最近看到很多人对MCP/RAG/Agent/Cache/Fine-tuning/Prompt/GraphRAG 都分不清楚,今天我将通过图文,为你讲解其核心技术与实践原理,希望对你们有所帮助。
一、大模型核心架构演进
1.1 函数调用 & MCP(模型上下文协议)
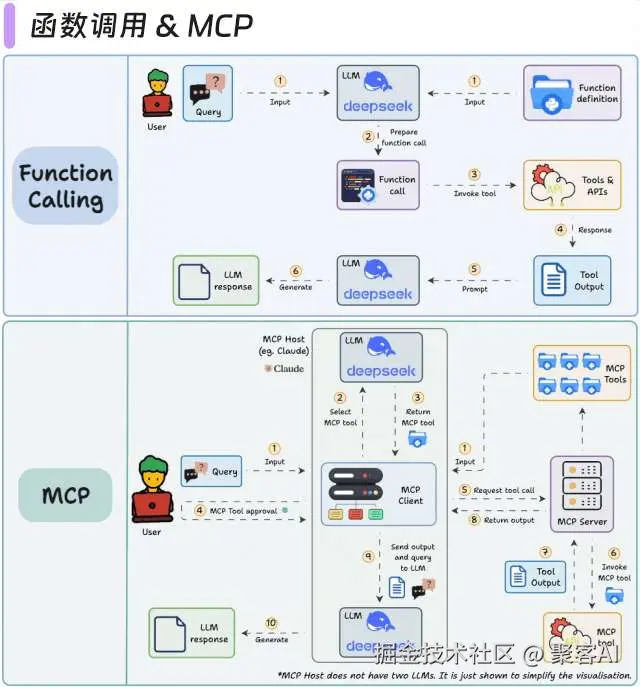
- 传统方案:预定义工具链导致灵活性差,错误传播风险高
- MCP突破:
- 动态上下文感知路由(Context-Aware Routing)
- 工具并行调用机制(Parallel Tool Invocation)
- 自修复工作流(Self-Correcting Pipeline)
1.2 Transformer到MoE架构进化
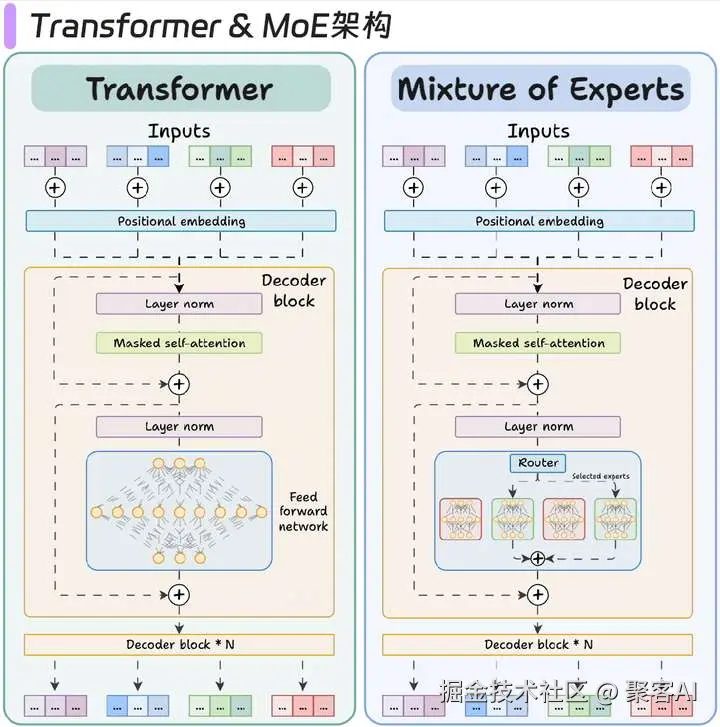
- 核心创新:
- 稀疏激活:每次推理仅激活2-4个专家(如Mixtral 8x7B)
- 专家专业化:每个专家学习不同领域知识(代码/数学/语言)
- 吞吐量提升:相同参数量下推理速度提升6倍
二、大模型训练技术全景
2.1 四阶段训练体系
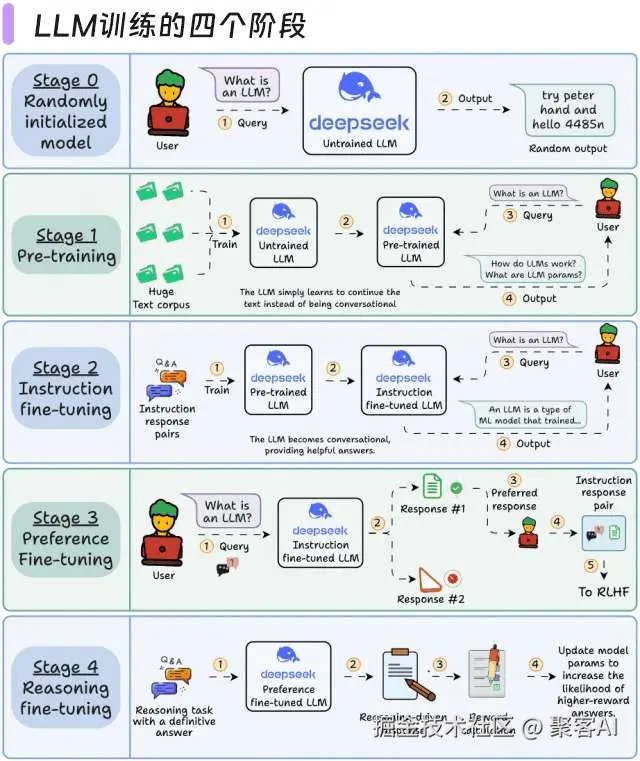
| 阶段 | 数据规模 | 关键技术 | 目标输出 |
|---|
| 预训练 | TB级语料 | Megatron-DeepSpeed | 基础语言模型 |
| 指令微调 | 百万级SFT | LoRA/QLoRA | 任务响应能力 |
| 偏好对齐 | 万级偏好对 | DPO/ORPO | 价值观对齐 |
| 推理优化 | 合成数据 | RFT/Rejection Sampling | 复杂推理能力 |
ps:这里顺便给大家分享一个大模型微调的实战导图,希望能帮助大家更好的学习,粉丝朋友自行领取:《大模型微调实战项目思维导图》
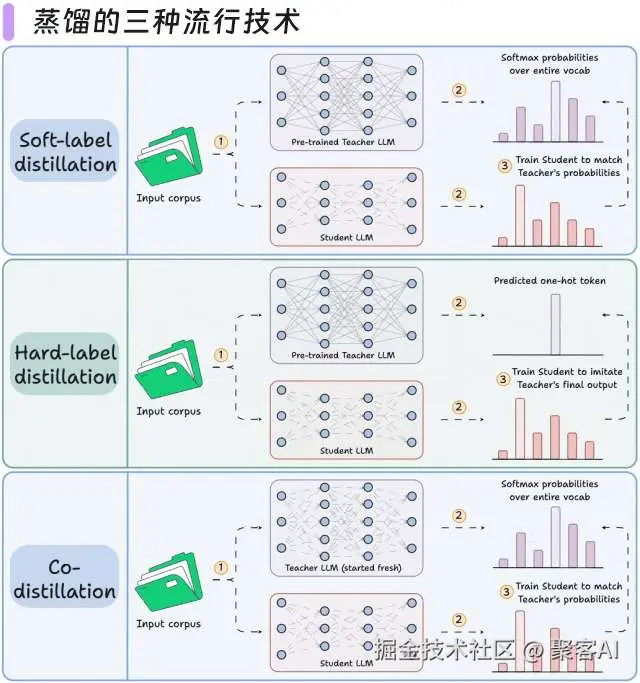
2.2 蒸馏技术应用
LLM 不仅从原始文本中学习;它们也相互学习:
- Llama 4 Scout 和 Maverick 是使用 Llama 4 Behemoth 训练的。
- Gemma 2 和 3 是使用谷歌专有的 Gemini 训练的。
- 蒸馏帮助我们做到这一点,下面的图描绘了三种流行的技术。
三、RAG架构演进路线
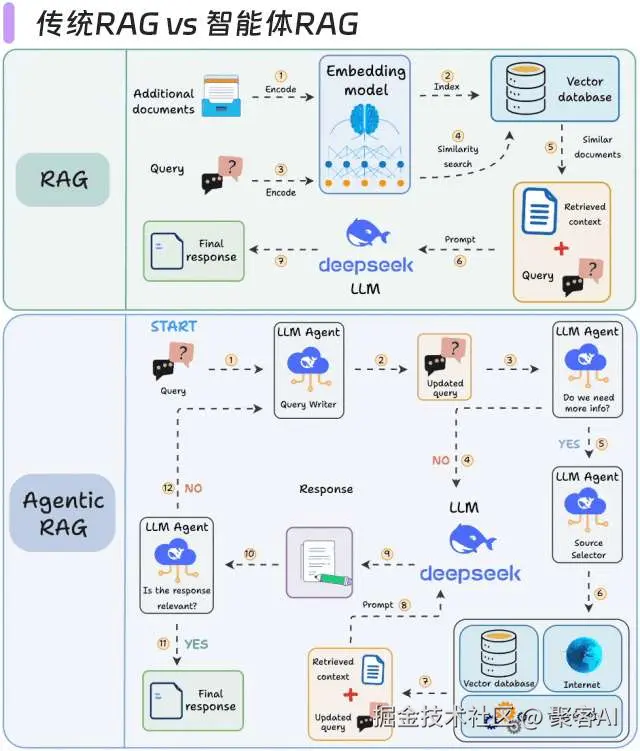
3.1 传统RAG vs 智能体RAG
3.2 HyDE解决方案
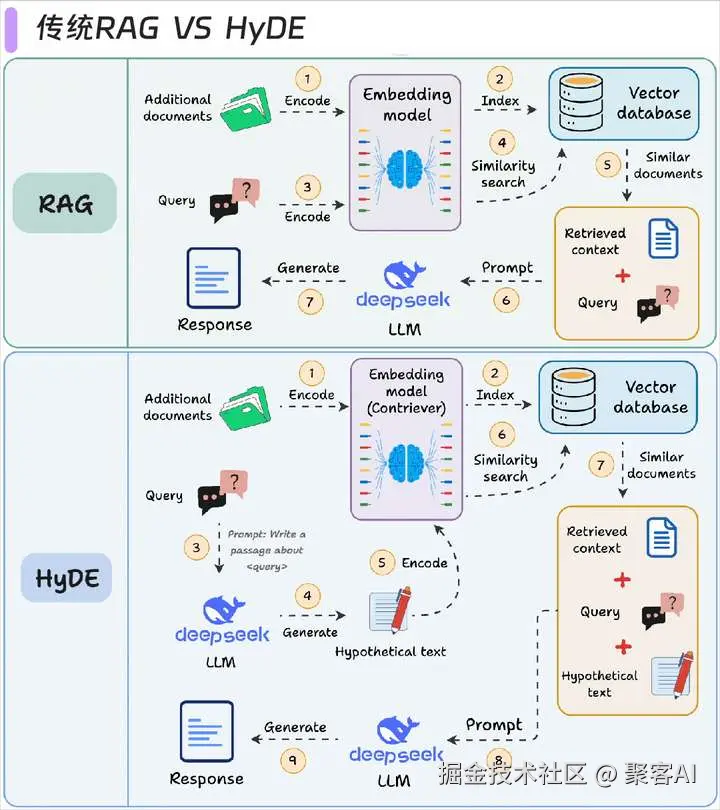
- 效果对比:
- HotpotQA数据集:传统RAG准确率58% → HyDE达到76%
- 关键机理:通过假设文档弥合问题与答案的语义鸿沟
四、推理优化关键技术
4.1 KV缓存机制
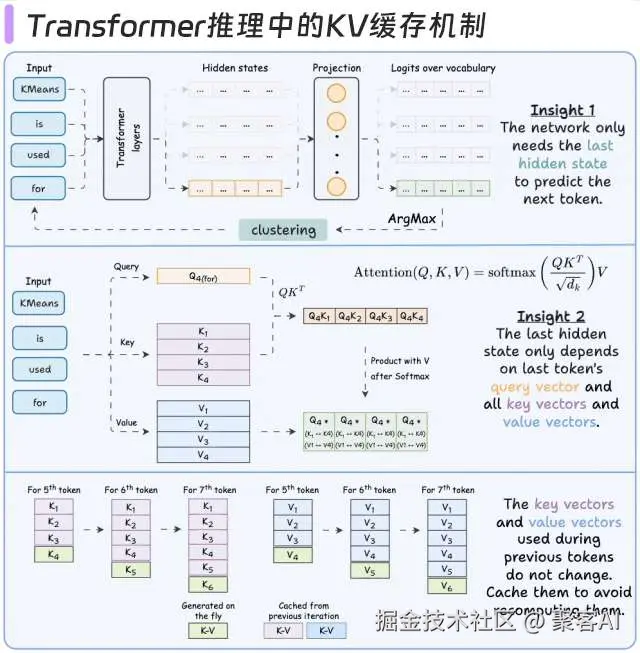
- 性能收益:
- 128K上下文:推理延迟降低4.8倍
- 显存占用减少37%(通过FP8缓存量化)
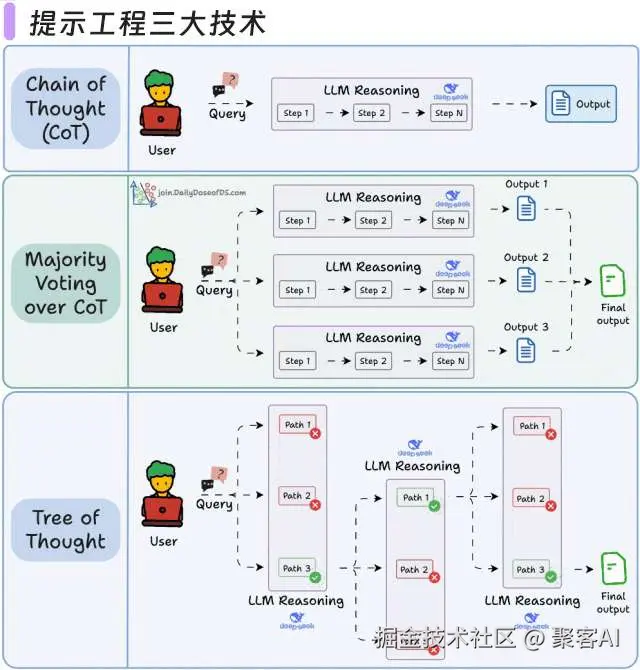
4.2 提示工程三大技术
- 思维链(CoT)
- 自洽性(Self-Consistency):生成多条推理路径 → 投票选择最佳答案
- 思维树(ToT)
五、智能体系统设计框架
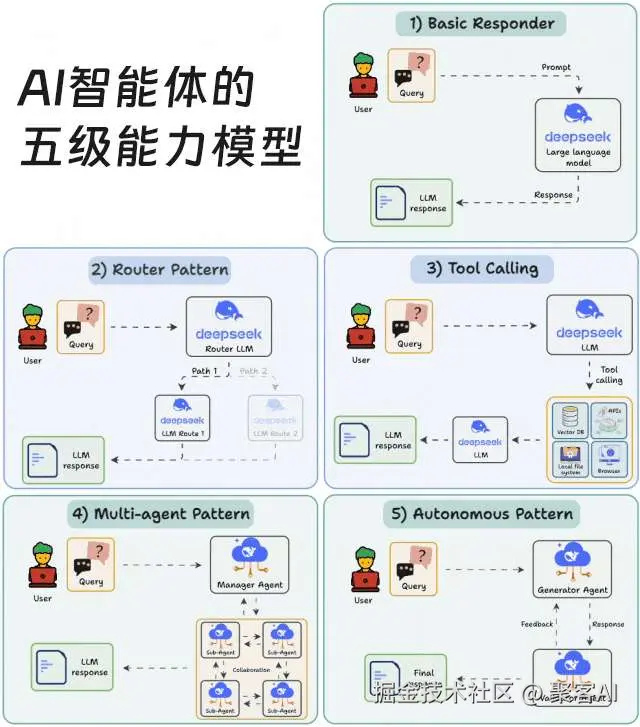
| 级别 | 类型 | 核心能力 | 示例场景 |
|---|
| L1 | 响应型 | 单轮问答 | ChatGPT基础模式 |
| L2 | 函数型 | 工具调用 | GitHub Copilot |
| L3 | 流程型 | 多工具编排 | AutoGPT |
| L4 | 目标型 | 动态规划+自我验证 | Devin开发助手 |
| L5 | 自治型 | 长期记忆+环境交互 | 工业控制系统 |
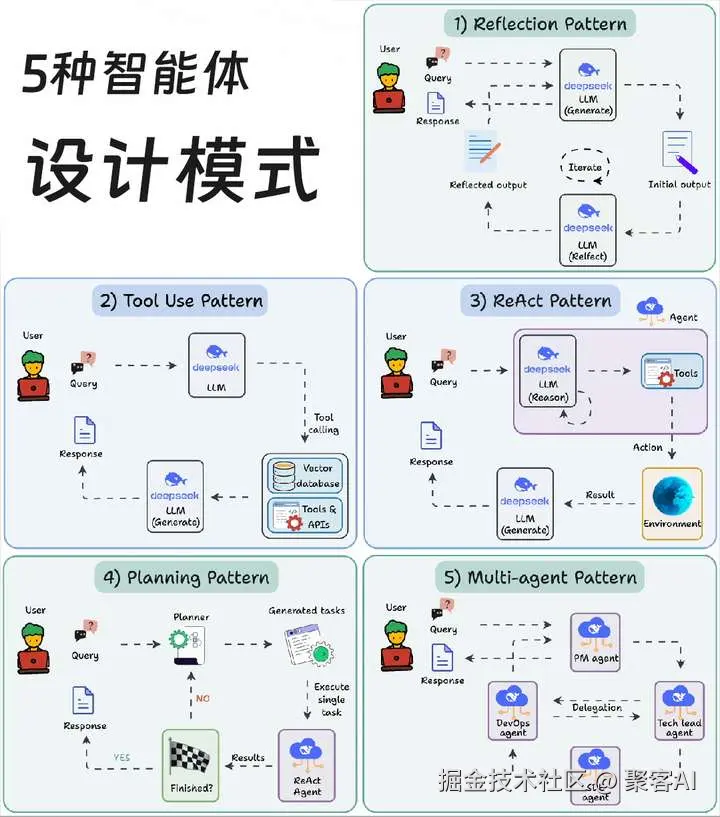
5.2 智能体设计模式
AI 智能体行为允许 LLM 通过自我评估、规划和协作来完善其输出!
这张图描绘了构建 AI 智能体时采用的 5 种最流行设计模式。
六、技术架构选择指南
- 数据敏感型场景:Fine-tuning + 私有化部署
- 知识密集型场景:GraphRAG + 知识图谱
- 高并发场景:MoE架构 + KV缓存优化
- 复杂任务场景:Agent架构 + 多工具编排
作者总结:未来通过MCP协议实现智能体工具动态编排,结合GraphRAG解决复杂知识推理,配合MoE架构提升推理效率,将会形成新一代大模型应用开发范式。各位朋友可根据具体场景需求,组合这些技术构建高性能AI系统。好了,本期分享就到这里,如果对你有所帮助,记得告诉身边有需要的朋友。点个小红心,我们下期见。



