

卡拉彼丘手游正式版
1.65G · 2025-12-24

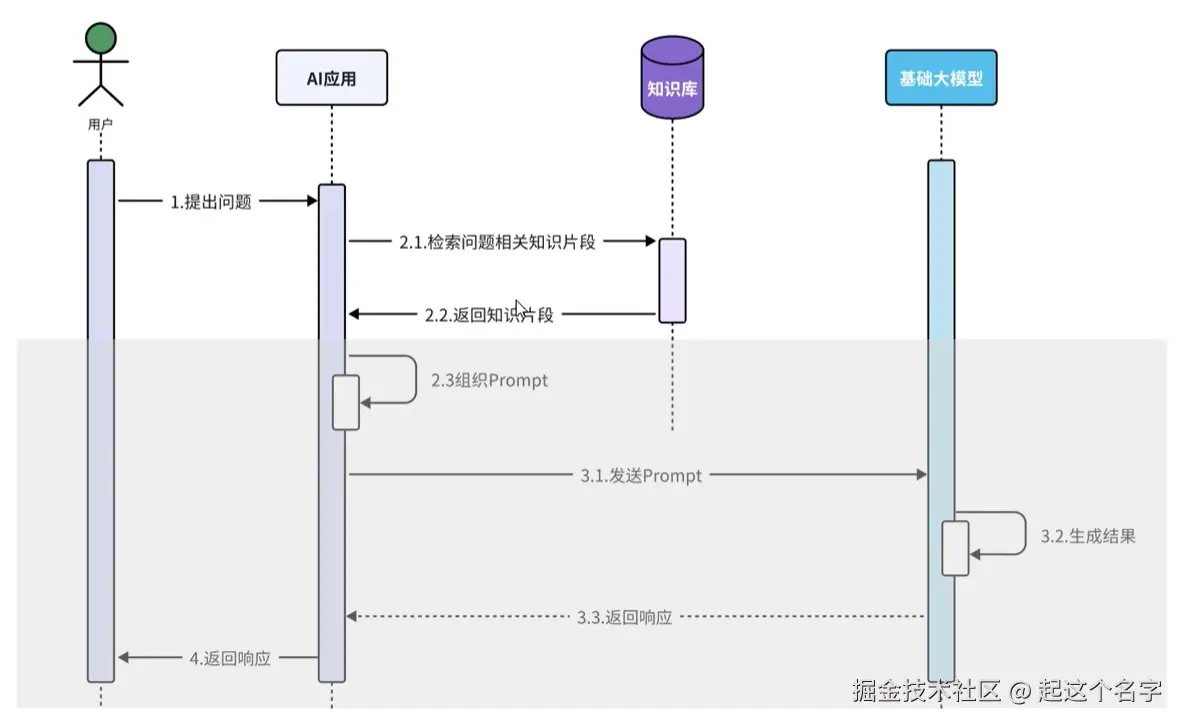
RAG,Retrieval Augmented Generation,检索增强生成。通过检索外部知识库的方式增强大模型的生成能力。
基础大模型训练完成后,随着时间的推移,产生的新数据大模型是无法感知的;而且训练大模型的都是通用数据,有关专业领域的数据大模型也是不知道的。此时就需要外挂一个知识库。
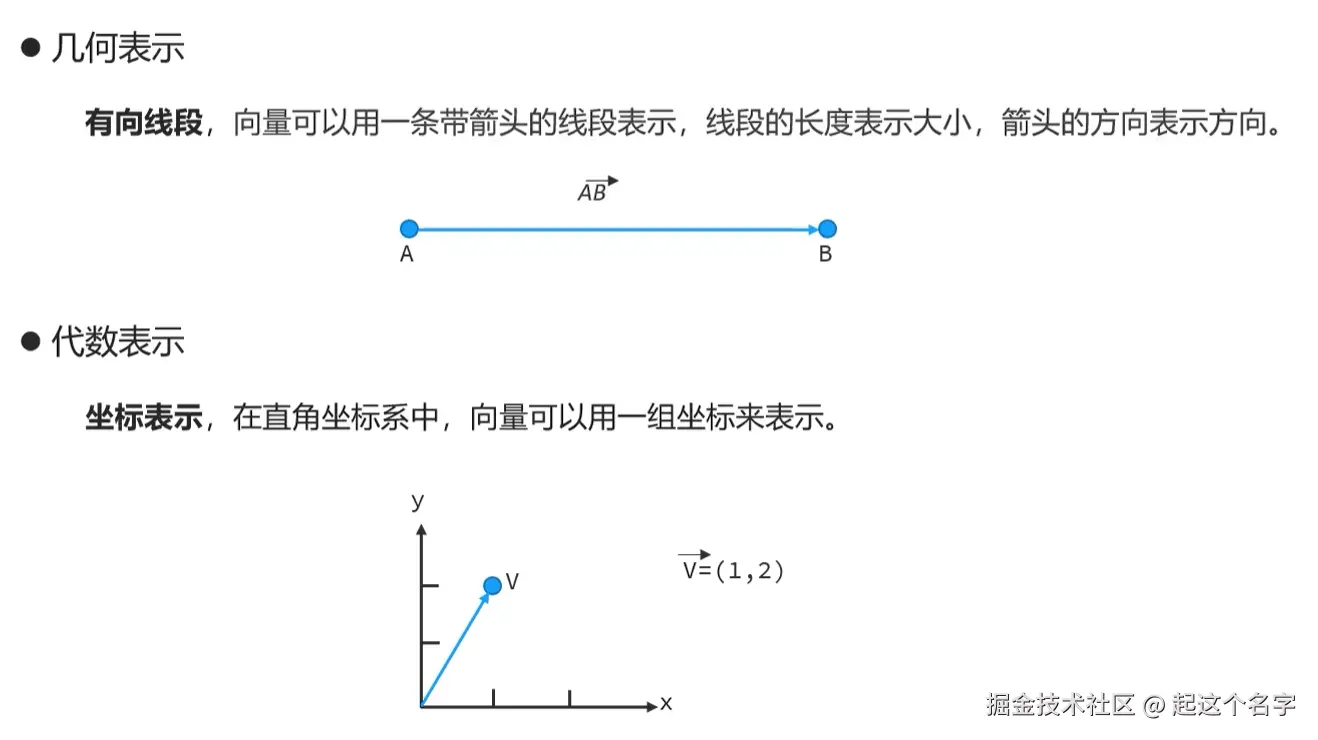
向量数据库: Milvus、Chroma、Pinecone、RedisSearch(Redis)、pgvector(PostgreSQL) 向量是表示具有大小和方向的量。
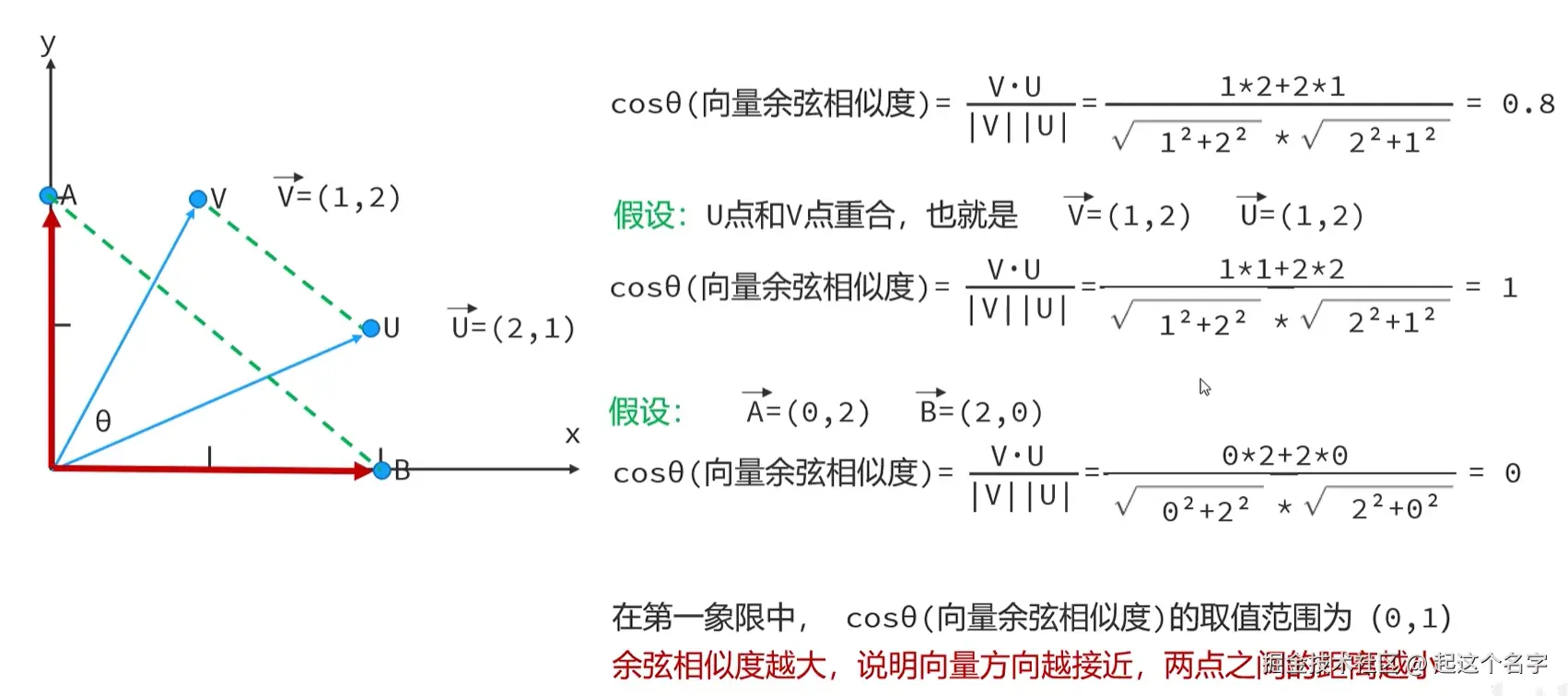
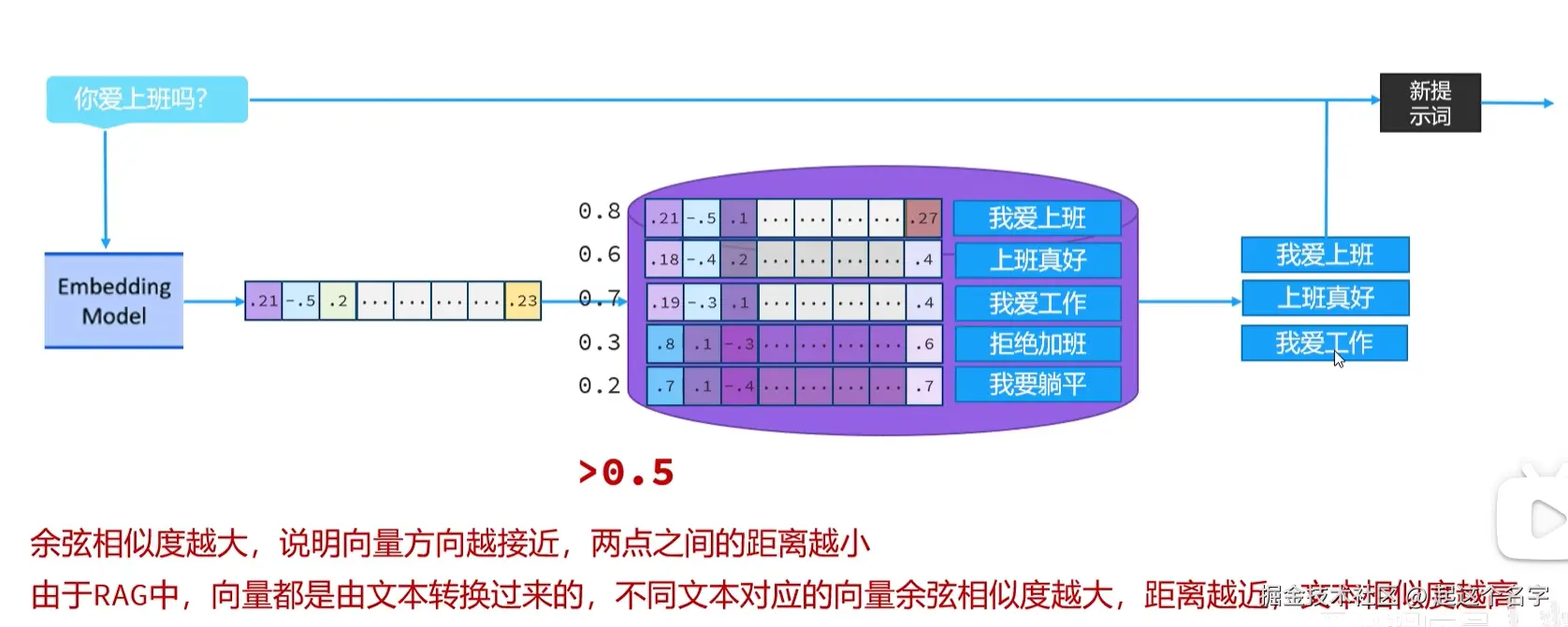
向量余弦相似度,用于表示坐标系中两个点之间的距离远近
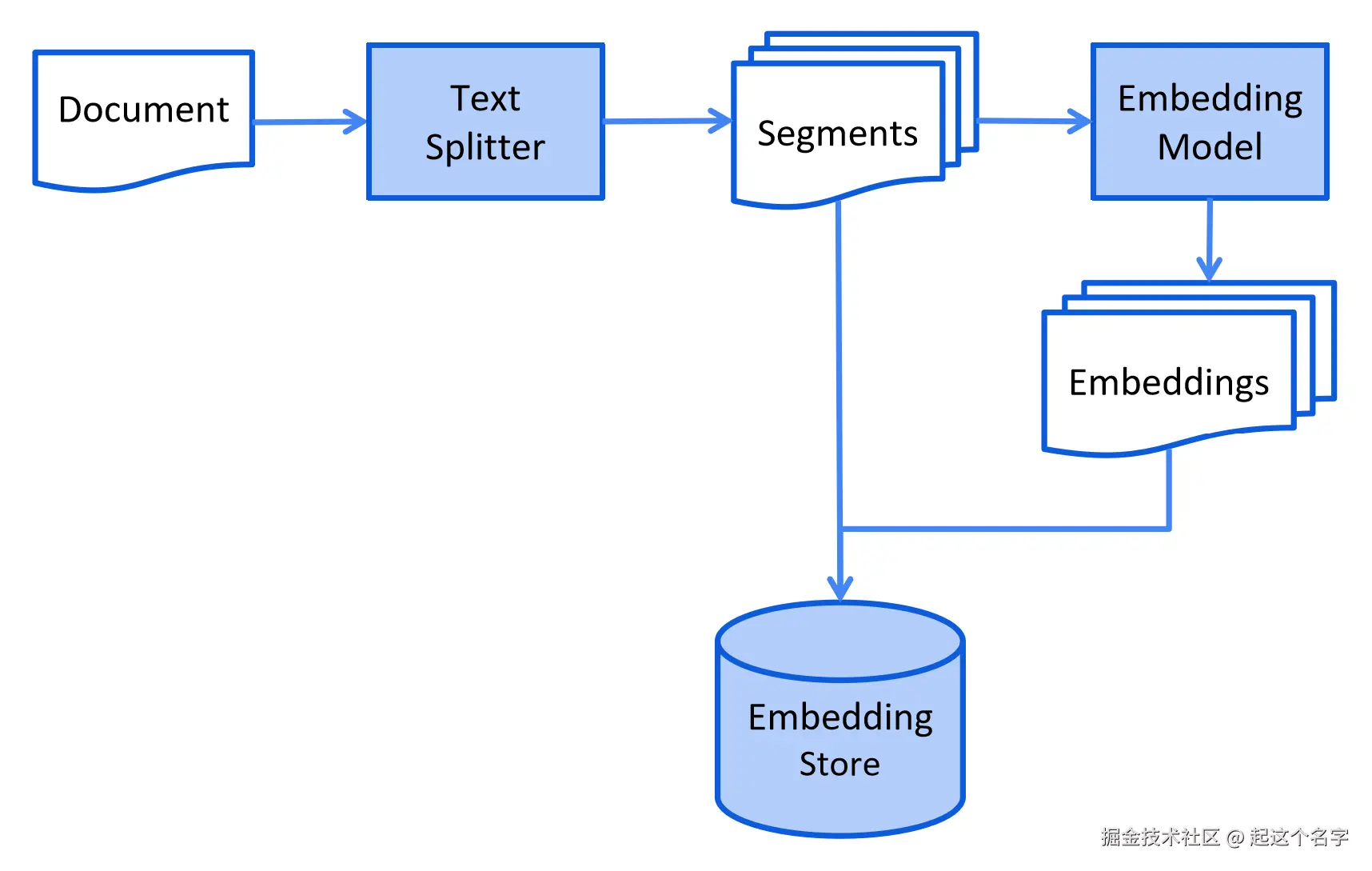
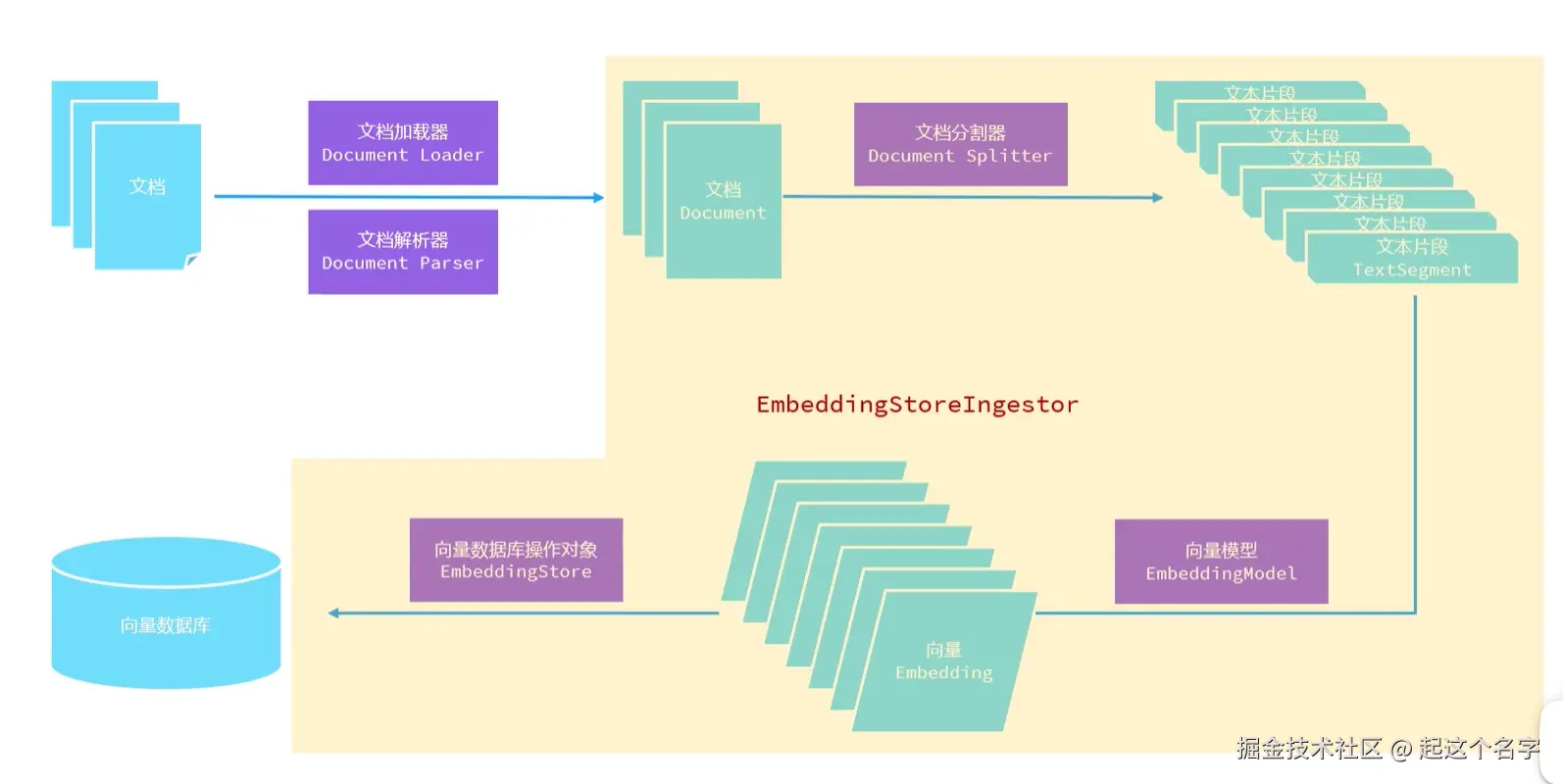
索引(存储)
向量存储步骤:
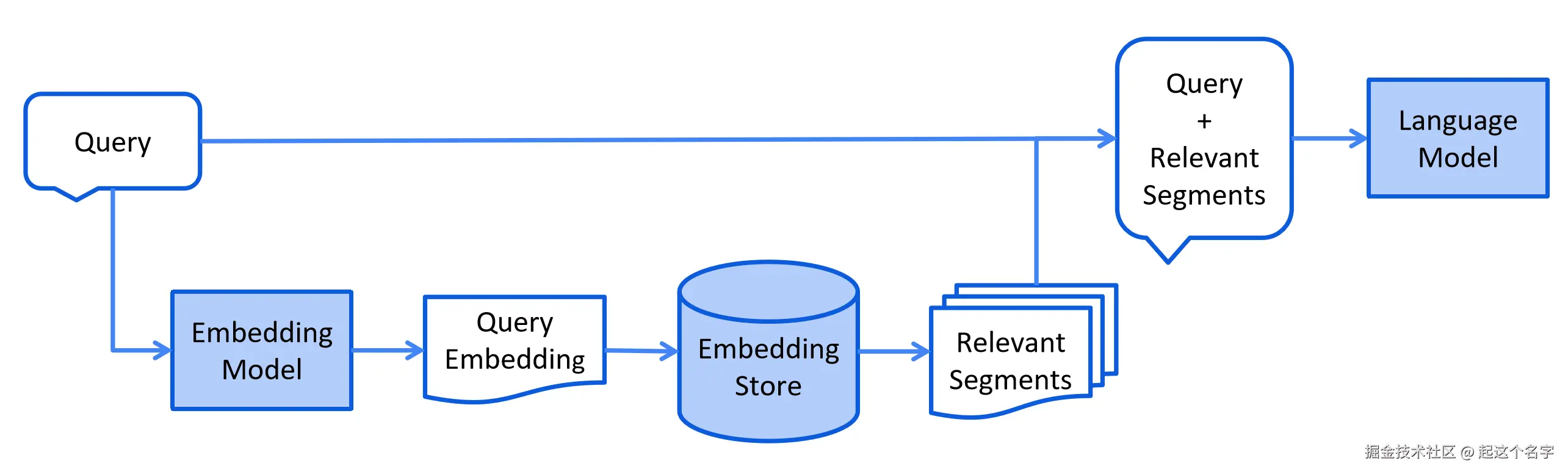
检索
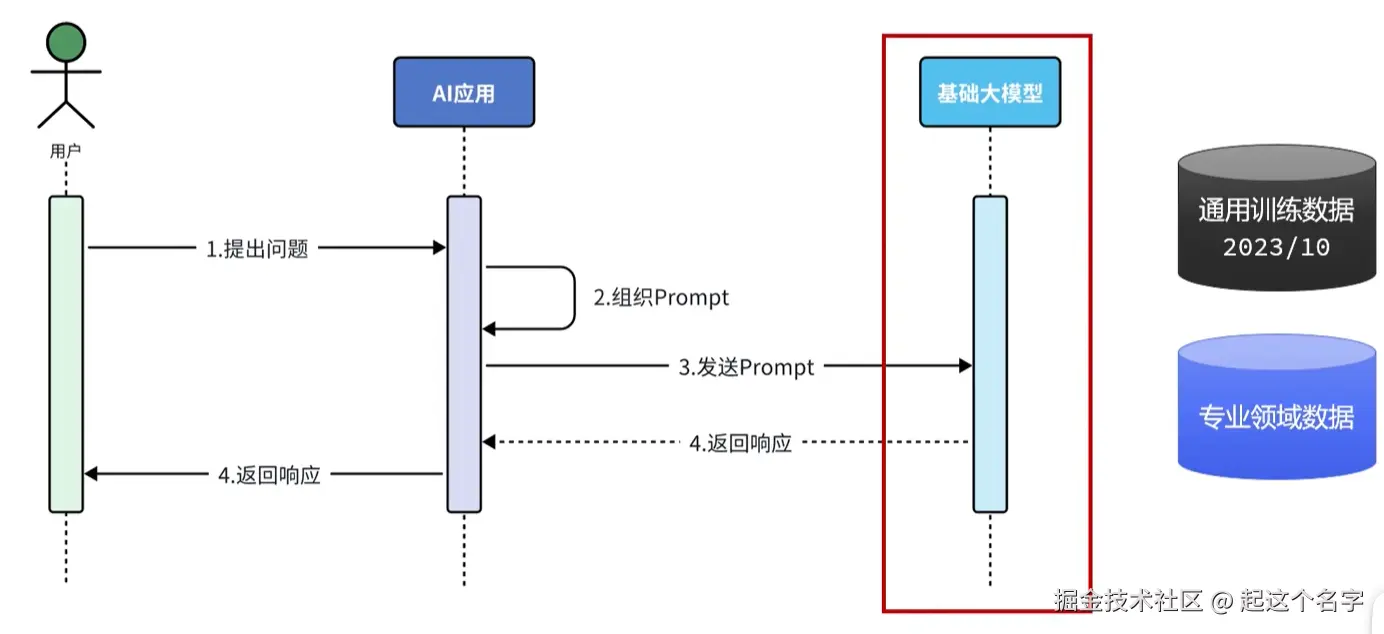
检索阶段通常在线进行,当用户提交一个应该使用索引文档回答的问题时。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及嵌入用户的查询(问题) 并在嵌入存储中执行相似度搜索。
然后将相关片段(原始文档的片段)注入到提示中并发送给 LLM。
<!-- 提供向量数据库和向量模型 -->
<dependency>
<groupld>dev.langchain4j</groupld>
<artifactld>langchain4j-easy-rag</artifactld>
<version>1.0.1-beta6</version>
</dependency>
List<Document> documents = ClassPathDocumentLoader.loadDocuments("文档路径");
InMemoryEmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
EmbeddingStorelngestor ingestor = EmbeddingStorelngestor.builder()
.embeddingStore(store)
.build();
ingestor.ingest(documents);
ContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(store) // 指定向量数据库
.maxResults(3) // 最高、最多检索结果的数量
.minScore(0.6) // 最小余弦相似度
.build();
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
contentRetriever = "retriever"
)
用于把磁盘或者网络中的数据加载进程序,常用的文档加载器:
用于解析使用文档加载器加载进内存的内容,把非纯文本数据转化成纯文本,常用的文档解析器:
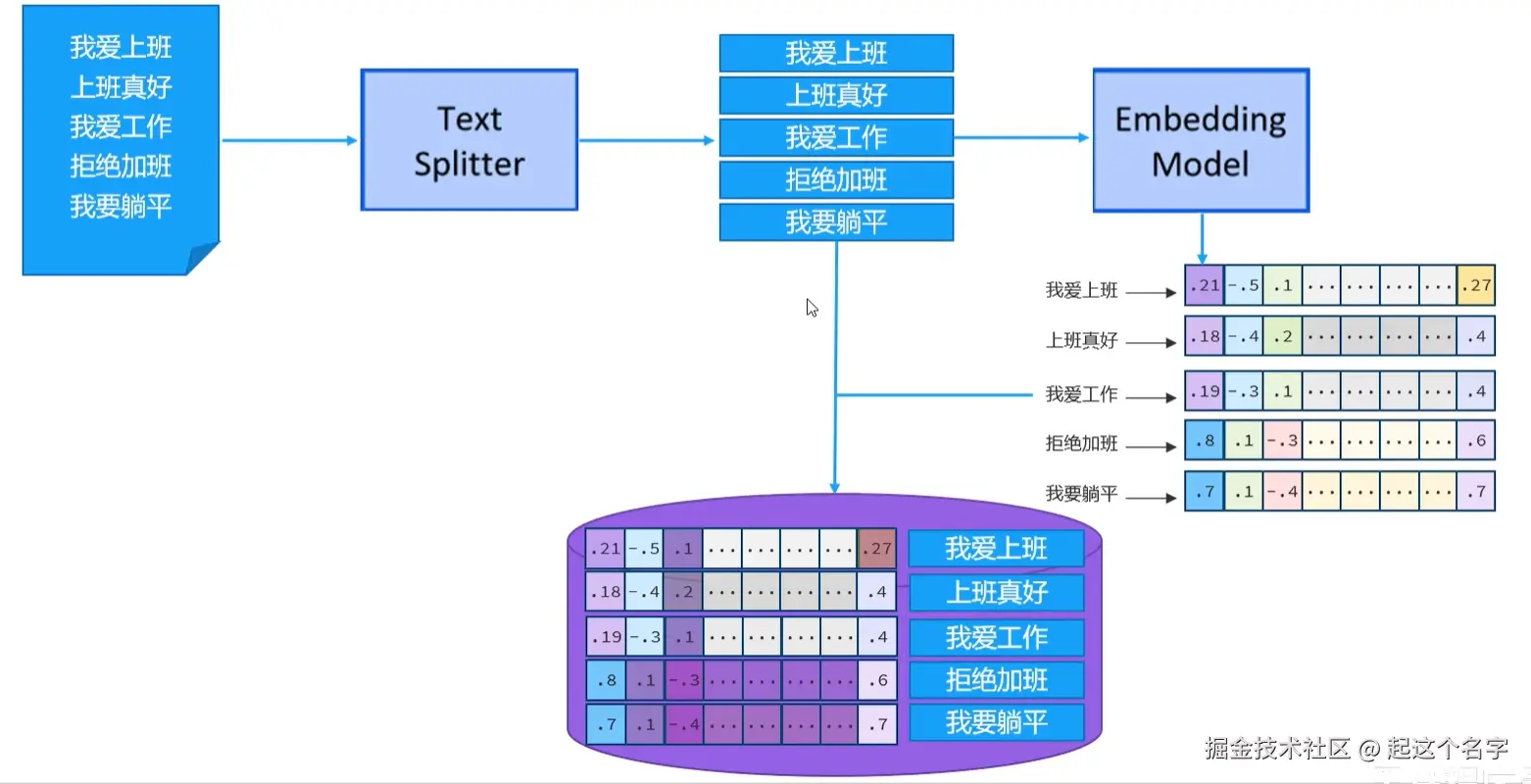
用于把一个大的文档,切割成一个一个的小片段,常用的文档分割器:
用于把文档分割后的片段向量化或者查询时把用户输入的内容向量化
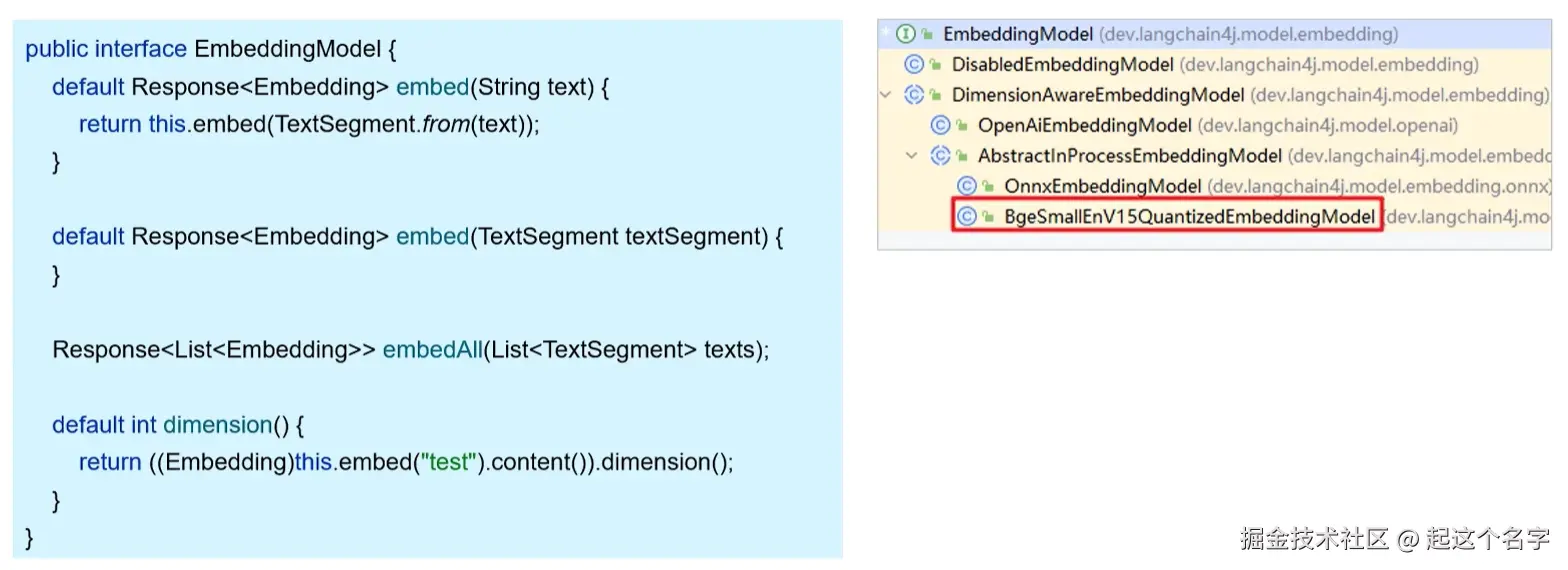
Langchain4j 内置的向量模型
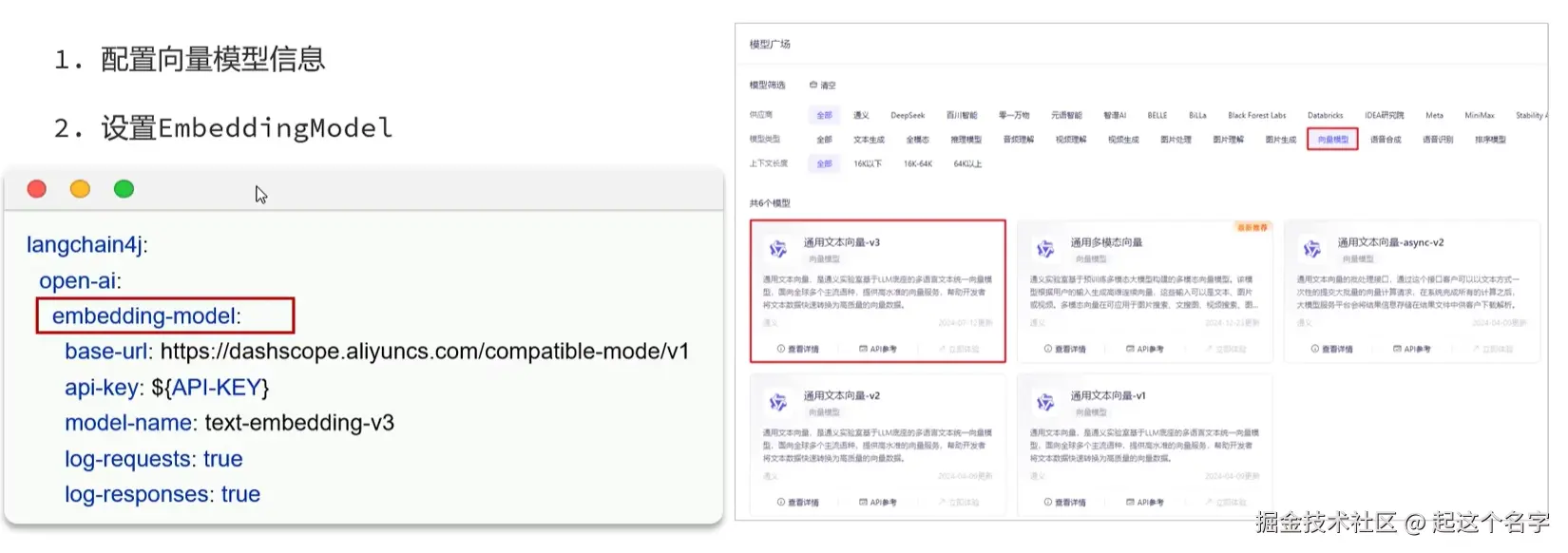
application.yml中配置第三方更强大的向量模型
EmbeddingStoreIngestor和EmbeddingStoreContentRetriever即可。
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.documentSplitter(ds)
.embeddingModel(embeddingModel)
.build();
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel)
.minScore(0.5)
.maxResults(3)
.build();
配置 RedisSearch 向量数据库
参考链接:
RAG 工作机制详解——一个高质量知识库背后的技术全流程
黑马程序员LangChain4j从入门到实战项目全套视频课程,涵盖LangChain4j+ollama+RAG
1.65G · 2025-12-24
157.25MB · 2025-12-24
170MB · 2025-12-24

