






有道开口读最新版
627.12MB · 2025-12-23

?Hello,早上好呀各位!
今是2025年08月30日上午九点钟?,昨晚睡得比较早,今天也起得早,自从前几周颈椎不好之后,小编现在为了狗命,早睡早起,保命要紧❗
然后呢,终于有时间来和大家分享上周日去参加 TRAE 深圳场 Hackathon 活动的精彩经历啦!整个周末过得非常愉快和充实。
但是,回来后这一周公司业务实在有点忙?,所以,这篇文章来得有点晚,但正所谓 "虽迟但到" 嘛!记录一下,记录一下哈。
虽然,活动周日才开始,但是,周五下班后小编就高铁闪现过去了,先去大学舍友的 Base Home 暂住。
为什么来得那么着急?这可不是为了玩哦,全是为了健康,医生让小编多户外活动,少低头玩手机?。所以呢,寻思着周六可以去爬一爬梧桐山,看看这山有多高,嘿嘿。
周六和舍友一起去爬梧桐山,但由于他起得比较晚(真不赖我,俺八点左右就醒了?),我们中午12点才出发,稍微有点着急了。建议下次要爬山通关的话,最好还是上午来,这样就可以慢慢享受沿途的风光。?
顺便记录一下路线,我们是从梧桐山南站下的地铁,从凌云道开始往爬上,经过深圳电视塔,再从十里杜鹃到好汉坡,然后登顶往鹏城第一高峰,最后从泰山涧下山到北大门的。其实,应该要从秀桐道下山的,可惜,天有点晚了。
附图一张:

活动行程是从上午十点半到晚上六点,安排得相当满呢。
其实,最后应该是晚上六点四十多分才结束,因为参加路演的大佬太多了?,时间有点不够。可惜,小编高铁买的票比较早,所以,六点钟俺就提前撤了,最后的评审与颁奖过程就没有参与。(虽然获奖也没有俺?)
活动从上午十点半开始,主理人介绍背景、活跃气氛、用户破冰,让大家认识各位大佬。
来参加的人员好像说有120人左右,参与者包括字节的大佬们、行业牛人、各公司CEO和创业者、还有其他大厂高手。?
比较有意思的是,主办方还邀请了小学生、初中生、大学生等在校生前来,小编记得有名清华学子就坐在我旁边!?
然后,其中最小的参与者好像才12岁,大家都非常有才华。都在台上踊跃地介绍着自己,小编作为小喽啰,只偷摸蜷缩在角落安静地听着。
小编也是第一次吃上字节跳动这家行业顶级大厂的饭啦!挺好吃,还量多管饱,哈哈哈。?
再附图一张:
吃饭期间可以自行去和大佬们互动交流,大家人都非常友好的。正如一个 "黑客松" 主理人说的,其实过来参加活动,咱们的目标不是做项目参赛拿奖,更重要的应该是去和别人交流、学习、成为朋友。这里的人基本都可以算是未来或者现在的行业精英了,认识他们比拿奖更有价值。?
Em...有道理吧,可惜小编是一个社恐的I人。。。。。。
本次活动主题是:用 TRAE SOLO 模式 "现场" ? 做一个产品,然后由评委现场打分。
时长是三个小时,从下午一点到四点,这时候你就可以尽情将你的想法展现出来,然后由 TRAE 落地实现它!
然后,继续附上动图一张,如下:
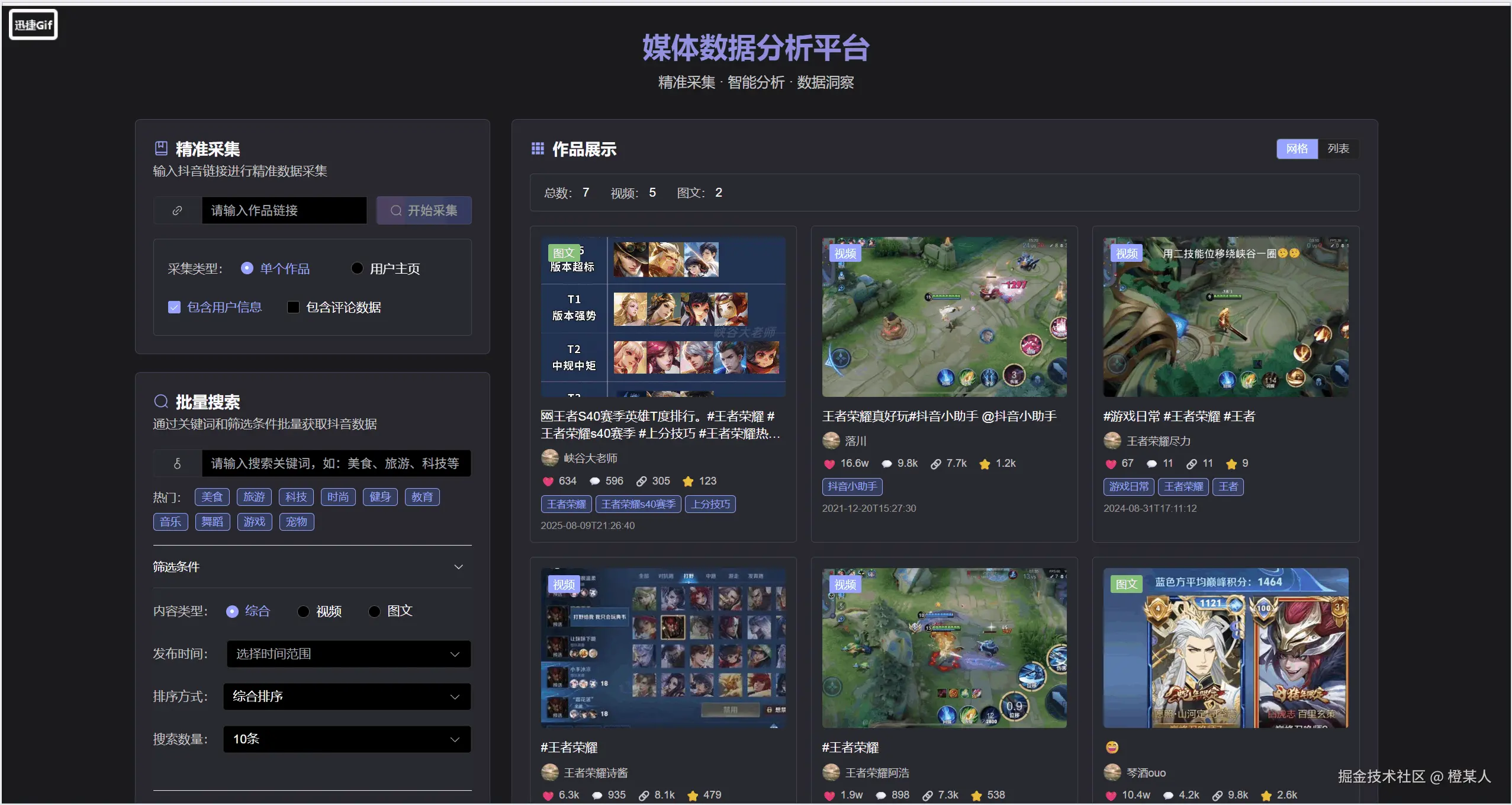
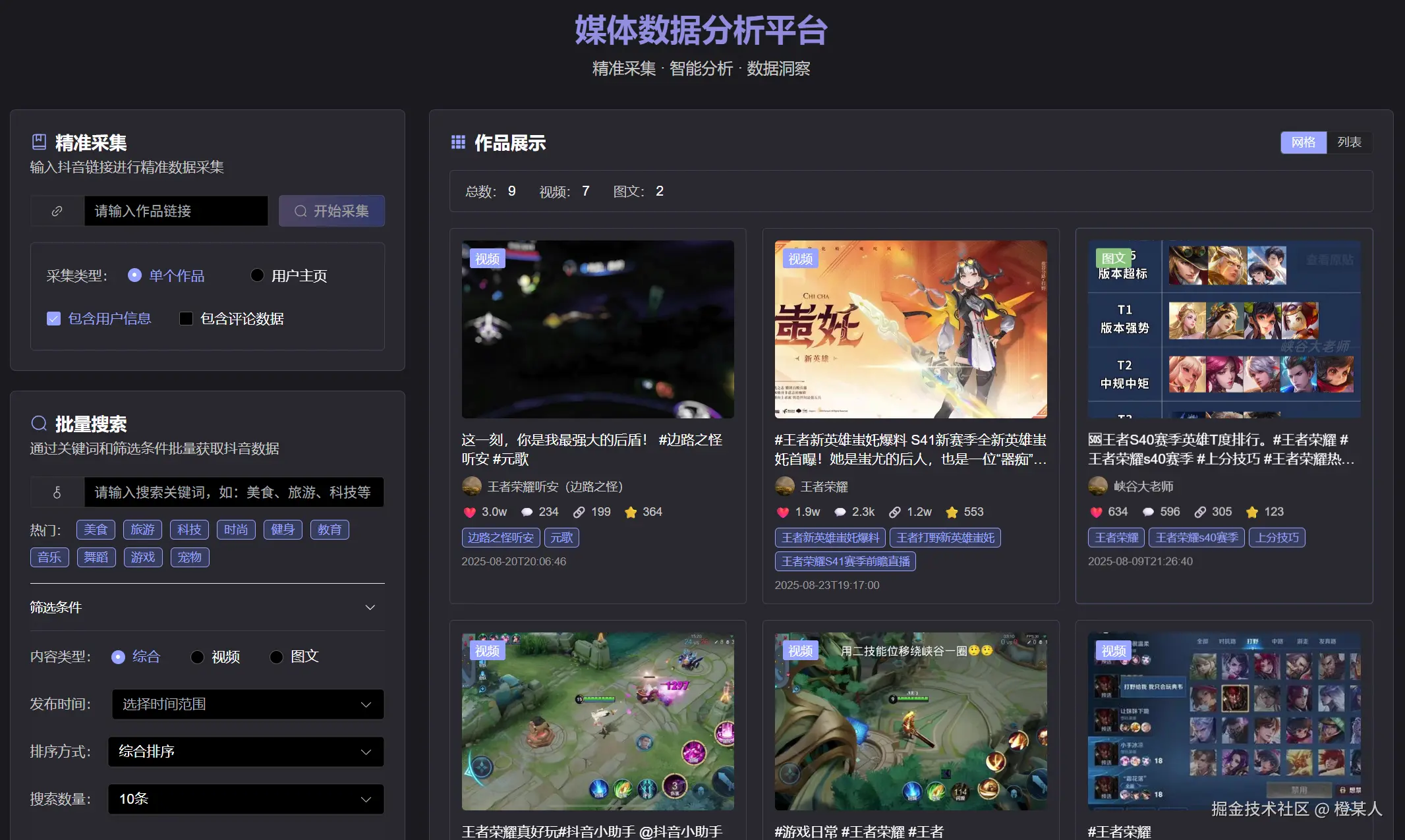
这是小编现场做的一个小功能,三个小时让AI撸出来的产品。
接下来,咱们就来介绍一下整个产品从想法到实现的过程。
小编在报名参加活动的时候,就一直在构思要做什么。想法有非常多,但由于自己本身就是一个程序员,考虑到短短三小时的时间限制,很多比较庞大不切实际的想法自己脑中就 PASS 了。
最终,选择了"媒体数据分析平台"这个想法,灵感来源于小编的新媒体同事的需求,她们经常需要分析媒体爆款内容,但手动收集数据效率太低,缺乏系统化的分析工具,这算是其中最小一个MVP的尝试。
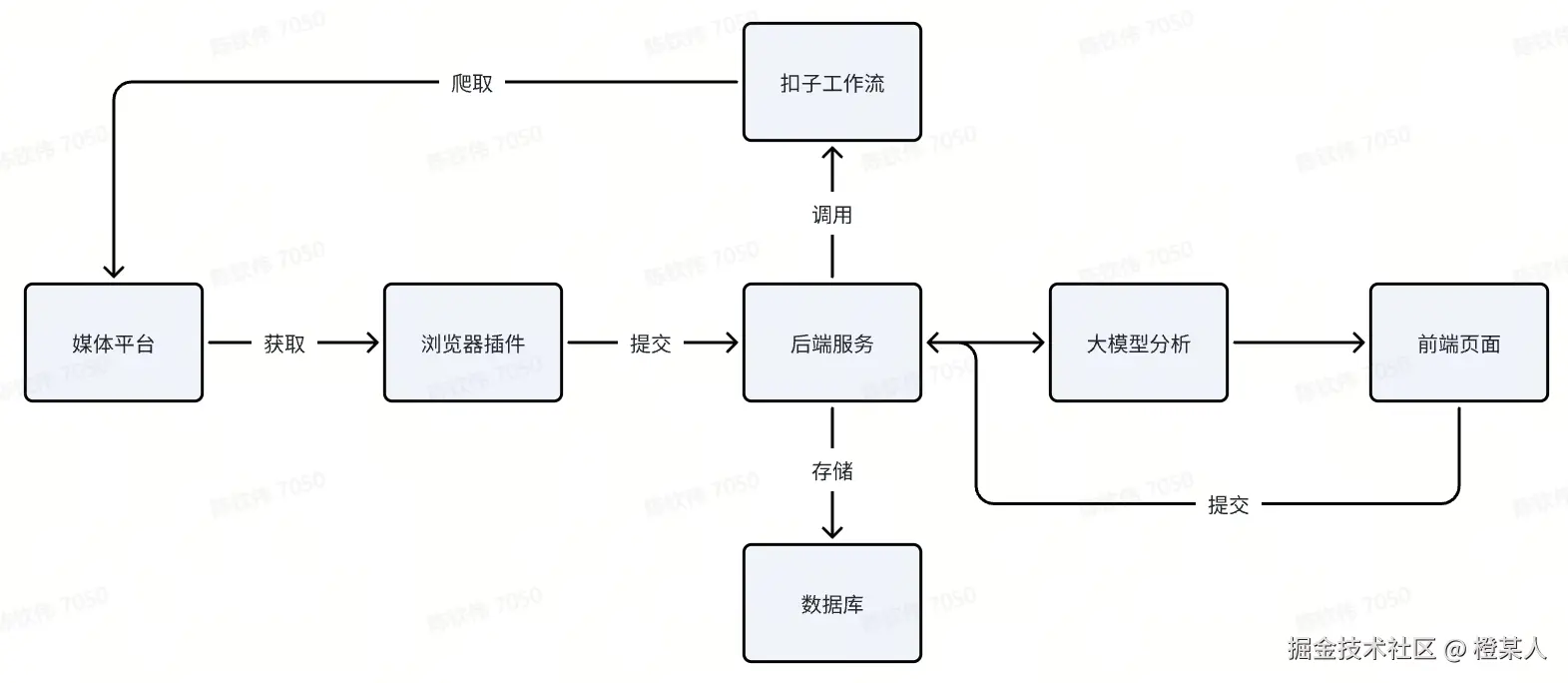
媒体数据分析平台是一个专为新媒体团队打造的数据洞察工具,通过集成扣子工作流(爬虫),实现对抖音、快手、小红书、微博等媒体平台的作品/帖子的自动化数据采集、存储和智能分析。
解决的痛点:
原本的设想是一个完整的系统,包括:
流程图:
但由于太复杂了,最终只选择实现最核心的能力。
技术栈:
前端:Vue3
后端:Python
数据库:SQLite
爬虫:扣子工作流
?为什么选择SQLite数据库呢❓
当时小编以为参赛源码需要提交,为了方便其他人能快速跑起来这个项目,就使用了这种文件类型的数据库,日常小编使用Mysql数据库偏多,没想到,在现场反而数据库这方面折腾了比较多的时间。?
?关于爬虫方案,为什么选择用扣子的工作流来实现❓
一开始是想自己写爬虫来爬取的,但是可能耗时会比较久,所以就选择使用扣子的工作流更便捷。在扣子平台上,小编设计了一个简单但高效的工作流,就三个节点:
?还有,小编项目中前后端项目是分离成两个项目,这是为什么❓
很多人说前端项目与后端项目放一起会比较好,AI容易对接前后端,但小编却不这么认为。在现在AI还是L3的时代,我觉得还不能把项目全交由AI来完成。要不做出来的产品,绝对不是你所期望的,分离、分步才是王道。
如果你想做一个玩具产品,或者验证产品最小MVP,那么完全交由AI是可以的。但小编始终认为现在用AI来做项目,你最好还是要人为把控项目的整体情况。
不管是前端还是后端项目,虽然尝试要All in AI,但绝不可放飞自我,全交由AI。开发人员(非开发人员当我没说?)应该对整个项目有一个基础的把控,比如项目的架构、整体走向、规范、选型、模块的划分以及风格等等。开发人员始终得是"掌舵人" 。?
由于咱们这个媒体数据分析系统目前就一个页面,让AI来完成页面开发基本就没什么压力了。?
小编大致给AI描述了一下页面上都有什么功能,比如,我提到有精准采集与批量采集功能,精准采集主要就是让用户填一个链接信息......,反正就是用自然语言描述了一下页面的样子与交互过程。
然后,TRAE 会给我生成一个需求文档,一般大体是满足的。但是,AI会想得比较全面,会扩展比较多的内容。此时,我会自己看看需求文档,进行二次修改,得到最终期望的需求,再让AI去执行。
不过,还有一些小技巧,例如,项目初始化这块。
小编一般会选择自己手动用 Vite 初始化项目结构,再规划项目目录,然后再手动去安装需要的依赖(element-plus、unocss等等),并将Vue、element-plus等依赖配置成按需引入。
为什么要这么做呢??
其一,小编自己是前端出身,做这些事情更得心应手,并且,项目结构会是自己平时习惯的样子。
其二,很多时候,这些项目基建工作的事情交给AI来做,效果可能不尽人意,都说开头难,AI也一样,那还不如自己手动来干。
还有,有时让AI单独做前端的时候,很多时候AI可能会顺便帮你把后端也给干了,虽然结果可能是错的。
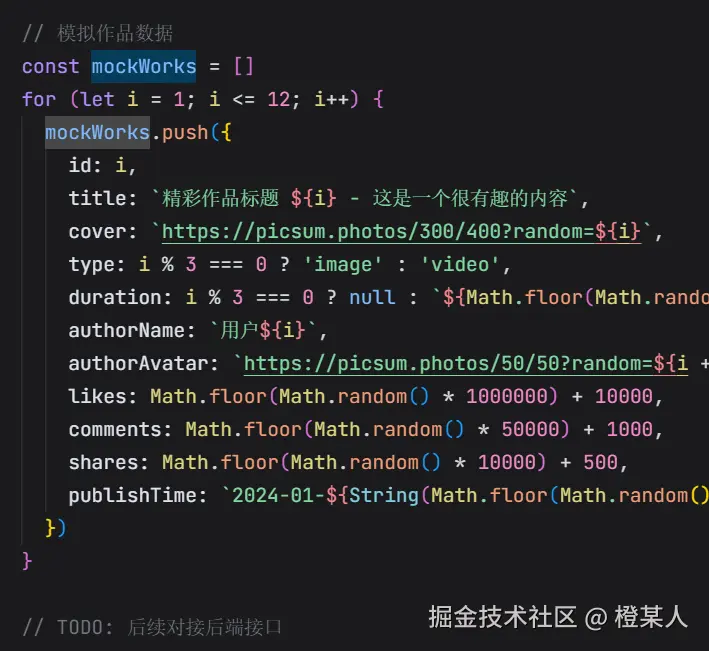
这时,你可以强调告诉它,只让它完成前端部分的开发,需要数据的时候,可以自行进行Mock数据,但要留出后续对接接口的情况。
还有,还有,有时小编会手动介入去修改代码,但会选择性介入,比如,页面改个背景色,改个边距,改个图标等等,这对于前端的我来说,不过就是顺手的事情,这咱就不会去劳烦AI出手啦。?
后端这块小编选择了 Python + Quart 的技术栈。
首先,小编给AI规划了项目的架构情况:
├── src/
│ ├── __init__.py
│ ├── core/ # 核心配置
│ │ ├── config.py # 配置管理
│ │ └── database.py # 数据库连接
│ ├── models/ # 数据模型
│ │ ├── __init__.py
│ │ └── works.py # 作品模型
│ ├── repository/ # 数据访问层
│ │ ├── __init__.py
│ │ └── works_repository.py
│ ├── service/ # 业务逻辑层
│ │ ├── __init__.py
│ │ └── works_service.py
│ ├── route/ # 路由层
│ │ ├── __init__.py
│ │ └── main_route.py
│ └── common/ # 通用工具
│ ├── __init__.py
│ └── response.py # 统一响应格式
│── main.py # 应用入口
└─ ...
然后,我会告诉它按我这个项目结构初始化项目,但依赖还是我自己来执行:
pip install -r requirements.txt
因为,我不想它折腾半天。等项目初始化完成后,我会让它先写一个健康探针的接口,并启动项目,这样子我能确定项目是否能被成功启动。
from quart import Blueprint
from src.common.utils.response_helper import ResponseHelper
from src.common.utils.logger import log
response = ResponseHelper()
healthy_route = Blueprint('healthy', __name__)
# cicd探针接口
@healthy_route.route('/healthz', methods=['GET'])
async def healthz():
log.info("健康检查接口被调用")
return response.success(
data={'status': 'ok', 'service': '服务健康'},
message="服务运行正常"
)
之后,小编才会进入业务接口的开发。
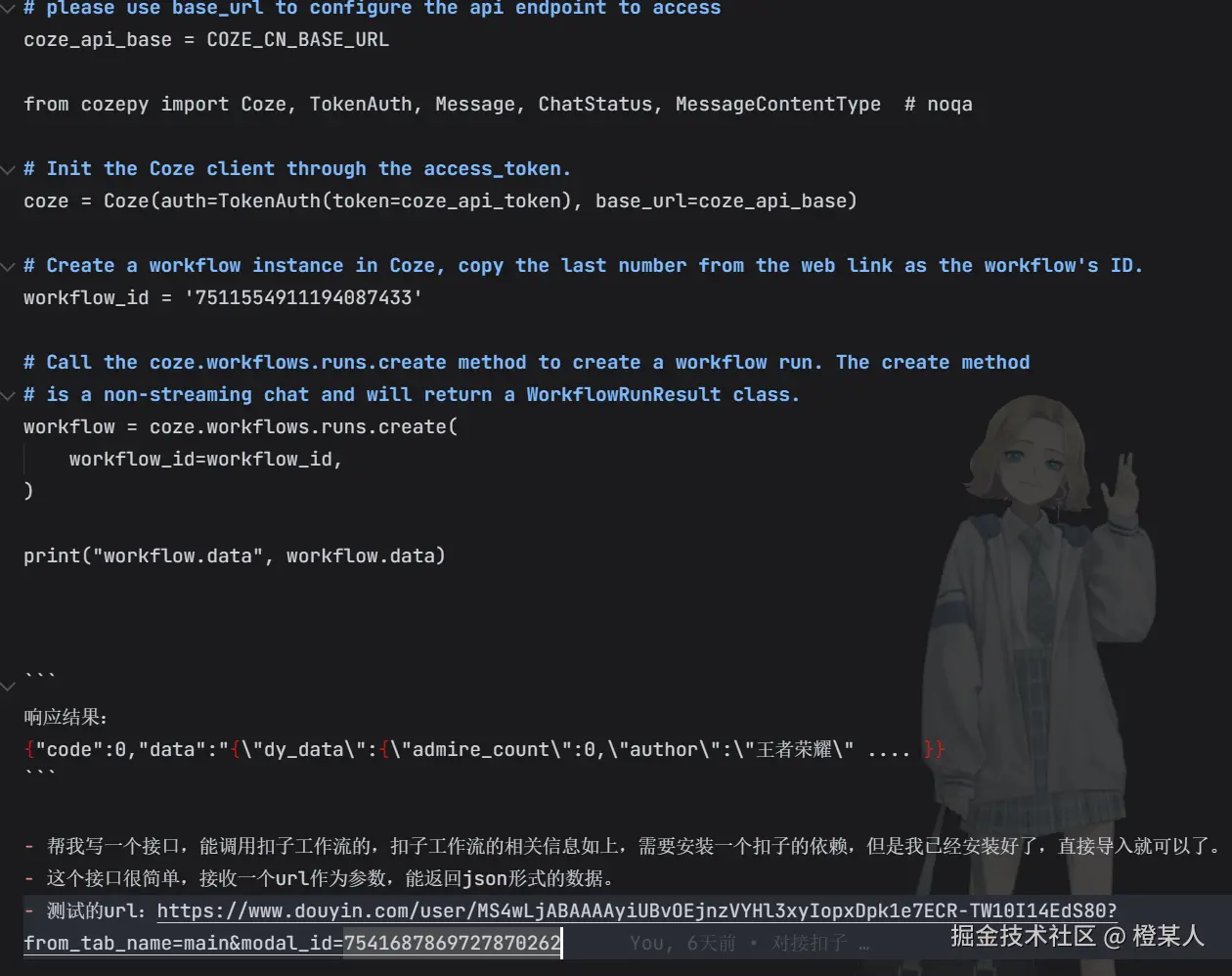
?第一个接口是:接收用户从前端提交的作品链接,然后调用扣子工作流爬取数据,再将数据存储到数据库中。
这个接口的编写过程小编分成两步让AI实现:
扣子工作流API调用过程来源于扣子文档的介绍,直接复制过来丢给AI作为上下文就行。
这种分步实现的方式,虽然比较麻烦,但也有好处:降低复杂度、成功率更高、便于调试、减少返工等等。
小编个人感觉这种开发策略才比较适合AI编程,因为AI在处理复杂的多步骤任务时容易出错,分步实现能大大提高开发效率和代码质量。 ?
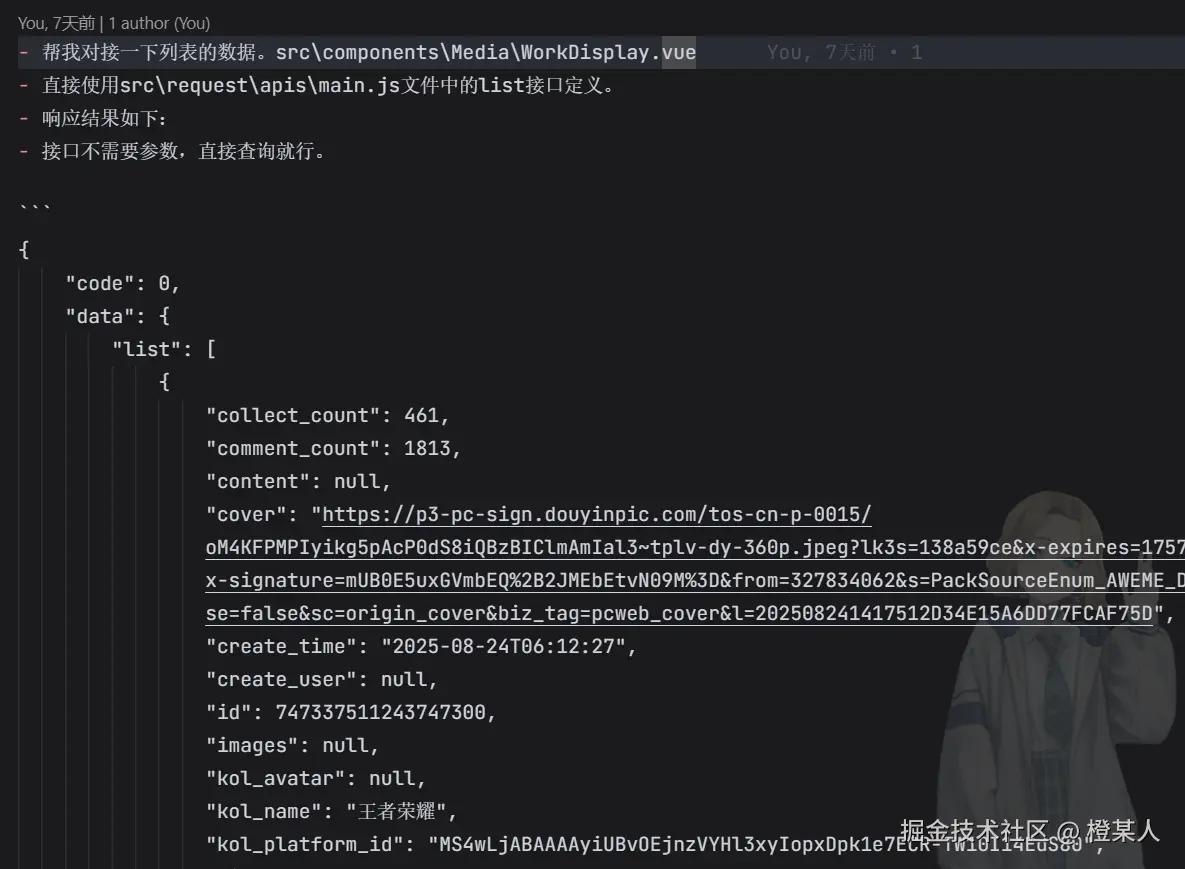
接口开发完成后,接下来就是激动人心的前后端联调环节了!? 这个阶段可以说是见证奇迹的时刻,前端的页面终于要和后端的数据产生化学反应啦。?
很早很早之前我就一直用AI在辅助开发了,其中发现一个现象:
后端接口的稳定性 ?
前端交互的复杂性 ?
现在,咱们来看看当时现场小编是如何写得提示词给AI作为上下文的。哦,当时的项目情况是前后端都已经能单独启动了,并且前端能正常调用后端服务,这是手动调试的,因为前端一般有封装好的网络模块,改改后端服务地址就行。
提交接口提示词:
列表接口提示词:
联调成功的关键要素:接口输入的参数说明与接口输出的响应格式。
有这两点就够了,其他的AI能够自行领悟自通的。?
这一小节记录一下小编当时耗时较多的问题场景。
?问题一:扣子工作流对接
小编需要在Python服务中对接扣子工作流,用户填了作品详情链接后,Python服务需要调用扣子工作流的接口,把链接传过去,然后获取数据。
对接这块,小编已经从扣子中获取了对接的形式给到 TRAE,但它一直没有成功,折腾了相当多的时间。
最终的Python代码:
from quart import Blueprint, request, jsonify
import asyncio
import json
from cozepy import COZE_CN_BASE_URL, Coze, TokenAuth
from src.service.works_service import WorksService
# 创建蓝图
main_route = Blueprint('main_route', __name__)
# 扣子API配置
coze_api_token = ''
coze_api_base = COZE_CN_BASE_URL
workflow_id = '7511554911194087433'
# 初始化Coze客户端
coze = Coze(auth=TokenAuth(token=coze_api_token), base_url=coze_api_base)
@main_route.route('/api/coze/workflow', methods=['POST'])
async def call_coze_workflow():
"""
调用扣子工作流API接口
接收URL参数,返回抖音视频数据
"""
try:
# 获取请求数据
data = await request.get_json()
# 验证参数
if not data or 'url' not in data:
return jsonify({
'code': 400,
'msg': 'Missing required parameter: url',
'data': None
}), 400
url = data['url']
# 调用扣子工作流
workflow = coze.workflows.runs.create(
workflow_id=workflow_id,
parameters={
'dy_share_url': url
}
)
# 处理响应数据并存储
if workflow and workflow.data:
try:
works_service = WorksService()
full_response = {
"code": 0,
"data": workflow.data,
"msg": "Success"
}
response_json = json.dumps(full_response)
saved_work = await works_service.save_douyin_work(response_json, url)
print(f"数据存储成功: {saved_work}")
except Exception as storage_error:
print(f"数据存储失败: {str(storage_error)}")
return jsonify({
'code': 0,
'msg': 'Success',
'data': workflow.data
})
else:
return jsonify({
'code': 500,
'msg': 'Workflow execution failed',
'data': None
}), 500
except Exception as e:
return jsonify({
'code': 500,
'msg': f'Internal server error: {str(e)}',
'data': None
}), 500
当时,小编看 SOLO 模式下的终端一直报错,查看代码发现也没啥毛病呀,很简单的逻辑,脑中寻思着开头就卡住了,和自己预估的有落差,就...紧张了,然后也没仔细去注意到达是什么错误,反正在那里让AI去自我修复。
最后,发现是没给测试链接(上面截图是有一个抖音链接的,是小编后面补的),AI就"贴心"自我虚拟了一个链接提交给了扣子的工作流,然后工作流报错,这个错误基本就是AI无法理解的,两者就陷入了僵持,你提交,我报错,你提交,我报错。。。
这其实也是一个比较常见的问题,当AI缺乏完整的第三方API信息,而网上相关资料又比较少时,很容易产生"幻觉"。
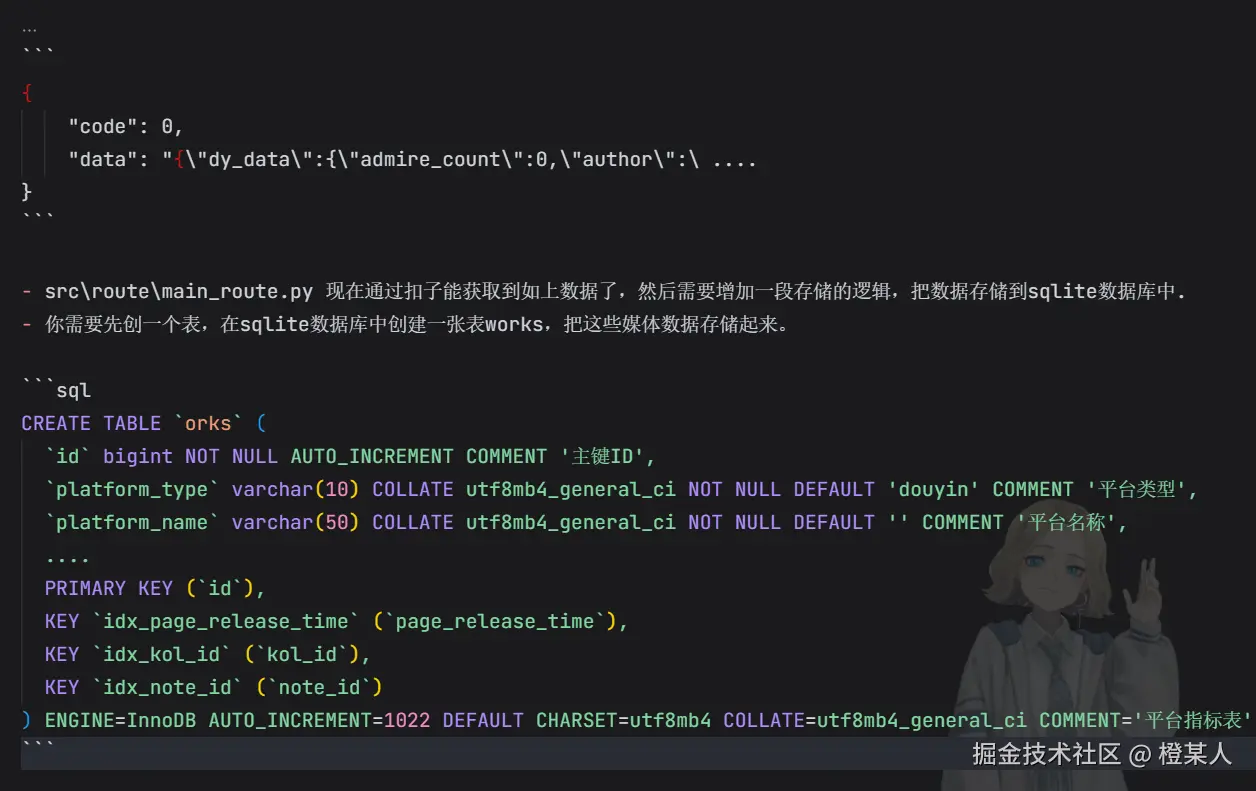
?问题二:SQLite存储问题
说实话,小编也没用过SQLite数据库。
在成功获取了数据后,一直存储不起来,从列表中一直查不出数据。
最后,发现原来是一直没有初始化数据库,没有表,所以存储不上。?♂️
?问题二:项目部署挑战
大概做到页面能提交用户填写链接、爬取回来数据、存储起来、从数据库中查询出来,这整体耗费了小编两个小时左右时间。
本来想继续做批量采集的,因为还有最后一个小时,后面应该会顺畅一些。
但后面小编从提交方式中得知最好要部署到 Vercel 上。
所以,就先果断放弃批量采集功能了,部署才是关键!毕竟不管做得好不好,总要给自己一个完整的交代,有始有终。?
前端部署:比较简单,和 TRAE 说一下要部署就部署上去了。小编很早之前就已经尝试过部署过前端,这还一样便捷! ?
后端部署:这里就有点麻烦了,第一次让AI帮忙部署Python服务到Vercel上,虽然前后耗时比较久,但是总算成功了。试了一下探针的接口是成功的,但奇怪的是,自己写的业务接口就访问不了,一直返回404。?
应该不是代码问题,本地都是正常的,感觉是Python版本的问题吧?反正就是让AI一直去修复,就是死活修复不了。
所以,最后无奈也只能放弃,提交作品的时候,只提交了一些录屏?、截图情况,也算是结尾啦。
之后,剩下一点时间就和旁边南网来的大哥闲聊了。
哦,还有,四点截止提交作品后,还有茶歇可以食,真不错?,附图一张:
最后呢,就是对自己项目有信心的大佬报名参加路演,等待评委的现场评分,当然,所有提交的作品,评委也会去看然后评分的。
小编的作品情况:
虽然功能相对简单,但这个"精准采集"的小功能算是比较完整地实现了预期目标。✨
整个活动产生的参赛的作品非常多,各路大佬的创意想法都非常新颖,让小编大开眼界!其中还有那个最小的小学生也获奖了呢!
这次 Hackathon 活动整体感受挺好的,感谢 TRAE 团队组织的这次精彩活动,也期望下次有机会再与各位大佬见面、学习。
踏上回广州的高铁?,看着窗外飞逝的风景,回想这两天的经历,真是一个愉快的周末!
同时,希望在未来的开发工作中,咱们要学会更好地与AI协作,发挥各自的优势,创造出更好的产品。?
至此,本篇文章就写完啦,撒花撒花。
希望本文对你有所帮助,如有任何疑问,期待你的留言哦。
老样子,点赞+评论=你会了,收藏=你精通了。

