
沙盒粉碎模拟器
106.24 MB · 2025-12-20

之前介绍了ZGC,埋了个坑,说是会写分代ZGC,但是因为所在的业务组比较忙,且分代ZGC的相关资料较少,所以就搁置了一段时间,现在有时间了,就继续完成。因为网上的ZGC的资料很少介绍到分代ZGC,一般都是介绍完ZGC之后就没了,所以我这篇文章主要也是参考官方的文档和YouTube上的视频,结合自己的理解,尽可能通俗的描述清楚分代ZGC到底做了什么优化。
阅读此篇文章前建议先查看上篇:JDK新特性】聊聊ZGC的核心原理
本文将围绕着分代ZGC所做的几个优化进行分析:
官方文档:openjdk.org/jeps/439
学过JVM的jy都知道,堆中的大部分对象基本上生命周期都很短,朝生暮死。而如果不分代,那么就会导致整堆扫描,性能较差。
这个问题,我在油管上的一个视频看到了答案:www.youtube.com/watch?v=LXW…
官方的这个视频介绍了几种垃圾回收器,也解释了为什么要做分代zgc, 视频中介绍了,一开始为了考虑性能,重点着重于解决延迟问题



(ps:这一部分我看很多文章都引用到了这个官方视频的截图,如果你感兴趣,可以直接去看这个视频:www.youtube.com/watch?v=YyX…)
不分代的ZGC使用Java堆的3个视图(“marked0”,“marked1”,“remapped”),即3种不同“颜色”的堆指针和同一个堆的3个虚拟内存映射。
因此,操作系统可能会报告 3 倍大的内存使用量。例如,对于 512 MB 的堆,报告的已提交内存可能高达 1.5 GB,不包括堆以外的内存。
多重映射会影响报告的使用内存,但物理上堆仍将使用 512 MB 的 RAM。这有时会导致一个有趣的效果,即进程的 RSS 看起来大于物理 RAM 的数量。
与不分代ZGC的4个颜色位相比,分代ZGC需要12个颜色位来标识不同的GC阶段,这显然不能用多重映射内存来实现了。(说明!! 很多文章提到分代ZGC并不是完全不使用多重映射,而是在老年代依旧保持了多重映射的机制。这种说法是错误的!可以参考官方的资料,官方地址:openjdk.org/jeps/439
读过我上篇的朋友一定知道,多重映射主要是为了读屏障在处理的时候,能够知道新的地址在哪里,而做的一个优化。但是在分代ZGC中,分代ZGC通过巧妙地代码逻辑来优化了这部分,而不是多重映射(可以看下文,或者下文中的源码链接)。
而分代ZGC最终的布局是这样的(图就是视频链接里面的截图)
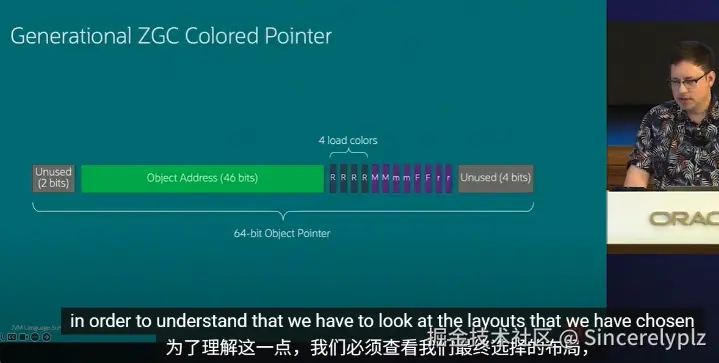
栈上指针是无色指针(colorless pointer)
彩色指针低位布局
元数据位放在低位,对象地址放在高位。
通过位移(shift)指令就可以:
这在 x64 架构上只需要 一条指令,效率很高。
在介绍分代zgc的屏障优化之前,我们先回顾一下什么是屏障。
垃圾回收器(GC)为了在程序运行时不打断用户逻辑,会在 对象访问(load) 和 对象修改(store) 时,插入一些“小检查逻辑”,叫做 barriers(屏障) 。
分代ZGC中屏障主要做了这几件事儿:
加载屏障(读屏障):
存储屏障(写屏障):
因为对象的每一次访问和写入都需要触发屏障,频率极高,如果屏障很慢就会导致整个程序的吞吐量被拖垮。
用于优化屏障的一些技术包括:
OK,接下来我们一个一个开始分析。
官方文档的描述:
我们将结合源码进行分析:
源码:github.com/openjdk/jdk…
链接中的这段代码是 ZGC 的屏障实现核心之一,具体是 ZBarrier 的 快速路径与慢路径逻辑总控。
我们来系统分析 快速路径的主逻辑 。
template <typename ZBarrierSlowPath>
inline zaddress ZBarrier::barrier(ZBarrierFastPath fast_path,
ZBarrierSlowPath slow_path,
ZBarrierColor color,
volatile zpointer* p,
zpointer o,
bool allow_null) {
z_verify_safepoints_are_blocked();
// Fast path
if (fast_path(o)) {
return ZPointer::uncolor(o);
}
// Make load good
const zaddress load_good_addr = make_load_good(o);
// Slow path
const zaddress good_addr = slow_path(load_good_addr);
// Self heal
if (p != nullptr) {
// Color
const zpointer good_ptr = color(good_addr, o);
assert(!is_null(good_ptr), "Always block raw null");
self_heal(fast_path, p, o, good_ptr, allow_null);
}
return good_addr;
}
快速路径是:
if (fast_path(o)) {
return ZPointer::uncolor(o);
}
即 检查对象指针 o 是否已经是load good 或 mark good 或 store good 等状态。
如果是,就直接去掉颜色位(ZPointer::uncolor(o)),返回真实的对象地址,不触发任何 barrier 操作。
触发慢路径是 当 fast_path(o) 为 false 时:
表示指针中包含无效或过期的标志位(例如指向被转发的对象、被回收的 page、或 Remap Bad 状态)。
于是进入:
const zaddress load_good_addr = make_load_good(o);
这里调用:
inline zaddress ZBarrier::make_load_good(zpointer o) {
if (is_null_any(o)) {
return zaddress::null;
}
if (ZPointer::is_load_good_or_null(o)) {
return ZPointer::uncolor(o);
}
return relocate_or_remap(ZPointer::uncolor_unsafe(o), remap_generation(o));
}
也就是说,慢路径主要做两件事:
最后调用:
self_heal(fast_path, p, o, good_ptr, allow_null);
执行自愈(CAS 原子替换),将旧的坏指针换成新修复的指针。
总结就是:快速路径只做检查,如果没问题直接返回裸地址,跳过一切屏障操作,从而实现近似零开销的访问性能,而慢路径才是真正的GC。
在非分代ZGC中,加载屏障要负责:
但是因为分代ZGC,需要追踪新生代和老年代,并且在有颜色指针和无颜色指针的切换,所以为了减少复杂性,优化快速路径,标记的责任被转移到了存储屏障上面。
当分代ZGC收集年轻代的时候,只会访问年轻代的对象,但是如果老年代中的对象指向了年轻代,那我怎么知道哪些对象是被老年代的对象访问的呢?这个时候就需要Remembered-set,Remembered-set维护了老年代对于年轻代的引用。但这样就会有一个问题,收集年轻代的时候会移动对象,但是对象的指针不会立刻更新!
存储屏障是在程序给对象字段赋值时自动触发的逻辑,它的作用就是:每当你在老年代对象中写入一个引用字段时,把这个字段地址记到记忆集中。
但是屏障是非常“热”的路径(几乎所有赋值操作都会触发),如果每次写字段都要进入慢路径、往记忆集加一条记录,那开销会很大。
ZGC 的优化就是:每个字段,在一个年轻代 GC 周期中,只被慢路径处理一次。
也就是说 第一次写入这个字段时:
后续再写入这个字段:
由于ZGC是并发GC的,那么就有一个问题:在 GC 标记过程中,应用还在不停修改对象引用。
那我怎么知道哪些对象在「标记开始时」是活的呢?
因为如果 GC 一边在标记,一边应用把某个引用删掉(断开了),GC 就可能漏标(遗漏存活对象) 。
SATB(Snapshot-At-The-Beginning)就是一种解决办法。
在标记阶段开始的那一刻,GC 认为堆中所有从根对象可达的对象都是活的。 不管程序之后怎么改引用,我都要把当时那一刻的‘可达图’完整标记完。GC 想维护的是那一刻的“快照视图” (snapshot)
但是这就有一个问题,假设在标记期间,程序可能会这样做:
a.field = null;
这就意味着 “a.field” 原来指向的对象失去了一个引用。
如果此时 GC 还没来得及扫描 a.field 指向的对象,那它就会被漏掉。
虽然说a.field指向的是null了,但是原先的对象我们依旧要认为它是活的,这就是GC想要维护快照的一致性。
为了维护这个一致性,写屏障(store barrier)会在“引用被覆盖前”告诉 GC:“这个字段原来指向的对象 X 要被我改掉了,请你把 X 标记为活的!”
但这里也有一个关键的优化点:“Store barriers need only report a to-be-overwritten field value the first time that the field is stored to within a marking cycle.”
也就是说:
a.field,写屏障会报告“旧值”。原因是:
这里就直接看原文了
原文是:
其实就是说,前面介绍到的存储集的优化和STAB的标记优化有很多类似的地方。比如
所以就直接将两个快速路径融合为了一个快速路径的检查,如果两个属性中的任何一个失败,就会采用慢路径,并且执行GC。
这里也直接看原文吧,很好理解
我个人理解,其实就是慢路径过于昂贵,所以创建了一个缓冲区,当前快速路径检查需要GC时,会放到缓冲区中,缓冲区满了,才会丢给慢路径进行GC。
无论是加载屏障还是存储屏障,执行时都需要检查某些GC的状态变量(比如当前GC阶段,年轻代/老年代状态)这些状态变量通常存储在
但是读取这些变量在不同 CPU 架构上的性能差异较大,可能成为瓶颈。
屏障补丁优化思路:
总结一下,由于分代ZGC的复杂性,ZGC做了很多的屏障上的优化,来提高分代ZGC的吞吐量。接下来我们介绍第二个分代ZGC优化点。
许多垃圾回收器使用一种称为卡表标记的 remembered-set 技术。当应用程序线程写入对象字段时,它也会写入(即弄脏)一个称为卡表的大字节数组中的一个字节。通常,表中的一字节对应于堆中 512 字节的地址范围。为了找到所有从旧代到年轻代的对象指针,垃圾回收器必须定位并访问卡表中脏字节所对应的地址范围内的所有对象字段。
但是ZGC的认为这样的标记,“粒度“ 太大,也就是将一个region认为是脏的,但是GC的时候,还是要扫描所有的”脏卡“,然后把里面的年轻代的字段找出来。
ZGC做的优化就是精确到每个字段(每个对象中的字段可能会持有跨代引用)而不是region。
分代ZGC使用的是bitmap,每个比特位代表一个潜在的对象地址。而这样的位图,分代ZGC做了两个。
两个bitmap中,一个用于给应用线程不断地写入,而另一个作为前一次记录的可读副本。当年轻代开始收集的时候,会交换这两个bitmap,将上一次的可读副本用于写入,将上一次写入的作为GC新的可读的remembered set,这种交换是原子性的。
这样做的好处是,应用线程无需等待位图被清除,GC处理一个位图时,另一个位图可并行的被应用线程填充。而且分为两个还减少了读和写之间的并发问题。比如G1,在标记卡片的时候,需要使用内存栅栏,这导致存储屏障的性能更差了。
其实这个优化主要是因为传统的GC是“存活对象会在单次遍历中被发现和重定位”。传统的GC由于一边遍历一边重定位,所以需要估算新的目标区域的大小,而如果估算失败会导致很严重的问题。
为了避免这种问题,所以估算的时候,一般会往大了估,这就是额外的堆内存。
而分代ZGC是在搬迁之前就完整的标记了存活的对象,不需要偏大估计,也就不需要额外的堆内存浪费。
假设一个ZGC中的一个Region的存活对象非常多的话,那么搬迁不如“原地老化”。所以ZGC通过分析年轻代的里面的密度来确定哪些适合搬迁。
但这里的“原地老化”并不是说,整个region就不回收了,同样的,即使这个region中大多数都是存活对象,但是依旧会标记哪些是死亡对象,但不会清除。下次年轻代再分析时,如果这块区域死的对象比较多了,就是认为“值得搬”了,那时,会彻底释放死对象占的空间。
即使升到了老年代,如果region太满了(绝大多数都是存活对象),则忽略哪些已经标记死亡的对象,但是下一次老年代GC的时候会被正式清理。也就是晋升后的 Region 会被老年代的标记—清理流程接管。
在有些垃圾回收期中,会直接将大对象放到老年代。但是因为分代ZGC的灵活性,我们允许大对象在年轻代分配,并且在不移动的情况下,进行老化(年龄+1),而且如果这些大对象很快就死了,那么就可以在年轻代中快速销毁,即使要升到老年代也可以原地升级:ZGC 的设计支持 region aging without relocation,也就是: 区域(region)可以“老化”(从 young → old)而不需要移动对象。。
我们知道remembered-set是老年代对于年轻代的引用,目的是为了防止每次young-gc的时候去扫描老年代,那为什么不反过来维护一个呢?
因为年轻代的回收频率比老年代高的多,所以这样的维护成本很高,所以当要回收老年代时,会在老年代标记阶段前,来一次年轻代收集,这次收集和正常的年轻代收集一样执行,但是这样就可以扫描出来,哪些引用指向了老年代。
ok,结束,其实本文还有很多内容没有详细的讲,比如垃圾回收算法,一些垃圾回收器的比较,希望读者能够有基本的JVM常识再来阅读此篇,最后希望正在读的你,能够有所收获。

