能吃 —— 要是服务部署了 3 台服务器(分布式),每台都有自己的本地缓存:
所以本地缓存只适合:单机部署、数据不常变、不需要多机共享的场景(比如本地测试、简单工具类)。
分布式缓存是把数据存在独立的缓存服务器集群里(比如 Redis、Memcached),所有后端服务器都去这一个 “冰箱” 里拿数据 —— 不管你访问哪台后端服务器,查的都是同一个缓存,数据肯定一致。
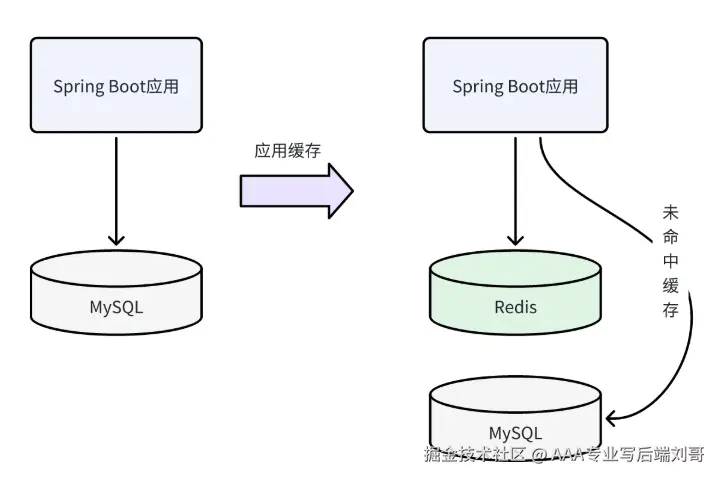
毕竟要和缓存服务器通信(走 TCP/IP),比本地缓存慢一点 —— 但也就多几毫秒,对比数据库的几十上百毫秒,还是快很多,绝大多数场景都能接受。
| 场景 | 选哪种? | 例子 |
|---|---|---|
| 单机部署、数据不变 | 本地缓存 | Guava Cache 存配置 |
| 分布式部署、多机共享 | 分布式缓存 | Redis 存用户会话、商品 |
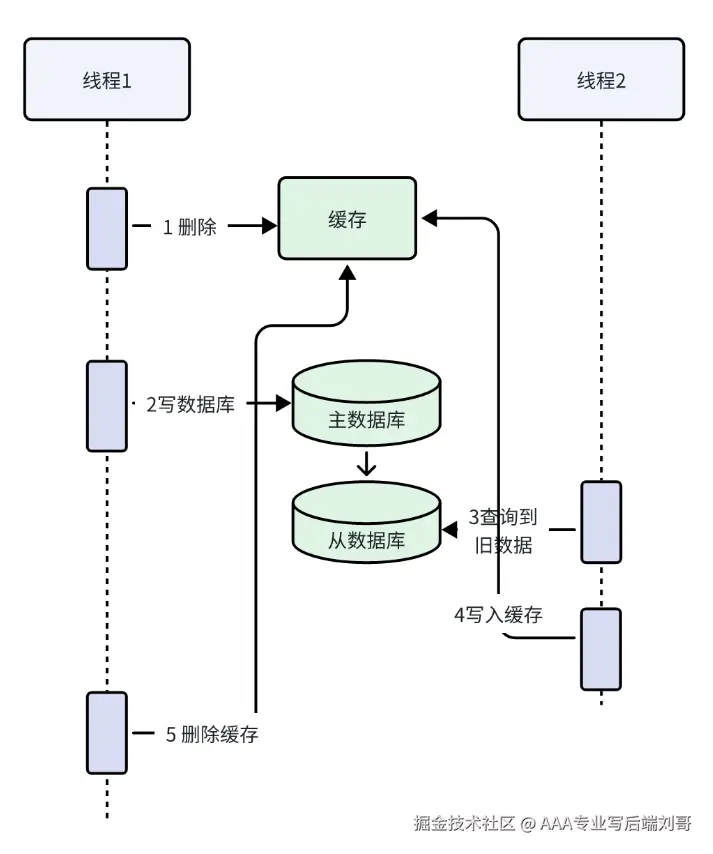
用缓存爽归爽,但一更新数据就容易出问题 —— 比如你改了数据库里的商品价格,缓存里还是旧价格,用户看到的就是 “假价格”,这就是缓存一致性问题(缓存脏了)。
先看为啥会脏?常见场景:
别慌!下面 3 个方案,从 “强一致” 到 “最终一致”,覆盖不同业务需求。
核心思路:用锁保证 “更新数据库” 和 “更新缓存” 是一个 “原子操作”—— 同一时间只有一个线程能改,别人都得排队,不会乱。
// 用key做锁,保证同一key的操作排队
synchronized (productId) {
try {
// 1. 先更数据库(成功才算第一步)
productMapper.updatePrice(productId, newPrice);
// 2. 再更缓存(数据库成功了,缓存才更)
redisTemplate.opsForValue().set("product:price:" + productId, newPrice);
} catch (Exception e) {
// 失败了可以回滚缓存(比如删了),避免脏数据
redisTemplate.delete("product:price:" + productId);
throw new RuntimeException("更新失败");
}
}
只要锁没毛病,数据库和缓存肯定同步,适合 “钱相关” 的场景(比如用户余额、订单金额)—— 总不能用户付了钱,缓存里还是没付的状态吧?
锁会让并发请求排队,比如每秒 1000 个请求,都得等着一个一个处理,接口响应时间会变长 —— 鱼和熊掌不可兼得,看业务能不能接受。
要是业务能接受 “短暂不一致”(比如商品详情页,1 秒内看到旧价格没事),延迟双删是性价比很高的方案。
核心思路:删两次缓存,中间隔一会儿,把 “旧数据写回缓存” 的坑堵上。
public void updateProductPrice(String productId, BigDecimal newPrice) {
// 1. 第一次删缓存
redisTemplate.delete("product:price:" + productId);
// 2. 更新数据库
productMapper.updatePrice(productId, newPrice);
// 3. 等1秒(时间根据业务调,比如数据库读耗时+网络延迟)
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// 4. 第二次删缓存
redisTemplate.delete("product:price:" + productId);
}
不用加锁,请求来了直接处理,就等 1 秒(一般业务感知不到),适合大部分非金融场景(商品、文章、用户资料)。
中间那 1 秒,可能有用户看到旧数据 —— 但总比一直脏数据强,而且大部分场景用户根本没感觉。
要是你想让 “更新接口” 跑得飞快,哪怕缓存慢个几十毫秒也没事,异步双写就很合适。
核心思路:更新数据库后,不用等缓存更新,直接返回;缓存更新扔给 “异步线程” 或者 “MQ” 去做,后台慢慢处理。
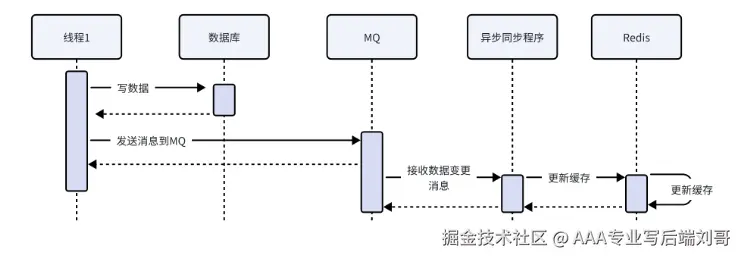
用户点 “更新”,瞬间看到 “成功”,体验好;缓存更新在后台慢慢跑,就算 MQ 排队,也只是晚一点同步,不影响用户。
要是 MQ 堆积严重,缓存可能几分钟都没同步 —— 适合 “对实时性要求不高” 的场景(比如用户改个昵称,就算缓存晚 1 分钟同步,也没啥大问题)。
不管你用哪种一致性方案,都得给缓存加个 “过期时间”(比如 Redis 的expire)—— 这是最后一道兜底,防止缓存 “永久脏”。
最后想问大家:你们平时用缓存踩过哪些坑?比如遇到过缓存穿透、雪崩吗?评论区聊聊,一起避坑涨经验!

