






我要当国王无广告版
24.16 MB · 2025-12-19


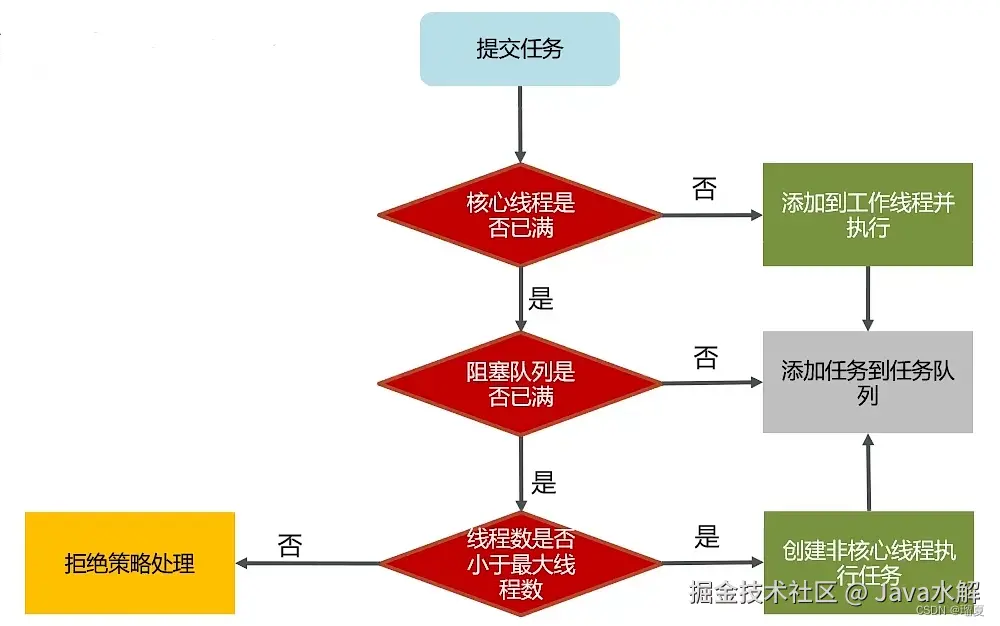
线程池的核心参数有七个:
corePoolSize:核心线程数
maximumPoolSize:最大线程数量,核心线程+救急线程的最大数量
keepAliveTime:救急线程的存活时间,存活时间内没有新任务,该线程资源会释放
unit:救济线程的存活时间的单位
workQueue:工作队列,当没有空闲核心线程时,新来的任务会在此队列排队,当该队列已满时,会创建应急线程来处理该队列的任务
treadFactory:线程工厂,可以定制线程的创建,线程名称,是否是[守护线程]等
handler:拒绝策略,在线程数量达到最大线程数量时,实行拒绝策略 拒绝策略:
线程池执行原理:
常见的阻塞队列有:
ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO
LinkedBlockingQueue:基于链表的有界阻塞队列,FIFO
两者区别(链表与数组的区别)
| ArrayBlockingQueue | LinkedBlockingQueue |
|---|---|
| 底层是数组 | 底层是链表 |
| 强制有界 | 默认无界,传递容量参数后有界 |
| 初始化时即创建好node对象数组 | 插入时才创建node对象 |
| 两把锁(头尾) | 一把锁 |
LinkedBlockingQueue的优点是锁分离,很适合生产和消费频率差不多的场景,这样生产和消费互不干涉的执行,能达到不错的效率
没有固定答案,先设定预期,比如我期望的 CPU 利用率在多少,负载在多少, GC 频率多少之类的指标后,再通过测试不断的调整到一个合理的 线程数
公式:
分三种情况
高并发,任务处理时间短 ——》CPU核数+1,减少线程上下文切换
并发不高,任务处理时间长 IO密集型任务——》CPU核数*2+1
读写多,DB操作多,CPU占用少,并且IO数据传输时,是不占用CPU的,所以就可以多释放CPU资源,给其他线程运行,
CPU密集型任务——》CPU核数+1
CPU占用高,如计算任务,视频解码任务,这些任务线程上下文切换开销大,所以要尽量减小开销,提高CPU效率
在JUC的Executor类中,提供了多种[创建线程池]的方法,主要有四种
1、固定线程数的线程池
核心线程数与最大线程数一样,没有救急线程
阻塞队列是LinkedBlockingQueue,最大容量是Integer.MaxValue
适合任务量已知,相对耗时的任务
2、单例线程的线程池
核心线程数和最大线程数都是1,没有救急线程
阻塞队列是LinkedBlockingQueue,最大容量是Integer.MaxValue
适合按顺序执行的任务,与单线程的区别是,单线程运行完了就会销毁,而线程池创建的线程运行结束不会销毁,而是等待下一个任务,可以重复使用,减少了创建线程和销毁线程的时间,提高资源利用率。
3、可缓存的线程池
核心线程数为0,最大线程数为Integer.MaxValue,救急线程存活时间为1分钟
阻塞队列为SynchronousQueue:不存储元素的阻塞队列,每一个插入操作必须等待一个移除操作
适合任务比较密集,且任务执行时间短的情况,因为使用的是救急线程,在一定时间没有新任务后就会销毁,节省资源,同时能应付任务密集的时间段。
4、可以定时执行的线程池
核心线程数自定义,最大线程数为Integer.MaxValue
适合需要定时执行任务的场景
1、批量将pgsql数据导入ES
计算数据总条数——》固定每页200条,计算总页数N——》将页数N设置为CountdownLatch的count——》创建N个线程批量导入,每次导入完调用countdown方法——》主线程中调用await方法,线程都执行完后,主线程结束
2、异步调用
用户搜索需要保存搜索记录,但保存功能不能影响正常搜索——》搜索时通过线程异步调用保存记录功能
关键注释:@EnableAsync加在SpringBoot启动类上,@Bean将自定义线程池注入到容器中(核心8,最大8), @Async("线程池名称")加在需要异步调用的方法上,
ThreadLocal是java.lang包中的一个类,它实现了线程之间的资源隔离,让每个线程都有自己的独立资源
ThreadLocal的底层实现的关键是它的静态内部类ThreadLocalMap
ThreadLocal内存泄漏问题:
回答这个问题,我们首先要知道java中的四种引用
强引用:强引用是最常见的,只要把一个对象赋值给一个引用变量,那么这个对象就被强引用了,强引用的对象只要不为null,就不会被回收
软引用:软引用相对弱化一些,需要用softReference对象构造方法去创建软引用,当内存充足时,软引用的对象不会被回收,当不足时就会被回收
弱引用:弱引用又更弱了一些,需要用weakReference的构造方法创建弱引用,当发送GC时,只要是弱引用的对象就会被回收
虚引用:虚引用要配合引用队列使用,它的主要作用是跟踪对象垃圾回收的状态,当对象被回收时,通过引用队列做一些通知类工作
在ThreadLocalMap中,Key ThreadLocal是一个弱引用,但是值value是一个强引用,当垃圾回收时,弱引用ThreadLocal会被回收,而value不会,这就导致value成了一个无法被访问也无法回收的变量,造成内存泄漏
解决办法:当使用完ThreadLocal变量后,及时使用remove方法进行清除。
static class Entry extends WeakReference<ThreadLocal<?>> {/** The value associated with this ThreadLocal. */Object value;Entry(ThreadLocal<?> k, Object v) {super(k);value = v;}}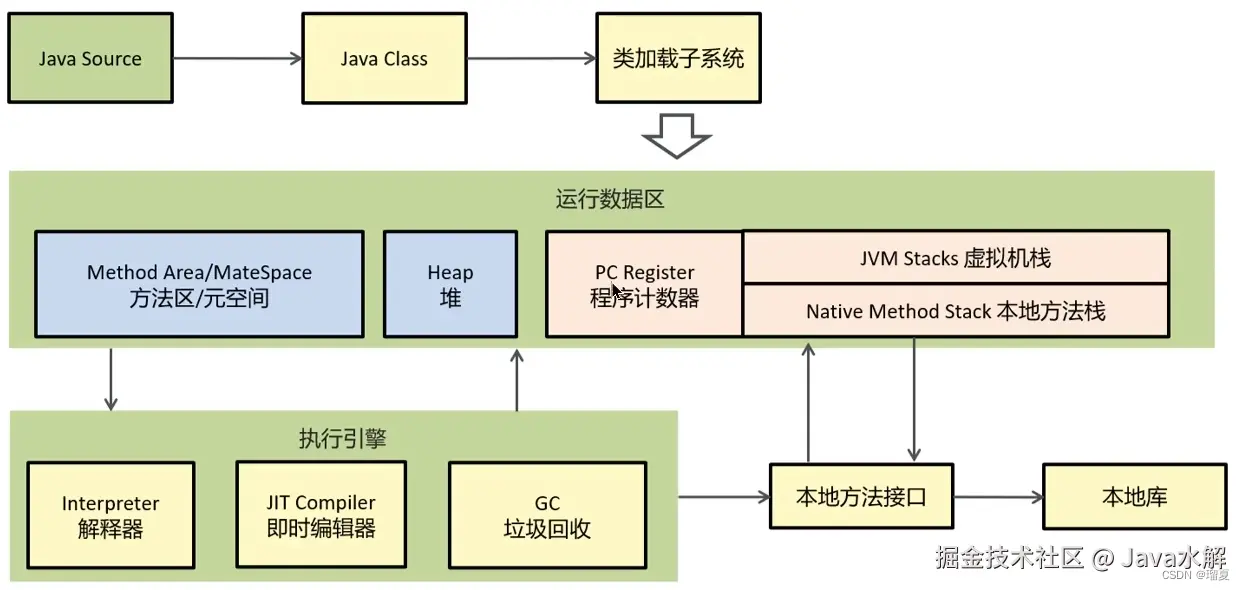
类加载器:将java字节码文件加载到内存中
运行时数据区:就是我们常说的JVM的内存,我们的所有程序都被加载到这运行
执行引擎:负责将字节码翻译成底层系统指令,然后交由系统执行
本地方法接口:与本地库交互实现一些基础功能
JVM运行时数据区由方法区(元空间),堆,程序计数器,虚拟机栈,本地方法栈组成
方法区/元空间:方法区是一个线程共享的区域,里面存储了类信息,常量,静态变量等待信息,虚拟机启动时创建,虚拟机关闭时释放,内存无法满足分配请求时,会报OOMError:Metaspace
堆:Java堆是一个线程共享的区域,里面存储了实例对象、数组等等,内存不够时抛出OOM异常
堆分为年轻代和老年代
程序计数器:用来记录当前线程正在执行的字节码指令地址,是线程私有的
虚拟机栈:虚拟机栈是java方法执行时的内存结构,线程私有,虚拟机会在每个java方法执行时开启一个栈帧,用于存储方法参数,局部变量,返回地址,操作数栈(中间计算结果,比如i+j的值)等信息,当方法执行完毕时,该方法会从虚拟机栈中出栈。
本地方法栈:本地方法栈是线程私有的,为虚拟机使用的native方法提高服务
如果栈的深度超过了虚拟机允许的最大深度,就会抛出StackOverflowError异常; 如果在扩展栈时无法申请到足够的内存,就会抛出OutOfMemoryError异常。
垃圾回收主要指的是堆内存,栈帧内存在栈帧出栈后就释放
每个虚拟机栈内存默认为1M
不一定,机器内存是固定的,栈内存越大,可以同时活动的栈帧就越少,效率反而降低
只要局部变量没有离开方法的作用范围,就是线程安全的
如果局部变量引用了一个对象,并且逃离了方法的作用范围,就有可能线程不安全
栈帧过多:比如太多层级的递归调用
栈帧过大:出现少
1、存放内容
堆中存放的是对象实例和数组,该区域更关注的是数据的存储,
(静态变量放在方法区,静态对象仍然放在堆中)
栈中存放的是局部变量,栈帧,操作数栈,返回结果等。该区更关注的是程序方法的执行。
然而实际上,对象并不总是在堆中进行分配的,这里就需要介绍一下JVM的逃逸分析技术了。JVM会通过逃逸分析技术,对于逃不出方法的对象,会让其在栈空间上进行分配。
2、程序的可见度
堆是线程共有的,栈是线程私有的。
3、异常错误
如果栈内存没有可用的空间存储方法调用和局部变量,JVM会抛出java.lang.StackOverFlowError。而如果是堆内存没有可用的空间存储生成的对象,JVM会抛出java.lang.OutOfMemoryError
4、物理地址
堆的物理地址是不连续的,性能相对较慢,是垃圾回收区工作的区域。在GC时,会考虑物理地址不连续,而使用不同的算法,比如复制算法,标记-整理算法,标记-清除算法等。
栈中的物理地址是连续的,LIFO原则,性能较快。
5、内存分别
堆因为是不连续的,所以分配的内存是在运行期确认的,因此大小不固定,一般堆大小远远大于栈。
栈是固定大小的,所以在编译期就确认了。
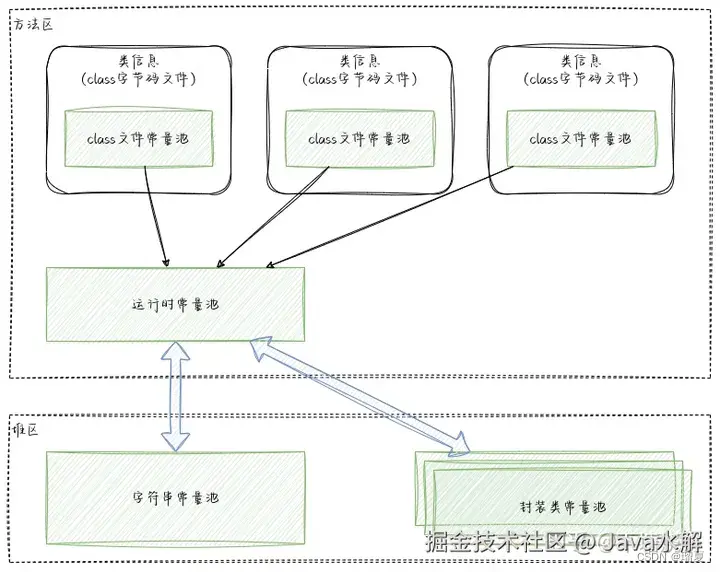
[JVM知识梳理之二_JVM的常量池]
运行时常量池是方法区的一部分,它可以看做是一张表,用于存放编译器生成的各种字面量和符号引用,在类被加载时,它的常量池信息就会被放入运行时常量池,并且还会保存符号引用对应的直接引用。
而字符串常量池是存放在堆里的,在HotSpot虚拟机中,它的底层是一个c++的hashtable,它将字符串的字面量作为key,实际堆中创建的String对象的引用作为value。
当创建一个String对象时,会拿着字面量尝试在字符串常量池中获取对应String对象引用,如果是首次执行,就会在堆中创建一个String对象,并保存到字符串常量池中,然后返回。
直接内存不属于JVM内存,是操作系统的内存,常见于NIO操作,用于数据缓冲区,拥有较高的读写性能,且不受JVM内存回收影响
BIO(同步阻塞IO)
发送请求后线程一直阻塞,直到数据处理完并返回
NIO(同步非阻塞IO)
通过一个线程轮询大量socket,当有socket准备就绪时通知客户端,客户端调用函数接收。
AIO(异步非阻塞IO)
当没有任何一个强引用指向对象时,对象就可以被垃圾回收
主流的虚拟机一般通过可达性分析算法分析一个对象是否能被回收,也有系统采用引用计数法判断
可达性分析算法:
1、算法主要思想是先确定一些肯定不能被回收的对象作为GCRoot, GCRoot对象可以是:
虚拟机栈中引用的对象
本地方法栈中Native方法引用的对象
方法区中静态属性,常量引用的对象
2、然后以GCRoot为根节点,去向下搜索,找到它们直接引用或间接引用的对象
3、在遍历完之后,如果发现有一些对象不可达,那么就认为这些对象已经没用用了,需要被回收
引用计数法:
就是为每一个对象添加一个引用计数器,用来统计指向当前对象的引用次数,一旦这个引用计数器变为0,就意味着它可以被回收了。
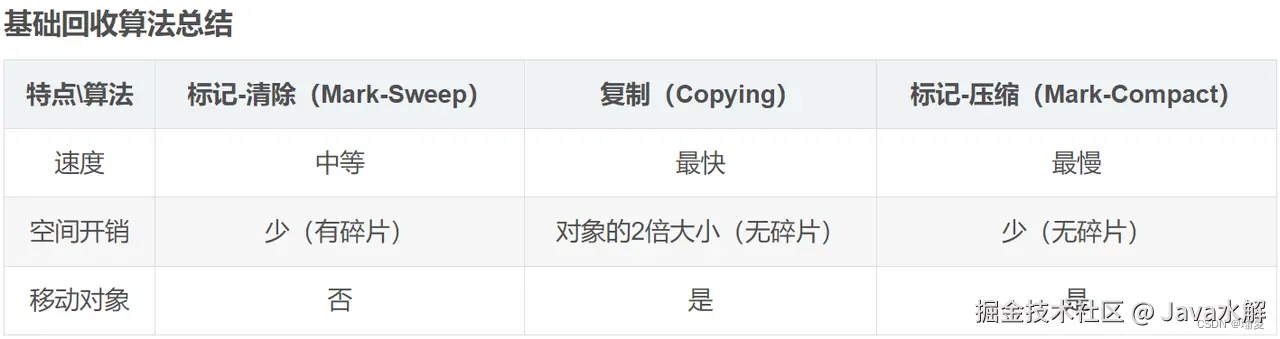
1、标记清除算法:标记清除算法分为两个步骤,标记-清除
标记:遍历内存空间,对需要被回收的对象打上标记,通常使用可达性分析算法
清除:再次遍历空间,将被标记的内存进行回收
缺点:
遍历两次,效率低
因为清除后没有进行整理,容易形成碎片化不连续的的内存空间
2、标记整理算法:标记整理算法分为三个步骤,标记-整理-清除
标记同上
整理:将所有存活的对象压到内存的一端,并按顺序排列
清除掉其他空间
缺点:
效率低,速度慢
3、复制算法:将内存分为等大的两块,每次只使用其中一块,当触发GC时,将存活的对象全部移到另一块内存的一端,然后将当前内存空间一次性回收,如此循环往复
缺点:内存利用率低
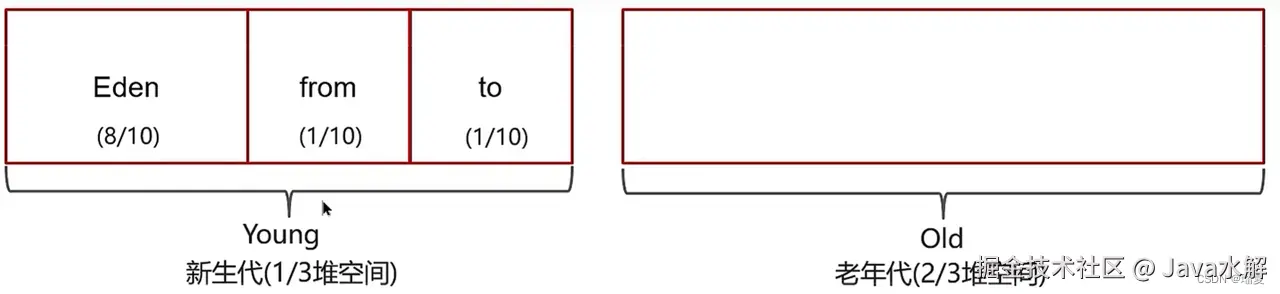
在java8中,内存被分为两份:新生代和老年代
新生代内存使用复制算法,老年代内存使用标记整理算法
当对象在新生代内存中经历了一定的垃圾回收后,它将被晋升到老年代。
分代收集算法重复利用了对象生命周期的特点,提高了回收效率
大对象直接进入老年代
什么是大对象呢,这个是由jvm定义的参数值决定的,但是这个参数只在Serial和ParNew垃圾收集器中生效 :-XX:PretenureSizeThreshold
当我们新分配的对象大小大于等于这个值,就会直接在老年代中分配
长期存活的对象将进入老年代
在每个对象的头信息中,都包括一个年龄计数器
对象在经过一次minor gc之后,如果仍然存活,并且能够被 survior所容纳 ,那么这个年龄计数器就会加一,当计数器的值达到了默认值大小(一般默认值为15),就会进入到老年代。
对象动态年龄判断后决定是否进入老年代
当survior区域的存活对象的总大小占用了survior区域大小的50%(可以通过参数指定),那么此时将按照这些对象的存活年龄从从到大排序,然后依次累加,当累加到对象大小超过50%,则将大于等于当前对象年龄的存活对象全部挪到老年代。
详细解释:
首先要知道Minor GC 和 Full GC的区别
普通GC(minor GC):只针对新生代区域的GC,指发生在新生代的垃圾回收动作,因为大多数Java对象存活率都不高,所以Minor GC非常频繁,一般回收速度也比较快。
全局GC(major GC or FullGC) :指发生在老年代的垃圾收集动作,出现了Major GC,经常会伴随至少一次的MinorGC(不是绝对的)。Major GC的速度一般要比Minor GC慢10倍以上。
该算法将内存分为新生代、老年代、新生代中又分伊甸园、幸存区from、幸存区to,对象创建之初,会存在于伊甸园中,当伊甸园满了之后,会触发一次Minor GC,伊甸园中还存活的对象会被转入幸存区from,当伊甸园再次触发Minor GC时,GC会扫描伊甸园和幸存区from,对这两个区进行垃圾回收,垃圾回收后,幸存区from中还存活的对象利用复制清除算法复制到幸存区to(如果有对象的年龄达到了老年代区,则复制到老年代区),复制完之后把幸存区from清除掉,之后把from区和to区交换位置(from变to,to变from,保证幸存区to为空),最后把伊甸园中存活下来的对象放入幸存区from,(如果有对象的年龄达到了老年代区,则复制到老年代区),同时把这些对象的年龄+1即可。
串行收集器:GC时只会有一个线程在工作,Java应用中的线程都要STW,等待垃圾回收结束
并行收集器:GC时会有多个线程参与垃圾收集,Java应用中的线程都要STW,等待垃圾回收结束,JVM默认
CMS(Concurrent Mark Sweep)收集器:并发收集器,进行垃圾回收时不会暂停Java应用线程,STW时间短,CMS收集器采用的是标记清除算法,所以不需要移动存活对象的位置,GC可以和Java应用程序同时运行
G1(Garbage-First)收集器:基于区域划分的收集器,适用于大内存应用。
G1是JDK9默认的垃圾收集器,代替了CMS收集器。它的目标是达到更高的吞吐量和更短的GC停顿时间。
G1垃圾回收器将堆内存划分为多个区域,每个区域都可以充当Eden,Survivor,old,humongous(专为大对象准备)
G1垃圾回收过程可以分为几个主要阶段:
1、初始标记:标记GCRoot直接关联的对象,需要STW
2、并发标记:对GCRoot开始对堆中对象进行并发标记,需要STW
3、重新标记:解决一些漏标错标问题,需要STW
4、混合收集:将不需要回收的eden,Survivor对象放入新的Survivor区,old对象放入新的old区,如果Survior对象达到老年年龄后也会放入新old区。然后将区域内存回收
要注意的是,混合收集不会处理所有区域,而是根据停顿时间目标去筛选出回收价值高(存活对象少)的区域。
类加载器是一个负责加载类的对象,因为JVM虚拟机只能运行二进制文件,类加载器的作用就是将字节码文件加载到JVM中运行。
JVM中有三个内置的类加载器
BootStrapClassLoader(启动类加载器):最顶层的加载器,由C++实现,主要用来加载Java的核心类裤(JAVA_HOME/lib)
ExtensionClassLoader(扩展类加载器) :主要负责加载JAVA_HOME/lib/ext下的扩展类
AppClassLoader(应用程序类加载器) :主要负责加载ClassPath下的类,也就是开发者自己写的Java类
另外,还有自定义ClassLoader,通过继承ClassLoader实现。
当一个类加载器尝试加载一个类时,会先委托上一级加载器去加载,如果上一级还有上级,就会委托上一级的加载器的上级去加载,如果所有上级加载器都不能加载该类,则类加载器尝试自己加载类。
作用:
1、防止重复加载:防止已经在上级加载器中加载的类重复地被子加载器再次加载
2、为了安全,防止核心类库API被篡改
3、保证类的一致性

