
缘之空安卓版汉化
1435MB · 2025-12-24

? 上节从 传统AI应用开发 的 "痛点" (需手动管理上下文、多步骤任务处理复杂、外部集成工具需大量样板代码、扩展性差) 引出了功能强大的 LangChain,然后系统讲解了 "七大核心组件" 中的前四个:Models (LLM模型配置)、Prompts (提示词模板)、Tools (工具函数) 和 Chains (链式调用-LCEL),本节把剩余几个组件过完~
记忆问题 & 解决链条:
无记忆 → 完整保存 → 成本过高 → 滑动窗口 → 丢失重要信息 → LLM智能压缩
↓
配置复杂 → 现代化API → 多用户混淆 → Session隔离 → 特殊需求 → 自定义Memory
↓
业务适配 → 角色提示 → 重启丢失 → 数据库存储 → 记忆质量参差 →
智能管理 (重要性评估 + 时间衰减) → 性能瓶颈 → 优化器 (压缩 + 关键信息提取 + 最近消息)
LangChain 的早期版本中 (v0.0.x) 存在多种专门的Memory类用于管理对话历史:
LangChain v0.1 引入了更灵活的接口 (与Chain对象紧密联合):
LangChain v0.3 正式推荐使用 LangGraph Persistence 作为主要的记忆管理方案:、
虽然官方推荐新项目使用 LangGraph,但过渡期的解决方案在简单应用中仍然非常实用,故先展开讲讲~
替代了旧版本的 ConversationChain,功能更强大更灵活,自动管理消息历史的读取、存储和注入。
conversation = RunnableWithMessageHistory(
runnable=chain, # 对话链
get_session_history=get_history, # 获取会话历史的函数
input_messages_key="input", # 输入消息的键名
history_messages_key="history", # 历史消息的键名
)
# 优势
# 自动注入: 在调用前自动将历史消息注入到提示模板中
# 自动保存: 在调用后自动保存新的用户输入和AI回复
# 会话隔离: 通过session_id实现多用户/多会话的完全隔离
# 无需手动管理: 不再需要手动调用save_context等方法
所有聊天消息历史存储类的抽象父类,定义了统一的接口标准,确保不同存储后端的接口一致性(内存、文件、数据库等),核心方法:
def add_message(self, message: BaseMessage) -> None:
"""添加单条消息到历史记录"""
pass
def clear(self) -> None:
"""清空历史记录"""
pass
@property
def messages(self) -> List[BaseMessage]:
"""获取所有历史消息列表"""
pass
最基础的 内存存储实现,简单直接,适用于短时间的对话会话或不需要持久化的简单应用
from langchain_community.chat_message_histories import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("你好")
history.add_ai_message("你好!很高兴见到你")
消息占位符,在提示模板中为历史消息预留位置,实现动态消息注入。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个友好的AI助手"),
MessagesPlaceholder(variable_name="history"), # 历史消息占位符
("human", "{input}")
])
:通过 session_id 实现多用户、多会话的独立记忆管理,代码示例:
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 使用时指定session_id
response = conversation.invoke(
{"input": "你好"},
config={"configurable": {"session_id": "user_123"}}
)
from langchain_openai import ChatOpenAI
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.chat_history import BaseChatMessageHistory
import os
# 1. 初始化LLM
llm = ChatOpenAI(
temperature=0,
api_key= os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
model=os.getenv("DEFAULT_LLM_MODEL")
)
# 2. 创建会话存储(Session管理)
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
"""实现BaseChatMessageHistory接口规范"""
if session_id not in store:
store[session_id] = ChatMessageHistory() # 使用ChatMessageHistory
return store[session_id]
# 3. 创建包含MessagesPlaceholder的提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是专业的客服代表,请友好、耐心地帮助客户解决问题。"),
MessagesPlaceholder(variable_name="history"), # 关键:历史消息占位符
("human", "{input}")
])
# 4. 创建对话链
chain = prompt | llm
# 5. 包装成具有记忆功能的RunnableWithMessageHistory
conversation = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
# 6. 多用户对话演示
def chat_with_customer(customer_id: str, message: str):
"""与特定客户对话"""
response = conversation.invoke(
{"input": message},
config={"configurable": {"session_id": customer_id}}
)
return response.content
# 测试多个客户
customers = [
("customer_001", "你好,我的订单有问题"),
("customer_002", "我想退换商品"),
("customer_001", "订单号是ABC123"), # 客户001继续对话
("customer_002", "商品质量不好"), # 客户002继续对话
]
# 分别处理两个客户的对话
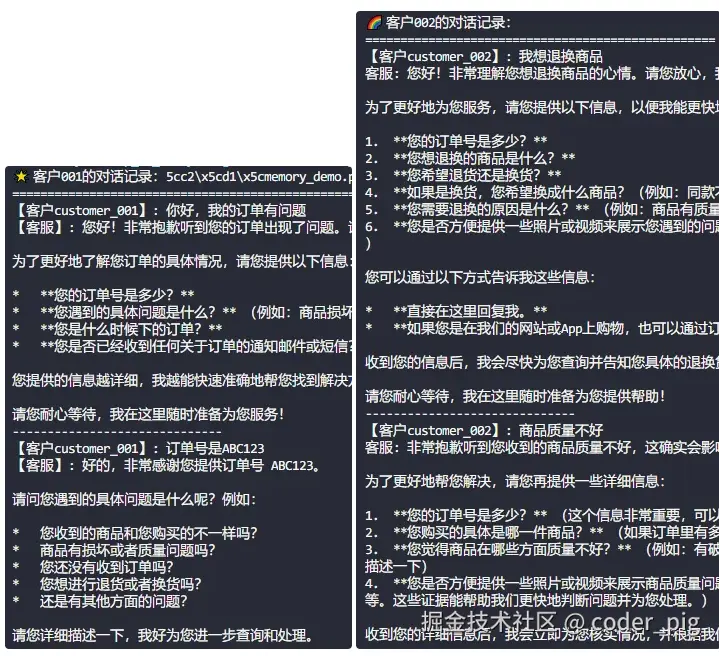
print("? 客户001的对话记录:")
print("="*50)
for customer_id, message in customers:
if customer_id == "customer_001":
response = chat_with_customer(customer_id, message)
print(f"【客户{customer_id}】: {message}")
print(f"【客服】: {response}")
print("-" * 30)
print("n? 客户002的对话记录:")
print("="*50)
for customer_id, message in customers:
if customer_id == "customer_002":
response = chat_with_customer(customer_id, message)
print(f"【客户{customer_id}】: {message}")
print(f"客服: {response}")
print("-" * 30)
运行输出结果:
? 传统Memory方案的局限性:
架构:
输入 → Memory读取 → LLM处理 → 输出 → Memory保存
↑___________________________|
LangGraph 的革命性改进:
架构:
[状态存储]
↕
输入 → [节点A] → [节点B] → [节点C] → 输出
↓ ↓ ↓
[检查点1] [检查点2] [检查点3]
① 状态 (State) —— 贯穿整个执行过程的数据容器
通常是一个 Python字典 或 Pydantic类型,在 LangGraph 中,定义 State 最常用和推荐的方式是使用 Python 的 TypedDict,这能为你提供代码补全和类型检查等好处。一个关键的特性是使用 Annotated 和 add_messages 来让 LangGraph 自动处理聊天消息的累积。
from typing import TypedDict, List, Annotated
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
class ConversationState(TypedDict):
"""
对话状态定义
'messages' 字段经过特殊注解,以实现消息的累积性追加,
而不是每次都被新消息覆盖。
"""
# 消息列表:使用 Annotated 和 add_messages 来累积对话历史
messages: Annotated[List[BaseMessage], add_messages]
# 以下字段将采用默认的覆盖更新策略
user_info: dict # 用户信息
context: str # 当前上下文
step: str # 当前步骤
metadata: dict # 元数据
② 节点 (Node) —— 执行具体逻辑的最小单元
代表工作流程中的一个个具体 "步骤" 或 "任务",负责执行具体的工作,在 LangGraph 中,节点本质上就是 Python 函数 或 LCEL Runnable 对象,它们接收当前的 State 作为输入,执行相应的逻辑(如:调用大语言模型、执行工具、访问数据库等),然后返回对状态的更新。从功能和约定的角度,可以归纳为以下几种:
【入口节点】
from langgraph.graph import StateGraph
# 假设 agent_node 是我们定义的一个节点函数
workflow = StateGraph(ConversationState)
workflow.add_node("agent", agent_node)
workflow.set_entry_point("agent")
【常规节点】
def my_logic_node(state: ConversationState):
# ... 执行一些逻辑 ...
updated_state = {"context": "new_value"}
return updated_state
workflow.add_node("my_node", my_logic_node)
【工具节点】
from langgraph.prebuilt import ToolNode
# 'tools' 是一个工具列表
tool_node = ToolNode(tools)
workflow.add_node("tools", tool_node)
【结束节点】
# 在条件边的逻辑中,如果满足某个条件,就返回 END
def should_continue(state: AgentState):
if some_condition:
return "end" # 'end' 会被映射到 END 节点
else:
return "continue_node"
workflow.add_conditional_edges(
"start_node",
should_continue,
{"continue": "continue_node", "end": END}
)
③ 边 (Edge) —— 节点之间的执行流程
定义了节点之间的连接关系和流程的走向,是 LangGraph 实现复杂控制流的关键。类型有这几种:
【常规边】
# 从 'node_A' 执行完后,总是流向 'node_B'
workflow.add_edge("node_A", "node_B")
【条件边】
#【条件函数】一个接收当前状态作为输入的函数,返回值 (通常是一个字符串) 将决定走哪条路径。
def router_function(state: AgentState):
if "tool_calls" in state["messages"][-1].additional_kwargs:
return "execute_tools"
else:
return "end_process"
workflow.add_conditional_edges(
"agent_node", #【起始节点】条件判断发生的节点
router_function,
#【路径映射】一个字典,将条件函数的返回值映射到具体的下一个节点名称
{
"execute_tools": "tools_node",
"end_process": END
}
)
【入口条件边】
def initial_router(state: AgentState):
if state["is_simple_question"]:
return "chatbot_node"
else:
return "agent_with_tools_node"
workflow.set_conditional_entry_point(
initial_router,
{
"chatbot_node": "chatbot_node",
"agent_with_tools_node": "agent_node"
}
)
④ 检查点 (Checkpoint) —— 状态在特定时刻的快照
指在图的每个执行步骤之后,将当前的 "State快照" 保存到持久化存储 (如:数据库) 中的机制。它的好处包括:
LangGraph 内置了多种检查点后端:
核心要点 在于在 compile 时加入 checkpointer,并在 invoke 时提供一个唯一的 thread_id,这样,你就开启了LangGraph 的 "记忆" 功能。简单代码示例:
from langgraph.checkpoint.sqlite import SqliteSaver
# 1. 定义一个检查点后端
# 'conn' 是一个数据库连接对象
memory_saver = SqliteSaver.from_conn_string(":memory:") # 使用内存中的 SQLite 进行演示
# 2. 在编译 (compile) 图时,将 checkpointer 传入
# workflow = ... (你已经定义好的 StateGraph)
app = workflow.compile(checkpointer=memory_saver)
# 3. 在调用图时,提供一个可配置的 'thread_id'
# 'thread_id' 就像是每个独立对话的“存档文件名”
# 同一个 'thread_id' 的调用会共享同一个历史记录
user_input = "你好吗?"
config = {"configurable": {"thread_id": "user_123"}}
# 第一次调用
response = app.invoke({"messages": [("human", user_input)]}, config=config)
print(response)
# 第二次调用,LangGraph 会自动加载 'user_123' 的历史状态
user_input_2 = "我刚才问了你什么?"
response_2 = app.invoke({"messages": [("human", user_input_2)]}, config=config)
print(response_2) # 模型将能够回答出 "你好吗?"
先 pip install langgraph langgraph-checkpoint 安装下依赖,导入必要模块:
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.sqlite import SqliteSaver
from typing import TypedDict, List
from langchain_openai import ChatOpenAI
import os
① 定义状态
class SimpleConversationState(TypedDict):
"""简单对话状态"""
messages: List[str]
user_name: str
step_count: int
② 创建节点
def greet_node(state: SimpleConversationState) -> SimpleConversationState:
"""问候节点"""
print(f"? 欢迎 {state['user_name']}!")
return {
**state,
"messages": state["messages"] + ["你好!很高兴认识你!"],
"step_count": state["step_count"] + 1,
}
def chat_node(state: SimpleConversationState) -> SimpleConversationState:
"""对话节点"""
llm = ChatOpenAI(
temperature=0,
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
model=os.getenv("DEFAULT_LLM_MODEL"),
)
# 获取最新消息
latest_message = state["messages"][-1] if state["messages"] else ""
# 生成回复
response = llm.invoke(f"回复用户:{latest_message}")
return {
**state,
"messages": state["messages"] + [response.content],
"step_count": state["step_count"] + 1,
}
def end_node(state: SimpleConversationState) -> SimpleConversationState:
"""结束节点"""
print(f"? 对话结束,共进行了 {state['step_count']} 步")
return state
③ 构建图
def create_simple_chat_graph():
"""创建简单聊天图"""
# 初始化图
graph = StateGraph(SimpleConversationState)
# 添加节点
graph.add_node("greet", greet_node)
graph.add_node("chat", chat_node)
graph.add_node("end", end_node)
# 设置入口点
graph.set_entry_point("greet")
# 添加边
graph.add_edge("greet", "chat")
graph.add_edge("chat", "end")
graph.add_edge("end", END)
# 配置检查点
checkpointer = MemorySaver()
# 编译图
app = graph.compile(checkpointer=checkpointer)
return app
④ 运行图
def demo_simple_chat():
"""演示简单聊天"""
# 创建应用
app = create_simple_chat_graph()
# 初始状态
initial_state = {
"messages": ["你好,我是新用户"],
"user_name": "张三",
"step_count": 0,
}
# 执行图
config = {"configurable": {"thread_id": "user_001"}}
result = app.invoke(initial_state, config=config)
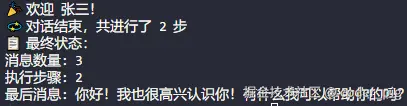
print("? 最终状态:")
print(f"消息数量: {len(result['messages'])}")
print(f"执行步骤: {result['step_count']}")
print(f"最后消息: {result['messages'][-1]}")
运行输出结果:
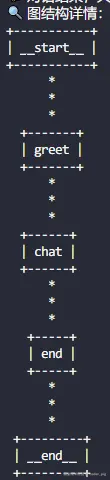
? 对图结构感兴趣,可以调用 get_graph() 获取图结构详情:
print(json.dumps(app.get_graph().to_json(), indent=2, ensure_ascii=False))
# 输出结果
{
"nodes": [
{
"id": "__start__",
"type": "runnable",
"data": {
"id": [
"langgraph",
"_internal",
"_runnable",
"RunnableCallable"
],
"name": "__start__"
}
},
{
"id": "greet",
"type": "runnable",
"data": {
"id": [
"langgraph",
"_internal",
"_runnable",
"RunnableCallable"
],
"name": "greet"
}
},
{
"id": "chat",
"type": "runnable",
"data": {
"id": [
"langgraph",
"_internal",
"_runnable",
"RunnableCallable"
],
"name": "chat"
}
},
{
"id": "end",
"type": "runnable",
"data": {
"id": [
"langgraph",
"_internal",
"_runnable",
"RunnableCallable"
],
"name": "end"
}
},
{
"id": "__end__"
}
],
"edges": [
{
"source": "__start__",
"target": "greet"
},
{
"source": "chat",
"target": "end"
},
{
"source": "greet",
"target": "chat"
},
{
"source": "end",
"target": "__end__"
}
]
还可以安装 grandalf 依赖库,然后以 ASCII文本图 的可视化形式展示图结构:
print(app.get_graph().draw_ascii())
运行输出结果:
? 还可以安装 Graphviz软件 + pygraphviz库 来实现更精美的可视化效果。
? LLM 的知识来源于其庞大的、固定的训练数据,这导致了两个局限性:
? 为了解决这个问题,检索增强生成 (RAG,Retrieval Augmented Generation) 应运而生,它的核心思想非常简单——"开卷考试",当用户提出一个问题时,不直接把问题丢给LLM,而是先从 "私有知识库" 中 "检索相关信息",再连同 "原始问题" 一起作为 "上下文增强" 后的 "提示词",再交给 LLM 去生成答案。这样做的好处:
?♂️ LangChain 的 Indexes 组件正式实现 RAG流程 的 "基石",它提供了一整套工具将原始数据处理成一种结构化的、便于LLM高效查询和利用的形式。这个处理过程,就是 "索引的构建过程",通常包含四大核心环节:文档加载、文本分割、向量存储、文档检索。接下来,逐一深入讲解这四个环节~
文档源 → Document Loaders → Text Splitters → Embeddings → Vector Stores → Retrievers
↓ ↓ ↓ ↓ ↓ ↓
PDF/网页 加载文档 文本分割 向量化 向量存储 相似度检索
一个标准的 Document 对象包含两个核心部分:
from langchain_core.documents import Document
# Document包含两个主要属性
doc = Document(
page_content="这是文档的主要内容", # 文本内容
metadata={ # 元数据
"source": "example.pdf",
"page": 1,
"author": "张三"
}
)
LangChain 为不同的数据源提供了相应的加载器,如:文本文件 → TextLoader,PDF文件 → PyPDFLoader、网页内容 → WebBaseLoader、CSV文件 → CSVLoader。简单代码示例:
# 示例:加载一个PDF文件
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("path/to/your/document.pdf")
documents = loader.load()
# 'documents' 现在是一个 Document 对象的列表
# 列表中的每个对象通常对应PDF的一页
print(documents[0].page_content[:200]) # 打印第一页的前200个字符
print(documents[0].metadata) # 打印第一页的元数据
LangChain 中最常用且推荐的分割器是 RecursiveCharacterTextSplitter,它的工作方式非常智能:
分割时的两个关键参数:
简单代码示例:
# 示例:分割已加载的文档
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个块的最大字符数
chunk_overlap=200 # 相邻块的重叠字符数
)
chunks = text_splitter.split_documents(documents)
# 'chunks' 现在是一个新的 Document 对象列表,但内容是分割后的小块
print(f"原始文档数量: {len(documents)}")
print(f"分割后块的数量: {len(chunks)}")
这就需要借助这两样东西了:
简单代码示例:
# 示例:将文本块嵌入并存储到 Chroma 向量数据库中
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# 1. 初始化嵌入模型
embeddings_model = OpenAIEmbeddings()
# 2. 从文本块创建向量存储
# 这会处理好所有的嵌入计算和存储过程
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings_model
)
简单代码示例:
# 示例:从向量存储创建一个检索器并使用它
# 1. 创建检索器
retriever = vectorstore.as_retriever(
search_type="similarity", # 相似度搜索
search_kwargs={"k": 3} # 返回top-3结果
)
# 2. 使用检索器进行查询
query = "LangChain的索引组件包含哪些部分?"
relevant_docs = retriever.invoke(query)
# 'relevant_docs' 是一个根据查询的语义相似度排序的 Document 列表
print(relevant_docs[0].page_content)
上面调 as_retriever() 创建的是 "最基础的检索器",它执行的是 "语义相似度搜索", 在真实复杂的业务场景下,单纯的语义相似度可能并不够用,LangChain为此提供了多种更先进的检索策略。
很多时候,用户的查询中不仅包含了语义信息,还可能隐含了结构化的元数据过滤条件,如:给我找一下2023年之后,关于LangChain V0.1.0版本的更新文档。
如果用简单的向量搜索,它可能会找回所有关于LangChain更新的文档,而无法精确满足年份和版本的限制。而 自查询检索器非常巧妙:
概念代码示例:
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
# 1. 定义你的元数据字段
metadata_field_info = [
AttributeInfo(name="year", description="文档发布的年份", type="integer"),
AttributeInfo(name="version", description="文档对应的LangChain版本", type="string"),
]
# 2. 创建自查询检索器
# retriever = SelfQueryRetriever.from_llm(
# llm, vectorstore, document_content_description, metadata_field_info
# )
# 3. 执行查询
# relevant_docs = retriever.invoke(
# "关于LangChain V0.1.0版本,2023年之后的更新文档"
# )
? 在做文本分割时常常面临一个两难的困境:
父文档检索器 则优雅地解决了这个问题。它的索引构建分为两步:
在检索时,它先用用户查询去匹配最相关的小 "子块",但最终返回给用户或LLM的,是这些子块所对应的、拥有完整上下文的"父块"。 这就实现了 "用小块精准检索,用大块生成答案" 的理想效果。
? 集成检索器 可以将多个不同的检索器组合在一起。当用户查询时,它会分别调用内部的每一个检索器,然后使用一种特定的算法 (如 Reciprocal Rank Fusion) 来重新排序和融合所有检索结果,最终返回一个综合了多种算法优势的最佳结果列表。概念代码示例:
# 概念代码示例
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# 1. 准备你的文档和块
# ...
# 2. 初始化两个不同的检索器
bm25_retriever = BM25Retriever.from_documents(docs)
faiss_vectorstore = FAISS.from_documents(docs, embeddings_model)
faiss_retriever = faiss_vectorstore.as_retriever()
# 3. 创建集成检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever],
weights=[0.5, 0.5] # 可以为不同检索器的结果设置权重
)
# 4. 执行查询
# relevant_docs = ensemble_retriever.invoke("你的查询")
? 在之前的讲解中,索引构建流程(加载->分割->嵌入->存储)是一个一次性的、同步的过程,但在实际生产环境中,往往会面临更复杂的需求,如:
LangChain 提供了一个强大的 indexing API 来解决以上问题,它通过一个 "记录管理器" (Record Manager) 来跟踪哪些文档已经被处理和索引。其核心逻辑:
Indexing API 确保了我们的向量存储与原始数据源能够高效、低成本地保持同步,是构建生产级RAG应用不可或缺的一环。
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
def build_knowledge_qa_system():
"""构建知识库问答系统的函数"""
# 1. 加载文档
print("? 正在加载文档...")
loader = DirectoryLoader(
"knowledge_base/",
glob="*.txt",
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8"}
)
documents = loader.load()
print(f"加载了 {len(documents)} 个文档")
# 2. 分割文本
print("✂️ 正在分割文本...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
splits = text_splitter.split_documents(documents)
print(f"分割成 {len(splits)} 个文本块")
# 3. 创建向量存储
print("? 正在创建向量索引...")
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splits, embeddings)
# 4. 创建检索器
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 3, "fetch_k": 6}
)
# 5. 创建问答链
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
verbose=True
)
return qa_chain
def test_qa_system():
"""测试问答系统的函数"""
qa_chain = build_knowledge_qa_system()
questions = [
"什么是机器学习?",
"深度学习有哪些应用?",
"如何选择合适的算法?"
]
for question in questions:
print(f"n❓ 问题: {question}")
result = qa_chain.invoke({"query": question})
print(f"? 答案: {result['result']}")
print("? 参考来源:")
for doc in result['source_documents']:
print(f" - {doc.metadata.get('source', 'unknown')}")
import pandas as pd
from langchain_core.documents import Document
def build_product_recommendation_system():
"""构建产品推荐系统的函数"""
# 1. 准备产品数据
def prepare_product_documents():
"""准备产品文档的内部函数"""
# 模拟产品数据
products_data = [
{
"id": "P001",
"name": "iPhone 15 Pro",
"category": "手机",
"brand": "Apple",
"price": 8999,
"description": "配备A17 Pro芯片的高端智能手机,拥有钛金属机身和48MP主摄像头",
"features": ["A17 Pro芯片", "钛金属", "48MP摄像头", "5G网络"]
},
{
"id": "P002",
"name": "MacBook Air M2",
"category": "笔记本电脑",
"brand": "Apple",
"price": 9499,
"description": "搭载M2芯片的轻薄笔记本电脑,13.6英寸Liquid视网膜显示屏",
"features": ["M2芯片", "13.6英寸", "轻薄设计", "全天候电池"]
},
{
"id": "P003",
"name": "小米13 Ultra",
"category": "手机",
"brand": "小米",
"price": 5999,
"description": "专业摄影旗舰手机,徕卡光学镜头,骁龙8 Gen2处理器",
"features": ["徕卡镜头", "骁龙8 Gen2", "专业摄影", "快充技术"]
}
]
documents = []
for product in products_data:
# 将产品信息组合成文本
content = f"""
产品名称: {product['name']}
品牌: {product['brand']}
分类: {product['category']}
价格: ¥{product['price']}
描述: {product['description']}
特性: {', '.join(product['features'])}
"""
doc = Document(
page_content=content.strip(),
metadata={
"product_id": product['id'],
"name": product['name'],
"category": product['category'],
"brand": product['brand'],
"price": product['price']
}
)
documents.append(doc)
return documents
# 2. 构建产品向量索引
documents = prepare_product_documents()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 3. 创建推荐检索器
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 3, "lambda_mult": 0.8} # 更注重多样性
)
return retriever
def product_recommendation_demo():
"""产品推荐演示函数"""
retriever = build_product_recommendation_system()
# 模拟用户查询
user_queries = [
"我想要一个拍照好的手机",
"推荐一个适合办公的笔记本电脑",
"有什么苹果的产品推荐吗?",
"性价比高的手机有哪些?"
]
for query in user_queries:
print(f"n? 用户查询: {query}")
docs = retriever.invoke(query)
print("? 推荐产品:")
for i, doc in enumerate(docs):
product_name = doc.metadata['name']
price = doc.metadata['price']
print(f" {i+1}. {product_name} - ¥{price}")
from langchain_community.document_loaders import PyPDFLoader, CSVLoader
from langchain.text_splitter import CharacterTextSplitter
def build_multimodal_document_system():
"""构建多模态文档检索系统的函数"""
def load_multiple_document_types():
"""加载多种类型文档的内部函数"""
all_documents = []
# 加载PDF文件
pdf_loader = PyPDFLoader("reports/annual_report.pdf")
pdf_docs = pdf_loader.load()
for doc in pdf_docs:
doc.metadata["doc_type"] = "PDF报告"
all_documents.extend(pdf_docs)
# 加载CSV文件
csv_loader = CSVLoader("data/sales_data.csv")
csv_docs = csv_loader.load()
for doc in csv_docs:
doc.metadata["doc_type"] = "销售数据"
all_documents.extend(csv_docs)
# 加载文本文件
text_loader = DirectoryLoader(
"documents/",
glob="*.txt",
loader_cls=TextLoader
)
text_docs = text_loader.load()
for doc in text_docs:
doc.metadata["doc_type"] = "文本文档"
all_documents.extend(text_docs)
return all_documents
# 1. 加载所有文档
print("? 正在加载多种格式文档...")
documents = load_multiple_document_types()
print(f"总共加载了 {len(documents)} 个文档")
# 2. 智能分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=100,
separators=["nn", "n", "。", ",", " ", ""]
)
splits = text_splitter.split_documents(documents)
# 3. 创建向量存储
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
splits,
embeddings,
persist_directory="./multimodal_db"
)
# 4. 创建智能检索器
retriever = vectorstore.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"score_threshold": 0.7,
"k": 5
}
)
return retriever
def multimodal_search_demo():
"""多模态检索演示函数"""
retriever = build_multimodal_document_system()
queries = [
"2023年的销售额是多少?", # 可能来自CSV或PDF
"公司的发展战略是什么?", # 可能来自文本文档
"最新的产品发布情况", # 可能来自多种文档类型
]
for query in queries:
print(f"n? 查询: {query}")
docs = retriever.invoke(query)
print("? 相关文档:")
for doc in docs:
doc_type = doc.metadata.get('doc_type', 'unknown')
source = doc.metadata.get('source', 'unknown')
content_preview = doc.page_content[:100] + "..."
print(f" 类型: {doc_type}")
print(f" 来源: {source}")
print(f" 内容: {content_preview}")
print(" ---")
想象一下你有一个非常聪明的助理?,你告诉它 "帮我查一下明天深圳的天气怎么样,如果下雨的话,就提醒我带伞"。在这个场景中:
除了 LLM 和 Tools 外,还需要一个 Agent Executor,这是Agent的 "执行器" 或者说 "运行时环境",它负责协调LLM 和 Tools之间的交互,循环地执行以下步骤,直到任务完成:
这个循环的过程,通常被称为 "ReAct" (Reasoning and Acting) 循环。
用户输入 → Agent → Tool Selection → Tool Execution → Result Analysis → 下一步决策
↓ ↓ ↓ ↓ ↓ ↓
"计算题" 思考工具 选择计算器 执行计算 分析结果 返回答案
第一轮:
第二轮:
第三轮:
通过这个例子,我们可以清晰地看到,Agent通过LLM的推理能力,将一个复杂问题分解成了多个可执行的子任务,并利用工具一步步地找到答案,这就是Agent的强大之处?。
基础也最经典的Agent类型,完全基于上面讲过的 ReAct 框架,命名解读:
工作流程:
优点:通用性强,是理解Agent工作原理的最佳范例。
缺点: 严重依赖LLM的格式遵循能力,有时LLM可能会"忘记" 输出特定格式,导致解析失败。
通过 "自问自答" 的方式将复杂问题分解,它专门设计用于一个单一但强大的工具:搜索 (Search)。工作流程:
? 对于需要通过多次搜索、层层递进才能解决的问题非常有效,思考路径清晰。不过应用场景相对受限,因为它被设计为只使用搜索这一个工具。
? 专门为与 文档知识库 (如Wikipedia) 交互而设计的Agent,通常配备两个专属工具:
工作流程:
? 上面的 "标准Agent" 是 "构建Agent的旧范式",其核心工作方式可以概括为 "基于纯文本的指令模拟",即用软件工程的 "补丁" (复杂的Prompt和Parser) 去弥补 旧LLM 的能力不足,"假装" LLM能调用工具。像 GPT-4、Gemini、Claude 4等现代LLM,它们本身就被训练和设计成能够理解 "工具" 和 "函数" ****的改变。这时就不需要我们去 "教" 了,这是它们的 "原生能力"。create_tool_calling_agent (llm,tools,prompt) 就是 LangChain 中利用并统一了这种原生能力的 "标准化接口"。新范式的工作流程:
# LLM输出不再是Action: Search... 这样的文本,而是类似这样的数据结构:
{
"tool_calls": [
{
"name": "search_web",
"arguments": {
"query": "LangChain latest version",
"engine": "google"
}
}
]
}
其它 Agent create_xxx() 工厂方法:
?♂️ LangChain 中负责驱动 Agent 执行任务的 "运行时环境",扮演 "总指挥" 的角色,接收用户输入后:
简单使用示例:
# ① 准备LLM
llm = ChatOpenAI(temperature=0, model="gpt-4") # temperature=0 确保输出更稳定
# ② 准备Tools
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# ③ 初始化 AgentExecutor
# initialize_agent 是一个便捷的函数,它将 LLM, Tools 和一个预设的 Agent 封装在一起
# AgentType.ZERO_SHOT_REACT_DESCRIPTION 是最常用的一种 Agent 类型
# verbose=True 可以让我们看到 Agent 的完整思考过程
agent_executor = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# ④ 调用 invoke() 运行 AgentExecutor
response = agent_executor.invoke({
"input": "目前英伟达的股价是多少?如果我买15股,需要多少美元?"
})
print(response)
? 逐步实现一个 "获取单词长度+计算" 的 Agent,如 "单词 'LangChain' 的长度乘以 5 是多少?"
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
import os
# ================================
# ? ① 选择支持工具调用的LLM
# ================================
llm = ChatOpenAI(
temperature=0, # 设置为0可以使模型的输出更具确定性,对于需要精确执行工具的Agent任务来说通常是更好的选择。
api_key= os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
model=os.getenv("DEFAULT_LLM_MODEL")
)
两个工具:一个用于计算乘法,一个用于获取单词长度。
# ================================
# ? ② 定义 Tools
# 关键点:
# 1. 清晰的函数名:`multiply`,让LLM一眼就能看懂其功能。
# 2. 详细的文档字符串(docstring):`"""计算两个整数的乘积。"""`,这是最重要的!LLM将依赖这个描述来决定何时以及如何使用该工具。
# 3. 明确的类型注解:`(a: int, b: int) -> int`,这帮助LLM理解输入和输出的数据类型,生成正确的参数。
# ================================
@tool
def multiply(a: int, b: int) -> int:
"""计算两个整数的乘积。"""
print(f"--- 调用工具 [multiply] --- 参数: a={a}, b={b}")
return a * b
@tool
def get_word_length(word: str) -> int:
"""返回一个单词的长度。"""
print(f"--- 调用工具 [get_word_length] --- 参数: word='{word}'")
return len(word)
# 将所有定义好的工具放入一个列表中,以便后续提供给Agent
tools = [multiply, get_word_length]
# ================================
# ? ③ 设计 Prompt
# ================================
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个强大的助手,可以使用工具来回答问题。"),
("human", "{input}"), # 用户输入
("placeholder", "{agent_scratchpad}"), # 填充Agent的中间步骤的占位符 (工具调用记录、工具输出等)
])
# ================================
# ? ④ 使用工厂函数创建Agent
# `create_tool_calling_agent`是一个高级函数,它将LLM、工具和提示组合在一起,
# 创建出一个遵循原生工具调用逻辑的Agent“大脑”。
# 这个函数内部封装了处理工具调用请求和响应的复杂逻辑。
# 返回的`agent`是一个Runnable对象,定义了决策逻辑,但还不能独立运行。
# ================================
agent = create_tool_calling_agent(llm, tools, prompt)
# ================================
# ? ⑤ 创建 AgentExecutor
# 设置 `verbose=True` 后,它会以非常详细的方式打印出Agent的每一步思考和行动,
# 让你能清晰地看到其内部工作流程。
# ================================
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# ================================
# ? ⑥ 调用Agent并获取结果
# 使用`.invoke()`方法来运行Agent。输入必须是一个字典,其键与提示中的占位符相对应。
# ================================
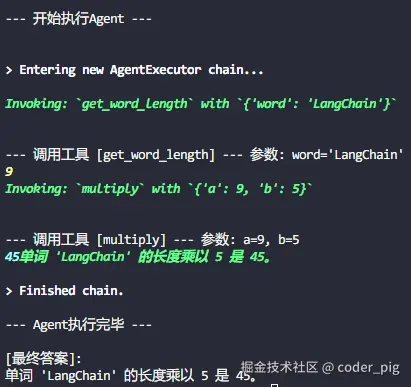
print("nn--- 开始执行Agent ---")
question = "单词 'LangChain' 的长度乘以 5 是多少?"
response = agent_executor.invoke({
"input": question
})
print("n--- Agent执行完毕 ---")
# 响应`response`是一个字典,最终的答案通常在`output`键中
print("n[最终答案]:")
print(response["output"])
运行输出结果:

