消除迷宫:异境入侵官方中文版
· 2025-11-02

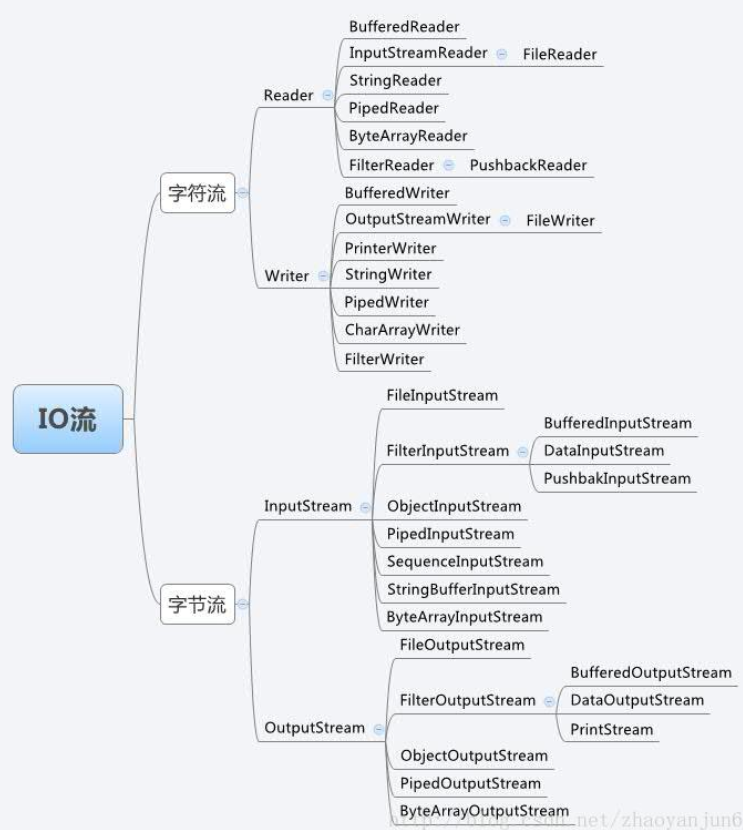
流是用来处理数据的。流的本质是数据传输
处理数据时,一定要先明确数据源,或者数据目的地
数据源可以是文件,可以是键盘。
数据目的地可以是文件、显示器或者其他设备。
而流只是在帮助数据进行传输,并对传输的数据进行处理,比如过滤处理、转换处理等。
键盘输入数据
读取文件中的数据
向文件中写数据
通过网络上传下载数据
等
流按操作对象分为两种:
(线路中只能传输字节流,字符流是对字节进行了封装)
流按流向分为:
字节流:一次读入或读出是8位二进制。
字符流:一次读入或读出是16位二进制。
数据序列从文件、内存或其他设备中流入到cpu中,称为输入流。
InputStream 是所有的输入字节流的父类,它是一个抽象类。
ByteArrayInputStream、StringBufferInputStream、FileInputStream 是三种基本的介质流,它们分别从Byte 数组、StringBuffer、和本地文件中读取数据。
PipedInputStream 是从与其它线程共用的管道中读取数据
ObjectInputStream 和所有FilterInputStream 的子类都是装饰流(装饰器模式的主角)。
数据序列从cpu流出到文件、内存或其他设备的称为输出流。
OutputStream 是所有的输出字节流的父类,它是一个抽象类。
ByteArrayOutputStream、FileOutputStream 是两种基本的介质流,它们分别向Byte 数组、和本地文件中写入数据。
PipedOutputStream 是向与其它线程共用的管道中写入数据。
ObjectOutputStream 和所有FilterOutputStream 的子类都是装饰流。
节点流:直接与数据源相连,读入或读出。
直接使用节点流,读写不方便,为了更快的读写文件,才有了处理流。

常用的节点流
父 类 :InputStream 、OutputStream、 Reader、 Writer
文 件 :FileInputStream 、 FileOutputStrean 、FileReader 、FileWriter 文件进行处理的节点流
数 组 :ByteArrayInputStream、 ByteArrayOutputStream、 CharArrayReader 、CharArrayWriter 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)
字符串 :StringReader、 StringWriter 对字符串进行处理的节点流
管 道 :PipedInputStream 、PipedOutputStream 、PipedReader 、PipedWriter 对管道进行处理的节点流
处理流和节点流一块使用,在节点流的基础上,再套接一层,套接在节点流上的就是处理流。如BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
常用的处理流
缓冲流:BufferedInputStrean 、BufferedOutputStream、 BufferedReader、 BufferedWriter 增加缓冲功能,避免频繁读写硬盘。
转换流:InputStreamReader 、OutputStreamReader实现字节流和字符流之间的转换。
数据流: DataInputStream 、DataOutputStream 等-提供将基础数据类型写入到文件中,或者读取出来。
InputStreamReader 、OutputStreamWriter 要InputStream或OutputStream作为参数,实现从字节流到字符流的转换。
换流的特点:
其是字符流和字节流之间的桥梁
可对读取到的字节数据经过指定编码转换成字符
可对读取到的字符数据经过指定编码转换成字节
何时使用转换流?
当字节和字符之间有转换动作时;
流操作的数据需要编码或解码时。
read()
从输入流中读取数据的下一个字节。返回 0 到 255 范围内的 int 字节值。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。
read(byte[] b)
从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。以整数形式返回实际读取的字节数。如果因为流位于文件末尾而没有可用的字节,则返回值 -1(比如b的长度是1024的长度,就非末尾的读取都是每次读1024个字节到b中,所以b经过一次read其中的数据就变化一次)
write(byte[] b)
将 b.length 个字节从指定的 byte 数组写入此输出流。
fr.close();关闭流资源,并将流中的数据清空到文件中:
如果不关闭流,会造成资源的浪费,从而影响程序的性能,还有可能让文件锁住,其他程序无法操作它。
Java对待目录和文件都统一用File来表示
File类提供本地文件系统的功能,对文件或目录及其属性进行基本操作
File对象用于封装一个抽象路径名
封装的文件没有时不会报错(但如果用FileOutputStream fos=new FileOutputStream(file);这样根据file类获取Stream时如果文件不存在时就会报FileNotFoundException)
要先删除文件,才能删掉其所在文件夹,要一层一层删
File类共提供了3个不同的构造方法
File(String path)
File f = new File(“c:myFilefile”);//可以是路径
File f = new File(“myFile.txt”);//可以是文件File(String path, String name);
File f = new File(“file”,”myFile.txt”);File(File dir,String name)
File f = new File(new File(“c:myFilefile”),”myFile.txt ”))|
方法 |
描述 |
|
public boolean creatNewFile() |
创建新文件,如果指定的文件不存在并成功创建,则返回true,如果指定的文件已经存在,则返回false。如果创建失败抛Io异常 |
|
public boolean exists() |
可以判断文件是否存在。 |
|
public boolean isDirectory () |
判断是不是目录。文件不存在也返回false
|
|
public boolean isFile() |
判断是不是文件。文件不存在也返回false |
|
public boolean mkdir() |
创建目录,成功返回true。只能创建一个文件夹,要求所有的父目录都存在,否则创建失败。 |
|
public boolean mkdirs() |
创建目录,成功返回true,会创建所有不存在的父目录。(注意即便最后创建失败,但是也可能创建了一些中间目录) |
|
boolean canExecute() |
判断文件是否可执行 |
|
boolean canRead() |
判断文件是否可读 |
|
boolean canWrite() |
判断文件是否可写 |
|
boolean isHidden() |
判断是不是隐藏文件 |
|
boolean isAbsolute() |
判断是否是绝对路径 文件不存在也能判断 |
|
String getName() |
返回由此抽象路径名表示的文件或目录的名称。文件会带后缀名。 |
|
String getPath() |
将此抽象路径名转换为一个路径名字符串 |
|
String getAbsolutePath() |
返回此抽象路径名的绝对路径名形式。 |
|
String getParent() |
返回此抽象路径名父目录的路径名字符串如果没有指定父目录返回null |
|
long lastModified() |
获取最后一次修改的时间 |
|
long length() |
返回由此抽象路径名表示的文件的长度 |
|
boolean renameTo(File f) |
重新命名此抽象路径名表示的文件。 |
|
File[] liseRoots() |
获取机器盘符 |
|
String[] list() |
返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中的文件和目录。 |
|
String[] list(FilenameFilter filter) |
返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
|
void delete() |
将当前文件删除 |
对于跟字节码文件有相同的目录的文件可以用
ClassLoader classLoder=其中的一个类名.class.getClassLoader();
InputStream in= classLoader.getSourceAsStream(“com/test/a.txt”);
即要把包的路径写上
或者InputStream in= 其中的一个类名.class.getSourceAsStream(“a.txt”);相对是相对字节码所在的包,直接定位到了字节码所在文件,也可以用绝对路径(“/com/test/a.txt”)绝对是相对类加载器的根目录
InputStream ,OutputStream。
Reader , Writer。
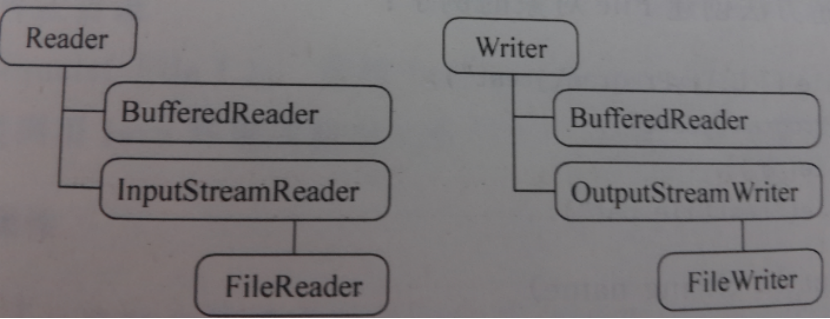
由这四个类派生出来的子类名称都是以其父类名作为子类名的后缀。
如:InputStream的子类FileInputStream。
如:Reader的子类FileReader(直接父类是InputStreamReader)。
InputStreamReader是Reader的子类
导入IO包中的类
进行IO异常处理
在finally中对流进行关闭
以字符为最小读写单位,也就是16位的一个字符的Unicode码,不能用于读写以字节为单位的文件。
|
类名 |
功能 |
|
BufferedReader及输出流 |
用于将字符流读写缓冲存储 |
|
InputStreamReader及输出流 |
用于将字节码与字符码相互转换 |
|
FileReader及输出流 |
用于字符文件的输入输出 |
字节流
字节为最小读写单位
可以读写字符文件
方法跟字符流类似
|
类名 |
功能 |
|
PipedInputStream及输出流 |
管道流,实现程序之间和线程之间的通信 |
|
FileInputStream及输出流 |
文件流,实现本地磁盘文件系统中的文件进行顺序读写的操作 |
|
ObjectInputStream及输出流 |
对象流,将对象作为数据通过流进行传输和储存 |

read()方法一个字节一个字节读,到-1停止
字节文件中会出现-1,其read()方法会与运算来再起前补24个0
InputStream中available()方法返回此输入流下一个方法调用可以不阻塞地从此输入流读取(或跳过)的估计字节数。如:int len = in.available(); byte[] buf = new byte[len];
in为InputStream类的引用变量
OutputStream类的write(int b)方法会把b对应的字节写入表现出来是对应的字符
System.in,System.out为标准输入流和标准输出流,返回类型为InputStream和PrintStream(OutputSteam的子类)都为字节流,默认的输入设备为键盘,输出设备为显示器,可用if语句规定读到什么结束,如if("bye".equals(Line)) break;可以通过System类的setIn,setOut方法对默认设备进行改变。
System.setIn(new FileInputStream(“1.txt”));//将源改成文件1.txt
System.setOut(new PrintStream(“2.txt”));//将目的改成文件2.txt,然后System.out.print(“b”)就会把字符串输出到2.txt。System.setOut(System.out)改回显示器。
同时该setIn和setOut可以实现文件的拷贝:
Scanner scan=new Scanner(System.in);
String s;
try{
while((s=scan.nextLine())!=null){
System.out.println(s);java中操作二进制文件使用字节输入输出流,操作字符文件使用字符输入输出流,字节流可以操作字符文件,但不提倡这么做。
使用字节流读取文本文件,如果文本文件中有中文,可能会出现乱码想象,这是因为字节流不能字节操作Unicode字符所致,因此java不提倡用字节流读取文本文件。
先读到数组中比一个个在文件中读效率高,数组在内存而文件在硬盘
一般数组的长度定义为1024
定义文件路径时,可以用“/”或者“\”。
在读取文件时,必须保证该文件已存在,否则出异常。
常用的4个类
FileInputStream: 字节文件输入流
FileOutputStream: 字节文件输出流
FileReader: 字符文件输入流
FileWriter: 字符文件输出流
如果文件路径不对会报FileNotFoundException,文件不存在也会报FileNotFoundException
FileInputStream(String filename);
带有文件路径和文件后缀的完整字符串
FileInputStream(File file);
指定文件对象
FileInputStream(FileDescription fdObj)
自定的文件描述符
一次读一个字节,返回整数值,末尾是返回-1
(返回整型的原因:为了提示什么时候文件没有内容了如果返回字符型不能够表达什么时候结束,-1为约定的,有字符时返回的是字符转为int类型的值即左边加16位的0)(int4个字节,Unicode所有字符两个字节)
一次读取数组内容实际长度个字节,如1024,每次读1024(最后一次除外),末尾反-1.
从off位置读len个字节。
如果文件路径不对会报FileNotFoundException,如果文件路径对文件不存在就会新建文件,文件存在也会新建新的来替换旧的
FileOutputStream(String filename);
带有文件路径和文件后缀的完整字符串
FileOutputStream(File file);
指定文件对象
FileOutputStream(FileDescription fdObj)
自定的文件描述符
一次写一个字节
一次写b.length个字节
从off开始写len个字节
FileReader(String filename);
FileReader(File file);
FileReader(FileDescription fdObj)
FileWriter(String filename);
FileWriter(File file);
FileWriter(FileDescription fdObj)
是包装流
提供了缓冲的功能,使数据处理速度大大加快,提高了读写效率。
默认的缓冲区大小为8192
write方法一般先把数据存放在缓冲区,缓冲区满时,会一次性写入输出流,即写入文件,如果缓冲区不满,可以用flush()方法写入输出流。
与FileReader和FileWriter配合使用。
关闭br,bw内部流也会自动关闭
BufferedReader(Reader in);
BufferedWriter(Writer out);
例如:
br = new BufferedReader(new FileReader("src/a.txt"));
bw = new BufferedWriter(new FileWriter("src/b.txt"));
读取一个文本行,当没有内容时返回null,结束条件:换行 ('n')、回车 ('r') 或回车后直接跟着换行,其中的回车换行会被过滤掉。
while((s=br.readLine())!=null){
System.out.println(s);}因为回车换行已经读过,所以读取一行后已经定位到下一行。
将自定的字符串s从偏移量off开始的len个字符写入文件输出流。
刷新缓冲区,将缓冲区的数据写入到文件中。
String s;
File f =new File(“D:/jtest/”,”a.txt”);
File f2=new File(“b.txt”);
BufferedReader br= new BufferedReader(new FileReader(f));
BufferedWriter bw=new BufferedWriter(new FileWriter(f2));
while((s=br.readLine())!=null){
bw.write(s,0,s.length());
bw.flush();
}关闭流和异常这里省略
如:setLineNumber(100)则行号从101开始,无参数从1开始
InputStream
|__FilterInputStream
|__BufferedInputStream
使用它们可以防止每次读取/发送数据时进行实际的写操作,代表着使用缓冲区。
我们有必要知道不带缓冲的操作,每读一个字节就要写入一个字节,由于涉及磁盘的IO操作相比内存的操作要慢很多,所以不带缓冲的流效率很低。带缓冲的流,可以一次读很多字节,但不向磁盘中写入,只是先放到内存里。等凑够了缓冲区大小的时候一次性写入磁盘,这种方式可以减少磁盘操作次数,速度就会提高很多!
同时正因为它们实现了缓冲功能,所以要注意在使用BufferedOutputStream写完数据后,要调用flush()方法或close()方法,强行将缓冲区中的数据写出。否则可能无法写出数据。
BufferedInputStream(InputStream in) //使用默认buf大小、底层字节输入流构建bis
BufferedInputStream(InputStream in, int size) //使用指定buf大小、底层字节输入流构建bis
因为IO流都需要关闭,不处理就可能关闭出现问题
ByteArrayInputStream中包含一个内部缓冲区,用来包含那些可能从流中读的字节数组。还有一个内部计数器来跟踪下一个将被读取的字节。
输入流和输出流都有close方法
作用:释放资源,释放对文件的锁定
对于使用缓存的输出流还会调用flush方法把数据清空到接收端
刷新此输出流并强制写出所有缓冲的输出字节。
输入流没有flush方法,输出流实现了Flushable接口都有flush方法
没有带缓存的流的flush方法是空的实现,带缓存的流的flush方法有真正的实现
带有缓冲功能的输出流在close()方法之前要先调用flush()方法,
为了保险就调用一次flush再close。
在创建一个文件时,如果目录下有同名文件将被完全覆盖新建空白写入。如果追加,参数多加一个true会从文件内容末尾追加
public static void main(String[] args)
{
FileWriter fw = null;
try
{
fw = new FileWriter("src/2.txt", true); //创建文件
也可以先File file = new File("src/2.txt");, 然后fw = new FileWriter(file, true);
/
fw.write("中国"); //在文件中写入内容
//fw.flush();//刷新缓冲,使内容写到文件中
}
catch(IOException e)
{
e.printStackTrace();
}
finally
{
try
{
if(fw != null) fw.close(); //自动刷新缓冲,并关闭关联
}
catch(IOException e)
{
e.printStackTrace();
}
}
}
如:
import java.io.IOException;
import java.io.Reader;
import java.io.Writer;
public class CloseUtil{
private CloseUtil(){}
public static void close(Reader r, Writer w) throws IOException
{
try
{
if(r != null) r.close();
}
finally
{
if(w != null) w.close();
}
}
}
比如InputStream的对象调用了read方法以后,这个对象中的数据就已经产生变化了
如果要复用可以先读到一个字节数组中,这里用ByteArrayOutputStream来转化出这个自己数组方便使用
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len;
while((len = inputStream.read(buffer)) > -1) {
baos.write(buffer, 0, len);
}
baos.flush();
InputStream stream1 = new ByteArrayInputStream(baos.toByteArray());
InputStream stream2 = new ByteArrayInputStream(baos.toByteArray());
直接继承Object类,实现了DataInput和DataOutput接口
RandomAccessFile(String filename,String mode)
filename文件名,
mode为操作方法:“r”只读,“rw”读写。
RandomAccessFile f = new RandomAccessFile(“a.txt”, ”rw”);
f.writeBytes(“ssssssss”);
f.close;说明:获得a.txt,并具有读写权限,向a.txt中写入指定内容,如果文件存在会覆盖原有内容,如果不存在,则新建一个文件,写入内容。
可以设置和访问行号
getLineNumber()方法获得行号
setLineNumber()方法设置行号
许多应用程序需要将处理的数据作为java的一种基本数据类型来使用,就要用到数据流。它们允许程序按与机器无关的格式读取java原始数据。
字符流与字节流的桥梁。
InputStreamReader OutputStreamWriter 为转换流,FileReader FileWriter为其子类
InputStreamReader:把读取的字节型数据解码为字符型数据
OutputStreamWriter :将写入的字符型数据编码为字节型数据。
InputStreamReader构造方法InputStreamReader(InputStream in)。
System.in的数据类型为InputStream
如:new OutputStreamWriter(new FileOutputStream("out.txt"),"UTF-8")//默认为GBK 改为UTF-8进行保存
new InputStreamReader(new FileInputStream("in.txt"),"UTF-8");
而不能用new FileReader("in.txt")
BfferedReader bufr =new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bufw =new BufferedWriter(new OutputStreamWriter(System.out));
通过InputStreamReader和OutputSteamReader把字节流转换为字符流进行传递
文件末尾读到null,可以作为结束条件
字节流转换为字符流本质是将字符串数组转换为字符串:
String(byte bytes[],String charsetName)
字符流转换为字节流本质是将字符串转换为字节数组:
String.getBytes(String charsetName)
PrintWriter (字符流)与PrintStream(字节流)
1、PrintWriter 对Writer进行包装,实现打印功能
write();传入int型会强转为char,写入一个字符
print();什么类型都能够写入
2、PrintStream 对OutputStream进行包装
操作对象
ObjectInputStream与ObjectOutputStream
ObjectOutputStream会序列化对象到硬盘
ObjectInputStream会对序列化的对象反序列化还原
有的时候我们需要找一种数据格式对内存中的对象进行描述,便于保存,这时,可能每个程序员都有自己的想法,都会去使用自己习惯的格式,对象的序列化,就是按照Java规定格式将对象转成一种数据,便于保存,这个过程就是序列化,将数据格式转为对象的过程叫反序列化
被序列化的类应该实现Serializable接口,否则无法序列化
ObjectOutputStream oos =new ObjectOutputStream(new FileOutputStream("src/object.txt"));
oos.writeObject(p1);
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("src/object.txt"));
Object obj = ois.readObject();//从硬盘中读取对象
Person p1 = (Person)obj;//为了用Person中的toString方法
System.out.println(obj);
SequenceInputStream
合并多个输入流,它没有输出流
如:
InputStream in1 = new FileInputStream("src/a.txt");
InputStream in2 = new FileInputStream("src/b.txt");
OutputStream out = new FileOutputStream("src/c.txt");
SequenceInputStream sis = new SequenceInputStream(in1, in2);
int ch;
while((ch = sis.read()) != -1) {
out.write(ch);
}当有多个流时用到Enumeration,用Vector类通过调用.elements()方法得到枚举变量,作为SequenceInputStream构造函数的参数读写就行
或者用
final Iterator < InputStream > iter = al.iterator();
SequenceInputStream sis = new SequenceInputStream(new Enumeration < InputStream > () {
public boolean hasMoreElements() {
return iter.hasNext();
}
public InputStream nextElement() {
return iter.next();
}操作基本数据类型
DateinputStream与DataOutPutStream
用于将基本数据类型数据以其原本大小存储,而不是字符大小
其中有writeInt(6);readDouble();等方法来进行数据的读取,数据所占用空间不变,但还会转为对应的字符,不够的用空格代替,字节流字符流write(int)会把int数据转换为相对应的字符写入。
操作内存缓冲数组
ByteArrayStream与CharArrayReader
如int a = 1;这其中就用到了DateOutputStream包装ByteArrayOutputStream对象在用writeInt()方法实现
管道流
PipedInputStream与PipedOutputStream
默认则是从ClassPath根下获取,path不能以’/'开头,最终是由ClassLoader获取资源。
如:
DBCPUtil.class.getClassLoader().getResourceAsStream("dbcpconfig.properties");
path 不以’/'开头时默认是从此类所在的包下取资源,以’/'开头则是从ClassPath根下获取。其只是通过path构造一个绝对路径,最终还是由ClassLoader获取资源。
如:
在me.class目录的子目录下,例如:com.x.y 下有类me.class ,同时在 com.x.y.file 目录下有资源文件myfile.xml
那么,应该有如下代码:
me.class.getResourceAsStream("file/myfile.xml");
前面没有 “ / ” 代表当前类的目录
不在me.class目录下,也不在子目录下,例如:com.x.y 下有类me.class ,同时在 com.x.file 目录下有资源文件myfile.xml
那么,应该有如下代码:
me.class.getResourceAsStream("/com/x/file/myfile.xml");
“ / ”代表了工程的根目录,例如工程名叫做myproject,“ / ”代表了myproject
默认从WebAPP根目录下取资源,Tomcat下path是否以’/'开头无所谓,当然这和具体的容器实现有关。
java.nio 全称New IO也可以翻译成java non-blocking IO,非阻塞式IO
为所有的原始类型(boolean类型除外)提供缓存支持的数据容器
IO NIO
面向流 面向缓冲
阻塞IO 非阻塞IO
无 选择器
面向流与面向缓冲
标准的IO基于字节流和字符流进行操作的,而NIO是基于通道(Channel)和缓冲区(Buffer)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
nio是非阻塞的(异步IO)可以让你异步的使用IO,例如:当线程从通道读取数据到缓冲区时,线程还是可以进行其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也类似。
选择器(Selectors)
选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。
如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,这时候用NIO处理数据可能是个很好的选择。
而如果只有少量的连接,而这些连接每次要发送大量的数据,这时候传统的IO更合适。使用哪种处理数据,需要在数据的响应等待时间和检查缓冲区数据的时间上作比较来权衡选择。
缓存I/O又被称作标准I/O,大多数文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。即:通过高速缓存来进行io读写操作
缓存I/O的优点:
缓存I/O的缺点:数据在传输过程中需要在应用程序地址空间和缓存之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
直接IO:
应用程序直接访问磁盘数据,而不经过内核缓冲区
直接IO的缺点:如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载
磁盘IO:
主要的延时是由(以15000rpm硬盘为例): 机械转动延时(机械磁盘的主要性能瓶颈,平均为2ms) + 寻址延时(2~3ms) + 块传输延时(一般4k每块,40m/s的传输速度,延时一般为0.1ms) 决定。(平均为5ms)
网络IO主要延时由: 服务器响应延时 + 带宽限制 + 网络延时 + 跳转路由延时 + 本地接收延时 决定。(一般为几十到几千毫秒,受环境干扰极大)
所以两者一般来说网络IO延时要大于磁盘IO的延时。
页面:
用js:
window.location.href=ctx+'download/one?contentId='+contentId+'&categoryId='+categoryId;
或者在页面直接a标签跳转这个连接也可以
@
GetMapping("/one")@ ResponseBody
public void downLoad(Long contentId, Long categoryId, HttpServletResponse resp) throws IOException {
if(contentId == null) {
return;
}
Content content = contentService.selectContentById(contentId);
//根据contentId查询出来文件路径
String fileUrl = documentService.findFileUrl(contentId, MaterialsConstants.FILE_DOWNLOAD);
if(StringUtils.isNotEmpty(fileUrl)) {
//获取文件名
String fileName = fileUrl.substring(fileUrl.lastIndexOf("/") + 1);
String fileAllUrl = ProjectConfig.FILEPREFIX + fileUrl;
InputStream in = null;
OutputStream out = null;
try { in = new URL(fileAllUrl).openStream();
//输入流放入输出流
// 把本地文件发送给客户端
resp.setContentType("text/html; charset=UTF-8"); // 设置编码字符
resp.setContentType("application/x-msdownload"); // 设置内容类型为下载类型
//采用中文文件名需要在此处转码
fileName = new String(fileName.getBytes("GB2312"), "ISO_8859_1");
resp.setHeader("Content-Disposition", "attachment; filename=" + fileName);
out = resp.getOutputStream();
int byteRead = 0;
byte[] buffer = new byte[512];
while((byteRead = in .read(buffer)) != -1) {
out.write(buffer, 0, byteRead);
} //记录资料下载次数
// redisUtils.incr(MaterialsConstants.CONTENT_DOWNLOAD_COUNTE_PREFIX+contentId);
//mongo 记录下载记录7天热度值
HotContentVo hotContentVo = new HotContentVo();
hotContentVo.setContentId(contentId);
hotContentVo.setHot(MaterialsConstants.HOT_DOWNLOAD);
hotContentVo.setCategoryId(categoryId);
hotContentVo.setClassificId(content.getClassificId());
hotContentVo.setSubjectId(content.getSubjectId());
// hotContentVo.setCreateTime(new Date());
mongoUtils.saveMongoDB(hotContentVo); //数据库存储总热度值和增加下载计数
ContentHot contentHot = new ContentHot();
contentHot.setContentId(contentId);
contentHot.setHot(MaterialsConstants.HOT_DOWNLOAD);
contentHot.setDownloadCount(1);
contentService.saveContentHot(contentHot);
} catch(Exception e) {
log.error("下载文件异常", e);
} finally {
if( in != null) { in .close();
}
if(out != null) {
out.flush();
out.close();
}
}
};
}
下载文件:
a标签访问接口返回文件流
或href内容设置为流的二进制内容
js:
function bachDownload() { //获取选中的内容的contentId
if($("input[name='selectBox']:checked").length > 0) {
var contentIds = [];
$("input[name='selectBox']:checked").each(function() {
contentIds.push(Number(this.value)); //push 进数组
});
var url = prefix + '/bachDownLoad';
var xhr = new XMLHttpRequest();
var fd = new FormData();
fd.append("contentIds", contentIds);
xhr.responseType = "blob"; // 返回类型blob
// 定义请求完成的处理函数,请求前也可以增加加载框/禁用下载按钮逻辑
xhr.onload = function () { // 请求完成
if (this.status == 200) { // 返回200
var blob = this.response;
if(blob.size > 0) {
var reader = new FileReader();
reader.readAsDataURL(blob); // 转换为base64,可以直接放入a表情href
reader.onload = function (e) { // 转换完成,创建一个a标签用于下载
var a = document.createElement('a');
a.download = $("#contentTitle").text() + '.zip';
a.href = e.target.result;
$("body").append(a); // 修复firefox中无法触发click
a.click();
$(a).remove();
}
} else {
alert("资料文件不存在");
}
}
}; // 发送ajax请求
xhr.open("post", url, true);
xhr.send(fd);
}
}
java
@PostMapping("/bachDownLoad")
@ ResponseBody
public void bachDownLoad(@RequestParam("contentIds") List < Long > contentIds, HttpServletResponse resp) throws IOException {
if(CollectionUtils.isNotEmpty(contentIds)) {
//根据资料id获取文件url
List < String > fileUrls = iSpecialService.findFileUrls(contentIds, MaterialsConstants.FILE_DOWNLOAD);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ZipOutputStream zos = new ZipOutputStream(bos);
OutputStream out = null;
try {
for (String fileUrl : fileUrls) {
String fileName = fileUrl.substring(fileUrl.lastIndexOf("/") + 1);
String fileAllUrl = ProjectConfig.FILEPREFIX + fileUrl;
zos.putNextEntry(new ZipEntry(fileName));
int byteRead = 0;
byte[] buffer = new byte[512];
InputStream in = null;
byte[] bytes = null;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
try { in = new URL(fileAllUrl).openStream();
while ((byteRead = in .read(buffer)) != -1) {
baos.write(buffer, 0, byteRead);
}
baos.flush();
bytes = baos.toByteArray();
} catch (Exception e) {
throw e;
} finally {
if( in != null) { in .close();
}
baos.close();
}
zos.write(bytes, 0, bytes.length);
zos.closeEntry();
}
zos.close();
// 把本地文件发送给客户端
// resp.setContentType("text/html; charset=UTF-8"); // 设置编码字符
// resp.setContentType("application/x-msdownload"); // 设置内容类型为下载类型
// String fileName=System.currentTimeMillis()+"资料.zip";
// resp.setHeader("Content-Disposition", "attachment; filename=" + fileName);
out = resp.getOutputStream();
out.write(bos.toByteArray()); //TODO 记录文件下载次数
} catch (Exception e) {
log.error("下载文件异常", e);
} finally {
if(out != null) {
out.flush();
out.close();
}
}
}
fName.substring(fName.lastIndexOf("/")+1);

