
魔天记3d vivo客户端
374.22MB · 2025-12-16

详细可以查看:
基本数据类型:
score的参数来实现。适用于排行榜和带权重的消息队列等场景。特殊的数据类型:
相同点:
不同点:
BLPOP queue 0 //0表示不限制等待时间BLPOP和LPOP命令相似,唯一的区别就是当列表没有元素时BLPOP命令会一直阻塞连接,直到有新元素加入。
redis可以通过pub/sub主题订阅模式实现一个生产者,多个消费者,当然也存在一定的缺点,当消费者下线时,生产的消息会丢失。
PUBLISH channel1 hiSUBSCRIBE channel1UNSUBSCRIBE channel1 //退订通过SUBSCRIBE命令订阅的频道。
PSUBSCRIBE channel?*按照规则订阅。PUNSUBSCRIBE channel?*退订通过PSUBSCRIBE命令按照某种规则订阅的频道。其中订阅规则要进行严格的字符串匹配,PUNSUBSCRIBE *无法退订channel?*规则。
可以通过 List 类型 来实现 队列 和 栈
实现队列(FIFO):队列是一种 先进先出(FIFO)的数据结构。在Redis中,可以使用 PUSH 和 RPOP命令组合来实现队列。LPUSH 向列表的左侧推入元素,而 RPOP从列表的右侧弹出元素,这样可以保证最先进入的元素最先被弹出
实现栈(LIFO):栈是一种 后进先出(LIFO)的数据结构。在Redis 中,可以使用 LPUSH和 LPoP命令组合来实现栈。LPUSH 向列表的左侧推入元素,而 LPoP从列表的左侧弹出元素,这样可以保证最后进入的元素最先被弹出。
使用sortedset,拿时间戳作为score,消息内容作为key,调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理。
使用 Redis 实现排行榜的方式主要利用 Sorted Set(有序集合),它可以高效地存储、更新、以及获取排名数据。实现排行榜的主要步骤:
可以通过使用 位图(Bitmap)或使用 Redis 模块 RedisBloom。
Redis 中 HyperLogLog 结构,可以快速实现网页UV、PV 等统计场景。它是一种基数估算算法的概率性数据结构,可以用极少的内存统计海量用户唯一访问量的近似值。
Set 也可以实现,用于精确统计唯一用户访问量,但是但当用户数非常大时,内存开销较高。
Redis中的 Geo(Geoloaton的简写形式,代表地理坐标) 数据结构主要用于地理位置信息的存储,通过这个结构,可以方便地进行地理位置的存储、检索、以及计算地理距离等课作,GeO 数据结内存层使用了 Sorted set, 并结合了Geohash 编码算法来对地理位置进行处理。
Redis 中的 Sting 类型底层实现主要基于 SDS(Simple Dynamic string 简单动态字符串)结构,并结合 int、embstr、raw 等不同的编码方式进行优化存储。
详情请看这篇文章:
Ziplist:
Quicklist:
Redis 中的Zset(有序集合,Sorted set)是一种由 跳表 (Skip List)和哈希表 (Hash Table)组成的数据结构,Zset 结合了集合 (Set)的特性和排序功能,能够存储具有唯一性的成员,并根据成员的分数 (score) 进行排序
ZSet 的实现由两个核心数据结构组成:
当 Zset 元素数量较少时,Redis 会使用压缩列表(Zip List)来节省内存
如果任何一个条件不满足,Zset 将使用 跳表 +哈希表 作为底层实现,
这道面试题很多大厂比较喜欢问,难度还是有点大的。
平衡树 vs 跳表:平衡树的插入、删除和查询的时间复杂度和跳表一样都是 O(log n)。对于范围查询来说,平衡树也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。跳表诞生的初衷就是为了克服平衡树的一些缺点。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
红黑树 vs 跳表:相比较于红黑树来说,跳表的实现也更简单一些,不需要通过旋转和染色(红黑变换)来保证黑平衡。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
B+树 vs 跳表:B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过尽可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并。
跳表主要是通过多层链表来实现,底层链表保存所有元素,而每一层链表都是下一层的子集。
插入时,首先从最高层开始查找插入位置,然后随机决定新节点的层数,最后在相应的层中插入节点并更新指针
删除时,同样从最高层开始查找要删除的节点,并在各层中更新指针,以保持跳表的结构。
查找时,从最高层开始,逐层向下,直到找到目标元素或确定元素不存在。查找效率高,时间复杂度为 O(logn)
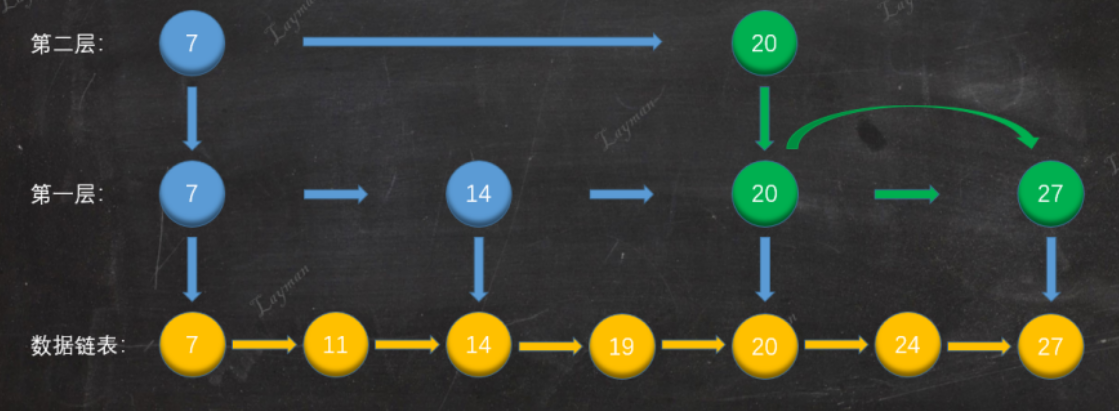
如果采用新增节点或者删除节点时,来调整跳表节点以维持比例2:1的方法的话,显然是会带来额外开销的。
跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。因为随机数取值在[0,0.25)范围内概率不会超过25%,所以这也说明了增加一层的概率不会超过25%。这样的话,当插入一个新结点时,只需修改前后结点的指针,而其它结点的层数就不需要随之改变了,这样就降低插入操作的复杂度。
// #define ZSKIPLIST_P 0.25int zslRandomLevel(void) { static const int threshold = ZSKIPLIST_P*RAND_MAX; int level = 1; //初始化为一级索引 while (random() < threshold) level += 1;//随机数小于 0.25就增加一层 //如果level 没有超过最大层数就返回,否则就返回最大层数 return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;}当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时, 我们称这些键发生了冲突(collision)。
关于解决hash冲突问题可以看这篇文章:
而redis是先通过拉链法解决,再通过rehash来解决hash冲突问题的,即再hash法,只不过redis的hash使渐进式hash
渐进式 rehash 步骤如下:
哈希表 2分配空间;哈希表 1中索引位置上的所有 key-value 迁移到哈希表 2上;哈希表 1的所有 key-value 迁移到哈希表 2,从而完成 rehash 操作。这样就把一次性大量数据迁移工作的开销,分摊到了多次处理请求的过程中,避免了一次性 rehash 的耗时操作。
在进行渐进式 rehash 的过程中,会有两个哈希表,所以在渐进式 rehash 进行期间,哈希表元素的删除、查找、更新等操作都会在这两个哈希表进行。比如,在渐进式 rehash 进行期间,查找一个 key 的值的话,先会在哈希表 1里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。新增一个 key-value 时,会被保存到哈希表 2里面,而哈希表 1则不再进行任何添加操作,这样保证了哈希表 1的 key-value 数量只会减少,随着 rehash 操作的完成,最终哈希表 1就会变成空表。
负载因子 = 哈希表已保存节点数量/哈希表大小
触发 rehash 操作的条件,主要有两个:
redis 的每个实例最多可以存放约 2^32 - 1 个keys,即大约 42 亿个keys。这是由 Redis 内部使用的哈希表实现决定的,它使用 32 位有符号整数作为索引。Redis 使用的哈希函数和负载因子等因素也会影响实际可存放键的数量。
需要注意的是,尽管 Redis 允许存储数量庞大的键,但在实践中,存储过多的键可能会导致性能下降和内存消耗增加。因此,在设计应用程序时,需要根据实际需求和硬件资源来合理规划键的数量,避免过度使用 Redis 实例造成负担。如果需要存储更多的键值对,可以考虑使用 Redis 集群或分片技术,以扩展整体存储容量。
本文来自在线网站:seven的菜鸟成长之路,作者:seven,转载请注明原文链接:www.seven97.top

