亚利桑那州立大学研究人员的新研究表明,大语言模型(LLM)中备受赞誉的"思维链"(CoT)推理可能更像一种"脆弱的幻象",而非真正的智能。这项研究基于越来越多质疑LLM推理深度的文献,但创新性地通过"数据分布"视角系统检验CoT失效的场景及原因。
对应用开发者至关重要是,该论文不仅提出批评,更为LLM应用的开发提供了清晰的实践指导——从测试策略到微调的作用——以应对这些局限性。
思维链的承诺与问题
要求LLM"逐步思考"的CoT提示法在复杂任务中展现出惊艳效果,使人误以为模型正在进行类人推理。但细究之下常暴露出挑战这一观点的逻辑矛盾。
多项研究表明,LLM往往依赖表层语义和线索而非逻辑程序。模型通过重复训练中见过的标记模式来生成看似合理的逻辑。但这种方法在面对偏离熟悉模板的任务或引入无关信息时往往失效。
尽管存在这些发现,新研究团队指出"对CoT推理何时及为何失效的系统性理解仍是未解之谜",这正是他们研究的重点。先前工作已证实LLM难以泛化其推理能力。如论文所述:"理论和实证证据表明,只有当测试输入与训练数据具有潜在结构相似性时,CoT才能良好泛化;否则性能急剧下降。"
LLM推理的新视角
ASU研究者提出新视角:CoT并非推理行为,而是一种受训练数据统计模式约束的高级模式匹配。他们假设"CoT的成功并非源于模型固有推理能力,而是其对于结构上类似分布内样本的分布外(OOD)测试案例的条件泛化能力。"换言之,LLM擅长将旧模式应用于相似新数据,却无法解决真正新颖的问题。
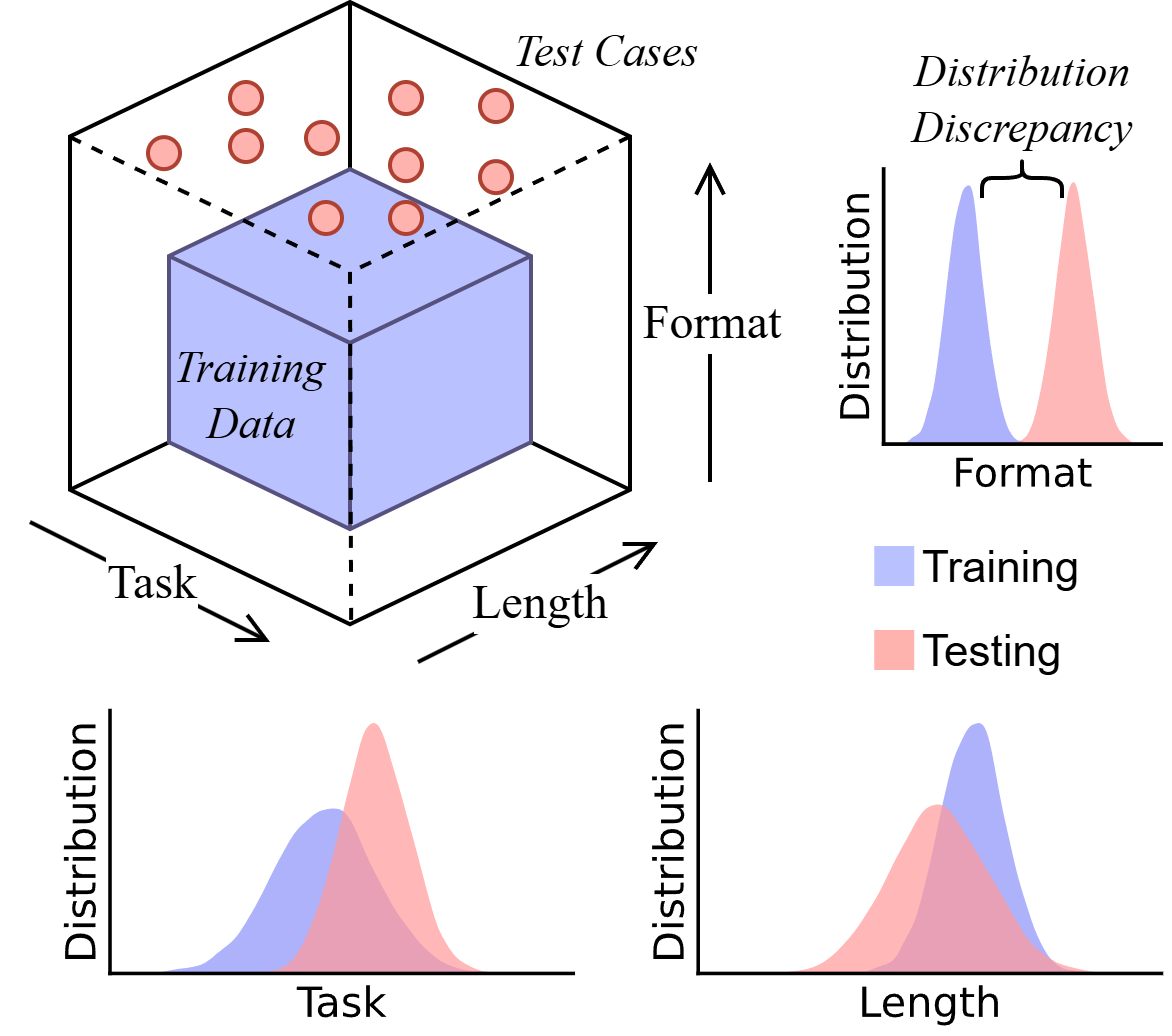
为验证该假设,他们通过"分布偏移"的三个维度解构CoT能力:首先测试"任务泛化"——模型能否将习得推理过程迁移至新任务类型;其次检验"长度泛化"——处理与训练样本长度差异显著的推理链;最后评估"格式泛化"——模型对提示词微小变化的敏感度。
他们开发了DataAlchemy框架,在受控环境中从头训练小型LLM,精确测量超出训练数据时的性能衰减。"数据分布视角和受控环境是我们试图传达的核心,"论文合著者、ASU博士生赵成帅告诉VentureBeat,"我们希望创建让公众、研究者和开发者自由探索LLM本质的空间,推动人类认知边界。"
幻象的证实
基于发现,研究者得出结论:CoT推理是"受训练数据分布约束的高级结构化模式匹配"。即使轻微超出该分布,性能就会崩溃。看似结构化推理更像幻象,"源于训练数据中记忆或插值的模式,而非逻辑推断"。
三个维度均呈现一致失效:面对新任务时,模型复制训练中最近似模式而非泛化;遭遇不同长度推理链时,强行增减步骤以匹配训练样本长度;对提示词表层变化(特别是核心要素和指令变动)表现出高度敏感性。
有趣的是,研究发现这些缺陷可通过监督微调(SFT)快速修复——用少量新数据微调后,模型在该类问题上表现迅速提升。但这种"速效方案"进一步佐证模式匹配理论:模型并未习得更抽象推理,只是记忆新模式来克服特定弱点。
企业级启示
研究者向从业者发出直接警告:"需警惕将CoT作为推理任务的即插即用方案,切勿将CoT式输出等同于人类思维。"他们为LLM应用开发者提供三项关键建议:
1)防范过度依赖与错误自信。 在金融或法律分析等高危领域,CoT不应被视为可靠推理模块。LLM可能产生比明显错误更具欺骗性的"流畅废话"(合理但逻辑缺陷的推理)。作者强调"领域专家的充分审计不可或缺"。
"科学进步应坚持以人为本——机器可辅助,但发现仍源于人性与好奇心。"赵成帅表示。
2)优先进行分布外(OOD)测试。 测试数据与训练数据镜像的标准验证不足衡量真正鲁棒性。开发者必须实施严格测试,系统探查任务、长度和格式变化下的失效情况。
3)视微调为补丁而非万能药。 虽然监督微调(SFT)能快速"修补"模型在特定新数据分布上的表现,但并未创造真正泛化能力,只是略微扩展模型的"分布内气泡"。依赖SFT修复每个OOD失效是不可持续策略,无法解决模型缺乏抽象推理的核心问题。
虽然CoT并非人类认知形式,但这种局限可控。多数企业应用涉及相对狭窄且可预测的任务集。论文发现为保障这些领域可靠性提供了蓝图。开发者可构建严格评估套件,系统测试模型在应用场景中可能遇到的任务、长度和格式变化下的表现,从而划定模型"分布内舒适区"边界,确定其与具体需求的契合点。
这种靶向测试将微调从被动"打补丁"转变为主动对齐策略。当评估暴露特定弱点时,开发者可创建小型靶向SFT数据集来应对。该方法摒弃追求宽泛通用推理,转而精准运用SFT确保模型模式匹配能力与企业任务轮廓精确吻合。最终,该研究为超越空想、工程化实现LLM应用的可预测成功提供了实用视角。
