
怒焰三国杀vivo客户端
873.12MB · 2025-11-29

1.1 谈谈你对ThreadLocal的理解?
ThreadLocal的作用主要是做数据隔离,填充的数据只属于当前线程,变量的数据对别的线程而言是相对隔离的。它不是针对程序的[全局变量],只是针对当前线程的全局变量。
1.2 ThreadLocal底层实现原理?
Threadlocal内部有一个非常关键的[内部类]ThreadlocalMap,里面定义了一个由key - value组成的Entry数组,key存放的就是当前的线程,value为我们所需的数据。 而key是弱引用会被gc清除,value是强引用不会被清除,所以会造成内存泄漏。如果我们在线程池中使用了Threadlocal,一定要记得调用remove()方法,避免ThreadLocal 保存的数据被泄漏或污染!!!
public void set(T value) {
//进行set方法时,先获取当前线程对象,根据当前线程获取ThreadLocalMap,
//然后以当前Threadlocal为key进行存储
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
AI写代码
2.1 synchronized与Reentrantlock的区别
2.2 volatile关键字如何保证可见性和有序性
2.3 Java如何避免死锁

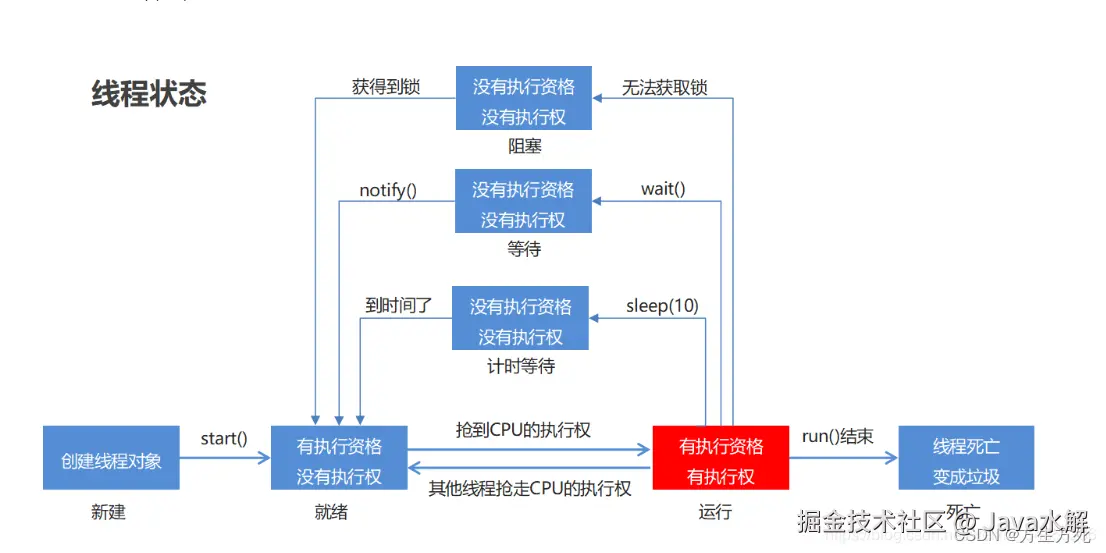
新建、就绪、运行、阻塞、死亡
3.2 如何获取多线程的返回值?
深坑!如果问多线程的创建方式,你一定知道是继承Thread类,实现runnable,callable接口。这里就是拐了个弯,变相的了解有返回值的callable接口。通过中间媒介FutureTask,将实现callable接口的类对象传递进去,调用FutureTask里面的get()方法,即可获取多线程的返回值。
3.3 为什么使用线程池,几个参数?
降低资源消耗(创建、销毁耗资源),提高响应速度(任务来了,可以有线程直接使用);
4.1、 并行、串行、并发?
4.2、 谈谈对AQS的理解,AQS如何实现可重入锁?
笔者总结了一篇Mysql高级,涉及内容较深些,也是常问的面试题,点击链接查阅
[Mysql高级篇]
1.1 索引的类型可以是String类型吗?
聚簇索引----数据和索引放一块,像主键索引,具有唯一性(Innodb就是)
数据库第一范式:必须要有id,这个id是自带索引的。
一般用自增id,字符串可以做id,但是不好,像uuid做的id是随机的,都没有排序!!!不像自增id维护索引的成本会很低
1.2 什么是索引?什么情况下用索引?什么时候不用?
1)就是一种数据结构,目的就是为了快速查找数据。
2)对查询频率高(索引就是为了提高查询效率),像where后的字段
数据量特别大, 索引不是越多越好,会影响增删的效率,典型的用空间换时间。
分组字段可以建立索引,因为分组的前提是排序(覆盖索引)
3)频繁更新的字段、查询少的、参与计算的不适合建索引。
1.3 索引失效?
1.4 查看索引使用和查看索引信息?
索引使用: explain 结果 (只要数字大于1)1 row in set 即生效了
查看索引信息: show indexs from 表名
1.5 复合索引?最左匹配原则?
最核心的是 等值比较
复合索引就是多个字段放一块(企业最常用的是符合索引!!!唯一索引,普通索引我们也用)
mysql会一直向右查询,直到遇到范围查询(> < like),比如用 a b c d四个字段创建了一个复合索引, a=3 b=5 c>7 d=9 只会用到前三个,因为b c d 是根据a 的后面进行规则的排序,即a是有序的,后面的bcd是无序的。 (hash索引用的不多,因为无序,但是定位快,了解即可)
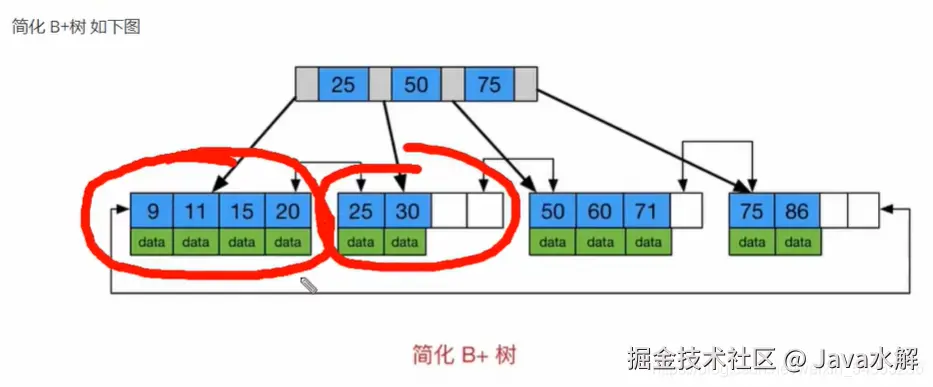
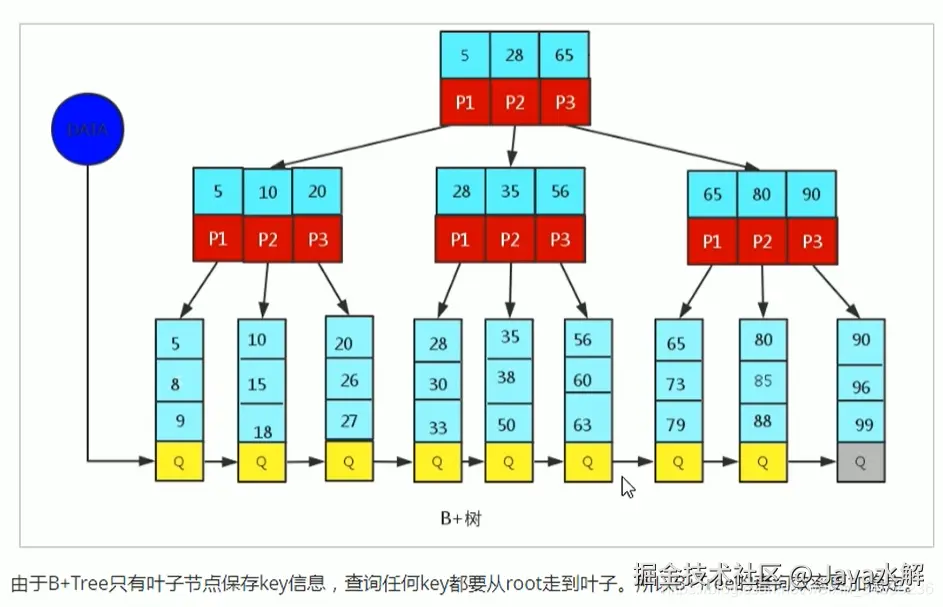
1.6 Btree和B+tree?为什么mysql用的是B+ tree? **
B+tree是Btree的升级版。
Btree:多路平衡树,当增删数据时,会自动的将数据进行这个平衡(旋转)
为什么从Btree转到B+tree? 因为:索引也是一个文件,存档在磁盘,在使用时读入到内存。内存是有限的,如果索引文件过大,无法一次性全部加载,需要分批加载。在有限磁盘的限制下,B+tree可以减少磁盘的I/O。
对于B+tree,所有的数据都存在叶子节点,根和非叶子节点只是存储的指针,指向下一个数据的地址,由叶子节点再去查找到关联的数据信息。对于查询的数据,都要从root节点走到叶子节点,所以查询相比于Btree更加稳定。
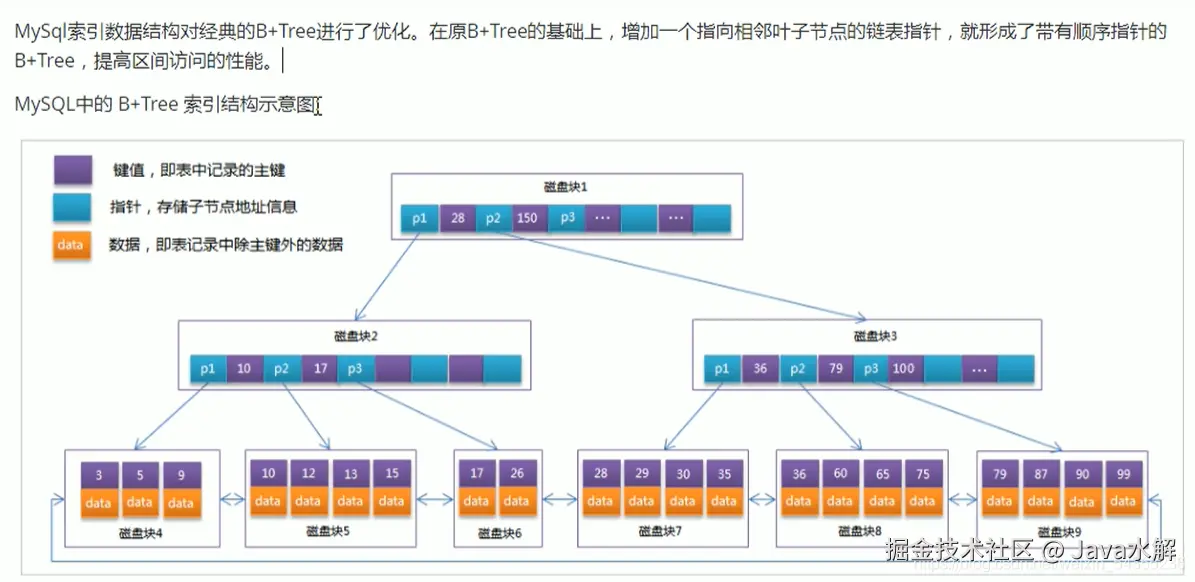
对于mysql,是在B+tree的基础上,在相邻节点间增加了一个链表指针,形成了带有顺序的B+tree,提高了区间的访问性能。
1.7 覆盖索引与回表
如果只需要在一棵索引树上就可以获取Sql所需要的所有列,就不需要回表查询,这样查询速度会更快。而实现覆盖索引最快的方式就是将所需要的字段放在一起建一个联合索引。
1.8 Mysql的锁有哪些?什么是间隙锁?
从锁的粒度来分
1、行锁:加锁粒度小,但是加锁的资源开销比较大。Innodb支持。
1)共享锁:多个事务可以共享一把锁,但是只能读不能修改
2)排他锁:只有一个事务可以获得排他锁,其他事务不能获取该行的锁。Innodb会自行对增删改操作添加排他锁。
2、表锁:加锁粒度大,加锁的资源消耗小,Mysalm和Innodb都支持。
3、全局锁:加锁后全库都处于只读状态,用于全库数据备份。
1.9 海量数据下,如何快速找到一条数据
1)使用布隆过滤器,快速过滤不存在的数据;
2)red is中建立数据缓存
3)查询优化
2.1 数据库的分库分表?什么时候分?怎么分?
当单表数据超过1000W时,很多操作的性能会下降,所以需要切分,以减少数据库的压力,缩短查询时间。
垂直切分:将关系联系不紧密的表进行分库,将一张表中不常用的字段进行抽取新建一张表。优点类似于微服务。
水平切分:当一个应用难以再细粒度的垂直切分,根据数据间的逻辑进行划分,比如客户、存款、支付;
2.2 数据库的优化?
1)sql优化以及索引的优化,索引建立要合理,过多会影响增删性能
2)数据可设计要满足他的三大范式、五大约束
3)硬件优化
2.3 表设计的时候注意哪些,字段?
spring里面的事务和mysql里面的事务是一个概念,如果mysql不支持事务,加上@transation也是无效的。但是spring里面的@transation不能用于分布式环境下,分布式多线程下用的是senta+@globalTransation注解。
3.1 @transation用于类和方法有什么区别?
@transation只能修饰public方法。
类上:相当于在所有的public方法上加上了@transation注解
方法:会覆盖类上的配置。
3.2 事务的4个条件ACID
原子性:所有的操作是一个整体,要么全部成功,要么全部失败(回滚)
一致性:事务开始前后,数据库的完整性没有被破坏,也就是写入的资料完全符合我们的预设。
隔离性:允许多个并发事务对数据进行读写操作,它可以有效的防止多个事务并发执行时由于交叉执行而导致数据的不一致。(隔离性里面有4个隔离级别:读未提交、读以提交、可重复读、串行化)
持久性:事务完成,对数据的操作就是永久的,即使系统故障也不会丢失。
3.3 mysql事物隔离级别?
MySQL 提供了四种隔离级别,用于控制事务之间的隔离程度,以确保事务操作的一致性和并发性。这四种隔离级别分别是:
4.1 mysql中的null和空值有什么不一样?
1)空值是不占空间的,null值占用空间。两者就像:空值是真空状态的杯子,而null值是装满空气的杯子。
2)查寻上:null 值是用is null/is not null来查询,而空值( ’ ’ )则可以用 = > !=等。 在使用聚合函数count时,会过滤掉null,而不会过滤掉 ( ’ ’ )值。
在实际开发中,没有特定需求,可以直接使用空值!!!
4.2 mysql主从数据库延时的原因?
4.3 mysql主从复制的过程?

