
一级建造师建设工程法规总题库
40.28MB · 2025-12-18

本章将回顾 AI 智能体 的演进历程,从早期的机器人流程自动化(RPA)到当今复杂的多智能体架构。我们将界定“什么才是真正的 AI 智能体”,拆解其关键组成,并考察正在重塑全球各行各业的不同类型的 AI 智能体。
本章将涵盖以下主题:
读完本章后,你将清晰理解 AI 智能体的演进、其关键组件,以及它们如何改变产业。
你可以在本书配套的 GitHub 代码库获取本章的完整代码:github.com/PacktPublis…
从传统的基于规则自动化到复杂的AI 驱动智能体,这段旅程伴随着显著的技术进步。最初的自动化局限于僵化、预定义的工作流;随着机器学习(ML)、强化学习(RL)与大型语言模型(LLM)的兴起,AI 智能体正变得更加自主、智能,并具备复杂决策能力。下面我们按阶段梳理近几十年的几种“代理”形态。
这是自动化的早期形态,聚焦于基于规则的系统来执行预定义任务。此类系统遵循严格的逻辑流程,依据明确条件与结构化输入采取行动。它们对重复性流程很有效,但缺乏灵活性、适应性,也难以处理非结构化数据。例如,一个严格依据决策树运作、不会从交互中学习的规则型聊天机器人,在动态环境或意外输入面前就捉襟见肘。
随着 AI 发展,基于机器学习与强化学习的智能体出现。它们可以从数据中学习,基于概率模型做决策,并通过试错优化行为。我们分别展开:
基于规则的代理 → 机器学习模型:从静态规则集逐步过渡到能基于训练数据进行分类与预测的模型。
例如,早期的客服聊天机器人依据决策树回答用户,并结合命名实体识别机制进行路由。
定义(Definition)
命名实体识别(NER) 是一种自然语言处理任务,用于识别并归类文本中的关键信息,如人名、组织名、地点、日期及其他预定义实体。
强化学习(RL)智能体:通过与环境交互进行学习,为获得长期回报而优化行动。RL 被广泛用于游戏、机器人与复杂问题求解。
例如,DeepMind 的 AlphaGo 通过模拟数百万盘对弈并以试错优化策略,学会了围棋。
然而,这些早期智能体的主要短板是泛化能力有限。以 AlphaGo 为例:它虽在围棋上臻于化境,但其智能狭窄且领域特定——既不能把所学迁移到象棋等其他棋类,也无法胜任客服或排期这样的无关任务。这类 AI 在边界明确的环境中表现卓越,但当规则、上下文或输入模式发生变化就难以适应。
这暴露了 AI 的更广泛挑战:我们需要能跨领域推理、理解模糊指令,并对动态环境进行实时适应的智能体。
这正是 LLM 驱动智能体 登场之处。
随着 LLM 的出现,智能体在推理、规划与动态交互上的能力显著增强。生成式 AI 使这些智能体不仅能回答问题,还能综合信息、自动化工作流,并与多种外部系统集成——本章后文将详细展开。
从高层看,基于 LLM 的智能体之所以强大,在于它们可利用诸如 GPT-4o 等模型,不仅理解上下文、检索相关信息,还可编排一组组件,使智能体能与周边环境互动。这一“额外的智能层”使现代 AI 智能体区别于既有的 RPA 系统,也区别于仅生成文本的 LLM 本身。
此外,一旦引入大型多模态模型,AI 智能体就能融合文本、语音、视觉、结构化数据等多模态,以更贴近人类的方式进行交互。
例如,一个基于 LLM 的零售助理可以处理语音问询、分析商品图片,并实时查询库存数据库。
AI 智能体演进中的一大突破是多智能体系统:多个智能体协作完成复杂任务。通过任务分解、专业化与并行执行,系统获得更高的效率与自主性。
例如,一个多智能体研究系统中:一名代理负责检索论文,另一名总结内容,第三名则为团队产出可执行洞见。
此外,我们还可赋予代理以“自我复制”能力:根据需求生成额外子代理来处理子任务,实现弹性扩展。
例如,一个 AI 项目经理 可派生设计、编码、测试等专业子代理来协作完成软件开发流程。
AI 演化的终极目标是通用人工智能(AGI)智能体——能够胜任人类所能完成的任何智力任务的系统。AGI 智能体将整合推理、规划、记忆与自我改进,在广泛应用中自主运作。
在本书写作时,AGI 仍未达成普遍共识的标准形态,但我们正在见证 AI 智能体边界的持续拓展,令人振奋。
在全书中,我们主要聚焦于单体、基于 LLM 的智能体,并在第 7 章涉及多智能体框架。接下来,让我们先给出 AI 智能体的定义。
AI 智能体是一类基于软件的实体,能够感知其环境、围绕目标进行推理、做出决策并执行行动——常以自主方式——并与外部系统交互。不同于遵循预编程规则的传统自动化,AI 智能体可以根据上下文动态适应、利用外部工具,并引入记忆以随时间改进决策。
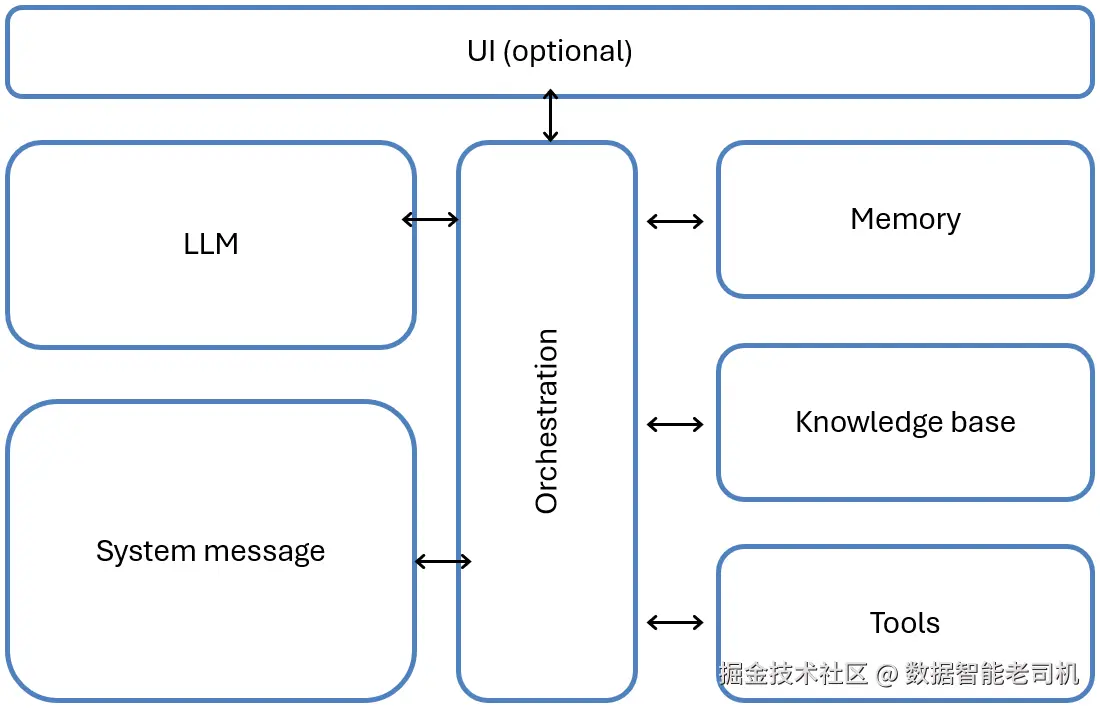
在技术层面上,AI 智能体由若干核心组件构成:
图 2.1:AI 智能体的主要组件
在此之上,还需要一个编排层(orchestration layer)来治理任务流转,确保各组件之间的协调。
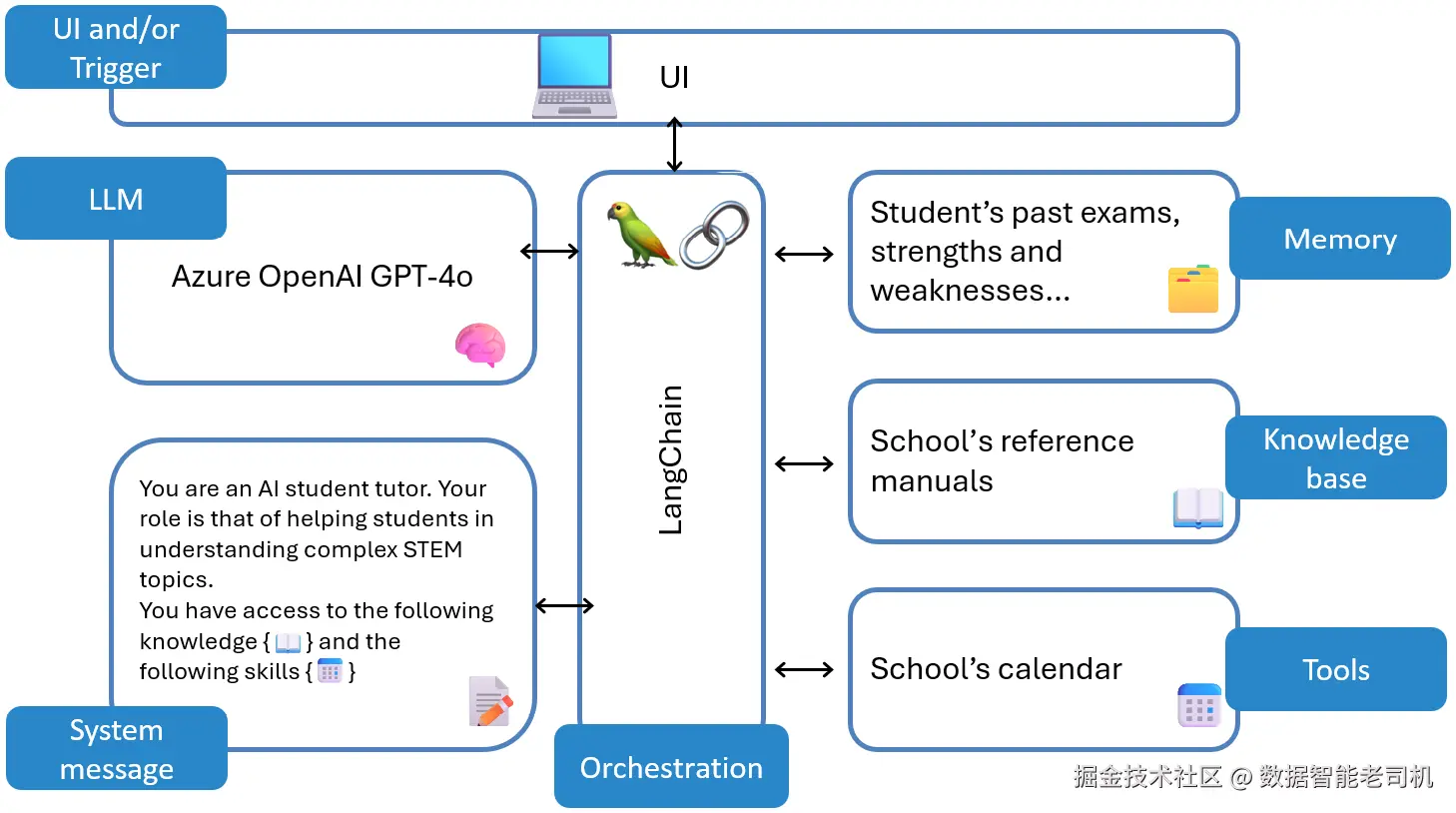
举例:设想一所学校开发一名 AI 代理,帮助高中生掌握复杂的 STEM 主题。借助 LLM、记忆与编排,该代理可提供个性化辅导、引用权威来源,并依据每位学生的学习需求自适应。
图 2.2:AI 辅导助理示例
下面放大到各组件:
实际工作流程示例:
接下来一个关键问题是:代理如何知道何时调用特定知识或特定工具?
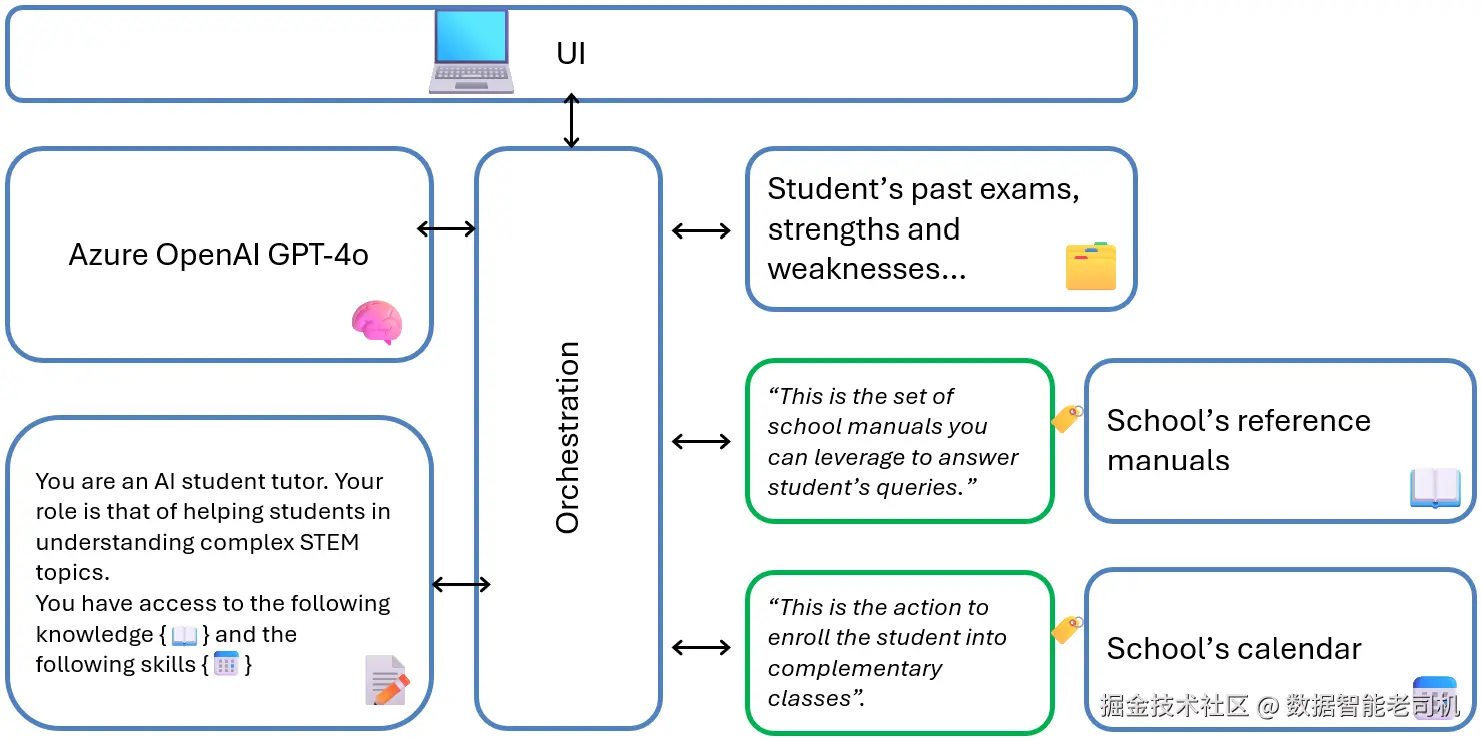
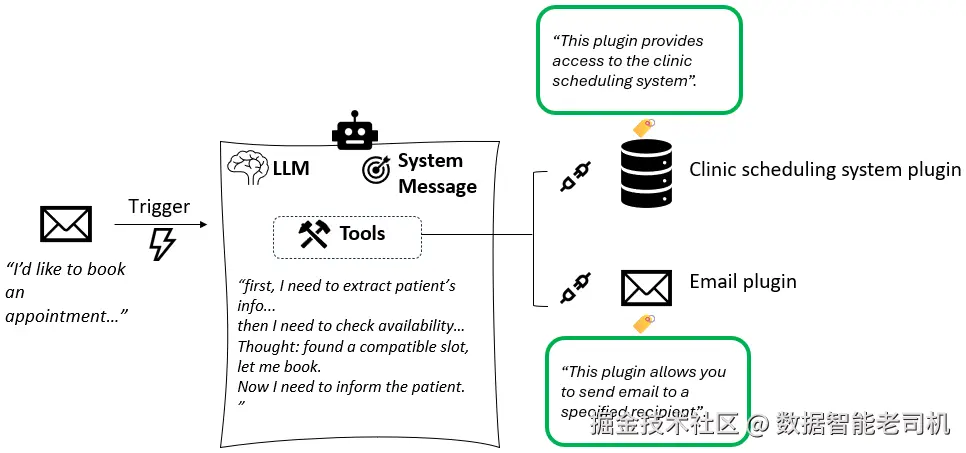
其强大之处在于:语言模型理解自然语言。每当一个工具/组件(例如“预订会议”操作)被注册,它不仅仅由底层逻辑(如调用某 API 的 POST 请求)定义,还会配有一段自然语言描述,用清晰的文字说明该工具做什么、返回什么。LLM 会读取这些描述,并据此决定何时/如何在任务中调用工具。本质上,模型不仅在执行代码,更在基于人类可读描述对可用动作进行推理与选择。
图 2.3:以自然语言描述代理组件的示例
因此,当用户提出请求时,代理(以 LLM 为“大脑”)会遍历所有组件描述,判断应调用哪一个来解决问题。
实践中,我们可以为“如何调用合适的工具”定义不同策略。例如,你可能希望某个工具总是先被调用,然后再由代理决定是否需要追加其他工具。应对这种规定次序的一种方式,是直接写入系统消息。例如:
这些策略由编排器层进行定义与落实,第 3 章将进一步说明。
AI 智能体在复杂度与能力上各不相同,从简单的检索型代理到完全自主系统不一而足。理解这些类型有助于组织与开发者为特定用例选型。本节我们将把 AI 智能体归为三大类:检索型代理(retrieval agents) 、任务型代理(task agents)与自主型代理(autonomous agents) 。
在第 1 章中,我们介绍了 RAG(检索增强生成) :在生成回答前,LLM 会先从已正确嵌入并存储于 向量数据库(VectorDB) 的知识库中检索相关文档或片段。
检索型 AI 代理建立在 RAG 的基础上,但引入了更先进的代理式行为,使其更具自主性与适应性。实际上,我们在标准 RAG 流水线之上增加了一层智能与规划,让代理可以为“如何检索到最相关的信息”制定策略。
注(Note)
检索型 AI 代理常被称为 agentic RAG。在这种方法中,知识源被视为“工具(tools) ”,即每个来源都配有一段自然语言描述,从而使代理可依据用户查询决定调用哪一来源。一旦调用,具体检索机制与传统 RAG 相同;不同之处在于,新增的智能层可以判断当前信息是否足够,必要时继续调用其他来源。
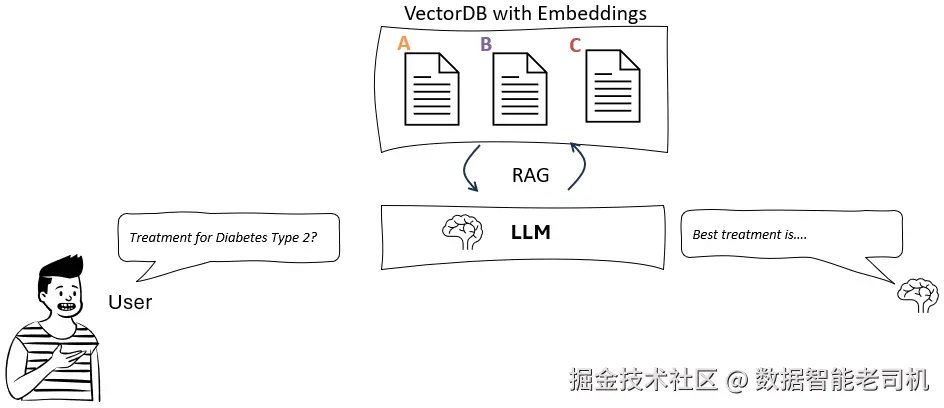
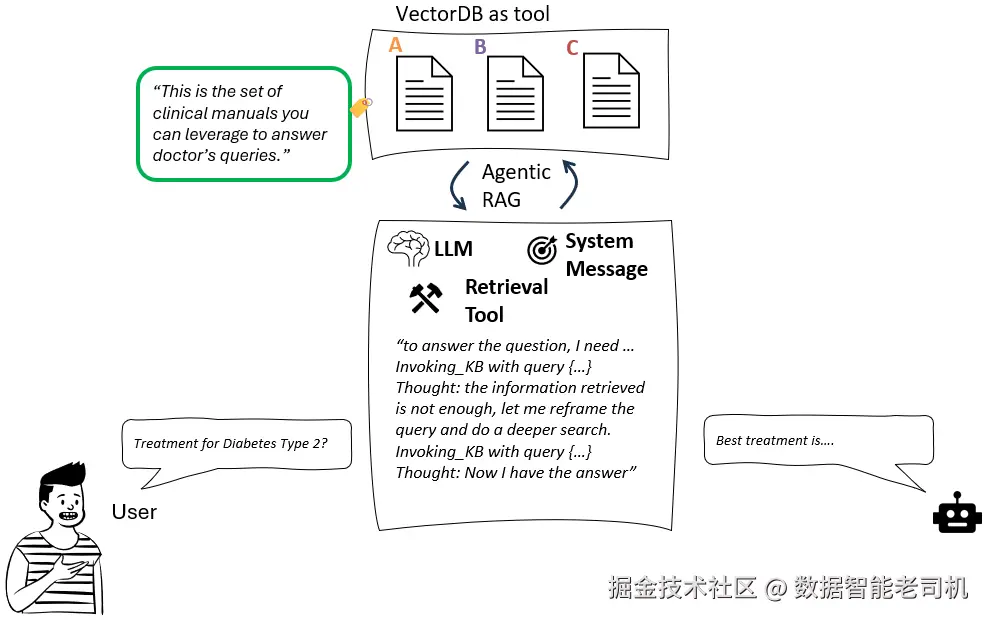
示例:我们希望为医生构建一个能快速检索治疗方案的 AI 助手。医生提问:“2 型糖尿病的最新治疗方案有哪些?”来看两种方法的对比:
传统 RAG 方法:
图 2.4:传统 RAG 流水线
检索型 AI 代理方法:
图 2.5:Agentic RAG 流水线
小结: 与传统 RAG 相比,agentic RAG 带来多方面改进:
检索型代理是最基础的 AI 代理形态,但这层额外的智能已显著改善用户体验。然而,AI 代理的真正威力在于将检索能力与可执行任务相结合——这一点将在后续的任务型与自主型代理中体现。
任务型代理不止于信息检索,它们会执行具体动作。此类代理旨在自动化工作流、替代用户的重复性操作。与检索型代理不同,任务型代理会根据用户指令或外部触发器执行预定义的动作。
注(Note)
在谈到 AI 智能体时,你常会听到 tasks、tools、skills、plugins、functions、actions 等术语,常被交替使用来指代代理“能做事”的能力。不同的编排平台对术语也各不相同。下面做个简要厘清:
get_weather 函数可以返回某地的实时天气。让我们继续看一个医疗领域的示例,这次从全科诊所前台接待员 John 的视角出发。
John 需要处理大量预约请求。病人通过电话、邮件与线上系统预约。处理临时取消与改期非常耗时,也常导致排班出现空档。
John 一天的典型流程可能如下:
本质上,上述步骤就是 John 为达成目标(为医生与病人找到最优时间)所需完成的一系列任务。
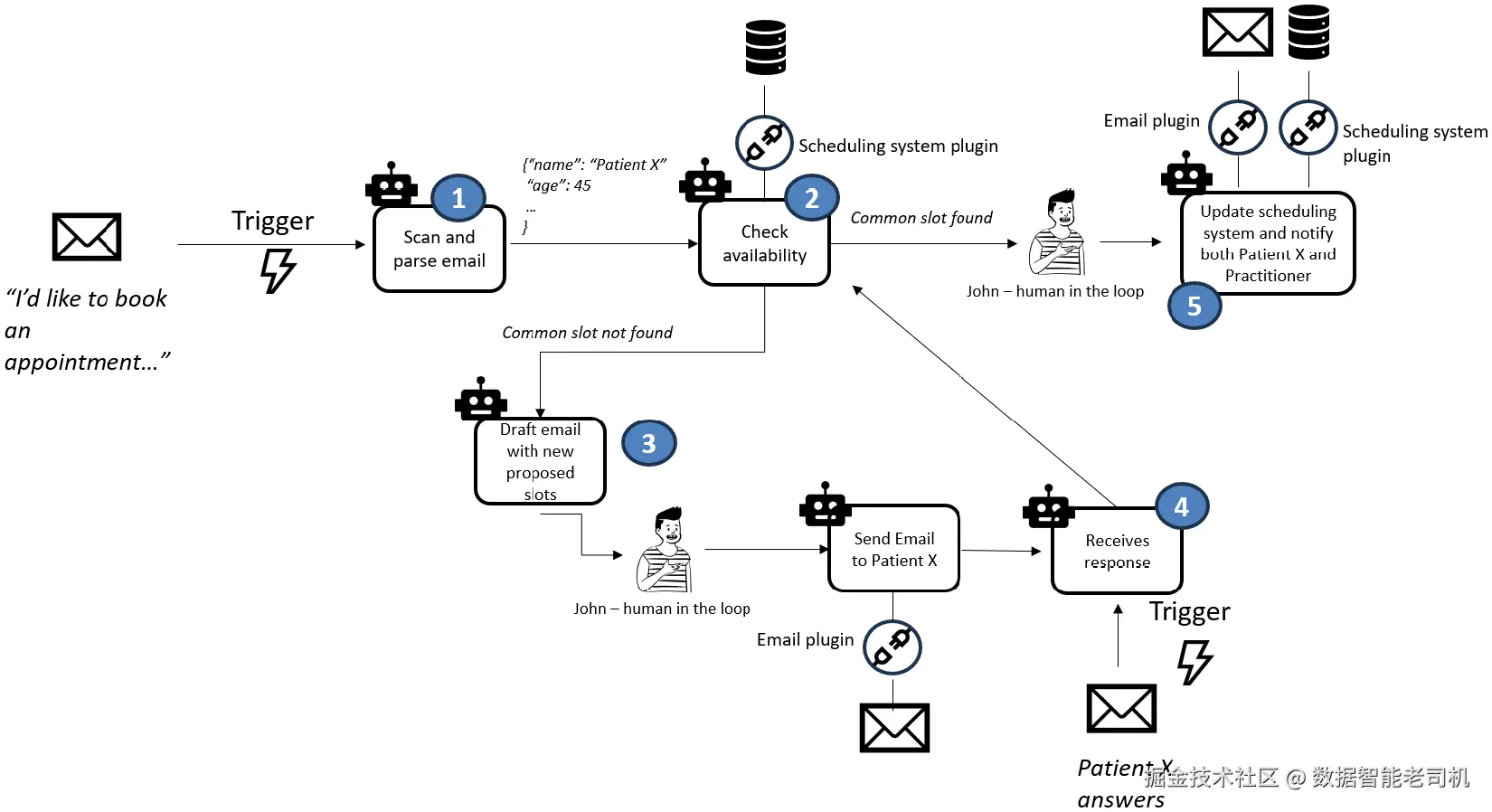
当我们希望用 AI 智能体(更具体地说,任务型代理)来映射并增强业务流程时,一个良好实践是把人的任务转化为代理的任务。例如,任务型代理可这样协助 John:
图 2.6:任务型代理如何执行一项任务
(提示:需要查看高清图?请在 next-gen Packt Reader 或本书的 PDF/ePub 版本中查看。购买本书可免费获得 next-gen Packt Reader。扫描二维码或访问 packtpub.com/unlock,搜索本书名称并确认版本。)
自动扫描邮件:代理读取来自病人 X 的邮件,提取关键信息(姓名与联系方式、偏好日期/时间、所需专科)。
检查可用性:代理调用诊所排班系统插件(即我们为代理配备的工具),将病人的偏好与该专科医生最早可用时段进行匹配;若匹配,跳至步骤 5。
生成备选并拟稿:若无匹配,代理基于医生日程生成最优备选时段列表,并借助写作技能起草给病人 X 的回复邮件(由 John 审核后发送)。
病人反馈:病人 X 提出新偏好,并且要么
落地预约与通知:John 与病人 X 达成一致后,代理再次使用上述插件在系统中创建预约,并通过邮件插件发送确认邮件给病人 X;同时更新医生日历并通知其预订信息。
图 2.7:面向诊所的任务型 AI 代理“解剖图”示例
如你所见,AI 代理就像 John 的助理,代为处理重复的排班任务,从而让他把精力集中在线下接待与服务上。
自主型代理是最先进的一类 AI 智能体。不同于在预设边界内运行的检索型与任务型代理,自主型代理能够战略性编排多项任务与检索流程,实时决策以优化工作流。它们具备高度的独立性、适应性与情境感知,因而可在最少人工干预下完成复杂操作。
自主型代理的关键区别在于其能够:
继续以 John 的诊所为例。随着诊所业务繁忙,管理预约、取消与改期变得愈发吃力。任务型代理已能简化单个动作,但现在自主型代理在极少监督下接管端到端的排班流程。其逐步工作方式如下:
该自主型代理能规划、检索、决策、行动、适配与学习——而无需依赖预定义的固定流程。John 只需聚焦边界案例,其余由代理智能处理。
自主型代理代表着 AI 驱动流程自动化 的下一步。通过将检索式 AI 的能力(情境感知、实时检索细化)与任务执行技能(预约排班、自动通知)相融合,自主型代理能够从根本上重塑业务流程与日常运营。
注(Note)
尽管自主型代理与业务流程自动化的概念高度契合,但它们同样能为客户体验带来新提升。以上述场景为例,病人 X 无需电话或邮件,可直接使用代理提供的对话式界面(如诊所网站或 WhatsApp 渠道)。在此过程中,代理捕捉意图、在需要时追问补充信息,并在后台编排各系统执行任务,从而带来更顺畅的交互体验。
我们可以为代理设定不同程度的自主性;取舍取决于业务场景以及我们对解决方案准确度的信心。
AI 智能体已从基础自动化工具进化为复杂的自主系统,重塑业务运营与专业工作流。本文介绍了三种主要类型:
针对每个用例部署合适类型的 AI 代理,是实现高影响力自动化与优化用户体验的关键。
从下一章开始,我们将更深入剖析 AI 智能体的各个组成部分,首先从**AI 编排(orchestration)**入手。
40.28MB · 2025-12-18
103.24MB · 2025-12-18
102.63MB · 2025-12-18

