
缘之空安卓版汉化
1435MB · 2025-12-24

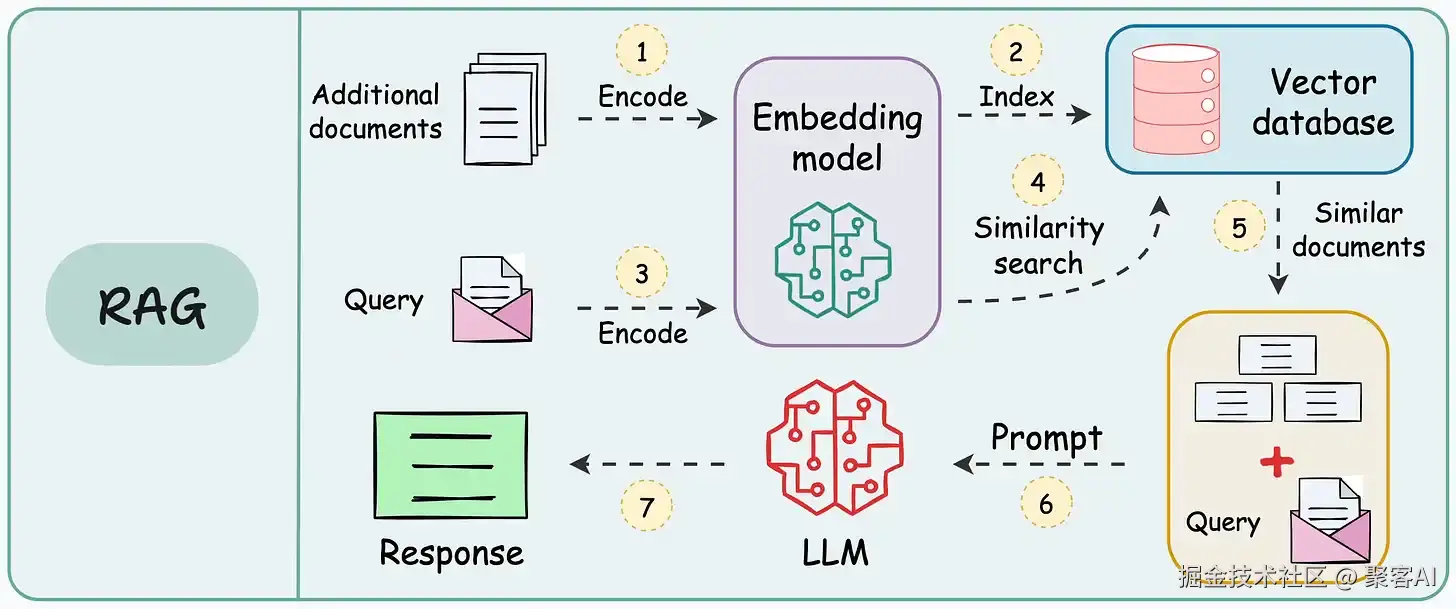
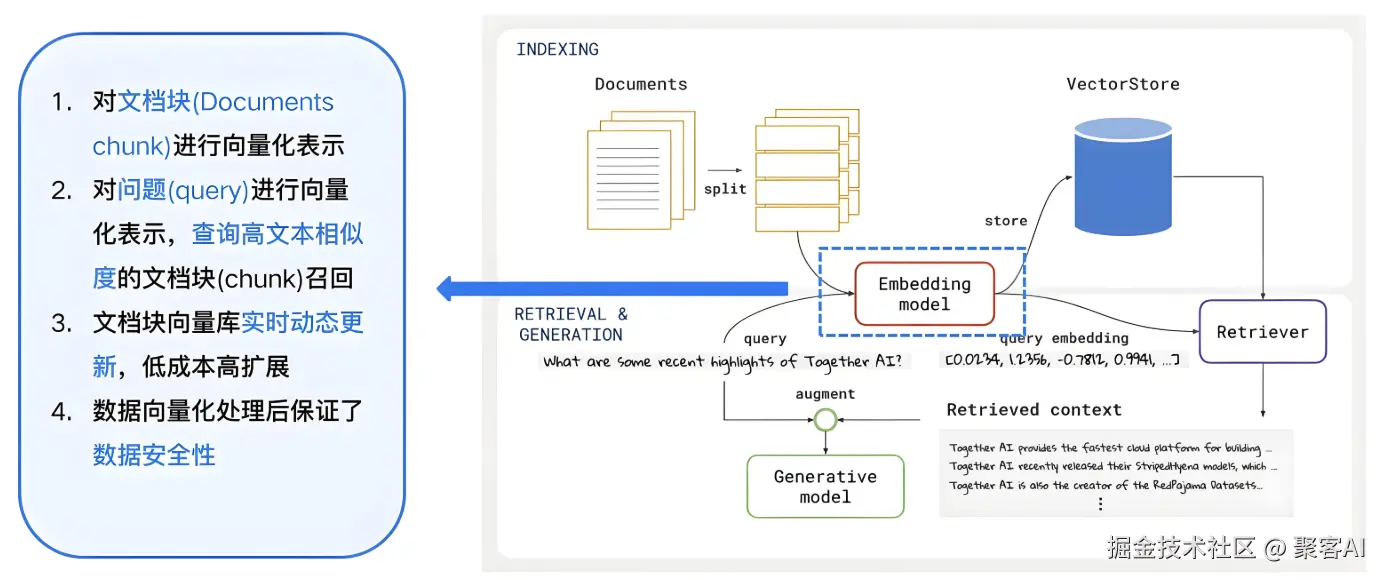
在RAG(检索增强生成)系统开发中,技术选型与场景适配的合理性直接决定系统性能。今天我将基于企业级实践经验,系统化拆解开发全流程的十大关键误区,并提供四维优化框架,助力开发者构建高精度、高可用的RAG系统。如果对你有所帮助,记得告诉身边有需要的朋友。
| 误区 | 典型场景案例 | 核心影响 |
|---|---|---|
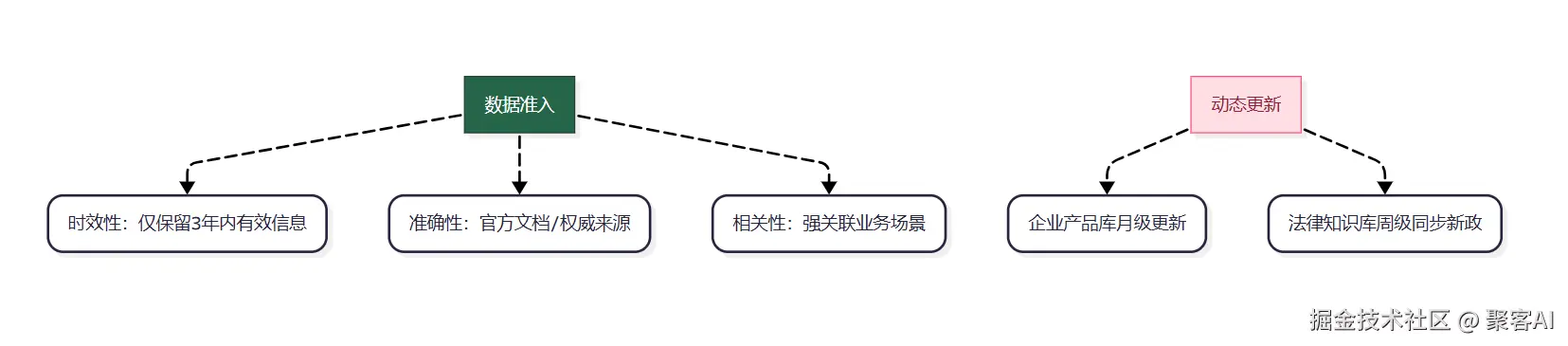
| 盲目堆砌低质数据 | 企业产品库混入历史版本参数,导致检索结果过时 | 知识相关性↓,用户体验恶化 |
| 文本拆分粒度失当 | 教育教案整段拆分,检索时夹杂无关知识点 | 生成结果冗余或语义断裂 |
| 缺失动态更新机制 | 政务系统未同步2024年社保新政,回答法律效力失效 | 知识时效性丧失,系统可信度崩塌 |
| 误区 | 典型场景案例 | 技术根因 |
|---|---|---|
| 通用算法未场景适配 | 法律场景中BM25算法无法精准匹配法条结构化特征 | 漏检率↑,误检率↑ |
| 过度追求召回率 | 医疗系统召回90%高血压知识但含30%无关内容 | 生成答案掺杂错误信息,医疗风险↑ |
| 默认嵌入模型未调优 | 金融术语(如PE估值)向量表征偏差 | 语义相似度计算失真,检索精度↓ |
| 忽视查询意图解析 | 用户问"手机充电慢"未识别"安卓硬件排查"需求 | 检索目标与需求错位 |
| 误区 | 典型场景案例 | 后果 |
|---|---|---|
| 缺失知识约束机制 | 大模型将"1年保修期"错误生成"2年" | 知识脱节导致事实性错误 |
| 误区 | 典型场景案例 | 长期影响 |
|---|---|---|
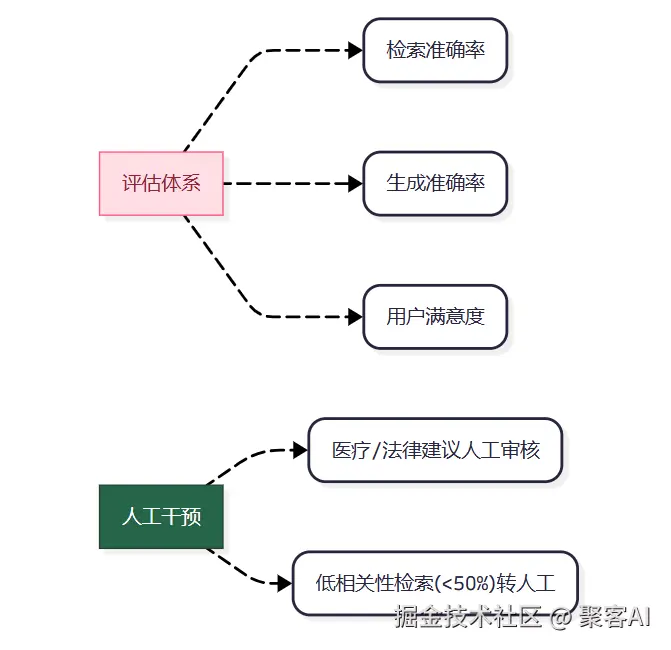
| 缺乏量化评估体系 | 仅凭主观感受判断效果,无法定位检索/生成模块瓶颈 | 优化方向迷失,迭代效率↓ |
| 过度追求全自动化 | 法律建议生成未设人工审核,输出歧义条款 | 高风险场景可靠性危机 |
关键策略:
算法适配
嵌入模型调优
意图理解增强
# 查询优化伪代码示例
def query_optimize(user_query):
intent = classify("事实查询/问题解决/信息推荐") # 意图分类模型
if intent == "问题解决":
return expand_query("安卓手机充电慢硬件排查") # 术语补充引擎
核心机制:
| 维度 | 核心原则 | 落地价值 |
|---|---|---|
| 数据 | 质量>规模,动态>静态 | 保障知识源头可靠性 |
| 检索 | 场景适配>算法默认,精度>召回 | 提升需求-知识匹配效率 |
| 生成 | 知识约束>模型自由发挥 | 杜绝事实性错误 |
| 系统 | 量化驱动+人机协同 | 实现可持续性能进化 |
由于文章篇幅有限,关于RAG的优化和RAG的评估我之前也整理了一个5W字的技术文档,这里就不过多去讲了,感兴趣的粉丝朋友可以自行领取:《检索增强生成(RAG)技术文档》,好了,今天的分享就到这里,点个小红心,我们下期见。

