房产达人无限金币
161.44MB · 2025-12-23

基于字节跳动分布式治理的理念,数据平台数据治理团队自研了 SLA 保障平台,目前已在字节内部得到广泛使用,并支持了绝大部分数据团队的 SLA 治理需求,每天保障的 SLA 链路数量过千,解决了数据 SLA 难对齐、难保障、难管理的问题。
SLA(Service Level Agreement):服务级别协议,对互联网公司来说是网站服务可用性的保证。数据 SLA,即数据可用性保证,一般以数据产出时间作为 SLA。
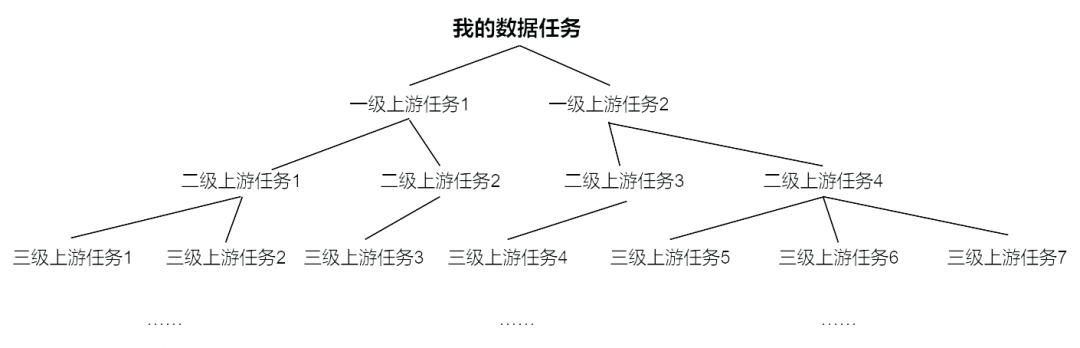
在海量数据任务开发场景中,因业务多样化、数据量大、数据任务复杂等问题,导致数据任务链路依赖复杂、链路长、跨团队节点依赖多,因此,在实际开发运维过程中,任务负责人为保证自身数据准时产出,会遇到如下困难:
沟通成本高:任务负责人尝试与上游任务负责人约定 SLA,但由于上游任务数多(可至上千个),且跨越多个团队,沟通成本非常高
权责不清晰:由于链路复杂,如何制定 SLA?谁来负责保障 SLA?
运维压力大:无法及时发现上游任务延迟,导致下游任务负责人承担绝大部分运维压力,且运维效果较差,往往发现延迟已经错过了补救的时间。
为解决上述问题,字节跳动数据平台通过自研的 SLA 保障平台,规范并推进各业务团队进行任务链路治理,有效保障数据的 SLA,数据 SLA 达标率达到 99.1%。
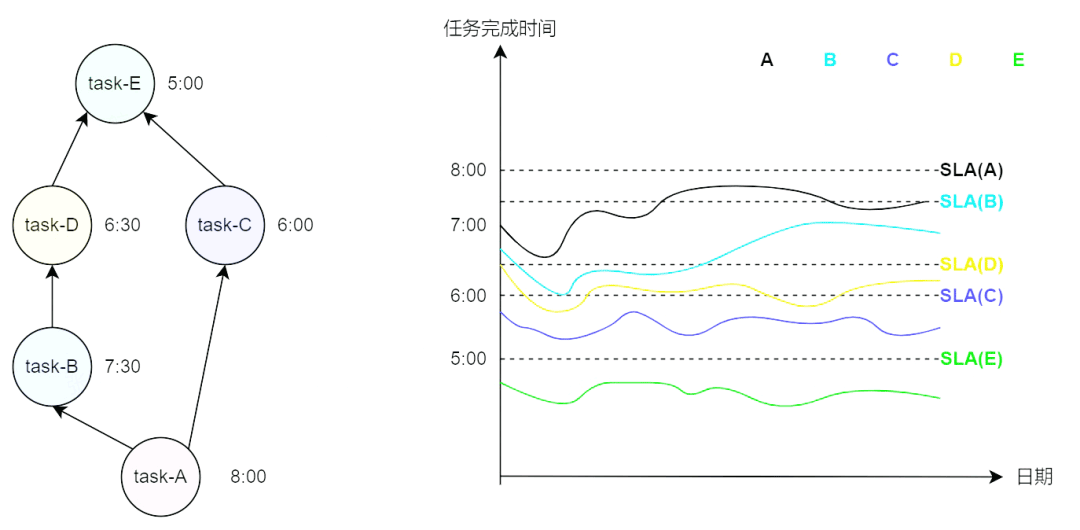
理想的一组任务的完成时间与对应 SLA 之间的关系如下图所示,即各个任务及其上游任务都在对应的 SLA 之前完成,这也是平台的治理目标。
SLA 保障平台除了解决上文的困难外,对不同的用户还有以下使用场景:
根据以上不同角色需求,SLA 保障平台提出自身解决方案。针对团队数据治理需求,平台提供完善的治理看板能力;针对任务链路复杂导致的 SLA 难达成,平台通过各项优化,简化了 SLA 达成流程;针对下游任务运维压力大的问题,平台优化通知体系,及时播报 SLA 状态。
那么,SLA 保障平台有哪些核心模块?平台是如何运转的呢?
任务负责人:即待保障 SLA 数据链路中的任务 owner,负责确定及签署所负责任务的 SLA,平台会按照其签署的 SLA 进行保障;
即产出数据的任务,通过数据任务的元信息,可构建整条数据生产链路的完整 DAG。在本平台中,所涉及的任务元信息一般需要包含以下内容:

申报人提起的一次申报内容,被称为一个“申报单”,一个申报单一般包含的核心内容如下:
| 元素 | 描述 |
|---|---|
| 申报任务 | 申报的任务,即申报人希望保障的任务,也被称为起点任务 |
| 期望 SLA | 申报人希望申报任务的产出时间,会直接按该时间进行签署 |
| 治理团队 | 数据治理方,该申报单将由此治理团队的管理员进行审批及治理 |
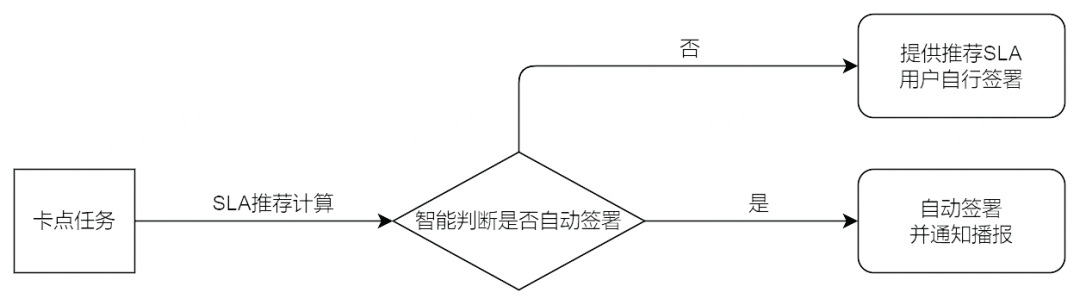
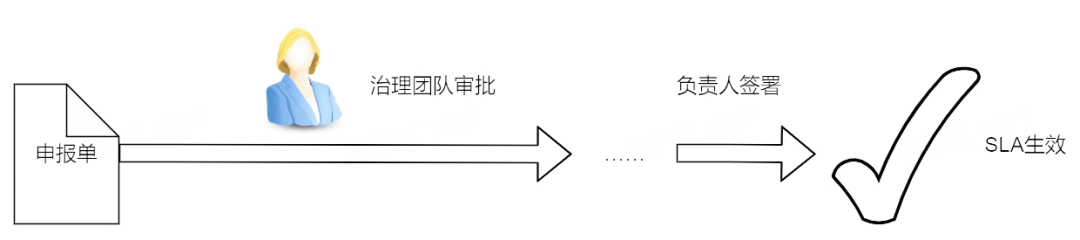
SLA 保障的前提是先达成 SLA 协议。在 SLA 保障平台中,以申报单签署的形式达成 SLA 协议。平台核心特点是优化了 SLA 达成的流程,先通过 “系统卡点计算” 减少待签署任务的数量,再通过 “SLA 推荐计算” 自动签署部分任务,最后为剩下的待签署任务智能提供合适的 SLA,进一步降低签署成本。
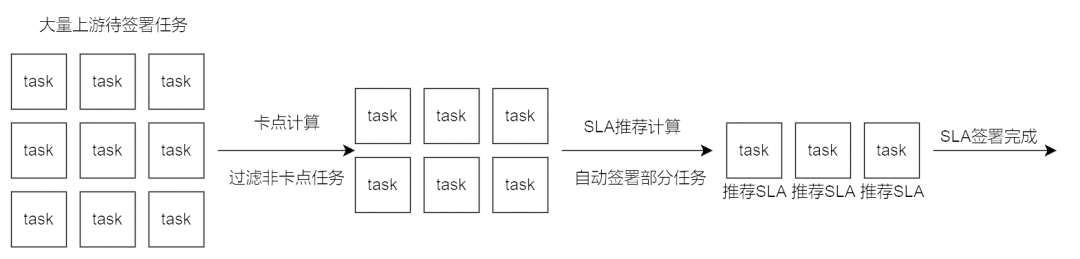
在申报签署环节中,各个环节的变化将通过通知模块传递信息给相应负责人,实时通知降低信息交流成本,加速了 SLA 的达成。

上图为申报签署的一般流程,在实际操作时,如任务链路变化、SLA 时间商讨待确认等特殊情况,申报签署流程会有微调。
首先需要申报人填写申报单,在申报人提交后,系统会根据申报单中的申报任务拉取上游的所有任务,构成一个完整的 DAG,并进行任务链路分析。链路分析的结果是后续算法的前提,也是管理员审批时的重要参考因素,可以让用户快速了解到自身任务在链路中所处的位置及上下游运行情况。
在理想情况下,为保证申报任务顺利推进,需要该任务的所有上游任务都签署 SLA 才算完成签署。而链路复杂导致的上游任务多、跨团队沟通成本高、SLA 难以确定等问题,成了整体 SLA 达成的最大阻碍。通过“卡点计算”与“SLA 推荐计算”可以跨越此阻碍。
本系统采取一定的“卡点策略”,计算出此 DAG 中的部分需要被签署的任务,此类任务称为“卡点任务”,这个过程称之为“卡点计算”。计算得到卡点任务后,在签署过程中可以忽略其他任务,从而大大降低签署成本。
一个申报单会关联多个任务(即该申报任务及其上游的卡点任务),同理一个任务也会关联多个申报单,因为在一个 DAG 中,申报任务可能从任意节点起,因此二者是 N:N 的关系。
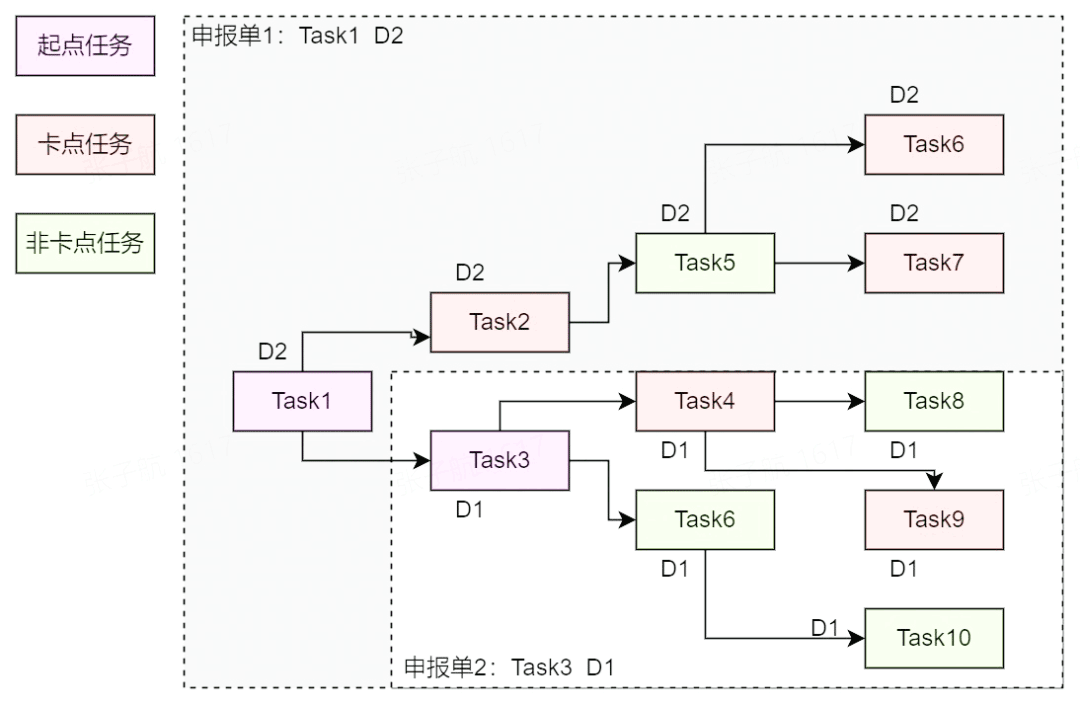
当两个申报单有部分任务列表重合时,如 Task4 关联了两个申报单,该任务的申报方、治理团队等数据是两个申报单的去重合集,而等级则取所有申报单中最高者。
利用任务及其上下游任务的历史运行信息,再结合推荐算法,得到该任务的推荐 SLA,这个过程称之为SLA 推荐计算。
在负责人签署 SLA 之前,SLA 推荐算法会智能计算每个任务的推荐的 SLA,并以此进一步通过算法自动签署部分待签署的任务,进一步降低签署成本。据平台数据统计,此功能可以自动签署近40% 的 SLA,是最核心的功能之一。
而对于剩余的待签署任务,会将算法推荐的 SLA 提供给任务负责人。任务负责人可以直接选择直接用这个 SLA 签署,也可以自行决定 SLA。一般情况下,智能推荐的 SLA 已经能满足绝大多数的需求,通过推荐 SLA,任务负责人更快的做出签署决定,再次降低了签署成本。
当一个申报单完成签署之后,平台将对申报单中的任务进行保障服务。保障服务的核心就是通过监控 SLA 的状态变化及时播报消息通知,为相应负责人及时提供一手资料,以此降低运维成本。对于一个离线任务,评价其 SLA 主要是依据其完成时间和其所承诺的 SLA 来判断,SLA 的状态分为四种,分别是:
从下图可以看到在任务达成、未达成两种情况下,随着时间的推移,其 SLA 状态的变化。
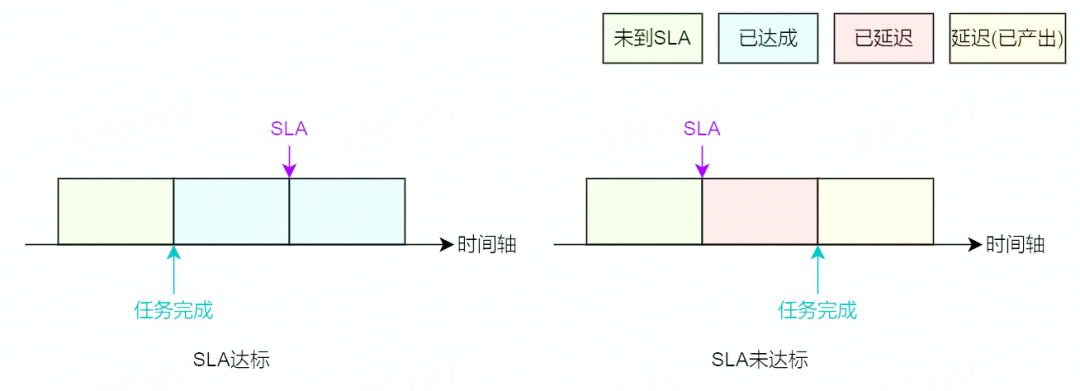
SLA 的实时状态是数据业务方所需要的重要信息,因此平台会所有任务的 SLA 进行监控,并在 SLA 状态变化时实时对相关人员发送通知,相关人员根据收到的通知知晓 SLA 的具体情况,并能做出应对措施。
复盘管理是本平台提供的响应式治理服务的实现方式,是数据治理方的重点关注对象。复盘管理又分为问题管理与事故管理,问题管理侧重于“为什么”——即整理分析 SLA 破线的原因,事故管理侧重于“怎么做”——即 SLA 破线事故之后该怎么治理。
问题管理模块的整体目标是满足数据治理团队对 SLA 问题的登记管理,支持对登记后的问题数据进行不同维度根因数据分析,辅助用户对问题根因进行治理,沉淀治理问题经验。
平台在进行系统保障监控时,会在 SLA 延迟时进行通知播报,并持续提醒负责人进行问题登记。在问题登记时,平台提供了一组根因树辅助登记,明确问题根因类别,方便统计分析。任务负责人进行问题登记后,累积数据展示在问题看板上,数据治理方由此做问题分析归纳总结。
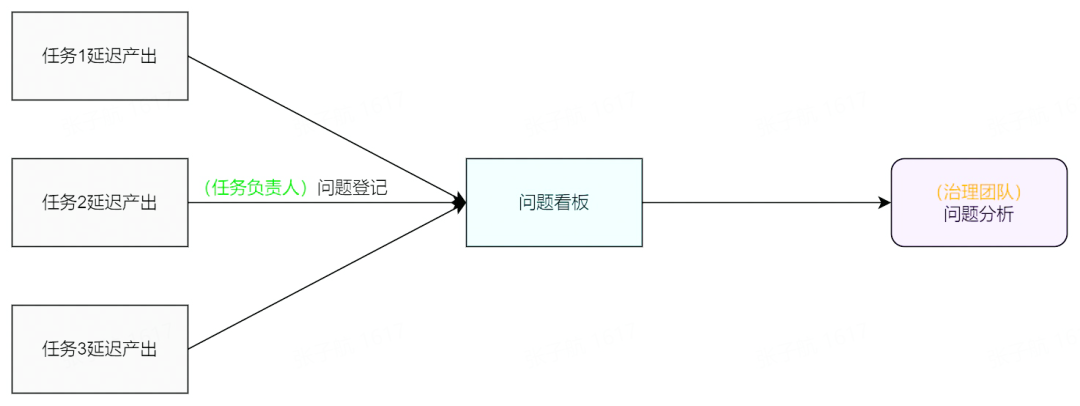
平台保证了 SLA 延迟记录与问题之间是一一对应的关系,并在问题看板上关联了 SLA 详情信息,包括任务链路、负责人、任务起止时间等。
问题登记往往是一个从多到少的过程,前期出现的问题在逐一治理解决后,将对后期的治理起到很好的参考警示作用,它的数据价值如下:
根据平台运营的记录显示,常见的问题有资源队列阻塞、上游任务故障、数据倾斜等。某数据团队双月问题登记总结如下,问题数量和问题根因种类得到了有效的收敛:
| 双月 | 问题数量 | 根因种类 |
|---|---|---|
| 2019-07/08 | 77 | 12 |
| 2019-09/10 | 58 | 10 |
| 2019-11/12 | 33 | 7 |
| 2020-01/02 | 23 | 5 |
| 2020-03/04 | 17 | 4 |
| 2020-05/06 | 9 | 2 |
| 2020-07/08 | 9 | 2 |
事故管理用于记录 SLA 破线事故的复盘与改进管理,每个事故至少对应一条 SLA 问题记录,而每个 SLA 问题不一定会造成事故。
事故可以在任意节点进行,一般在 SLA 破线并造成实际的业务影响之后,需要进行事故登记,事故登记同样会关联相关的 SLA 信息。一个事故的处理流程如下所示:
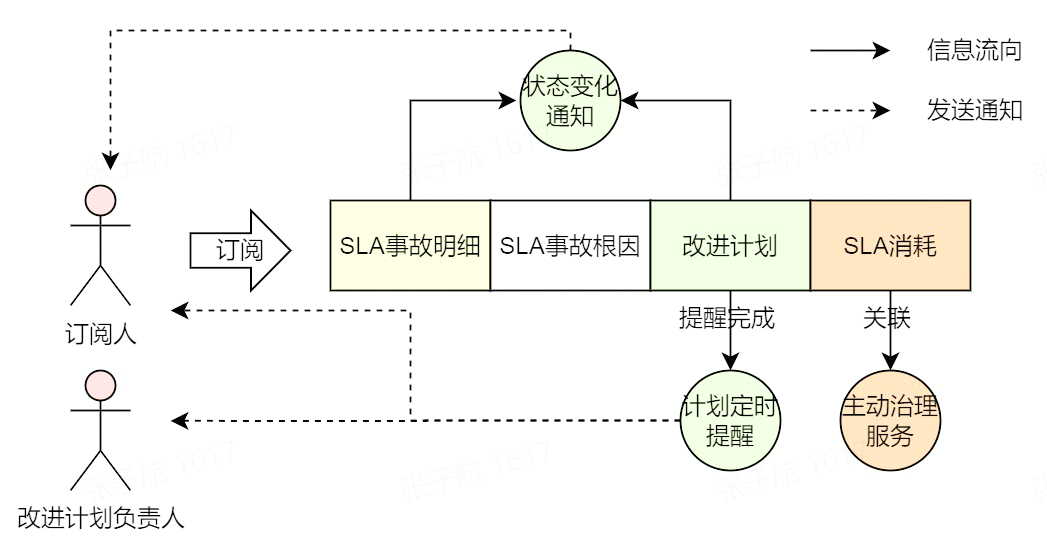
如图所示,事故主要包含 SLA 事故明细、SLA 事故根因、改进计划及 SLA 消耗这几部分,在这其中可以关注以下几点:
SLA 事故管理平台的数据是数据治理方治理成果的重要依据,也是整个 SLA 保障平台使用效果的体现,它的数据价值如下:
以下是某个团队的双月事故统计:
| 双月 | 事故数量 | 环比 |
|---|---|---|
| 2019-07/08 | 46 | - - - |
| 2019-09/10 | 26 | -43% |
| 2019-11/12 | 18 | -31% |
| 2020-01/02 | 13 | -28% |
| 2020-03/04 | 7 | -46% |
| 2020-05/06 | 6 | -14% |
| 2020-07/08 | 5 | -16% |
通过上述数据可知,本平台有效保障了核心任务的稳定产出,辅助降低了稳定性事故发生的概率,现在每双月该类型事故数量长期维持在个位数。
平台整体主要分为基础组件、规划式治理服务、响应式治理服务三大块,系统组件架构图如下:
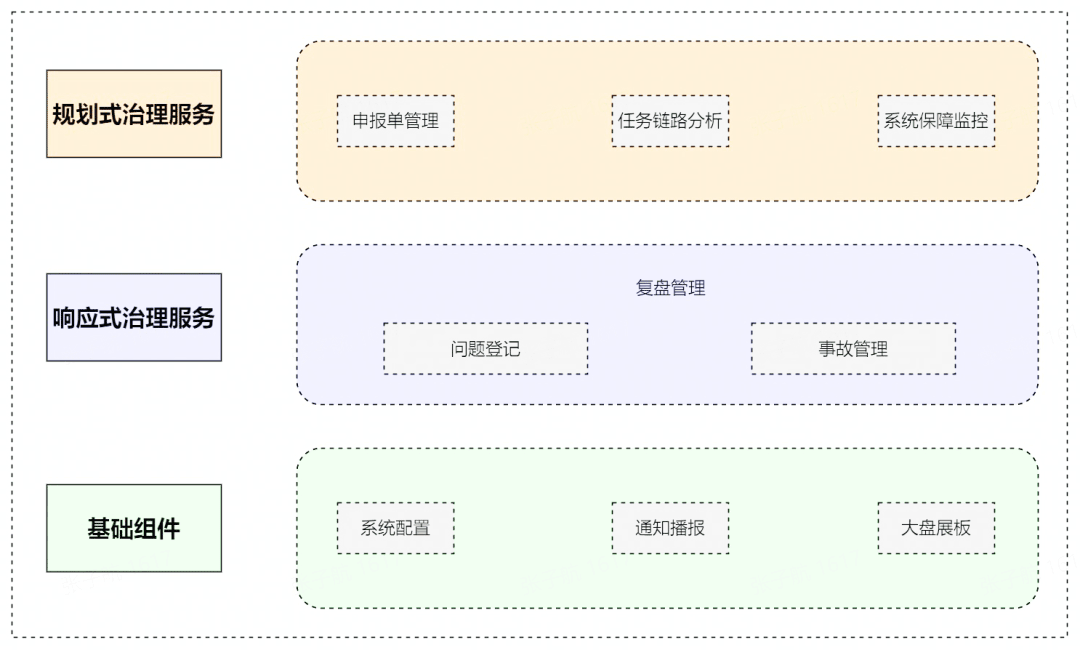
所谓“规划式治理”,即在问题发现前治理,通过主动规划约定 SLA 的形式保障任务产出。规划式治理是 SLA 相关问题发现的过程。
规划式治理服务即“提供以申报单签署的方式达成 SLA 协议的服务”,包括在此过程中申报单的生命周期管理操作,申报任务的链路分析,以及达成 SLA 之后的系统保障监控,服务于“申报签署流程”。
响应式治理是指通过复盘管理模块对 SLA 相关的事故/问题进行登记、管理、复盘的过程。在发现 SLA 相关问题之后,需要对问题进行处理,形成一个完整的闭环,在发现问题后进行的治理成为响应式治理。
响应式治理服务模块抽象出问题登记和事故管理两个模块,更加灵活的服务于数据 SLA 的问题归因与事故统计。
基础组件提供了配置、播报、看板等基本功能模块服务,为规划式、响应式治理服务提供了必要支撑,是整体 SLA 保障服务不可或缺的一环。
治理团队为 SLA 的管理团队,每个申报单都需要绑定一个治理团队,治理团队主要负责审批申报单。
数据团队为数据的归属方,一个数据团队对应一个业务团队,数据团队的设计保障了各个业务团队独立治理的需求。平台通过对数据团队的灵活配置支持,可以更细粒度的划分数据与任务的归属,解决权责不清的问题。
订阅管理是配置订阅信息的平台,本平台的订阅为 SLA 监控的通知播报,通过订阅管理可以将通知指定发动到个人或者群组。订阅管理是 SLA 监控保障服务不可或缺的一环。
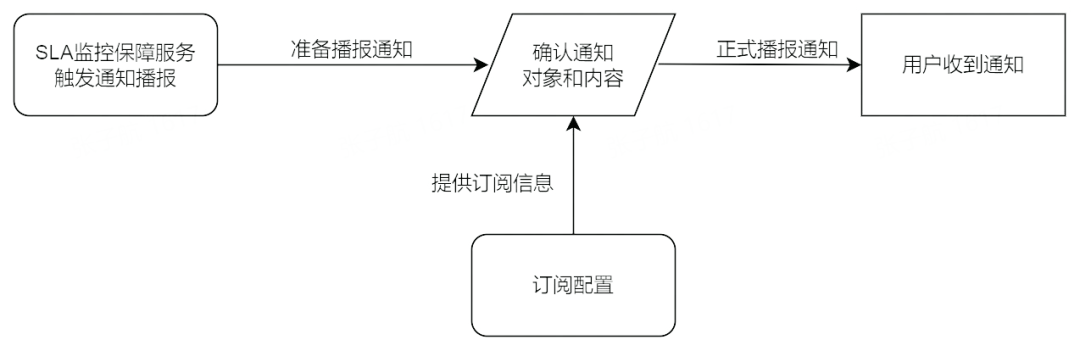
通知播报是本平台所提供的基础通知能力,是降低沟通成本、实现保障服务、提升用户体验的重要手段。在重要节点变更、用户操作、SLA 状态变化等情况下,都会进行通知播报。通知播报形式多样,根据不同的场景,有普通文本消息、加急消息、卡片通知、邮件通知、电话通知等。
SLA 大盘展板是数据治理方最为关心的部分,展板提供当日 SLA 整体统计信息、SLA 延迟趋势分析信息、SLA 等级分布明细、任务健康度明细、团队 SLA 达成信息统计等丰富信息,是很多团队数据治理指标重要参照来源。
未来字节跳动数据治理团队将持续打磨 SLA 保障平台,在卡点策略优化、SLA 推荐算法优化、基于 SLA 的任务管理机制上持续提升技术能力:
同时,文中阐述的部分能力已经通过火山引擎 DataLeap 产品向企业客户开放,更多关于SLA治理的资料请关注本站其它相关文章!

